 電子發(fā)燒友App
電子發(fā)燒友App


1.GPU加速:GPU是一種多核處理器,GPU起初是用來進(jìn)行圖形處理任務(wù)的,經(jīng)過長(zhǎng)時(shí)間的發(fā)展,GPU的發(fā)展是日趨復(fù)雜的,而且針對(duì)不同的領(lǐng)域也有不同。
當(dāng)GPU被用來進(jìn)行通用計(jì)算時(shí),就產(chǎn)生了一些通用的計(jì)算框架,比如說Opencl和CUDA。比如說高端GPU TItan系列,其頻率可以達(dá)到1Ghz,擁有330GB的帶寬,提供每秒極高的算力,但是功耗也達(dá)到了驚人的250W。對(duì)于嵌入式的GPU,比如說TegraX1,擁有256個(gè)處理核,帶寬為25GB/s,同樣在1Ghz的頻率下,算力仍可以達(dá)到近Titan的十分之一,但是功耗只有10W。
2.ASIC加速:這些芯片分為兩類:第一類,用來做訓(xùn)練和推理,這些芯片可以用來做DNN的訓(xùn)練,也可以做DNN的推理。第二類,用來做推理,這些ASICs用來運(yùn)行在GPU或者其他硬件上已經(jīng)訓(xùn)練好的模型,然后對(duì)訓(xùn)練過的網(wǎng)絡(luò)進(jìn)行修改,使得網(wǎng)絡(luò)可以運(yùn)行在不同的ASIC上。
3.FPGA加速:FPGA是一種可以重復(fù)配置的電路。在延遲方面,F(xiàn)PGA要比GPU更好。FPGA可以提供很高的帶寬同時(shí)也可以降低延遲。
1.2 FPGA實(shí)現(xiàn)
要實(shí)現(xiàn)某種運(yùn)算,其中一種方法就是將這種運(yùn)算以電路的方式實(shí)現(xiàn),而使用FPGA就是其中一個(gè)相對(duì)簡(jiǎn)單的方法,使用者可以將FPGA配置為所需要的電路。基于指令的硬件是通過軟件來實(shí)現(xiàn)的,而FPGA是通過專用硬件實(shí)現(xiàn)的。對(duì)于一些需要低延遲的算法,比如說智能駕駛,F(xiàn)PGA的延遲要比GPU更低。當(dāng)時(shí)用FPGA時(shí),可以將延遲控制在1微秒或者1微秒之外,但是對(duì)于CPU來說,延遲低于50微秒,性能就已經(jīng)很強(qiáng)了。除此之外,F(xiàn)PGA的定制化更強(qiáng),延遲能夠人為的控制,F(xiàn)PGA不需要操作系統(tǒng),內(nèi)部也不需要想CPU一樣通過總線進(jìn)行通行。
