 電子發(fā)燒友App
電子發(fā)燒友App


圖形處理器(英語:Graphics Processing Unit,縮寫:GPU),又稱顯示核心、視覺處理器、顯示芯片,是一種專門在個(gè)人電腦、工作站、游戲機(jī)和一些移動(dòng)設(shè)備(如平板電腦、智能手機(jī)等)上圖像運(yùn)算工作的微處理器。
圖形處置單元(或簡稱GPU)會(huì)賣力處置從PC外部傳送到所銜接表現(xiàn)器的一切內(nèi)容,不管你在玩游戲、編纂視頻或只是盯著桌面的壁紙,一切表現(xiàn)器中表現(xiàn)的圖象都是由GPU停止襯著的。本文體系極客將向人人先容甚么是GPU、它是若何事情的,和為何要為游戲和圖象密集型應(yīng)用程序設(shè)置裝備擺設(shè)公用顯卡。
對通俗用戶來講,現(xiàn)實(shí)上不消要自力顯卡就能夠向表現(xiàn)器「供給」內(nèi)容。像筆記本電腦或平板用戶,平日CPU芯片都邑集成GPU內(nèi)核,也便是人人熟稱的「核顯」,如許便可認(rèn)為對表現(xiàn)請求不高的低功耗裝備供給更好的性價(jià)比。
正因如斯,部門筆記本電腦、平板電腦和某些PC用戶來講,要想將其圖形處置器進(jìn)級(jí)到更高級(jí)別也很艱苦,乃至不太能夠。這就會(huì)招致游戲(和視頻編纂等)機(jī)能欠安,只能將圖形品質(zhì)設(shè)置低落能力事情。對此類用戶而言,只要在主板支撐和余暇空間充足的情況下,增加新顯卡才能夠或許把(游戲)表現(xiàn)體驗(yàn)進(jìn)步到一個(gè)新的程度。
GPU發(fā)展和現(xiàn)狀
1. GPU原來就是為了加速3D渲染的,后來被拿過來做計(jì)算。
2. 現(xiàn)在GPU可以支持通用的指令,可以用傳統(tǒng)的C和C++,還有Fortran來編程。
3. 現(xiàn)在單個(gè)高端GPU的性能已經(jīng)達(dá)到了傳統(tǒng)多核CPU集群的性能
4. 有的應(yīng)用通過GPU加速相比傳統(tǒng)的多核CPU來說可以達(dá)到100X的加速。對某些特定應(yīng)用來說GPU還是更適合的。
GPU編程模型
1. 在GPU中,工作的分配是通過在調(diào)度空間上并行地應(yīng)用或者映射一個(gè)函數(shù)(或者叫做kernel)。舉例來說,一個(gè)矩陣中的每一個(gè)點(diǎn)就是調(diào)度空間。
2. kernel就是描述在一個(gè)線程在調(diào)度空間中的每一個(gè)點(diǎn)要完成的工作。在調(diào)度空間中,每一個(gè)點(diǎn)都要啟動(dòng)一個(gè)線程。
3. 由于GPU是在單個(gè)PCI-e卡上的協(xié)處理器,數(shù)據(jù)必須通過顯式地從系統(tǒng)內(nèi)存拷貝到GPU板上內(nèi)存。
4. GPU是以SIMD的多個(gè)group的形式組織的。在每一個(gè)SIMD的group(或者叫warp,在NIVIDA CUDA編程中為32個(gè)線程)中,所有的線程在lockstep中執(zhí)行相同的指令。這樣的在lockstep中執(zhí)行相同指令的多個(gè)線程就叫做warp,雖然分支是被允許的,但是如果同一個(gè)warp中的線程出現(xiàn)不同的執(zhí)行路徑,會(huì)帶來一些性能開銷。
4. 對于memory-bound的應(yīng)用來說,可能的話,同一個(gè)warp中的所有線程應(yīng)當(dāng)訪問相鄰的數(shù)據(jù)元素,同一個(gè)warp中相鄰的線程應(yīng)當(dāng)訪問相鄰的數(shù)據(jù)元素。這可能要對數(shù)據(jù)布局和數(shù)據(jù)訪問模式進(jìn)行重新安排。
5. GPU有多個(gè)內(nèi)存空間可用于開發(fā)數(shù)據(jù)訪問模式。除了golbal memory以外,還有constant memory(read-only, cached),,texture memory(read-only, cached, optimized for neighboring regions of an array)和per-block shared memory(a fast memory space within each warp processor, managed explicitly by the programmer)。
6. GPU編程有兩個(gè)主要平臺(tái),一個(gè)是OpenCL,一個(gè)編程方式類似OpenGL的產(chǎn)業(yè)標(biāo)準(zhǔn),還有另一個(gè)是為了C/C++ Fortran的CUDA,在NVIDIA的GPU上編程。
7. OpenCL/CUDA編譯器并不是把C代碼轉(zhuǎn)換成CUDA代碼,編程人員最主要的工作還是選擇算法和數(shù)據(jù)結(jié)構(gòu)。例如在GPU上,基數(shù)排序和歸并排序要比堆排序和快速排序好。Some programming effort is also required to write the necessary CUDA kernel(s) as well as to add code to transfer data to the GPU,launch the kernel(s), and then read back the results from the GPU.
什么應(yīng)用適合GPU
1. 內(nèi)核中有豪多并行線程的應(yīng)用
2. 對于線程間的數(shù)據(jù)交換都發(fā)生在kernel調(diào)度空間中的相鄰線程之間的應(yīng)用,因?yàn)檫@樣就可以用到per-block shared memory.
3. 數(shù)據(jù)并行的應(yīng)用,多個(gè)線程做相似工作,循環(huán)是數(shù)據(jù)并行的主要來源。
4. 那些能得到很好的天然硬件支持的應(yīng)用,如倒數(shù)和反平方根,不過在編程中要打開“fastmath”選項(xiàng),確保使用硬件支持功能。
5. 需要對每個(gè)數(shù)據(jù)元素做大量的計(jì)算,或者能夠充分利用寬內(nèi)存接口(wide memory interface這里有疑問)
6. 做同步操作較少的應(yīng)用。
什么應(yīng)用不適合GPU
1. 并行度小的應(yīng)用,如需要的線程數(shù)小于100個(gè),那么使用GPU加速效果不明顯
2. 不規(guī)則的任務(wù)并行---盡管應(yīng)用需要很多線程,但是這些線程都做不同的工作,那么GPU不能得到有效的利用。不過這也依賴于具體工作,多久對線程調(diào)度一次,加速的可能仍然存在。
3. 頻繁的全局同步,這要求全局的barrier,帶來很大性能開銷。
4. 在線程之間,會(huì)出現(xiàn)隨機(jī)的點(diǎn)對點(diǎn)同步的應(yīng)用。GPU對這個(gè)的支持不好,通常需要在每次同步的時(shí)候做一個(gè)全局barrier,如果要利用GPU,最好重構(gòu)算法避免出現(xiàn)這個(gè)問題。
5. 要求計(jì)算量(相比于數(shù)據(jù)傳輸量)少的應(yīng)用。盡管在CPU+GPU計(jì)算結(jié)構(gòu)中,GPU可以帶來計(jì)算性能的提升,但是這些提升都被向GPU傳輸數(shù)據(jù)所消耗的實(shí)踐覆蓋了。舉個(gè)例子,對于兩個(gè)向量求和運(yùn)算,如果非常大的向量的話,一般都選擇在CPU上算,否則傳輸?shù)紾PU上的時(shí)間開銷很大。
硬件需求。
你需要有NVIDIA GeForce FX 或者 ATI RADEON 9500 以上的顯卡, 一些老的顯卡可能不支持我們所需要的功能(主要是單精度浮點(diǎn)數(shù)據(jù)的存取及運(yùn)算) 。
軟件需求
首先,你需要一個(gè)C/C++編譯器。你有很多可以選擇,如:Visual Studio .NET 2003, Eclipse 3.1 plus CDT/MinGW, the Intel C++ Compiler 9.0 及 GCC 3.4+等等。然后更新你的顯卡驅(qū)動(dòng)讓它可以支持一些最新特性。
