 電子發(fā)燒友App
電子發(fā)燒友App


FPGA 即 Field Programmable Gate Arrays,現(xiàn)場可編程門陣列。如果邏輯代數(shù)為數(shù)字世界的理論指導(dǎo),那么邏輯門電路就是蓋起座座數(shù)字大廈的基本塊塊磚瓦,無論基本的數(shù)字電路還是現(xiàn)代的集成電路,無不構(gòu)建在邏輯門之上,把邏輯門和時(shí)鐘組合起來,人們搭建起了加法器、選擇器、鎖存器、觸發(fā)器,進(jìn)而的運(yùn)算單元、可控制單元、RAM。按照聰明的工程師設(shè)計(jì)好的電路圖紙?jiān)賹⑦@些基本的數(shù)字電路原件組合起來,再設(shè)計(jì)成可以印刷的集成電路形式,就可以構(gòu)成各種專用的集成電路(ASIC)或者通用計(jì)算機(jī)處理器(CPU)等。FPGA相對(duì)ASIC來說更靈活。ASIC相對(duì)來說量產(chǎn)后會(huì)更廉價(jià)、節(jié)能,性能也更好。
專用集成電路只在意輸入和輸出,中間的一切算法會(huì)被固化到硬件設(shè)計(jì)中;而通用CPU則同時(shí)接收數(shù)據(jù)流和指令流,按照軟件工程師的程序指令序列執(zhí)行一些列計(jì)算任務(wù)(雖有人將CPU也歸為ASIC,但是我覺得這是在硬件角度上來說的,從計(jì)算任務(wù)的可編程性角度CPU實(shí)際上是最靈活通用的)。FPGA則介于ASIC和CPU之間,它并非將邏輯門組成的原件之間的連接形式固化,也非做成最有利通用計(jì)算的形式動(dòng)態(tài)地接收軟件指令來調(diào)動(dòng)片上已有的計(jì)算單元,而是可以通過重復(fù)硬件編程來改變它邏輯門所組成的基本功能單元和調(diào)整這些單元之間的連接關(guān)系。
1. 硬件架構(gòu)介紹
1.1 Overview
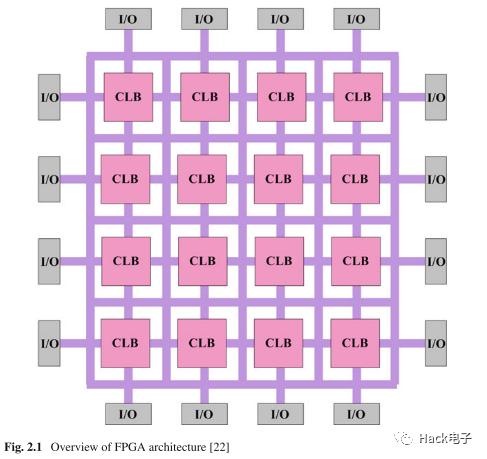
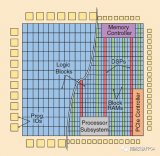
如下圖所示,邏輯上,F(xiàn)PGA主要由可編程的邏輯塊(programmable logic block, 主要是圖中CLB) 和 可編程互聯(lián)網(wǎng)絡(luò) (programmable interconnect network / routing interconnect, 主要是圖中SB, CB和一些路由通道組成)。
?
+-----------+
| |
| LUT +-+
| | | +--------+ +-----------+
+-----------+ | | | | |
+----> BLE +----> CLB +----+
+-----------+ | | | | | |
| | | +--------+ +-----------+ |
| Flip-Flop +-+ |
| | +---------------------+ |
+-----------+ | | |
| Switch Box (SB) +----+
| | |
+---------------------+ |
+---> FPGA
+---------------------+ |
| | |
| Connection Box +----+
| (CB) | |
+---------------------+ |
|
+---------------------+ |
| | |
| I/O Block | |
| +----+
+---------------------+
?