在FPGA中,可以連接任何的數(shù)據(jù)源,比如說網(wǎng)口或者傳感器,可以直接通過芯片的引腳就可以連接,這就和GPU與CPU形成了鮮明的對(duì)比(GPU和CPU與外界數(shù)據(jù)交互需要標(biāo)準(zhǔn)總線進(jìn)行連接)。
FPGA的直連技術(shù)可以為數(shù)據(jù)提供很高的帶寬,同時(shí)也降低了時(shí)延。
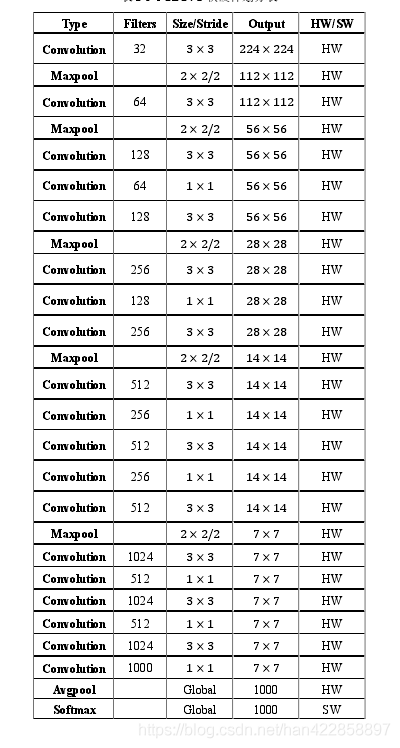
2、為什么用FPGA來加速YOLOV2
對(duì)于卷積核和池化的運(yùn)算來說,因?yàn)槭蔷仃囘\(yùn)算,這就需要相當(dāng)高的算力。而由于卷積和池化運(yùn)算都是流式運(yùn)算,所以將他們放在FPGA中實(shí)現(xiàn)從而進(jìn)行加速是一個(gè)很好的選擇。對(duì)于YOLOV2中的部分運(yùn)算,比如說計(jì)算坐標(biāo)圖像的預(yù)處理等,都是一些非流式運(yùn)算,或者是標(biāo)準(zhǔn)運(yùn)算,這些運(yùn)算適合放在ARM中進(jìn)行,于是將YOLOV2中的運(yùn)算做一下劃分,充分利用軟硬件協(xié)同的優(yōu)勢(shì),從而對(duì)整個(gè)算法進(jìn)行加速。
FPGA:卷積層和池化層
ARM:Softmax
3、FPGA簡(jiǎn)介
3.1 FPGA的基本結(jié)構(gòu)基本構(gòu)成:CLB(可配置邏輯塊),IOS(輸入輸出模塊),IR(互聯(lián)資源)
FPGA的功能是由SRAM中的數(shù)據(jù)類配置的,所以大部分FPGA芯片中都是采用查找表結(jié)構(gòu)的。FPGA中組合邏輯使用小型LUT實(shí)現(xiàn)的,這些LUT輸出端連接到D觸發(fā)器的輸入端,D在連接到其他邏輯電路或者是驅(qū)動(dòng)IO來對(duì)其進(jìn)行驅(qū)動(dòng)。
FPGA中的邏輯是通過加載編程數(shù)據(jù)來實(shí)現(xiàn)的,這些編程數(shù)據(jù)通過內(nèi)部靜態(tài)存儲(chǔ)單元來進(jìn)行加載。存儲(chǔ)單元的值可以配置邏輯單元各個(gè)模塊的連接通路,以及邏輯單元所實(shí)現(xiàn)的功能,也可以配置IO的功能以及電氣鼠性等,這些最終構(gòu)成了一個(gè)可以實(shí)現(xiàn)目標(biāo)功能的FPGA系統(tǒng)。
3.2 FPGA的相對(duì)優(yōu)勢(shì):