本文所附帶的源代碼,用到了兩個(gè)擴(kuò)展庫,GLUT 和 GLEW 。對于windows系統(tǒng),GLUT可以在 這里下載到,而Linux 的freeglut和freeglut-devel大多的版本都集成了。GLEW可以在SourceForge 上下載到,對于著色語言,大家可以選擇GLSL或者CG,GLSL在你安裝驅(qū)動(dòng)的時(shí)候便一起裝好了。如果你想用CG,那就得下載Cg Toolkit 。
二者擇其一
大家如果要找DirectX版本的例子的話,請看一下Jens Krügers的《 Implicit Water Surface》 demo(該例子好像也有OpenGL 版本的)。當(dāng)然,這只是一個(gè)獲得高度評(píng)價(jià)的示例源代碼,而不是教程的。
有一些從圖形著色編程完全抽象出來的GPU的元程序語言,把底層著色語言作了封裝,讓你不用學(xué)習(xí)著色語言,便能使用顯卡的高級(jí)特性,其中BrookGPU 和Sh 就是比較出名的兩個(gè)項(xiàng)目。
Back to top
初始化OpenGL
GLUT
GLUT(OpenGLUtility Toolkit)該開發(fā)包主要是提供了一組窗口函數(shù),可以用來處理窗口事件,生成簡單的菜單。我們使用它可以用盡可能少的代碼來快速生成一個(gè)OpenGL 開發(fā)環(huán)境,另外呢,該開發(fā)包具有很好的平***立性,可以在當(dāng)前所有主流的操作系統(tǒng)上運(yùn)行 (MS-Windows or Xfree/Xorg on Linux / Unix and Mac)。
[cpp] view plaincopy// include the GLUT header file
#include 《GL/glut.h》
// call this and pass the command line arguments from main()
void initGLUT(int argc, char **argv) {
glutInit ( &argc, argv );
glutCreateWindow(“SAXPY TESTS”);
}
OpenGL 擴(kuò)展
許多高級(jí)特性,如那些要在GPU上進(jìn)行普通浮點(diǎn)運(yùn)算的功能,都不是OpenGL內(nèi)核的一部份。因此,OpenGL Extensions通過對OpenGL API的擴(kuò)展, 為我們提供了一種可以訪問及使用硬件高級(jí)特性的機(jī)制。OpenGL擴(kuò)展的特點(diǎn):不是每一種顯卡都支持該擴(kuò)展,即便是該顯卡在硬件上支持該擴(kuò)展,但不同版本的顯卡驅(qū)動(dòng),也會(huì)對該擴(kuò)展的運(yùn)算能力造成影響,因?yàn)镺penGL擴(kuò)展設(shè)計(jì)出來的目的,就是為了最大限度地挖掘顯卡運(yùn)算的能力,提供給那些在該方面有特別需求的程序員來使用。在實(shí)際編程的過程中,我們必須小心檢測當(dāng)前系統(tǒng)是否支持該擴(kuò)展,如果不支持的話,應(yīng)該及時(shí)把錯(cuò)誤信息返回給軟件進(jìn)行處理。當(dāng)然,為了降低問題的復(fù)雜性,本教程的代碼跳過了這些檢測步驟。
OpenGL Extension Registry OpenGL擴(kuò)展注冊列表中,列出了幾乎所有的OpenGL可用擴(kuò)展,有需要的朋友可能的查看一下。
當(dāng)我們要在程序中使用某些高級(jí)擴(kuò)展功能的時(shí)候,我們必須在程序中正確引入這些擴(kuò)展的擴(kuò)展函數(shù)名。有一些小工具可以用來幫助我們檢測一下某個(gè)給出的擴(kuò)展函數(shù)是否被當(dāng)前的硬件及驅(qū)動(dòng)所支持,如:glewinfo, OpenGL extension viewer等等,甚至OpenGL本身就可以(在上面的連接中,就有一個(gè)相關(guān)的例子)。
如何獲取這些擴(kuò)展函數(shù)的入口指針,是一個(gè)比較高級(jí)的問題。下面這個(gè)例子,我們使用GLEW來作為擴(kuò)展載入函數(shù)庫,該函數(shù)庫把許多復(fù)雜的問題進(jìn)行了底層的封裝,給我們使用高級(jí)擴(kuò)展提供了一組簡潔方便的訪問函數(shù)。
[cpp] view plaincopyvoid initGLEW (void) {
// init GLEW, obtain function pointers
int err = glewInit();
// Warning: This does not check if all extensions used
// in a given implementation are actually supported.
// Function entry points created by glewInit() will be
// NULL in that case!
if (GLEW_OK != err) {
printf((char*)glewGetErrorString(err));
exit(ERROR_GLEW);
}
}
OpenGL離屏渲染的準(zhǔn)備工作
在傳統(tǒng)的GPU渲染流水線中,每次渲染運(yùn)算的最終結(jié)束點(diǎn)就是幀緩沖區(qū)。所謂幀緩沖區(qū),其實(shí)是顯卡內(nèi)存中的一塊,它特別這處在于,保存在該內(nèi)存區(qū)塊中的圖像數(shù)據(jù),會(huì)實(shí)時(shí)地在顯示器上顯示出來。根據(jù)顯示器設(shè)置的不同,幀緩沖區(qū)最大可以取得32位的顏色深度,也就是說紅、綠、藍(lán)、alpha四個(gè)顏色通道共享這32位的數(shù)據(jù),每個(gè)通道占8位。當(dāng)然用32位來記錄顏色,如果加起來的話,可以表示160萬種不同的顏色,這對于顯示器來說可能是足夠了,但是如果我們要在浮點(diǎn)數(shù)字下工作,用8位來記錄一個(gè)浮點(diǎn)數(shù),其數(shù)學(xué)精度是遠(yuǎn)遠(yuǎn)不夠的。另外還有一個(gè)問題就是,幀緩存中的數(shù)據(jù)最大最小值會(huì)被限定在一個(gè)范圍內(nèi),也就是 [0/255; 255/255]
如何解決以上的一些問題呢?一種比較苯拙的做法就是用有符號(hào)指數(shù)記數(shù)法,把一個(gè)標(biāo)準(zhǔn)的IEEE 32位浮點(diǎn)數(shù)映射保存到8位的數(shù)據(jù)中。不過幸運(yùn)的是,我們不需要這樣做。首先,通過使用一些OpenGL的擴(kuò)展函數(shù),我們可以給GPU提供32位精度的浮點(diǎn)數(shù)。另外有一個(gè)叫EXT_framebuffer_object 的OpenGL的擴(kuò)展, 該擴(kuò)展允許我們把一個(gè)離屏緩沖區(qū)作為我們渲染運(yùn)算的目標(biāo),這個(gè)離屏緩沖區(qū)中的RGBA四個(gè)通道,每個(gè)都是32位浮點(diǎn)的,這樣一來, 要想GPU上實(shí)現(xiàn)四分量的向量運(yùn)算就比較方便了,而且得到的是一個(gè)全精度的浮點(diǎn)數(shù),同時(shí)也消除了限定數(shù)值范圍的問題。我們通常把這一技術(shù)叫FBO,也就是Frame Buffer Object的縮寫。
要使用該擴(kuò)展,或者說要把傳統(tǒng)的幀緩沖區(qū)關(guān)閉,使用一個(gè)離屏緩沖區(qū)作我們的渲染運(yùn)算區(qū),只要以下很少的幾行代碼便可以實(shí)現(xiàn)了。有一點(diǎn)值得注意的是:當(dāng)我用使用數(shù)字0,來綁定一個(gè)FBO的時(shí)候,無論何時(shí),它都會(huì)還原window系統(tǒng)的特殊幀緩沖區(qū),這一特性在一些高級(jí)應(yīng)用中會(huì)很有用,但不是本教程的范圍,有興趣的朋友可能自已研究一下。
[cpp] view plaincopyGLuint fb;
void initFBO(void) {
// create FBO (off-screen framebuffer)
glGenFramebuffersEXT(1, &fb);
// bind offscreen buffer
glBindFramebufferEXT(GL_FRAMEBUFFER_EXT, fb);
