 電子發(fā)燒友App
電子發(fā)燒友App


了解RTOS任務(wù)
超級循環(huán)編程范式通常是嵌入式系統(tǒng)工程師最先接觸到的編程方法之一。用超級循環(huán)實現(xiàn)的程序有一個單一的頂層循環(huán),在系統(tǒng)需要執(zhí)行的各種功能之間循環(huán)。這些簡單的while循環(huán)很容易創(chuàng)建和理解(當它們很小的時候)。在FreeRTOS中,任務(wù)與超級循環(huán)非常相似--主要區(qū)別在于,系統(tǒng)可以有一個以上的任務(wù),但只有一個超級循環(huán)。
在本章中,我們將仔細研究超級循環(huán)和用它們實現(xiàn)一定程度的并行性的不同方法。之后,將對超級循環(huán)和任務(wù)進行比較,并從理論上介紹任務(wù)執(zhí)行的思維方式。最后,我們將看看任務(wù)是如何通過RTOS內(nèi)核實際執(zhí)行的,并比較兩種基本的調(diào)度算法。
超級循環(huán)編程介紹
所有的嵌入式系統(tǒng)都有一個共同的特性--它們沒有退出點。由于其性質(zhì),嵌入式代碼通常被期望總是可用的--靜靜地在后臺運行,處理內(nèi)務(wù)工作,并隨時準備接受用戶的輸入。與旨在啟動和停止程序的桌面環(huán)境不同,如果微控制器退出main()函數(shù),它就沒有任何事情可做。如果發(fā)生這種情況,很可能是整個設(shè)備已經(jīng)停止運作。由于這個原因,嵌入式系統(tǒng)中的main()函數(shù)從不返回。與應(yīng)用程序不同的是,應(yīng)用程序是由其主機操作系統(tǒng)啟動和停止的,大多數(shù)基于嵌入式MCU的應(yīng)用程序在上電時開始,在系統(tǒng)斷電時突然結(jié)束。由于這種突然的關(guān)閉,嵌入式應(yīng)用程序通常沒有任何通常與應(yīng)用程序相關(guān)的關(guān)閉任務(wù),如釋放內(nèi)存和資源。
下面的代碼代表了超級循環(huán)的基本思想:
void main ( void )
{
while(1)
{
func1();
func2();
func3();
//do useful stuff, but don't return
//(otherwise, where would we go. . what would we do. . .?!)
}
}
雖然非常簡單,但前面的代碼有許多值得指出的特點。while循環(huán)從不返回--它一直在執(zhí)行同樣的三個函數(shù)(這是故意的)。這三個看似無害的函數(shù)調(diào)用可以在實時系統(tǒng)中隱藏一些令人討厭的驚喜。
基本的超級循環(huán)
這個從不返回的主循環(huán)一般被稱為超級循環(huán)。超級循環(huán)總是很有趣,因為它可以控制系統(tǒng)中的大多數(shù)事情--除非超級循環(huán)使之發(fā)生,否則下圖中的任何事情都無法完成。這種類型的設(shè)置非常適合于非常簡單的系統(tǒng),只需要執(zhí)行一些不需要花費大量時間的任務(wù)。基本的超級循環(huán)結(jié)構(gòu)非常容易編寫和理解;如果你想解決的問題可以用一個簡單的超級循環(huán)來完成,那么就使用一個簡單的超級循環(huán)。下面是前面介紹的代碼的執(zhí)行流程--每個函數(shù)都是按順序調(diào)用的,而且循環(huán)永不退出:
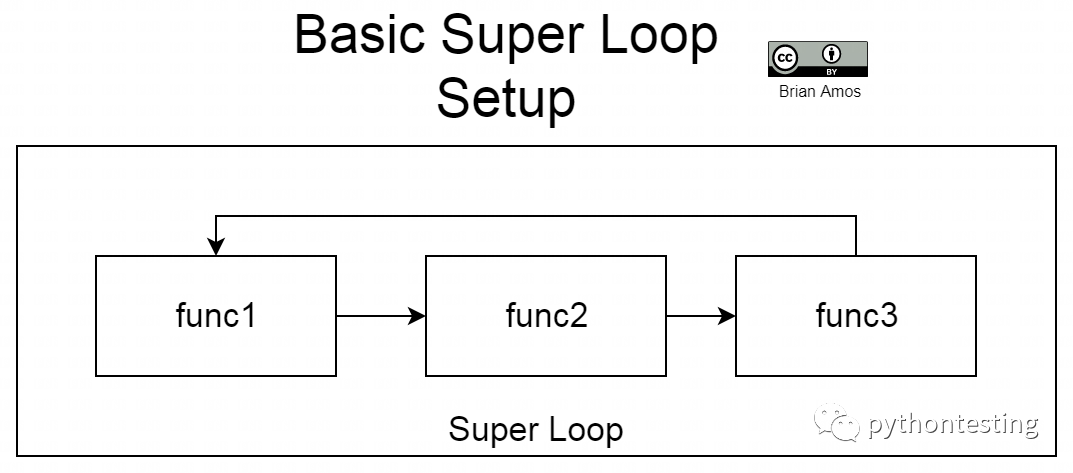
實時系統(tǒng)中的超級環(huán)路
當簡單的超級循環(huán)快速運行時(通常是因為它們的功能/責任有限),它們的響應(yīng)速度相當快。然而,超級循環(huán)的簡單性可能是一種祝福,也是一種詛咒。由于每個函數(shù)總是跟在前面的函數(shù)后面,它們總是以相同的順序被調(diào)用,并且完全相互依賴。一個函數(shù)引入的任何延遲都會傳播到下一個函數(shù),從而導(dǎo)致執(zhí)行該循環(huán)迭代的總時間增加(如下圖所示)。如果func1在循環(huán)中執(zhí)行一次需要10毫秒,而下一次需要100毫秒,那么func2在循環(huán)中第二次被調(diào)用的時間就不會像第一次那樣快:

讓我們更深入地看一下這個問題。在上圖中,func3負責檢查一個代表外部事件的標志的狀態(tài)(這個事件是一個信號的上升沿)。func3檢查標志的頻率取決于func1和func2執(zhí)行的時間。一個設(shè)計良好、反應(yīng)靈敏的超級循環(huán)通常會執(zhí)行得非常快,檢查事件的頻率要比事件發(fā)生的頻率高(呼出B)。當外部事件確實發(fā)生時,該循環(huán)直到func3的下一次執(zhí)行才檢測到該事件(呼出A、C和D)。注意,在事件產(chǎn)生和func3檢測到它之間有一個延遲。還要注意的是,這個延遲并不總是一致的:這種時間上的差異被稱為抖動。
在許多基于超級循環(huán)的系統(tǒng)中,與被輪詢的緩慢發(fā)生的事件相比,超級循環(huán)的執(zhí)行速度非常高。我們在頁面上沒有足夠的空間來顯示循環(huán)在檢測到事件之間執(zhí)行數(shù)百次(或數(shù)千次)的迭代!這就是所謂的抖動!
如果系統(tǒng)在響應(yīng)事件時有一個已知的最大抖動量,它被認為是確定性的。也就是說,它將在事件發(fā)生后的指定時間內(nèi)對事件作出可靠的反應(yīng)。高水平的確定性對于實時系統(tǒng)中的時間關(guān)鍵型組件是至關(guān)重要的,因為如果沒有它,系統(tǒng)可能無法及時響應(yīng)重要的事件。
考慮到循環(huán)反復(fù)檢查硬件標志的事件(這被稱為輪詢)。循環(huán)越緊密,標志被檢查的速度就越快--當標志經(jīng)常被檢查時,代碼將對感興趣的事件做出更多的反應(yīng)。如果我們有需要及時采取行動的事件,我們可以只寫非常緊密的循環(huán),等待重要事件的發(fā)生。這種方法是有效的--但前提是該事件是系統(tǒng)唯一感興趣的事情。如果整個系統(tǒng)唯一的責任就是觀察該事件(沒有后臺I/O、通信等),那么這是一個有效的方法。這種類型的情況在今天復(fù)雜的現(xiàn)實世界的系統(tǒng)中很少發(fā)生。響應(yīng)性差是單純基于輪詢的系統(tǒng)的局限性。接下來,我們將看看如何在我們的超級循環(huán)中獲得更多的并行性。
用超級循環(huán)實現(xiàn)并行操作
盡管基本的超級循環(huán)只能按順序通過函數(shù),但仍有辦法實現(xiàn)并行化。單片機有一些不同類型的專用硬件,它們被設(shè)計用來減輕CPU的一些負擔,同時還能實現(xiàn)高度響應(yīng)的系統(tǒng)。本節(jié)將介紹這些系統(tǒng)以及如何在超級循環(huán)風(fēng)格的程序中使用它們。
中斷