空間布局上,可以簡單理解為下圖[1]:
按編程技術(shù)分類FPGA
FPGA的基礎(chǔ),即可配置性依賴于存儲(chǔ)這些硬件門配置的介質(zhì),這種區(qū)別也成為FPGA的編程技術(shù),按照這種硬件編程技術(shù)分類,F(xiàn)PGA分為三類:基于SRAM的FPGA、基于flash的FPGA和基于反熔絲(antifuse)的FPGA[1]。
基于SRAM的FPGA是斷電易失的,所以需要在開機(jī)(startup)時(shí)通過JTAG編程,或者通過內(nèi)置/外置的非易失存儲(chǔ)進(jìn)行編程。
基于flash的FPGA的邏輯門本身就是非易失的。antifuse FPGA只能編程一次,不可逆。
1.2 組成單元
Look-Up Table (SRAM based)
k-bound LUT或稱為LUT-k指的是有k個(gè)輸入、2^k個(gè)配置bits的布爾函數(shù)邏輯。如下圖[1]所示的basic logic element(BLE)由1個(gè)LUT-4和一個(gè)D型觸發(fā)器(Flip-Flop)構(gòu)成,其中多個(gè)LUT-4有16個(gè)SRAM構(gòu)成的配置位,通過這些配置為配置這些選擇器可以構(gòu)成任意一個(gè)4輸入邏輯單元。
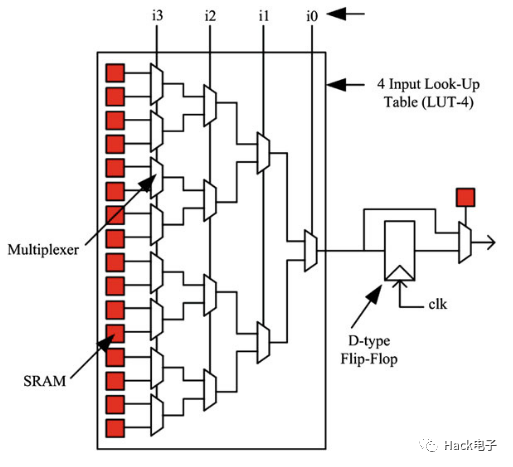
這個(gè)例子中,配置數(shù)據(jù)存在SRAM中,基于這種BLE的FPGA可以稱為基于SRAM(或說static memory)的FPGA。
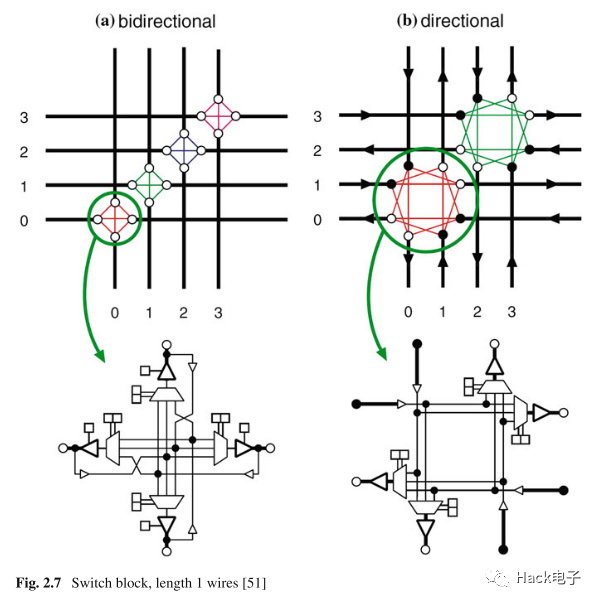
Switch Box (SRAM based)
如下圖[1]Switch Box中,分為雙向(a)和單向(b),一般后者更常用。這些switch都是基于pass transistor[3]的,每個(gè)pass transistor可以獨(dú)立地進(jìn)行開關(guān)配置。
基于NAND Flash 的 FPGA 組件
同樣也有人提出基于NAND flash的FPGA,基于NAND flash相對(duì)基于SRAM,除了LUT、SB的配置形式需要重新設(shè)計(jì)外,NAND flash還具有NVM都有的非易失特點(diǎn),可以減少外置flash存儲(chǔ)的使用,在上電后不用重新配置。
但是當(dāng)今的主流FPGA技術(shù)還是SRAM,因?yàn)樗鸵话愕腃MOS集成電路技術(shù)分享技術(shù),可以得到集成度、速度和功耗上的不斷提升。
一般的,要用Flash替代SRAM作為配置位,需要將SRAM cell替換為FMC(flash memory cell),如下圖以2-LUT為例[2],每個(gè)FMC都由2個(gè)flash晶體管Fp和Fq組成。當(dāng)然論文[2]的作者也提出了針對(duì)NAND Flash的更高效替代方法。
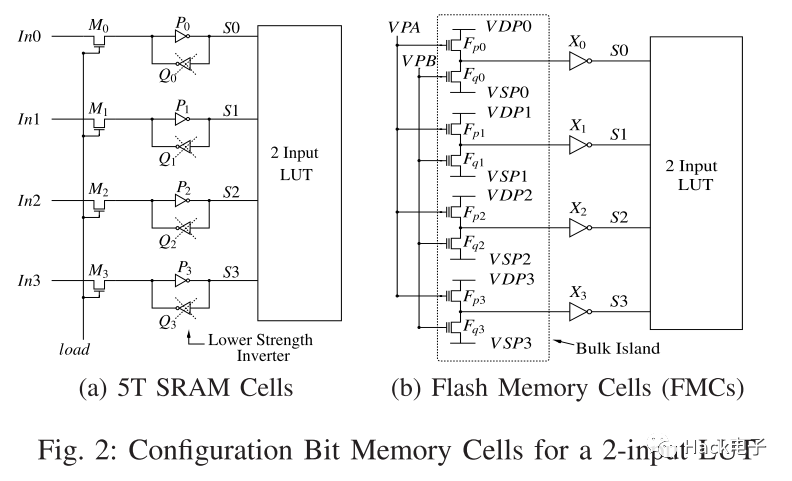
1.3 IP核
FPGA的IP核(core)可以看做是軟件中的各種庫,避免了編程或設(shè)計(jì)人員重復(fù)造輪子。現(xiàn)代FPGA的可編程門陣列只占50%,其他大部分被硬IP核占據(jù)。
硬IP核是系統(tǒng)設(shè)計(jì)中一些常用的模塊,直接以模塊形式集成到FPGA的,比如memory block、calculating circuits,transceiver和protocol controller等,有些甚至加入了CPU、DSP等[6]。
2. 軟件流程
軟件流程也叫CAD(計(jì)算機(jī)輔助)流程,負(fù)責(zé)將人實(shí)現(xiàn)的上層應(yīng)用邏輯映射到FPGA可編程硬件邏輯上,這個(gè)映射對(duì)最終的性能影響很大,所以這也是人們研究的一個(gè)重點(diǎn)。