}
Back to top
GPGPU 概念
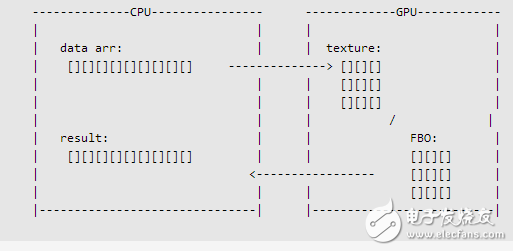
1: 數(shù)組 = 紋理
一維數(shù)組是本地CPU最基本的數(shù)據(jù)排列方式,多維的數(shù)組則是通過對一個(gè)很大的一維數(shù)組的基準(zhǔn)入口進(jìn)行坐標(biāo)偏移來訪問的(至少目前大多數(shù)的編譯器都是這樣做的)。一個(gè)小例子可以很好說明這一點(diǎn),那就是一個(gè)MxN維的數(shù)組 a[i][j] = a[i*M+j];我們可能把一個(gè)多維數(shù)組,映射到一個(gè)一維數(shù)組中去。這些數(shù)組我開始索引都被假定為0;
而對于GPU,最基本的數(shù)據(jù)排列方式,是二維數(shù)組。一維和三維的數(shù)組也是被支持的,但本教程的技術(shù)不能直接使用。數(shù)組在GPU內(nèi)存中我們把它叫做紋理或者是紋理樣本。紋理的最大尺寸在GPU中是有限定的。每個(gè)維度的允許最大值,通過以下一小段代碼便可能查詢得到,這些代碼能正確運(yùn)行,前提是OpenGL的渲染上下文必須被正確初始化。
[cpp] view plaincopyint maxtexsize;
glGetIntegerv(GL_MAX_TEXTURE_SIZE,&maxtexsize);
printf(“GL_MAX_TEXTURE_SIZE, %d ”,maxtexsize);
就目前主流的顯卡來說,這個(gè)值一般是2048或者4096每個(gè)維度,值得提醒大家的就是:一塊顯卡,雖然理論上講它可以支持4096*4096*4096的三維浮點(diǎn)紋理,但實(shí)際中受到顯卡內(nèi)存大小的限制,一般來說,它達(dá)不到這個(gè)數(shù)字。
在CPU中,我們常會(huì)討論到數(shù)組的索引,而在GPU中,我們需要的是紋理坐標(biāo),有了紋理坐標(biāo)才可以訪問紋理中每個(gè)數(shù)據(jù)的值。而要得到紋理坐標(biāo),我們又必須先得到紋理中心的地址。
傳統(tǒng)上講,GPU是可以四個(gè)分量的數(shù)據(jù)同時(shí)運(yùn)算的,這四個(gè)分量也就是指紅、綠、藍(lán)、alpha(RGBA)四個(gè)顏色通道。稍后的章節(jié)中,我將會(huì)介紹如何使用顯卡這一并行運(yùn)算的特性,來實(shí)現(xiàn)我們想要的硬件加速運(yùn)算。
在CPU上生成數(shù)組
讓我們來回顧一下前面所要實(shí)現(xiàn)的運(yùn)算:也就是給定兩個(gè)長度為N的數(shù)組,現(xiàn)在要求兩數(shù)組的加權(quán)和y=y+alpha*x,我們現(xiàn)在需要兩個(gè)數(shù)組來保存每個(gè)浮點(diǎn)數(shù)的值,及一個(gè)記錄alpha值的浮點(diǎn)數(shù)。
[cpp] view plaincopyfloat* dataY = (float*)malloc(N*sizeof(float)); float* dataX = (float*)malloc(N*sizeof(float)); float alpha;
雖然我們的實(shí)際運(yùn)算是在GPU上運(yùn)行,但我們?nèi)匀灰贑PU上分配這些數(shù)組空間,并對數(shù)組中的每個(gè)元素進(jìn)行初始化賦值。
在GPU上生成浮點(diǎn)紋理
這個(gè)話題需要比較多的解釋才行,讓我們首先回憶一下在CPU上是如何實(shí)現(xiàn)的,其實(shí)簡單點(diǎn)來說,我們就是要在GPU上建立兩個(gè)浮點(diǎn)數(shù)組,我們將使用浮點(diǎn)紋理來保存數(shù)據(jù)。
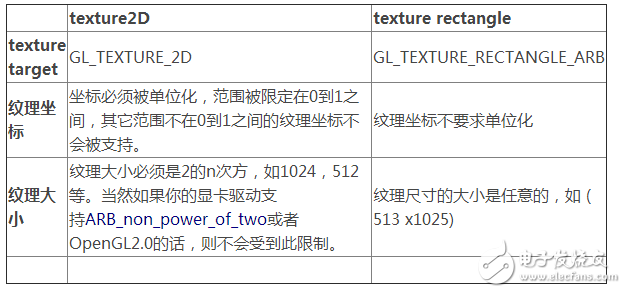
有許多因素的影響,從而使問題變得復(fù)雜起來。其中一個(gè)重要的因素就是,我們有許多不同的紋理對像可供我們選擇。即使我們排除掉一些非本地的目標(biāo),以及限定只能使用2維的紋理對像。我們依然還有兩個(gè)選擇,GL_TEXTURE_2D是傳統(tǒng)的OpenGL二維紋理對像,而ARB_texture_rectangle則是一個(gè)OpenGL擴(kuò)展,這個(gè)擴(kuò)展就是用來提供所謂的texture rectangles的。對于那些沒有圖形學(xué)背景的程序員來說,選擇后者可能會(huì)比較容易上手。texture2Ds 和 texture rectangles 在概念上有兩大不同之處。我們可以從下面這個(gè)列表來對比一下,稍后我還會(huì)列舉一些例子。

另外一個(gè)重要的影響因素就是紋理格式,我們必須謹(jǐn)慎選擇。在GPU中可能同時(shí)處理標(biāo)量及一到四分量的向量。本教程主要關(guān)注標(biāo)量及四分量向量的使用。比較簡單的情況下我們可以在中紋理中為每個(gè)像素只分配一個(gè)單精度浮點(diǎn)數(shù)的儲(chǔ)存空間,在OpenGL中,GL_LUMNANCE就是這樣的一種紋理格式。但是如果我們要想使用四個(gè)通道來作運(yùn)算的話,我們就可以采用GL_RGBA這種紋理格式。使用這種紋理格式,意味著我們會(huì)使用一個(gè)像素?cái)?shù)據(jù)來保存四個(gè)浮點(diǎn)數(shù),也就是說紅、綠、藍(lán)、alpha四個(gè)通道各占一個(gè)32位的空間,對于LUMINANCE格式的紋理,每個(gè)紋理像素只占有32位4個(gè)字節(jié)的顯存空間,而對于RGBA格式,保存一個(gè)紋理像素需要的空間是4*32=128位,共16個(gè)字節(jié)。
接下來的選擇,我們就要更加小心了。在OpenGL中,有三個(gè)擴(kuò)展是真正接受單精度浮點(diǎn)數(shù)作為內(nèi)部格式的紋理的。分別是:NV_float_buffer,ATI_texture_float 和ARB_texture_float.每個(gè)擴(kuò)展都就定義了一組自已的列舉參數(shù)及其標(biāo)識(shí),如:(GL_FLOAT_R32_NV) ,( 0x8880),在程序中使用不同的參數(shù),可以生成不同格式的紋理對像,下面會(huì)作詳細(xì)描述。
在這里,我們只對其中兩個(gè)列舉參數(shù)感興趣,分別是GL_FLOAT_R32_NV和GL_FLOAT_RGBA32_NV. 前者是把每個(gè)像素保存在一個(gè)浮點(diǎn)值中,后者則是每個(gè)像素中的四個(gè)分量分別各占一個(gè)浮點(diǎn)空間。這兩個(gè)列舉參數(shù),在另外兩個(gè)擴(kuò)展(ATI_texture_float andARB_texture_float )中也分別有其對應(yīng)的名稱:GL_LUMINANCE_FLOAT32_ATI,GL_RGBA_FLOAT32_ATI 和 GL_LUMINANCE32F_ARB,GL_RGBA32F_ARB 。在我看來,他們名稱不同,但作用都是一樣的,我想應(yīng)該是多個(gè)不同的參數(shù)名稱對應(yīng)著一個(gè)相同的參數(shù)標(biāo)識(shí)。至于選擇哪一個(gè)參數(shù)名,這只是看個(gè)人的喜好,因?yàn)樗鼈內(nèi)慷技戎С諲V顯卡也支持ATI的顯卡。
最后還有一個(gè)要解決的問題就是,我們?nèi)绾伟袰PU中的數(shù)組元素與GPU中的紋理元素一一對應(yīng)起來。這里,我們采用一個(gè)比較容易想到的方法:如果紋理是LUMINANCE格式,我們就把長度為N的數(shù)組,映射到一張大小為sqrt(N) x sqrt(N)和紋理中去(這里規(guī)定N是剛好能被開方的)。如果采用RGBA的紋理格式,那么N個(gè)長度的數(shù)組,對應(yīng)的紋理大小就是sqrt(N/4) x sqrt(N/4),舉例說吧,如果N=1024^2,那么紋理的大小就是512*512 。
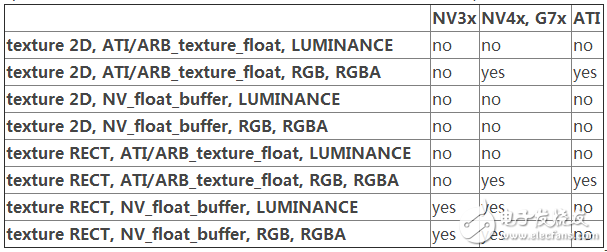
以下的表格總結(jié)了我們上面所討論的問題,作了一下分類,對應(yīng)的GPU分別是: NVIDIA GeForce FX (NV3x), GeForce 6 and 7 (NV4x, G7x) 和 ATI.