對單一事件進行輪詢不僅在CPU周期和功率方面是浪費的--它還會導(dǎo)致系統(tǒng)對其他事物沒有反應(yīng),這通常是應(yīng)該避免的。那么,我們怎樣才能讓單核處理器并行地做事情呢?嗯,我們不能--畢竟只有一個處理器。...但由于我們的處理器很可能每秒運行數(shù)百萬條指令,所以有可能讓它執(zhí)行足夠接近于并行的事情。MCU還包括用于生成中斷的專用硬件。中斷向MCU提供信號,使其在事件發(fā)生時直接跳到中斷服務(wù)程序(ISR interrupt service routine )。這是一個非常關(guān)鍵的功能,ARM Cortex-M內(nèi)核為其提供了一個標準化的外設(shè),稱為嵌套向量中斷控制器(NVIC nested vector interrupt controller。NVIC提供了一種處理中斷的通用方法。這個術(shù)語的嵌套部分標志著即使是中斷也可以被其他具有更高優(yōu)先級的中斷打斷。這相當方便,因為它允許我們將系統(tǒng)中時間最關(guān)鍵的部分的延遲和抖動量降到最低。
那么,中斷如何融入超級循環(huán),以更好地實現(xiàn)并行活動的假象?ISR內(nèi)部的代碼通常被保持得盡可能短,以盡量減少在中斷中花費的時間。這一點很重要,有幾個原因。如果中斷發(fā)生得很頻繁,而且ISR包含很多指令,那么ISR就有可能在被再次調(diào)用之前不返回。對于UART(universal asynchronous receiver / transmitter)或SPI(serial peripheral interface)等通信外設(shè)來說,這將意味著數(shù)據(jù)丟失(這顯然是不可取的)。保持代碼簡短的另一原因是其他中斷也需要得到服務(wù),這就是為什么把任何責任推給不在ISR上下文中運行的代碼是個好主意。
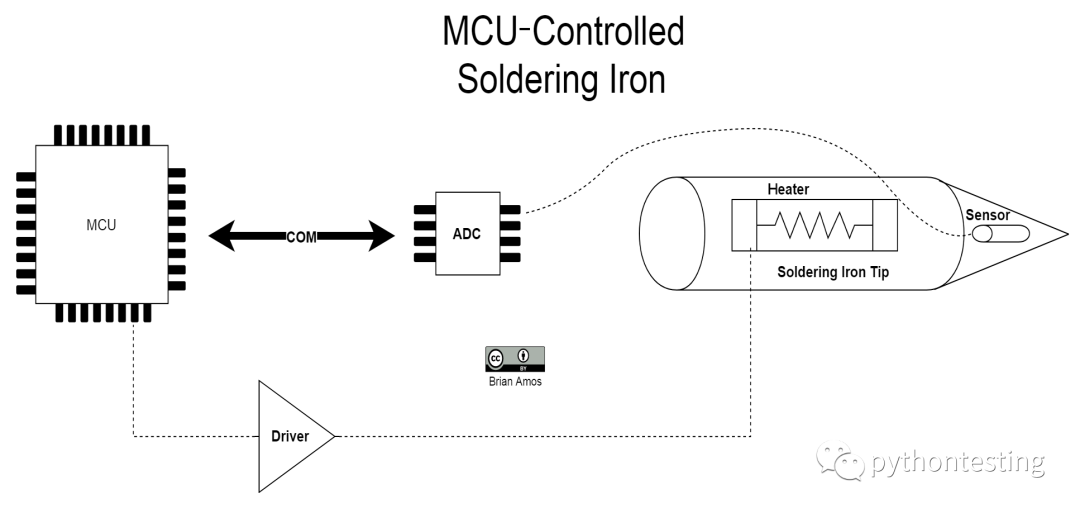
為了快速了解ISR是如何導(dǎo)致抖動的,讓我們看看簡單的例子:外部模數(shù)轉(zhuǎn)換器(ADC analog to digital converter )向MCU發(fā)出信號,表示已經(jīng)采集了讀數(shù),轉(zhuǎn)換結(jié)果準備傳送給MCU(參考這里的硬件圖):

在ADC硬件中,有一個引腳專門用來指示模擬值的讀數(shù)已被轉(zhuǎn)換為數(shù)字表示,并準備傳輸給MCU。然后,MCU將通過通信介質(zhì)(圖中的COM)啟動傳輸。
接下來,讓我們看看相對于轉(zhuǎn)換準備線的上升沿,ISR調(diào)用如何隨著時間的推移而相互疊加。下圖顯示了六個不同的ISR被調(diào)用以響應(yīng)信號的上升沿的情況。硬件中的上升沿與固件中的ISR被調(diào)用之間的少量時間是最小延遲。ISR響應(yīng)中的抖動是許多不同周期中延遲的差異:

有不同的方法來最小化關(guān)鍵ISR的延時和抖動。在基于ARM Cortex-M的MCU中,中斷優(yōu)先級是靈活的--在運行時可以為單個中斷源分配不同的優(yōu)先級。重新確定中斷優(yōu)先級的能力是確保系統(tǒng)中最重要的部分在需要時獲得CPU的一種方式。
如前所述,保持在中斷中執(zhí)行的代碼量盡可能短是很重要的,因為在ISR中的代碼將優(yōu)先于任何不在ISR中的代碼(例如main())。此外,較低優(yōu)先級的ISR不會被執(zhí)行,直到較高優(yōu)先級的ISR中的所有代碼都被執(zhí)行,并且ISR退出--這就是為什么保持ISR的簡短是重要的。嘗試限制ISR的責任(以及因此而產(chǎn)生的代碼)總是好主意。