與DSP和MCU相比,F(xiàn)PGA的運(yùn)算速度較快,實(shí)現(xiàn)控制功能更加靈活,與傳統(tǒng)的CPLD相比,F(xiàn)PGA更適合做一些規(guī)模更大邏輯更復(fù)雜的設(shè)計(jì)。
(1).FPGA有六部分構(gòu)成:可編程CLB,可編程IO,布線資源,嵌入式RAM,專用迎合以及內(nèi)嵌功能模塊。CLPD功能更加簡(jiǎn)單,構(gòu)成:可編程IO,基本邏輯單元,布線pool。2).FPGA更容易實(shí)現(xiàn)時(shí)序邏輯,CPLD更適合大規(guī)模組合邏輯。
(3).FPGA連線資源非常豐富,且CLB的利用率很高。
(4)。同專用集成電路比,F(xiàn)PGA更加靈活,開發(fā)周期更短,可以降低成本,同時(shí)也可以保證保密性和可靠性。
4、PYNQ開發(fā)框架與HLS加速理論
4.1 PYNQ
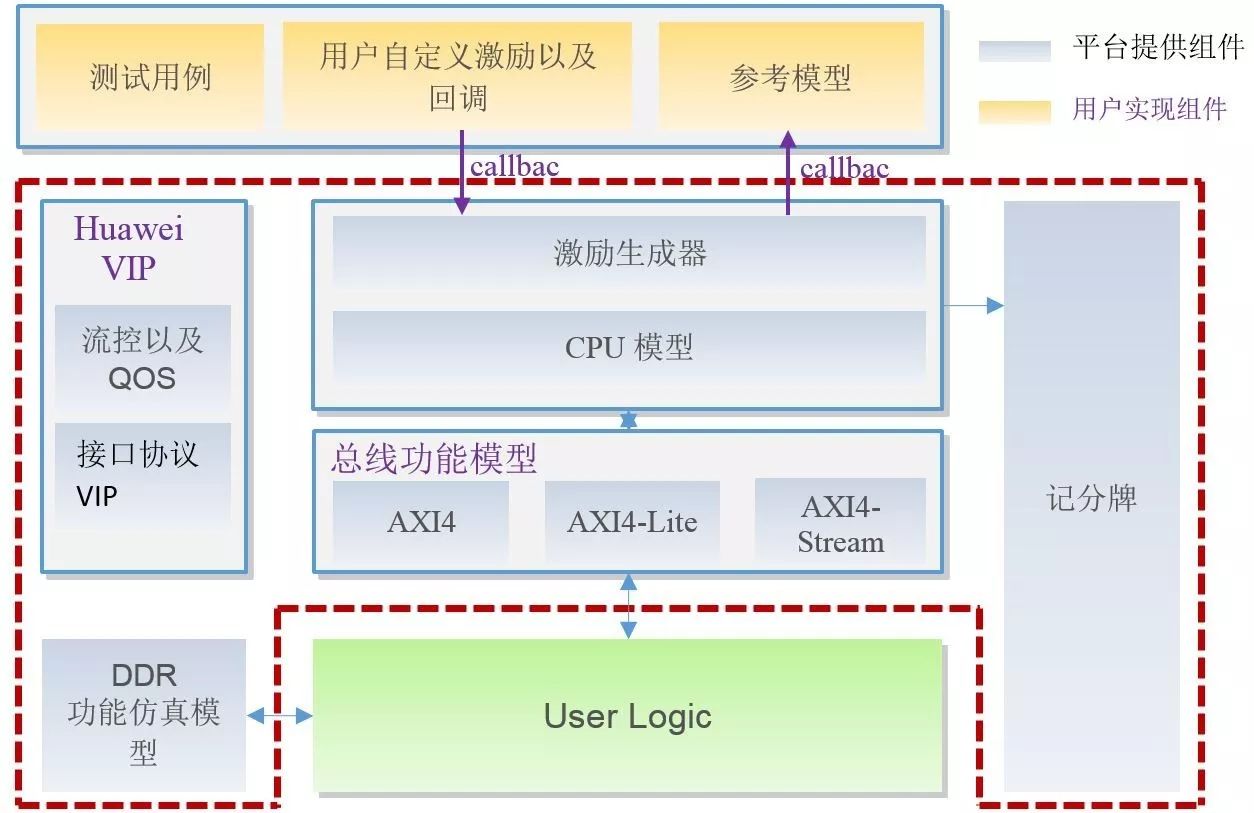
傳統(tǒng)的FPGA的框架有兩種,一種是FPGA與CPU互聯(lián)的,另一種是FPGA與RAM互聯(lián)的。但是這兩種開發(fā)對(duì)于然間人員來說很不友好,而PYNQ就很好的解決了這個(gè)問題,。PYNQ可以在ZYNQ上面運(yùn)行,ZYNQ包含PL和PS部分,PS部分是ARM的處理器,上面可以運(yùn)行LINUX系統(tǒng),操作系統(tǒng)上運(yùn)行ptyhon。PL部分是可編程邏輯資源,在開發(fā)過程中,首先在PL端設(shè)計(jì)IP核,將IP核配置成為AXI總線形式,然后在PS中對(duì)驅(qū)動(dòng)函數(shù)進(jìn)行調(diào)用。
PYQN是一種全新的開發(fā)框架,能夠用PYTHON對(duì)其進(jìn)行快速的FPGA部署,在部署過程中不用研究硬件的實(shí)現(xiàn)細(xì)節(jié)。
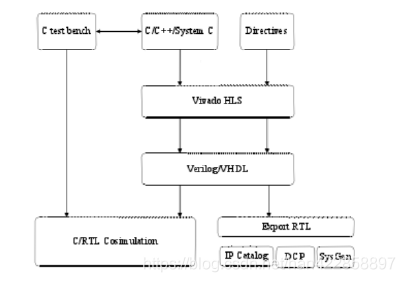
4.2 HLS
開發(fā)流程是基于C語言,能夠節(jié)約用戶大量的時(shí)間。其重要流程包括:C開發(fā),C仿真,C綜合以及RTL綜合等。
4.2.1 用HLS加速IP
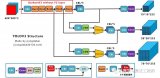