(*) Warning: 這些格式作為紋理是被支持的,但是如果作為渲染對像,就不一定全部都能夠得到良好的支持(seebelow)。
講完上面的一大堆基礎(chǔ)理論這后,是時(shí)候回來看看代碼是如何實(shí)現(xiàn)的。比較幸運(yùn)的是,當(dāng)我們弄清楚了要用那些紋理對像、紋理格式、及內(nèi)部格式之后,要生成一個(gè)紋理是很容易的。
[cpp] view plaincopy// create a new texture name
GLuint texID;
glGenTextures (1, &texID);
// bind the texture name to a texture target
glBindTexture(texture_target,texID);
// turn off filtering and set proper wrap mode
// (obligatory for float textures atm)
glTexParameteri(texture_target, GL_TEXTURE_MIN_FILTER, GL_NEAREST);
glTexParameteri(texture_target, GL_TEXTURE_MAG_FILTER, GL_NEAREST);
glTexParameteri(texture_target, GL_TEXTURE_WRAP_S, GL_CLAMP);
glTexParameteri(texture_target, GL_TEXTURE_WRAP_T, GL_CLAMP);
// set texenv to replace instead of the default modulate
glTexEnvi(GL_TEXTURE_ENV, GL_TEXTURE_ENV_MODE, GL_REPLACE);
// and allocate graphics memory
glTexImage2D(texture_target, 0, internal_format,
texSize, texSize, 0, texture_format, GL_FLOAT, 0);
讓我們來消化一下上面這段代碼的最后那個(gè)OpenGL函數(shù),我來逐一介紹一下它每個(gè)參數(shù):第一個(gè)參數(shù)是紋理對像,上面已經(jīng)說過了;第二個(gè)參數(shù)是0,是告訴GL不要使用多重映像紋理。接下來是內(nèi)部格式及紋理大小,上面也說過了,應(yīng)該清楚了吧。第六個(gè)參數(shù)是也是0,這是用來關(guān)閉紋理邊界的,這里不需要邊界。接下來是指定紋理格式,選擇一種你想要的格式就可以了。對于參數(shù)GL_FLOAT,我們不要被它表面的意思迷惑,它并不會(huì)影響我們所保存在紋理中的浮點(diǎn)數(shù)的精度。其實(shí)它只與CPU方面有關(guān)系,目的就是要告訴GL稍后將要傳遞過去的數(shù)據(jù)是浮點(diǎn)型的。最后一個(gè)參數(shù)還是0,意思是生成一個(gè)紋理,但現(xiàn)在不給它指定任何數(shù)據(jù),也就是空的紋理。該函數(shù)的調(diào)用必須按上面所說的來做,才能正確地生成一個(gè)合適的紋理。上面這段代碼,和CPU里分配內(nèi)存空間的函數(shù)malloc(),功能上是很相像的,我們可能用來對比一下。
最后還有一點(diǎn)要提醒注意的:要選擇一個(gè)適當(dāng)?shù)臄?shù)據(jù)排列映射方式。這里指的就是紋理格式、紋理大小要與你的CPU數(shù)據(jù)相匹配,這是一個(gè)非常因地制宜的問題,根據(jù)解決的問題不同,其相應(yīng)的處理問題方式也不同。從經(jīng)驗(yàn)上看,一些情況下,定義這樣一個(gè)映射方式是很容易的,但某些情況下,卻要花費(fèi)你大量的時(shí)間,一個(gè)不理想的映射方式,甚至?xí)?yán)重影響你的系統(tǒng)運(yùn)行。
數(shù)組索引與紋理坐標(biāo)的一一對應(yīng)關(guān)系
在后面的章節(jié)中,我們會(huì)講到如何通過一個(gè)渲染操作,來更新我們保存在紋理中的那些數(shù)據(jù)。在我們對紋理進(jìn)行運(yùn)算或存取的時(shí)候,為了能夠正確地控制每一個(gè)數(shù)據(jù)元素,我們得選擇一個(gè)比較特殊的投影方式,把3D世界映射到2D屏幕上(從世界坐標(biāo)空間到屏幕設(shè)備坐標(biāo)空間),另外屏幕像素與紋理元素也要一一對應(yīng)。這種關(guān)系要成功,關(guān)鍵是要采用正交投影及合適的視口。這樣便能做到幾何坐標(biāo)(用于渲染)、紋理坐標(biāo)(用作數(shù)據(jù)輸入)、像素坐標(biāo)(用作數(shù)據(jù)輸出)三者一一對應(yīng)。有一個(gè)要提醒大家的地方:如果使用texture2D,我們則須要對紋理坐標(biāo)進(jìn)行適當(dāng)比例的縮放,讓坐標(biāo)的值在0到1之間,前面有相關(guān)的說明。
為了建立一個(gè)一一對應(yīng)的映射,我們把世界坐標(biāo)中的Z坐標(biāo)設(shè)為0,把下面這段代碼加入到initFBO()這個(gè)函數(shù)中
[cpp] view plaincopy// viewport for 1:1 pixel=texel=geometry mapping
glMatrixMode(GL_PROJECTION);
glLoadIdentity();
gluOrtho2D(0.0, texSize, 0.0, texSize);
glMatrixMode(GL_MODELVIEW);
glLoadIdentity();
glViewport(0, 0, texSize, texSize);
使用紋理作為渲染對像
其實(shí)一個(gè)紋理,它不僅可以用來作數(shù)據(jù)輸入對像,也還可以用作數(shù)據(jù)輸出對像。這也是提高GPU運(yùn)算效率和關(guān)鍵所在。通過使用 framebuffer_object這個(gè)擴(kuò)展,我們可以把數(shù)據(jù)直接渲染輸出到一個(gè)紋理上。但是有一個(gè)缺點(diǎn):一個(gè)紋理對像不能同時(shí)被讀寫,也就是說,一個(gè)紋理,要么是只讀的,要么就是只寫的。顯卡設(shè)計(jì)的人提供這樣一個(gè)解釋:GPU在同一時(shí)間段內(nèi)會(huì)把渲染任務(wù)分派到幾個(gè)通道并行運(yùn)行, 它們之間都是相互獨(dú)立的(稍后的章節(jié)會(huì)對這個(gè)問題作詳細(xì)的討論)。如果我們允許對一個(gè)紋理同時(shí)進(jìn)行讀寫操作的話,那我們需要一個(gè)相當(dāng)復(fù)雜的邏輯算法來解決讀寫沖突的問題, 即使在芯片邏輯上可以做到,但是對于GPU這種沒有數(shù)據(jù)安全性約束的處理單元來說,也是沒辦法把它實(shí)現(xiàn)的,因?yàn)镚PU并不是基von Neumann的指令流結(jié)構(gòu),而是基于數(shù)據(jù)流的結(jié)構(gòu)。因此在我們的程序中,我們要用到3個(gè)紋理,兩個(gè)只讀紋理分別用來保存輸入數(shù)組x,y。一個(gè)只寫紋理用來保存運(yùn)算結(jié)果。用這種方法意味著要把先前的運(yùn)算公式:y = y + alpha * x 改寫為:y_new = y_old + alpha * x.