這個(gè)過程將人寫的硬件描述語言HDL轉(zhuǎn)成可以最終編程到FPGA的比特流。這個(gè)過程大概分為5步: synthesis(綜合)、technology mapping, mapping, placement, routing。CAD 工具最后生成的就是bit流。軟件流程的框圖[1]如下:
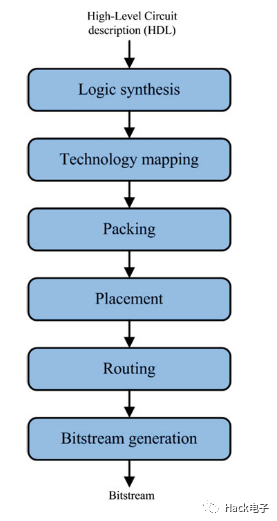
Logic Synthesis 邏輯綜合?將VHDL/verilog這類硬件描述編程語言轉(zhuǎn)成布爾門、flip-flops。
Technology Mapping?將上一步的邏輯門轉(zhuǎn)成k-bound的LUT (lookup-table)。
Clustering/Packing?將多個(gè)LB(即k-bound LUT + flip-flop對(duì),或稱BLE) 組成logic block clusters。主要有三種方法,各有利弊:
top-down:k路分割問題的基本的cost function 是 net cut,即partition間的邊數(shù)。
depth-optimal:用邏輯的重復(fù)換取更快的運(yùn)行
bottom-up: FPGA CAD中用的比較多,因?yàn)檫\(yùn)行快
Placement?主要決定logic block 的放到FPGA哪個(gè)logic block 位置,以最小的wiring 為主(wire length-driven placement)。或者平衡wiring 的密度(routability-driven placement);或者找到最快的電路速度(timing-driven placement)。常用partitioning或者模擬退火的方法
Routing?階段將網(wǎng)絡(luò)關(guān)聯(lián)到物理的routing網(wǎng)絡(luò),當(dāng)前state-of-the-art 算法是pathfinder。
在這些階段之后,還有時(shí)序分析階段和bitstream生成階段,最后的bitstream會(huì)真正的用于編程到SRAM存儲(chǔ)位來配置邏輯門。
3. Host FPGA管理系統(tǒng)的發(fā)展
[4] 提出了一種"FPGA操作系統(tǒng)", [5] 是對(duì)FPGA虛擬化的綜述。
[5]中的虛擬化其實(shí)是廣義的虛擬化,包括FPGA的時(shí)分復(fù)用、虛擬執(zhí)行和虛擬機(jī)。
時(shí)分復(fù)用:任務(wù)大,單FPGA資源少(而非FPGA資源少、任務(wù)小而要一直進(jìn)行切換FPGA配置)。
虛擬執(zhí)行:將任務(wù)切分為多個(gè)需要通信的子任務(wù)(Petri-Net model),用一種運(yùn)行時(shí)系統(tǒng)去管理它們。
虛擬機(jī):有vFPGA支持的hypervisor,或者稱為shell。
FPGA虛擬化的目標(biāo)和其他資源的虛擬化類似:單設(shè)備多租戶、資源管理、靈活性、隔離性、擴(kuò)展性、虛擬化性能損失最小化、安全性、可靠性和易用性。
FPGA和CPU、GPU的根本區(qū)別是應(yīng)用是硬件電路而非匯編指令。這帶來了大得多的切換開銷,不僅時(shí)間復(fù)用,空間也要復(fù)用。
對(duì)于FPGA相關(guān)工作的分類可以分為3種:resource level 、Node level 和 multi-node level。
3.1?Resource Level
分為可配置的(比如可以重新編程的邏輯陣列)和不可配置的(比如IP核)。
可配置overlays架構(gòu)部分:
Overlays架構(gòu)的思路是將FPGA編譯(配置)階段分成兩部分,將CAD部分提前,只有硬件部分inline執(zhí)行,來減少整體的重新配置時(shí)間。overlays的管理粒度可大可小,從軟核的虛擬化,到向量處理器,再到自定義處理單元(PE)再到細(xì)粒度的LUT單元。比較高層次的軟核、向量處理器對(duì)一般的軟件工程師更友好,不需要很多的硬件優(yōu)化。而PE粒度(或稱coarse-grained reconfigurable arrays, CGRAs)以一個(gè)代數(shù)運(yùn)算作為單元。又例如DRAGEN芯片專門針對(duì)DNA處理,overlay層允許生物領(lǐng)域?qū)<夷軌蛴肍PGA加速運(yùn)算。
overlay的二級(jí)制應(yīng)用之于configuration bit 類似于 Java JVM的字節(jié)碼之于機(jī)器碼。所以像字節(jié)碼到原生機(jī)器碼的轉(zhuǎn)換一樣,overlay應(yīng)用可以直接轉(zhuǎn)為overlay的FPGA配置。
不可配置的IO虛擬化部分:
通常用來管理多個(gè)應(yīng)用共享的IO資源,和其他虛擬化技術(shù)類似,虛擬化層可以用來提升安全/隔離性、隱藏IO操作的復(fù)雜性、監(jiān)視資源占用和保證QoS,有時(shí)也可以提升性能(比如加buffer)等。從根本上,IO虛擬化的概念支持和CPU、軟件系統(tǒng)類似,只是具體實(shí)現(xiàn)不同。對(duì)于FOGA而言,控制邏輯可以在軟件層,也可以是硬件模塊,軟件層次用來實(shí)現(xiàn)更靈活的配置、硬件部分加速IO訪問和管理。
這里的總結(jié)主要指的是一些host的工作可以卸載到FPGA,比如FPGA輔助NIC[7]、輔助SSD[8],甚至用于加速memcached這種通用KV cache的網(wǎng)絡(luò)[9, 10]。
3.2 Node Level
一般類似于虛擬機(jī)/多進(jìn)程中的設(shè)備虛擬化,分為多/單應(yīng)用組合上單/多FPGA四種[5]:

涉及到VMM、shell、調(diào)度等問題。
VMM型?將FPGA當(dāng)成一種IO資源,像其他虛擬機(jī)一樣以CPU為主體,這種情況下FPGA就像GPU一樣用,對(duì)軟件開發(fā)者更友好。
Shell型?以FPGA自身,給出與host通信、與其他IO設(shè)備通信、應(yīng)用管理等的設(shè)計(jì)。比如一種典型的設(shè)計(jì)是在FPGA的可配置部分,將管理部分和應(yīng)用部分分開,利用FPGA的partial reconfiguration特性主要重新配置FPGA的應(yīng)用部分,但這也會(huì)帶來很多開銷,包括讓長連線增加等。而且為實(shí)現(xiàn)多租戶增加的partial resion的數(shù)量也會(huì)導(dǎo)致更慢的運(yùn)算速度,所以找到一個(gè)合適的partial regions 大小和數(shù)量很重要!
調(diào)度問題?在FPGA上和CPU不太一樣,因?yàn)樯舷挛那袚Q和partial重配置需要占的時(shí)間很長,所以搶占式調(diào)度當(dāng)前不太現(xiàn)實(shí)。現(xiàn)在大多數(shù)方案基于非搶占調(diào)度,并且主要著眼時(shí)間的優(yōu)化,最近也開始有工作研究空間的優(yōu)化。
3.3 Multi-node Level
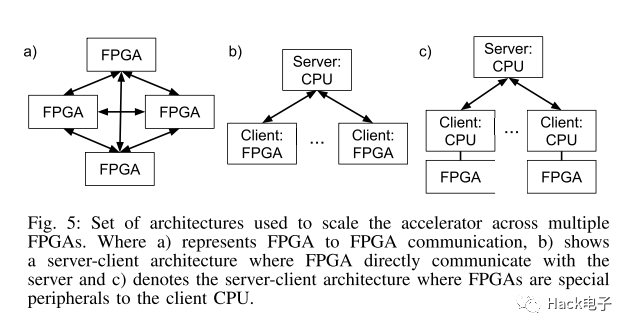
提供抽象,讓多個(gè)FPGA組合起來工作。大概架構(gòu)分為3種[5]:
審核編輯:湯梓紅












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論