當多個中斷被嵌套時,它們不會完全返回--實際上ARM Cortex M處理器有非常有用的功能,叫做中斷-尾部鏈。如果處理器檢測到一個中斷即將退出,但另一個中斷正在等待,那么下一個ISR將被執(zhí)行,而處理器不會完全恢復(fù)中斷前的狀態(tài),這進一步減少了延遲。
中斷和超級循環(huán)
在ISR中實現(xiàn)最小指令和責任的一種方法是在ISR中做盡可能少的工作,然后設(shè)置標志,由超級循環(huán)中運行的代碼來檢查。這樣一來,中斷就可以盡快得到服務(wù),而不需要整個系統(tǒng)都致力于等待該事件。在下圖中,注意到在最后由func3處理之前,中斷是如何被多次產(chǎn)生的。
根據(jù)該中斷試圖實現(xiàn)的具體目標,它通常會從相關(guān)的外設(shè)中獲取一個值并將其推入數(shù)組(或從數(shù)組中獲取值并將其送入外設(shè)寄存器)。在我們的外部ADC的情況下,ISR(每次ADC執(zhí)行轉(zhuǎn)換時觸發(fā))將出去到ADC,傳輸數(shù)字化的讀數(shù),并將其存儲在RAM中,設(shè)置標志,表明一個或多個值已經(jīng)準備好進行處理。這使得中斷可以被多次服務(wù),而不涉及高層代碼:

在通信外設(shè)傳輸大塊數(shù)據(jù)的情況下,可以用數(shù)組作為隊列來存儲要傳輸?shù)捻椖俊T谡麄€傳輸結(jié)束時,可以設(shè)置標志來通知主循環(huán)的完成。有很多例子可以說明隊列值是合適的情況。例如,如果需要對數(shù)據(jù)塊進行一些處理,首先收集數(shù)據(jù),然后在中斷之外一起處理整個數(shù)據(jù)塊,這往往是有利的。中斷驅(qū)動的方法并不是實現(xiàn)這種阻斷數(shù)據(jù)的唯一方法。
DMA
還記得處理器不可能真正做到并行的說法嗎?這仍然是事實。然而......現(xiàn)代的MCU不僅僅包含一個處理核心。當我們的處理核心在處理指令時,還有許多其他硬件子系統(tǒng)在MCU內(nèi)努力工作。這些努力工作的子系統(tǒng)之一被稱為直接內(nèi)存訪問控制器(DMA Direct Memory Access Controller):

前面的圖是非常簡化的硬件框圖,顯示了從RAM到UART外設(shè)的兩個不同的數(shù)據(jù)路徑的視圖。
在沒有DMA的情況下,從UART接收字節(jié)流,來自UART的信息將進入UART寄存器,被CPU讀取,然后推送到RAM進行存儲:
- CPU必須檢測到何時收到單獨的字節(jié)(或字),要么通過輪詢UART寄存器標志,要么通過設(shè)置中斷服務(wù)例程,當一個字節(jié)準備好時就啟動。
- 字節(jié)從UART傳輸后,CPU可以將其放入RAM進行進一步處理。
- 步驟1和2重復(fù)進行,直到收到整個信息。
當DMA被用在同樣的場景中時,會發(fā)生以下情況:
- CPU為傳輸配置DMA控制器和外圍設(shè)備。
- DMA控制器負責UART外設(shè)和RAM之間的所有傳輸。這不需要CPU的干預(yù)。
- 當整個傳輸完成時,CPU會得到通知,它可以直接處理整個字節(jié)流。
大多數(shù)程序員發(fā)現(xiàn)DMA幾乎是神奇的,如果他們習(xí)慣于處理超級循環(huán)和ISR。控制器被配置為在外設(shè)需要時向外設(shè)傳輸內(nèi)存塊,然后在傳輸完成時提供通知(通常是通過一個中斷)--就是這樣!這就是DMA!