FBO 擴(kuò)展提供了一個(gè)簡單的函數(shù)來實(shí)現(xiàn)把數(shù)據(jù)渲染到紋理。為了能夠使用一個(gè)紋理作為渲染對像,我們必須先把這個(gè)紋理與FBO綁定,這里假設(shè)離屏幀緩沖已經(jīng)被指定好了。
[cpp] view plaincopyglFramebufferTexture2DEXT(GL_FRAMEBUFFER_EXT, GL_COLOR_ATTACHMENT0_EXT, texture_target, texID, 0);
第一個(gè)參數(shù)的意思是很明顯的。第二個(gè)參數(shù)是定義一個(gè)綁定點(diǎn)(每個(gè)FBO最大可以支持四個(gè)不同的綁定點(diǎn),當(dāng)然,不同的顯卡對這個(gè)最大綁定數(shù)的支持不一樣,可以用GL_MAX_COLOR_ATTACHMENTS_EXT來查詢一下)。第三和第四個(gè)參數(shù)應(yīng)該清楚了吧,它們是實(shí)際紋理的標(biāo)識(shí)。最后一個(gè)參數(shù)指的是使用多重映像紋理,這里沒有用到,因此設(shè)為0。
為了能成功綁定一紋理,在這之前必須先用glTexImage2D()來對它定義和分配空間。但不須要包含任何數(shù)據(jù)。我們可以把FBO想像為一個(gè)數(shù)據(jù)結(jié)構(gòu)的指針,為了能夠?qū)σ粋€(gè)指定的紋理直接進(jìn)行渲染操作,我們須要做的就調(diào)用OpenGL來給這些指針賦以特定的含義。
不幸的是,在FBO的規(guī)格中,只有GL_RGB和GL_RGBA兩種格式的紋理是可以被綁定為渲染對像的(后來更新這方面得到了改進(jìn)),LUMINANCE這種格式的綁定有希望在后繼的擴(kuò)展中被正式定義使用。在我定本教程的時(shí)候,NVIDIA的硬件及驅(qū)動(dòng)已經(jīng)對這個(gè)全面支持,但是只能結(jié)會(huì)對應(yīng)的列舉參數(shù)NV_float_buffer一起來使用才行。換句話說,紋理中的浮點(diǎn)數(shù)的格式與渲染對像中的浮點(diǎn)數(shù)格式有著本質(zhì)上的區(qū)別。
下面這個(gè)表格對目前不同的顯卡平臺(tái)總結(jié)了一下,指的是有哪些紋理格式及紋理對像是可能用來作為渲染對像的,(可能還會(huì)有更多被支持的格式,這里只關(guān)心是浮點(diǎn)數(shù)的紋理格式):
列表中最后一行所列出來的格式在目前來說,不能被所有的GPU移植使用。如果你想采用LUMINANCE格式,你必須使用ractangles紋理,并且只能在NVIDIA的顯卡上運(yùn)行。想要寫出兼容NVIDIA及ATI兩大類顯卡的代是可能的,但只支持NV4x以上。幸運(yùn)的是要修改的代碼比較少,只在一個(gè)switch開關(guān),便能實(shí)現(xiàn)代碼的可移植性了。相信隨著ARB新版本擴(kuò)展的發(fā)布,各平臺(tái)之間的兼容性將會(huì)得到進(jìn)一步的提高,到時(shí)候各種不同的格式也可能相互調(diào)用了。
把數(shù)據(jù)從CPU的數(shù)組傳輸?shù)紾PU的紋理
為了把數(shù)據(jù)傳輸?shù)郊y理中去,我們必須綁定一個(gè)紋理作為紋理目標(biāo),并通過一個(gè)GL函數(shù)來發(fā)送要傳輸?shù)臄?shù)據(jù)。實(shí)際上就是把數(shù)據(jù)的首地址作為一個(gè)參數(shù)傳遞給該涵數(shù),并指定適當(dāng)?shù)募y理大小就可以了。如果用LUMINANCE格式,則意味著數(shù)組中必須有texSize x texSize個(gè)元數(shù)。而RGBA格式,則是這個(gè)數(shù)字的4倍。注意的是,在把數(shù)據(jù)從內(nèi)存?zhèn)鞯斤@卡的過程中,是全完不需要人為來干預(yù)的,由驅(qū)動(dòng)來自動(dòng)完成。一但傳輸完成了,我們便可能對CPU上的數(shù)據(jù)作任意修改,這不會(huì)影響到顯卡中的紋理數(shù)據(jù)。 而且我們下次再訪問該紋理的時(shí)候,它依然是可用的。在NVIDIA的顯卡中,以下的代碼是得到硬件加速的。
[cpp] view plaincopyglBindTexture(texture_target, texID);
glTexSubImage2D(texture_target,0,0,0,texSize,texSize,
texture_format,GL_FLOAT,data);
這里三個(gè)值是0的參數(shù),是用來定義多重映像紋理的,由于我們這里要求一次把整個(gè)數(shù)組傳輸一個(gè)紋理中,不會(huì)用到多重映像紋理,因此把它們都關(guān)閉掉。
以上是NVIDIA顯卡的實(shí)現(xiàn)方法,但對于ATI的顯卡,以下的代碼作為首選的技術(shù)。在ATI顯卡中,要想把數(shù)據(jù)傳送到一個(gè)已和FBO綁定的紋理中的話,只需要把OpenGL的渲染目標(biāo)改為該綁定的FBO對像就可以了。
glDrawBuffer(GL_COLOR_ATTACHMENT0_EXT);glRasterPos2i(0,0);glDrawPixels(texSize,texSize,texture_format,GL_FLOAT,data);
第一個(gè)函數(shù)是改變輸出的方向,第二個(gè)函數(shù)中我們使用了起點(diǎn)作為參與點(diǎn),因?yàn)槲覀冊诘谌齻€(gè)函數(shù)中要把整個(gè)數(shù)據(jù)塊都傳到紋理中去。
兩種情況下,CPU中的數(shù)據(jù)都是以行排列的方式映射到紋理中去的。更詳細(xì)地說,就是:對于RGBA格式,數(shù)組中的前四個(gè)數(shù)據(jù),被傳送到紋理的第一個(gè)元素的四個(gè)分量中,分別與R,G,B,A分量一一對應(yīng),其它類推。而對于LUMINANCE 格式的紋理,紋理中第一行的第一個(gè)元素,就對應(yīng)數(shù)組中的第一個(gè)數(shù)據(jù)。其它紋理元素,也是與數(shù)組中的數(shù)據(jù)一一對應(yīng)的。
把數(shù)據(jù)從GPU紋理,傳輸?shù)紺PU的數(shù)組
這是一個(gè)反方向的操作,那就是把數(shù)據(jù)從GPU傳輸回來,存放在CPU的數(shù)組上。同樣,有兩種不同的方法可供我們選擇。傳統(tǒng)上,我們是使用OpenGL獲取紋理的方法,也就是綁定一個(gè)紋理目標(biāo),然后調(diào)用glGetTexImage()這個(gè)函數(shù)。這些函數(shù)的參數(shù),我們在前面都有見過。
glBindTexture(texture_target,texID);glGetTexImage(texture_target,0,texture_format,GL_FLOAT,data);
但是這個(gè)我們將要讀取的紋理,已經(jīng)和一個(gè)FBO對像綁定的話,我們可以采用改變渲染指針方向的技術(shù)來實(shí)現(xiàn)。
glReadBuffer(GL_COLOR_ATTACHMENT0_EXT);glReadPixels(0,0,texSize,texSize,texture_format,GL_FLOAT,data);
由于我們要讀取GPU的整個(gè)紋理,因此這里前面兩個(gè)參數(shù)是0,0。表示從0起始點(diǎn)開始讀取。該方法是被推薦使用的。
一個(gè)忠告:比起在GPU內(nèi)部的傳輸來說,數(shù)據(jù)在主機(jī)內(nèi)存與GPU內(nèi)存之間相互傳輸,其花費(fèi)的時(shí)間是巨大的,因此要謹(jǐn)慎使用。由其是從CPU到GPU的逆向傳輸。
在前面“ 當(dāng)前顯卡設(shè)備運(yùn)行的問題” 中 提及到該方面的問題。
一個(gè)簡單的例子
[cpp] view plaincopy#include 《stdio.h》
#include 《stdlib.h》
#include 《GL/glew.h》
#include 《GL/glut.h》
int main(int argc, char **argv) {
// 這里聲明紋理的大小為:teSize;而數(shù)組的大小就必須是texSize*texSize*4
int texSize = 2;
int i;
// 生成測試數(shù)組的數(shù)據(jù)
float* data = (float*)malloc(4*texSize*texSize*sizeof(float));
float* result = (float*)malloc(4*texSize*texSize*sizeof(float));
for (i=0; i《texSize*texSize*4; i++)
data[i] = (i+1.0)*0.01F;
// 初始化OpenGL的環(huán)境
glutInit (&argc, argv);
glutCreateWindow(“TEST1”);
glewInit();
// 視口的比例是 1:1 pixel=texel=data 使得三者一一對應(yīng)