內(nèi)層并行現(xiàn)實(shí)化:在FPGA實(shí)現(xiàn)深度學(xué)習(xí)算法中的一層,在計(jì)算時(shí)候?qū)@一層進(jìn)行復(fù)用,計(jì)算完一層以后將數(shù)據(jù)緩存到片外的DDR中,當(dāng)進(jìn)行下一層計(jì)算式,再將數(shù)據(jù)讀入運(yùn)算單元中,在這個(gè)過程中需要FPGA的ARM來對(duì)IP核進(jìn)行配置,包括輸入輸出通道的數(shù)量,卷積核的尺寸等。配置完成后,IP和就可以進(jìn)行相應(yīng)層的運(yùn)算。
實(shí)現(xiàn)卷積IP核的經(jīng)典架構(gòu)
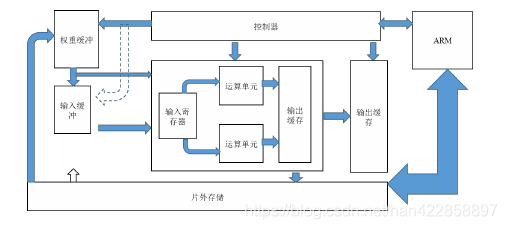
這個(gè)系統(tǒng)包含了片外DDR,ARM處理器,控制器,運(yùn)算單元以及各種緩沖器。緩存器:輸入輸出,權(quán)重緩沖等。輸入的圖像首先要加載帶輸入的寄存器中,然后通過運(yùn)算單元執(zhí)行卷積操作,卷積操作是通過多個(gè)運(yùn)算單元來運(yùn)算的,以保證運(yùn)算的速度。在進(jìn)行卷積運(yùn)算時(shí),第一季輸出緩存中的數(shù)據(jù)會(huì)被輸出到第二級(jí)輸出緩存,在當(dāng)前層運(yùn)算完之后,運(yùn)算結(jié)構(gòu)就會(huì)成為下一級(jí)的運(yùn)算輸出,用這樣的方式實(shí)現(xiàn)網(wǎng)絡(luò)每一層的加速。
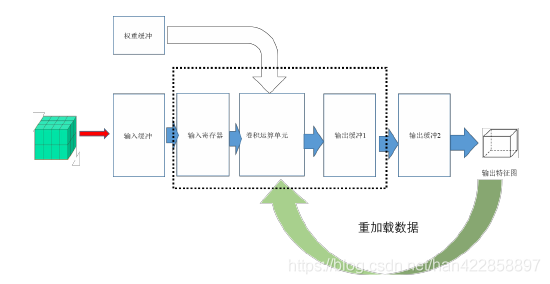
如上圖所展示的流程圖,可以實(shí)現(xiàn)網(wǎng)絡(luò)在單層內(nèi)部運(yùn)算的并行優(yōu)化,不必將整個(gè)網(wǎng)絡(luò)全部展開,可以獎(jiǎng)勵(lì)網(wǎng)絡(luò)的資源占用率,進(jìn)而降低功耗,實(shí)現(xiàn)了新跟你乖面積以及功耗的平衡。如果想藥實(shí)現(xiàn)單層網(wǎng)絡(luò)的加速效果,就需要在層的內(nèi)部實(shí)現(xiàn)流水。所以就需要一種數(shù)據(jù)拆分機(jī)制,將數(shù)據(jù)分為多個(gè)小塊,然后并行去處理這些數(shù)據(jù)。
將圖像分割為多個(gè)小塊,每個(gè)小塊的尺寸為Tr X Tc X Tn,而這一塊經(jīng)過計(jì)算之后得到的結(jié)果應(yīng)該是卷積計(jì)算的部分和,尺寸為Th X Tl X Tm,在這個(gè)運(yùn)算過程中,所欲要的權(quán)重尺寸是K X K X Tn X Tm。在處理完這一塊數(shù)據(jù)后,再處理這個(gè)特征圖的下一塊數(shù)據(jù)。這樣按快處理,直到本層的數(shù)據(jù)處理完成。