當然,這種便利也是有代價的。最初設(shè)置DMA傳輸確實需要一些時間,所以對于小的傳輸,實際上可能比使用中斷或輪詢的方法要花費更多的CPU時間來設(shè)置傳輸。
還有一些需要注意的地方:每個MCU都有特定的限制,所以在指望DMA對系統(tǒng)的關(guān)鍵設(shè)計組件的可用性之前,一定要閱讀數(shù)據(jù)手冊、參考手冊和勘誤表的細節(jié):
MCU內(nèi)部總線的帶寬限制了可以可靠地放在單一總線上的對帶寬要求高的外設(shè)的數(shù)量。
偶爾,映射到外設(shè)的DMA通道的有限可用性也使設(shè)計過程復(fù)雜化。
這些類型的原因就是為什么要讓所有的團隊成員參與到嵌入式系統(tǒng)的早期設(shè)計中來,而不是直接把它扔到墻上。
DMA對于有效地訪問大量的外設(shè)是很好的,使我們有能力為系統(tǒng)添加越來越多的功能。然而,當我們開始向超級循環(huán)添加越來越多的代碼模塊時,子系統(tǒng)之間的相互依賴關(guān)系也變得更加復(fù)雜。在下一節(jié)中,我們將討論為復(fù)雜系統(tǒng)擴展超級循環(huán)的挑戰(zhàn)。
擴展超級循環(huán)
現(xiàn)在已經(jīng)有了能夠可靠地處理中斷的響應(yīng)系統(tǒng)。也許我們已經(jīng)配置了DMA控制器來處理通信外圍設(shè)備的繁重工作。為什么我們需要實時操作系統(tǒng)?嗯,你完全有可能不需要! 如果系統(tǒng)只處理有限的任務(wù),而且沒有特別復(fù)雜或耗時的,那么可能就不需要比超級循環(huán)更復(fù)雜的東西。
但是,如果系統(tǒng)還要負責生成用戶界面(UI),運行復(fù)雜的耗時的算法,或者處理復(fù)雜的通信棧,那么這些任務(wù)很可能要花費非同小可的時間。如果帶有大量動畫的華麗奪目的用戶界面因為MCU正在處理從關(guān)鍵的傳感器收集數(shù)據(jù)而開始有點結(jié)巴,那也沒什么大不了的。要么動畫可以回調(diào),要么取消,而實時系統(tǒng)的重要部分則保持原樣。但是,如果那個動畫看起來仍然非常好,即使有一些來自傳感器的數(shù)據(jù)被遺漏,又會發(fā)生什么呢?
在我們的行業(yè)中,這個問題每天都有各種不同的方式。有時,如果系統(tǒng)設(shè)計得足夠好,丟失的數(shù)據(jù)會被檢測到并被標記出來(但它不能被恢復(fù):它永遠消失了)。如果設(shè)計團隊真的很幸運,它甚至可能在內(nèi)部測試中以這種方式失敗。然而,在許多情況下,遺漏的傳感器數(shù)據(jù)將完全沒有被注意到,直到有人注意到其中一個讀數(shù)似乎有點偏離......有時。如果每個人都很幸運,關(guān)于粗略讀數(shù)的錯誤報告可能包括一個提示,即它似乎只在有人在前面板上(玩那些花哨的動畫)時發(fā)生。這至少會給被指派去調(diào)試這個問題的可憐的固件工程師一個提示--但我們往往甚至沒有那么幸運。
這些是需要實時操作系統(tǒng)的系統(tǒng)類型。保證時間最緊迫的任務(wù)在必要時總是在運行,并在有空閑時間時將低優(yōu)先級的任務(wù)調(diào)度到運行,這是搶占式調(diào)度器的一個強項。在這種類型的設(shè)置中,關(guān)鍵的傳感器讀數(shù)可以被推到他們自己的任務(wù)中,并分配一個高優(yōu)先級--當需要處理傳感器的時候,有效地中斷了系統(tǒng)中的任何其他任務(wù)(除了ISR)。那個復(fù)雜的通信堆棧可以被分配一個比關(guān)鍵傳感器更低的優(yōu)先級。最后,具有花哨動畫的華麗用戶界面得到了剩余的處理器周期。它可以自由地執(zhí)行任意多的滑動阿爾法混合動畫,但只有在處理器沒有其他更好的事情可做的時候。
RTOS任務(wù)與超級循環(huán)相比較
到目前為止,我們只是非常隨意地提到了任務(wù),但任務(wù)到底是什么?思考任務(wù)的簡單方法是,它只是另一個主循環(huán)。在一搶占式RTOS中,任務(wù)和超級循環(huán)之間有兩個主要區(qū)別:
-
每個任務(wù)都收到它自己的私有堆棧。與共享系統(tǒng)堆棧的main中的超級循環(huán)不同,任務(wù)收到自己的堆棧,系統(tǒng)中的其他任務(wù)不會使用。這允許每個任務(wù)擁有自己的調(diào)用堆棧,而不干擾其他任務(wù)。
-
每個任務(wù)都有分配給它的優(yōu)先級。這個優(yōu)先級允許調(diào)度員決定哪個任務(wù)應(yīng)該運行(目標是確保系統(tǒng)中最高優(yōu)先級的任務(wù)總是在做有用的工作)。
考慮到這兩個特點,每個任務(wù)都可以被編程,好像它是處理器唯一要做的事情。你有一個你想看的單一標志和一些計算的華美的動畫要攪和嗎?沒問題:只需對任務(wù)進行編程,并給它分配合理的優(yōu)先級,相對于系統(tǒng)的其他功能而言。搶占式調(diào)度器將始終確保最重要的任務(wù)在有工作要做時被執(zhí)行。當一個較高優(yōu)先級的任務(wù)不再有有用的工作要做,并且它正在等待系統(tǒng)中的其他東西時,較低優(yōu)先級的任務(wù)將被切換到上下文并允許運行。
用RTOS任務(wù)實現(xiàn)并行操作
早些時候,我們看了在三個函數(shù)中循環(huán)的超級循環(huán)。現(xiàn)在讓我們把這三個函數(shù)中的每一個移到自己的任務(wù)中。我們將用這三個簡單的任務(wù)來研究以下內(nèi)容:
-
理論上的任務(wù)編程模型: 如何在理論上描述這三個任務(wù)
-
實際的輪流調(diào)度: 任務(wù)在使用輪回調(diào)度算法執(zhí)行時是什么樣子的
-
實際的搶占式調(diào)度: 使用搶占式調(diào)度執(zhí)行的任務(wù)是什么樣子的?