glMatrixMode(GL_PROJECTION);
glLoadIdentity();
gluOrtho2D(0.0,texSize,0.0,texSize);
glMatrixMode(GL_MODELVIEW);
glLoadIdentity();
glViewport(0,0,texSize,texSize);
// 生成并綁定一個(gè)FBO,也就是生成一個(gè)離屏渲染對像
GLuint fb;
glGenFramebuffersEXT(1,&fb);
glBindFramebufferEXT(GL_FRAMEBUFFER_EXT,fb);
// 生成兩個(gè)紋理,一個(gè)是用來保存數(shù)據(jù)的紋理,一個(gè)是用作渲染對像的紋理
GLuint tex,fboTex;
glGenTextures (1, &tex);
glGenTextures (1, &fboTex);
glBindTexture(GL_TEXTURE_RECTANGLE_ARB,fboTex);
// 設(shè)定紋理參數(shù)
glTexParameteri(GL_TEXTURE_RECTANGLE_ARB,
GL_TEXTURE_MIN_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_RECTANGLE_ARB,
GL_TEXTURE_MAG_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_RECTANGLE_ARB,
GL_TEXTURE_WRAP_S, GL_CLAMP);
glTexParameteri(GL_TEXTURE_RECTANGLE_ARB,
GL_TEXTURE_WRAP_T, GL_CLAMP);
// 這里在顯卡上分配FBO紋理的貯存空間,每個(gè)元素的初始值是0;
glTexImage2D(GL_TEXTURE_RECTANGLE_ARB,0,GL_RGBA32F_ARB,
texSize,texSize,0,GL_RGBA,GL_FLOAT,0);
// 分配數(shù)據(jù)紋理的顯存空間
glBindTexture(GL_TEXTURE_RECTANGLE_ARB,tex);
glTexParameteri(GL_TEXTURE_RECTANGLE_ARB,
GL_TEXTURE_MIN_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_RECTANGLE_ARB,
GL_TEXTURE_MAG_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_RECTANGLE_ARB,
GL_TEXTURE_WRAP_S, GL_CLAMP);
glTexParameteri(GL_TEXTURE_RECTANGLE_ARB,
GL_TEXTURE_WRAP_T, GL_CLAMP);
glTexEnvf(GL_TEXTURE_ENV,GL_TEXTURE_ENV_COLOR,GL_DECAL);
glTexImage2D(GL_TEXTURE_RECTANGLE_ARB,0,GL_RGBA32F_ARB,
texSize,texSize,0,GL_RGBA,GL_FLOAT,0);
//把當(dāng)前的FBO對像,與FBO紋理綁定在一起
glFramebufferTexture2DEXT(GL_FRAMEBUFFER_EXT,
GL_COLOR_ATTACHMENT0_EXT,
GL_TEXTURE_RECTANGLE_ARB,fboTex,0);
// 把本地?cái)?shù)據(jù)傳輸?shù)斤@卡的紋理上。
glBindTexture(GL_TEXTURE_RECTANGLE_ARB,tex);
glTexSubImage2D(GL_TEXTURE_RECTANGLE_ARB,0,0,0,texSize,texSize,
GL_RGBA,GL_FLOAT,data);
//--------------------begin-------------------------
//以下代碼是渲染一個(gè)大小為texSize * texSize矩形,
//其作用就是把紋理中的數(shù)據(jù),經(jīng)過處理后,保存到幀緩沖中去,
//由于用到了離屏渲染,這里的幀緩沖區(qū)指的就是FBO紋理。
//在這里,只是簡單地把數(shù)據(jù)從紋理直接傳送到幀緩沖中,
//沒有對這些流過GPU的數(shù)據(jù)作任何處理,但是如果我們會(huì)用CG、
//GLSL等高級(jí)著色語言,對顯卡進(jìn)行編程,便可以在GPU中
//截獲這些數(shù)據(jù),并對它們進(jìn)行任何我們所想要的復(fù)雜運(yùn)算。
//這就是GPGPU技術(shù)的精髓所在。問題討論:www.physdev.com
glColor4f(1.00f,1.00f,1.00f,1.0f);
glBindTexture(GL_TEXTURE_RECTANGLE_ARB,tex);
glEnable(GL_TEXTURE_RECTANGLE_ARB);
glBegin(GL_QUADS);
glTexCoord2f(0.0, 0.0);
glVertex2f(0.0, 0.0);
glTexCoord2f(texSize, 0.0);
glVertex2f(texSize, 0.0);
glTexCoord2f(texSize, texSize);
glVertex2f(texSize, texSize);
glTexCoord2f(0.0, texSize);
glVertex2f(0.0, texSize);
glEnd();
//--------------------end------------------------
// 從幀緩沖中讀取數(shù)據(jù),并把數(shù)據(jù)保存到result數(shù)組中。
glReadBuffer(GL_COLOR_ATTACHMENT0_EXT);
glReadPixels(0, 0, texSize, texSize,GL_RGBA,GL_FLOAT,result);
// 顯示最終的結(jié)果
printf(“Data before roundtrip: ”);
for (i=0; i《texSize*texSize*4; i++)
printf(“%f ”,data[i]);
printf(“Data after roundtrip: ”);
for (i=0; i《texSize*texSize*4; i++)
printf(“%f ”,result[i]);
// 釋放本地內(nèi)存
free(data);
free(result);
// 釋放顯卡內(nèi)存
glDeleteFramebuffersEXT (1,&fb);
glDeleteTextures (1,&tex);
glDeleteTextures(1,&fboTex);
return 0;
}
現(xiàn)在是時(shí)候讓我們回頭來看一下前面要解決的問題,我強(qiáng)烈建議在開始一個(gè)新的更高級(jí)的話題之前,讓我們先弄一個(gè)顯淺的例子來實(shí)踐一下。下面通過一個(gè)小的程序,嘗試著使用各種不同的紋理格式,紋理對像以及內(nèi)部格式,來把數(shù)據(jù)發(fā)送到GPU,然后再把數(shù)據(jù)從GPU取回來,保存在CPU的另一個(gè)數(shù)組中。在這里,兩個(gè)過程都沒有對數(shù)據(jù)作任何運(yùn)算修該,目的只是看一下數(shù)據(jù)GPU和CPU之間相互傳輸,所需要使用到的技術(shù)及要注意的細(xì)節(jié)。也就是把前面提及到的幾個(gè)有迷惑性的問題放在同一個(gè)程序中來運(yùn)行一下。在稍后的章節(jié)中將會(huì)詳細(xì)討論如何來解決這些可能會(huì)出現(xiàn)的問題。
由于趕著要完成整個(gè)教程,這里就只寫了一個(gè)最為簡單的小程序,采用rectangle紋理、ARB_texture_float作紋理對像并且只能在NVIDIA的顯卡上運(yùn)行。
你可以在這里下載到為ATI顯卡寫的另一個(gè)版本。

![]()
以上代碼是理解GPU編程的基礎(chǔ),如果你完全看得懂,并且能對這代碼作簡單的修改運(yùn)用的話,那恭喜你,你已經(jīng)向成功邁進(jìn)了一大步,并可以繼續(xù)往下看,走向更深入的學(xué)習(xí)了。但如看不懂,那回頭再看一編吧。
Back to top
GPGPU 概念 2:內(nèi)核(Kernels) = 著色器(shaders)
在這一章節(jié)中,我們來討論GPU和CPU兩大運(yùn)算模塊最基本的區(qū)別,以及理清一些算法和思想。一但我們弄清楚了GPU是如何進(jìn)行數(shù)據(jù)并行運(yùn)算的,那我們要編寫一個(gè)自已的著色程序,還是比較容易的。
面向循環(huán)的CPU運(yùn)算 vs. 面向內(nèi)核的GPU數(shù)據(jù)并行運(yùn)算
讓我們來回憶一下我們所想要解決的問題:y = y + alpha* x; 在CPU上,通常我們會(huì)使用一個(gè)循環(huán)來遍歷數(shù)組中的每個(gè)元素。如下:
[cpp] view plaincopyfor (int i=0; i《N; i++)