4.2.2 循環(huán)優(yōu)化HLS針對(duì)循環(huán)的優(yōu)化指令很多,這里只使用Loop Pipeline和Loop Unrolling。
Loop Pipeline的作用是對(duì)循環(huán)的進(jìn)行流水線化的并行處理,這種方式可以讓兩輪循環(huán)執(zhí)行時(shí)間重疊,使得在本輪循環(huán)過程中下一輪循環(huán)也可以同時(shí)執(zhí)行。
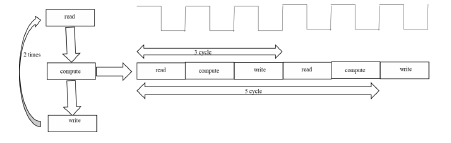
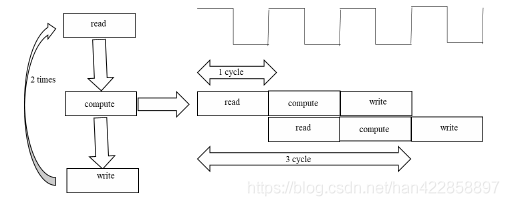
上述圖片是未經(jīng)過流水化處理和經(jīng)過處理的運(yùn)算步驟,可以清楚地看出,如果以兩次迭代為例,未經(jīng)過處理的運(yùn)算需要經(jīng)過5個(gè)時(shí)鐘周期才能完成運(yùn)算,而經(jīng)過流誰化處理的運(yùn)算僅僅需要三個(gè)時(shí)鐘周期。
Loop Unorlling在沒有進(jìn)行循環(huán)優(yōu)化之前,循環(huán)的運(yùn)行按照默認(rèn)設(shè)置來操作的。而當(dāng)進(jìn)行循環(huán)展開后,循環(huán)的電路會(huì)被設(shè)置為N份,N一般有HLS中的指令factor來指定。比如說factor為2時(shí),此時(shí)的迭代次數(shù)為8的話,那么迭代會(huì)被分為4次進(jìn)行,內(nèi)次是2個(gè)循環(huán)一次實(shí)現(xiàn)的。
4.3 硬件系統(tǒng)的構(gòu)建
4.3.1 PL部分PL部分使用HLS來實(shí)現(xiàn)卷積神經(jīng)網(wǎng)絡(luò)。
硬件配置如下:

最后將PL端生成的bitfile加載到FPGA中,最后在PC上觀察吃力后的圖像,進(jìn)行結(jié)果分析與統(tǒng)計(jì)。
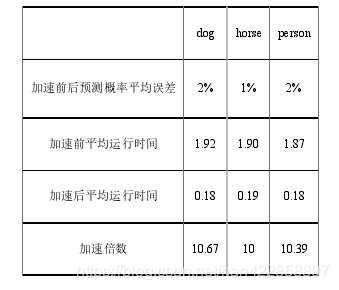
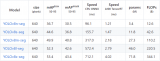
5、實(shí)驗(yàn)結(jié)果
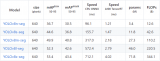
加速前后的時(shí)間對(duì)比。
















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論