在現(xiàn)實世界的程序中,每個任務(wù)幾乎都沒有單一的函數(shù);我們只是把它作為類似于前面的過于簡單的超級循環(huán)的例子。
理論上的任務(wù)編程模型
下面是使用超級循環(huán)來執(zhí)行三個函數(shù)的偽代碼。同樣的三個函數(shù)也包含在基于任務(wù)的系統(tǒng)中--每個RTOS任務(wù)(在右邊)包含與左邊的超級循環(huán)的函數(shù)相同的功能。當我們討論使用超級循環(huán)與使用調(diào)度器的任務(wù)驅(qū)動方法時,代碼執(zhí)行方式的差異時,這點將被繼續(xù)使用:

你可能會注意到超級循環(huán)實現(xiàn)和RTOS實現(xiàn)之間的直接區(qū)別是無限的while循環(huán)的數(shù)量。在超級循環(huán)的實現(xiàn)中,只有一個無限的while循環(huán)(在main()中),但是每個任務(wù)都有自己的無限的while循環(huán)。
在超級循環(huán)中,在調(diào)用下一個函數(shù)之前,被超級循環(huán)執(zhí)行的三個函數(shù)分別運行到完成,然后循環(huán)繼續(xù)到下一個迭代(如下圖所示):

在RTOS的實現(xiàn)中,每個任務(wù)本質(zhì)上是它自己的小的無限的while循環(huán)。超級循環(huán)中的函數(shù)總是一個接一個地被調(diào)用(由超級循環(huán)中的邏輯協(xié)調(diào)),而任務(wù)可以簡單地被認為是在調(diào)度器啟動后的所有并行執(zhí)行。下面是一個執(zhí)行三個任務(wù)的實時操作系統(tǒng)的圖示:

在圖中,你會注意到每個while循環(huán)的大小是不一樣的。這是使用并行執(zhí)行任務(wù)的調(diào)度器相對于超級循環(huán)的許多好處之一--程序員不需要立即關(guān)注最長的執(zhí)行循環(huán)的長度會拖累其他更緊密的循環(huán)。圖中描述了任務(wù)2的循環(huán)比任務(wù)1長很多。在超級循環(huán)系統(tǒng)中,這將導(dǎo)致func1的功能執(zhí)行頻率降低(因為超級循環(huán)需要先執(zhí)行func1,然后是func2,最后是func3)。在基于任務(wù)的編程模型中,情況并非如此--每個任務(wù)的循環(huán)可以被認為是與系統(tǒng)中的其他任務(wù)隔離的--而且它們都是并行運行的。
這種隔離和感知的并行執(zhí)行是使用實時操作系統(tǒng)的一些好處;它為程序員減輕了一些復(fù)雜性。所以,這是概念化任務(wù)的最簡單的方法--它們只是獨立的無限的while循環(huán),都是平行執(zhí)行的......在理論上。在現(xiàn)實中,事情并沒有這么簡單。在接下來的兩節(jié)中,我們將瞥見幕后發(fā)生的事情,使其看起來像是任務(wù)在并行執(zhí)行。
循環(huán)排程
概念化實際任務(wù)執(zhí)行的最簡單方法之一是輪流調(diào)度。在輪流調(diào)度中,每個任務(wù)得到一小塊時間來使用處理器,這是由調(diào)度器控制的。只要任務(wù)有工作要執(zhí)行,它就會執(zhí)行。就該任務(wù)而言,它完全擁有自己的處理器。調(diào)度器負責處理為下一個任務(wù)切換適當上下文的所有復(fù)雜問題:

這和之前展示的三個任務(wù)是一樣的,只不過不是理論上的概念化,而是通過任務(wù)的循環(huán)的每一次迭代都是隨著時間的推移而列舉的。因為循環(huán)調(diào)度器給每個任務(wù)分配了相等的時間片,最短的任務(wù)(任務(wù)1)已經(jīng)執(zhí)行了將近六次循環(huán),而最慢的循環(huán)任務(wù)(任務(wù)2)只完成了第一次循環(huán)。任務(wù)3已經(jīng)執(zhí)行了三次循環(huán)。
執(zhí)行相同函數(shù)的超級循環(huán)與執(zhí)行這些函數(shù)的輪回調(diào)度例程之間的一個極其重要的區(qū)別是這樣的: 任務(wù)3在任務(wù)2之前完成了其適度緊密的循環(huán)。當超級循環(huán)以串行方式運行函數(shù)時,函數(shù)3甚至不會開始,直到函數(shù)2運行完成。所以,雖然調(diào)度器沒有為我們提供真正的并行性,但每個任務(wù)都得到了它公平的CPU周期份額。所以,在這種調(diào)度方案下,如果任務(wù)有較短的循環(huán),它將比有較長循環(huán)的任務(wù)執(zhí)行得更頻繁。
所有這些切換都有一個(輕微的)代價--調(diào)度器需要在任何有上下文切換的時候被調(diào)用。在這個例子中,任務(wù)沒有明確地調(diào)用調(diào)度器來運行。在FreeRTOS運行在ARM Cortex-M上的情況下,調(diào)度器將被從SysTick中斷中調(diào)用(更多細節(jié)可在第7章FreeRTOS調(diào)度器中找到)。為了確保調(diào)度器內(nèi)核非常有效,并盡可能地減少運行時間,我們付出了相當多的努力。然而,事實是,它將在某些時候運行并消耗CPU周期。在大多數(shù)系統(tǒng)中,少量的開銷通常不會被注意到(或顯著),但在某些系統(tǒng)中,它可能成為問題。例如,如果一個設(shè)計處于可行性的極端邊緣,因為它有非常嚴格的時間要求和非常少的空閑CPU周期,如果超級循環(huán)/中斷方法已經(jīng)被仔細地描述和優(yōu)化,那么增加的開銷可能是不可取的(或者完全有必要)。然而,最好是盡可能地避免這種類型的情況,因為即使是在中等復(fù)雜的系統(tǒng)中,忽視中斷堆積(或嵌套條件語句偶爾需要更長的時間)并導(dǎo)致系統(tǒng)錯過最后期限的可能性也是非常大的。
基于搶占式的調(diào)度
搶占式調(diào)度提供了一種機制,以確保系統(tǒng)總是在執(zhí)行其最重要的任務(wù)。搶占式調(diào)度算法將優(yōu)先考慮最重要的任務(wù),不管系統(tǒng)中還有什么事情發(fā)生--除了中斷,因為它們發(fā)生在調(diào)度器下面,總是有更高的優(yōu)先級。這聽起來非常直接--而且確實如此--只是有一些細節(jié)需要考慮到。
讓我們看一下同樣的三個任務(wù)。這三個任務(wù)都有相同的功能:簡單的while循環(huán),無休止地增加不穩(wěn)定的變量。
現(xiàn)在,考慮以下三種情況,看看這三個任務(wù)中哪個會得到上下文。下圖中的任務(wù)與之前介紹的輪流調(diào)度的任務(wù)相同。三個任務(wù)中都有足夠多的工作要做,這將防止任務(wù)脫離上下文:

那么,當三個不同的任務(wù)被設(shè)置為三組不同的優(yōu)先級(A、B、C)時會發(fā)生什么?