dataY[i] = dataY[i] + alpha * dataX[i];
每一次的循環(huán),都會(huì)有兩個(gè)層次的運(yùn)算在同時(shí)運(yùn)作:在循環(huán)這外,有一個(gè)循環(huán)計(jì)數(shù)器在不斷遞增,并與我們的數(shù)組的長度值作比較。而在循環(huán)的內(nèi)部,我們利用循環(huán)計(jì)數(shù)器來確定數(shù)組的一個(gè)固定位置,并對數(shù)組該位置的數(shù)據(jù)進(jìn)行訪問,在分別得到兩個(gè)數(shù)組該位置的值之后,我們便可以實(shí)現(xiàn)我們所想要的運(yùn)算:兩個(gè)數(shù)組的每個(gè)元素相加了。這個(gè)運(yùn)算有一個(gè)非常重要的特點(diǎn):那就是我們所要訪問和計(jì)算的每個(gè)數(shù)組元數(shù),它們之間是相互獨(dú)立的。這句話的意思是:不管是輸入的數(shù)組,還是輸出結(jié)果的數(shù)組,對于同一個(gè)數(shù)組內(nèi)的各個(gè)元素是都是相互獨(dú)立的,我們可以不按順序從第一個(gè)算到最后一個(gè),可先算最后一個(gè),再算第一個(gè),或在中間任意位置選一個(gè)先算,它得到的最終結(jié)果是不變的。如果我們有一個(gè)數(shù)組運(yùn)算器,或者我們有N個(gè)CPU的話,我們便可以同一時(shí)間把整個(gè)數(shù)組給算出來,這樣就根本不需要一個(gè)外部的循環(huán)。我們把這樣的示例叫做SIMD(single instruction multiple data)。現(xiàn)在有一種技術(shù)叫做“partial loop unrolling”就是讓允許編譯器對代碼進(jìn)行優(yōu)化,讓程序在一些支持最新特性(如:SSE , SSE2)的CPU上能得到更高效的并行運(yùn)行。
在我們這個(gè)例子中,輸入數(shù)數(shù)組的索引與輸出數(shù)組的索引是一樣,更準(zhǔn)確地說,是所有輸入數(shù)組下標(biāo),都與輸出數(shù)組的下標(biāo)是相同的,另外,在對于兩個(gè)數(shù)組,也沒有下標(biāo)的錯(cuò)位訪問或一對多的訪問現(xiàn)像,如:y[i] = -x[i-1] + 2*x[[i] - x[i+1] 。這個(gè)公式可以用一句不太專業(yè)的語言來描術(shù):“組數(shù)Y中每個(gè)元素的值等于數(shù)組X中對應(yīng)下標(biāo)元素的值的兩倍,再減去該下標(biāo)位置左右兩邊元素的值。”
在這里,我們打算使用來實(shí)現(xiàn)我們所要的運(yùn)算的GPU可編程模塊,叫做片段管線(fragment pipeline),它是由多個(gè)并行處理單元組成的,在GeFore7800GTX中,并行處理單元的個(gè)數(shù)多達(dá)24個(gè)。在硬件和驅(qū)動(dòng)邏輯中,每個(gè)數(shù)據(jù)項(xiàng)會(huì)被自動(dòng)分配到不同的渲染線管線中去處理,到底是如何分配,則是沒法編程控制的。從概念觀點(diǎn)上看,所有對每個(gè)數(shù)據(jù)頂?shù)倪\(yùn)算工作都是相互獨(dú)立的,也就是說不同片段在通過管線被處理的過程中,是不相互影響的。在前面的章節(jié)中我們曾討論過,如何實(shí)現(xiàn)用一個(gè)紋理來作為渲染目標(biāo),以及如何把我們的數(shù)組保存到一個(gè)紋理上。因此這里我們分析一下這種運(yùn)算方式:片段管線就像是一個(gè)數(shù)組處理器,它有能力一次處理一張紋理大小的數(shù)據(jù)。雖然在內(nèi)部運(yùn)算過程中,數(shù)據(jù)會(huì)被分割開來然后分配到不同的片段處理器中去,但是我們沒辦法控制片段被處理的先后順序,我們所能知道的就是“地址”,也就是保存運(yùn)算最終結(jié)果的那張紋理的紋理坐標(biāo)。我們可能想像為所有工作都是并行的,沒有任何的數(shù)據(jù)相互依賴性。這就是我們通常所說的數(shù)據(jù)并行運(yùn)算(data-paralel computing)。
現(xiàn)在,我們已經(jīng)知道了解決問題的核心算法,我們可以開始討論如何用可編程片段管線來編程實(shí)現(xiàn)了。內(nèi)核,在GPU中被叫做著色器。所以,我們要做的就是寫一個(gè)可能解決問題的著色器,然后把它包含在我們的程序中。在本教程程中,我們會(huì)分別討論如何用CG著色語言及GLSL著色語言來實(shí)現(xiàn),接下來兩個(gè)小節(jié)就是對兩種語言實(shí)現(xiàn)方法的討論,我們只要學(xué)會(huì)其中一種方法就可以了,兩種語言各有它自已的優(yōu)缺點(diǎn),至于哪個(gè)更好一點(diǎn),則不是本教程所要討論的范圍。
用CG著色語言來編寫一個(gè)著色器
為了用CG語言來著色渲染,我們首先要來區(qū)分一下CG著色語言和CG運(yùn)行時(shí)函數(shù),前者是一門新的編程語言,所寫的程序經(jīng)編譯后可以在GPU上運(yùn)行,后者是C語言所寫的一系列函數(shù),在CPU上運(yùn)算,主要是用來初始化環(huán)境,把數(shù)據(jù)傳送給GPU等。在GPU中,有兩種不同的著色,對應(yīng)顯卡渲染流水線的兩個(gè)不同的階段,也就是頂點(diǎn)著色和片段著色。本教程中,頂點(diǎn)著色階段,我們采用固定渲染管線。只在片段著色階段進(jìn)行編程。在這里,使用片段管線能更容易解決我們的問題,當(dāng)然,頂點(diǎn)著色也會(huì)有它的高級(jí)用途,但本文不作介紹。另外,從傳統(tǒng)上講,片段著色管線提供更強(qiáng)大的運(yùn)算能力。
讓我們從一段寫好了的CG著色代碼開始。回憶一下CPU內(nèi)核中包含的一些算法:在兩個(gè)包含有浮點(diǎn)數(shù)據(jù)的數(shù)組中查找對應(yīng)的值。我們知道在GPU中紋理就等同于CPU的數(shù)組,因此在這里我們使用紋理查找到代替數(shù)組查找。在圖形運(yùn)算中,我們通過給定的紋理坐標(biāo)來對紋理進(jìn)行采樣。這里有一個(gè)問題,就是如何利用硬件自動(dòng)計(jì)算生成正確的紋理坐標(biāo)。我們把這個(gè)問題壓后到下面的章節(jié)來討論。為了處理一些浮點(diǎn)的常量,我們有兩種處理的方法可選:我們可以把這些常量包含在著色代碼代中,但是如果要該變這些常量的值的話,我們就得把著色代碼重新編譯一次。另一種方法更高效一點(diǎn),就是把常量的值作為一個(gè)uniform參數(shù)傳遞給GPU。uniform參數(shù)的意思就是:在整個(gè)渲染過程中值不會(huì)被改變的。以下代碼就是采用較高較的方法寫的。
[cpp] view plaincopyfloat saxpy (
float2 coords : TEXCOORD0,
uniform sampler2D textureY,
uniform sampler2D textureX,
uniform float alpha ) : COLOR
{
float result;
float yval=y_old[i];
float y = tex2D(textureY,coords);
float xval=x[i];
float x = tex2D(textureX,coords);
y_new[i]=yval+alpha*xval;
result = y + alpha * x;
return result;
}
從概念上講,一個(gè)片段著色器,就是像上像這樣的一段小程序,這段代碼在顯卡上會(huì)對每個(gè)片段運(yùn)行一編。在我們的代碼中,程序被命名為saxpy。它會(huì)接收幾個(gè)輸入?yún)?shù),并返回一個(gè)浮點(diǎn)值。用作變量復(fù)制的語法叫做語義綁定(semantics binding):輸入輸出參數(shù)名稱是各種不同的片段靜態(tài)變量的標(biāo)識(shí),在前面的章節(jié)中我們把這個(gè)叫“地址”。片段著色器的輸出參數(shù)必須綁定為COLOR語義,雖然這個(gè)語義不是很直觀,因?yàn)槲覀兊妮敵鰠?shù)并不是傳統(tǒng)作用上顏色,但是我們還是必須這樣做。綁定一個(gè)二分量的浮點(diǎn)元組(tuple ,float2)到TEXCOORD0語義上,這樣便可以在運(yùn)行時(shí)為每個(gè)像素指定一對紋理坐標(biāo)。對于如何在參數(shù)中定義一個(gè)紋理樣本以及采用哪一個(gè)紋理采樣函數(shù),這就要看我們種用了哪一種紋理對像,參考下表:
如果我們使用的是四通道的紋理而不是LUMINANCE格式的紋理,那們只須把上面代碼中的用來保存紋理查詢結(jié)果的浮點(diǎn)型變量改為四分量的浮點(diǎn)變量(float4 )就可以了。由于GPU具有并行運(yùn)算四分量數(shù)的能力,因此對于使用了rectangle為對像的RGBA格式紋理,我們可以采用以下代碼:
[cpp] view plaincopyfloat4 saxpy (