A(左上角): 任務(wù)1在系統(tǒng)中擁有最高的優(yōu)先級--它獲得了所有的處理器時間 不管任務(wù)1執(zhí)行了多少次迭代,如果它是系統(tǒng)中優(yōu)先級最高的任務(wù),并且它有工作要做(不需要等待系統(tǒng)中的其他東西),它將被賦予上下文并運行。
B(右上方): 任務(wù)2是系統(tǒng)中優(yōu)先級最高的任務(wù)。由于它有足夠多的工作要做,不需要等待系統(tǒng)中的其他東西,任務(wù)2將被賦予上下文。由于任務(wù)2被配置為系統(tǒng)中的最高優(yōu)先級,它將執(zhí)行,直到它需要在系統(tǒng)中等待其他東西。
C(左下角): 任務(wù)3被配置為系統(tǒng)中的最高優(yōu)先級任務(wù)。沒有其他任務(wù)運行,因為它們的優(yōu)先級較低。
現(xiàn)在,很明顯,如果你真的在設(shè)計一個需要多個任務(wù)并行運行的系統(tǒng),如果系統(tǒng)中所有的任務(wù)都需要100%的CPU時間,并且不需要等待任何東西,那么搶占式調(diào)度器就沒有什么用了。這種設(shè)置對于實時系統(tǒng)來說也不是很好的設(shè)計,因為它完全超載了(而且忽略了系統(tǒng)所要執(zhí)行的三個主要功能中的兩個)!這種情況被稱為 "任務(wù)"!所呈現(xiàn)的情況被稱為任務(wù)饑餓,因為只有系統(tǒng)中優(yōu)先級最高的任務(wù)獲得了CPU時間,而其他任務(wù)則被剝奪了處理器時間。
另一個值得指出的細節(jié)是,調(diào)度器仍然以預(yù)定的時間間隔運行。無論系統(tǒng)中發(fā)生了什么,調(diào)度器都會勤奮地按照預(yù)定的時間間隔運行。
這有一個例外。FreeRTOS有無滴答的調(diào)度器模式,旨在用于極低功率的設(shè)備,它可以防止調(diào)度器在相同的預(yù)定間隔內(nèi)運行。
這里顯示了一個使用搶占式調(diào)度器的更現(xiàn)實的用例:

在這種情況下,任務(wù)1是系統(tǒng)中優(yōu)先級最高的任務(wù)(它也恰好很快完成執(zhí)行)--任務(wù)1只有在調(diào)度器需要運行的時候才會被剝奪上下文;否則,它將保持上下文直到?jīng)]有任何額外的工作要執(zhí)行。
任務(wù)2是下一個最高優(yōu)先級的任務(wù)--你也會注意到,這個任務(wù)被設(shè)置為在每個RTOS調(diào)度器的勾選中執(zhí)行一次(由向下的箭頭表示)。任務(wù)3是系統(tǒng)中優(yōu)先級最低的任務(wù):只有當系統(tǒng)中沒有其他值得做的事情時,它才會得到上下文。在這張圖中,有三個要點值得關(guān)注:
A:任務(wù)2有上下文。即使它被調(diào)度器打斷了,但在調(diào)度器運行后,它又立即得到了上下文(因為它還有工作要做)。
B: 任務(wù)2已經(jīng)完成了迭代0的工作,調(diào)度器已經(jīng)運行并確定(因為系統(tǒng)中沒有其他任務(wù)需要運行)任務(wù)3可以擁有處理器時間。
C:任務(wù)2已經(jīng)開始運行迭代4,但是任務(wù)1現(xiàn)在有一些工作要做--盡管任務(wù)2還沒有完成該迭代的工作。任務(wù)1立即被調(diào)度器切換到執(zhí)行其更高優(yōu)先級的工作。在任務(wù)1完成了它需要做的事情后,任務(wù)2被切換回來完成迭代4。這一次,迭代運行到下一個tick,任務(wù)2再次運行(迭代5)。在任務(wù)2迭代5完成后,沒有更高優(yōu)先級的工作要執(zhí)行,所以系統(tǒng)中最低優(yōu)先級的任務(wù)(任務(wù)3)再次運行。看起來任務(wù)3終于完成了迭代0,所以它進入了迭代1并繼續(xù)運行......。
希望你還在聽我說! 如果沒有,那也沒關(guān)系,因為這只是一個非常抽象的例子。關(guān)鍵的啟示是,系統(tǒng)中優(yōu)先級最高的任務(wù)是優(yōu)先的。
RTOS任務(wù)與超級循環(huán)的對比--利與弊
超級循環(huán)對于責任有限的簡單系統(tǒng)是非常好的。如果系統(tǒng)足夠簡單,它們可以在響應(yīng)事件時提供非常低的抖動,但前提是循環(huán)足夠緊密。隨著系統(tǒng)越來越復(fù)雜,獲得更多的責任,輪詢率會下降。這種輪詢率的降低導(dǎo)致對事件的響應(yīng)抖動大得多。中斷可以被引入到系統(tǒng)中,以應(yīng)對抖動的增加。隨著基于超級循環(huán)的系統(tǒng)變得越來越復(fù)雜,跟蹤和保證對事件的反應(yīng)能力變得越來越難。
對于那些不僅有耗時的任務(wù),而且還需要對外部事件有良好的響應(yīng)能力的更復(fù)雜的系統(tǒng),實時操作系統(tǒng)變得非常有價值。對于實時操作系統(tǒng)來說,系統(tǒng)復(fù)雜性、ROM、RAM和初始設(shè)置時間的增加是為了換取一個更容易理解的系統(tǒng),它可以更容易地保證對外部事件的及時響應(yīng)。










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論