float2 coords : TEXCOORD0,
uniform samplerRECT textureY,
uniform samplerRECT textureX,
uniform float alpha ) : COLOR
{
float4 result;
float4 y = texRECT(textureY,coords);
float4 x = texRECT(textureX,coords);
result = y + alpha*x;
// equivalent: result.rgba=y.rgba+alpha*x.rgba
// or: result.r=y.r+alpha*x.y; result.g=。。。
return result;
}
我們可以把著色代碼保存在字符數(shù)組或文本文件中,然后通過OpenGL的CG運(yùn)行時(shí)函數(shù)來訪問它們。
建立CG運(yùn)行環(huán)境
在這一小節(jié),中描術(shù)了如何在OpenGL應(yīng)用程序中建立Cg運(yùn)行環(huán)境。首先,我們要包含CG的頭文件(#include 《cg/cggl.h》),并且把CG的庫函數(shù)指定到編譯連接選項(xiàng)中,然后聲明一些變量。
[cpp] view plaincopy// Cg vars
CGcontext cgContext;
CGprofile fragmentProfile;
CGprogram fragmentProgram;
CGparameter yParam, xParam, alphaParam;
char* program_source = “float saxpy( [。。。。] return result; } ”;
CGcontext 是一個(gè)指向CG運(yùn)行時(shí)組件的入口指針,由于我們打算對片段管線進(jìn)行編程,因此我們要一個(gè)fragment profile,以及一個(gè)程序container。為了簡單起見,我們還聲明了三個(gè)句柄,分別對應(yīng)了著色程序中的三個(gè)沒有語義的入口參數(shù)。我們用一個(gè)全局的字符串變量來保存前面所寫好的著色代碼。現(xiàn)在就把所有的CG初始化工作放在一個(gè)函數(shù)中完成。這里只作了最簡單的介紹,詳細(xì)的內(nèi)容可以查看CG手冊,或者到Cg Toolkit page.網(wǎng)頁上學(xué)習(xí)一下。
譯注:對于CG入門,可以看一下《CG編程入門》這篇文章:http://www.physdev.com/phpbb/cms_view_article.php?aid=7
[cpp] view plaincopyvoid initCG(void) {
// set up Cg
cgContext = cgCreateContext();
fragmentProfile = cgGLGetLatestProfile(CG_GL_FRAGMENT);
cgGLSetOptimalOptions(fragmentProfile);
// create fragment program
fragmentProgram = cgCreateProgram (
cgContext,CG_SOURCE,program_source,
fragmentProfile,“saxpy”,NULL);
// load program
cgGLLoadProgram (fragmentProgram);
// and get parameter handles by name
yParam = cgGetNamedParameter (fragmentProgram,“textureY”);
xParam = cgGetNamedParameter (fragmentProgram,“textureX”);
alphaParam = cgGetNamedParameter (fragmentProgram,“alpha”);
}
用OpenGL著色語言來編寫一個(gè)著色器
使用OpenGL的高級(jí)著色語言,我們不需要另外引入任何的頭文件或庫文件,因因它們在安裝驅(qū)動(dòng)程序的時(shí)候就一起被建立好了。三個(gè)OpenGL的擴(kuò)展:(ARB_shader_objects,ARB_vertex_shader 和ARB_fragment_shader)定義了相關(guān)的接口函數(shù)。它的說明書(specification )中對語言本身作了定義。兩者,API和GLSL語言,現(xiàn)在都是OpenGL2.0內(nèi)核的一個(gè)重要組成部份。但是如果我們用的是OpenGL的老版本,就要用到擴(kuò)展。
我們?yōu)槌绦驅(qū)ο穸x了一系列的全局變量,包括著色器對像及數(shù)據(jù)變量的句柄,通過使用這些句柄,我們可以訪問著色程序中的變量。前面兩個(gè)對像是簡單的數(shù)據(jù)容器,由OpenGL進(jìn)行管理。一個(gè)完整的著色程序是由頂點(diǎn)著色和片段著色兩大部份組成的,每部分又可以由多個(gè)著色程序組成。
[cpp] view plaincopy// GLSL vars
GLhandleARB programObject;
GLhandleARB shaderObject;
GLint yParam, xParam, alphaParam;
編寫著色程序和使用Cg語言是相似的,下面提供了兩個(gè)GLSL的例子,兩個(gè)主程序的不同之處在于我們所采用的紋理格式。變量的類型入關(guān)鍵字與CG有很大的不同,一定要按照OpenGL的定義來寫。
[cpp] view plaincopy// shader for luminance data | // shader for RGBA data
// and texture rectangles | // and texture2D
|
uniform samplerRect textureY; | uniform sampler2D textureY;
uniform samplerRect textureX; | uniform sampler2D textureX;
uniform float alpha; | uniform float alpha;
|
void main(void) { | void main(void) {
float y = textureRect( | vec4 y = texture2D(
textureY, | textureY,
gl_TexCoord[0].st).x; | gl_TexCoord[0].st);
float x = textureRect( | vec4 x = texture2D(
textureX, | textureX
gl_TexCoord[0].st).x; | gl_TexCoord[0].st);
gl_FragColor.x = | gl_FragColor =
y + alpha*x; | y + alpha*x;
} | }
下面代碼就是把所有對GLSL的初始化工作放在一個(gè)函數(shù)中實(shí)現(xiàn),GLSL API是被設(shè)計(jì)成可以模擬傳統(tǒng)的編譯及連接過程,更多的細(xì)節(jié),請參考橙皮書(Orange Book),或者查找一些GLSL的教程來學(xué)習(xí)一下,推薦到Lighthouse 3D’s GLSL tutorial 網(wǎng)站上看一下
[cpp] view plaincopyvoid initGLSL(void) {
// create program object
programObject = glCreateProgramObjectARB();
// create shader object (fragment shader) and attach to program
shaderObject = glCreateShaderObjectARB(GL_FRAGMENT_SHADER_ARB);
glAttachObjectARB (programObject, shaderObject);
// set source to shader object
glShaderSourceARB(shaderObject, 1, &program_source, NULL);
// compile
glCompileShaderARB(shaderObject);
// link program object together
glLinkProgramARB(programObject);
// Get location of the texture samplers for future use
yParam = glGetUniformLocationARB(programObject, “textureY”);
xParam = glGetUniformLocationARB(programObject, “textureX”);
alphaParam = glGetUniformLocationARB(programObject, “alpha”);
}
Back to top
GPGPU 概念3:運(yùn)算 = 繪圖
在這一章節(jié)里,我們來討論一下如何把本教程前面所學(xué)到的知識(shí)拼湊起來,以及如何使用這些知識(shí)來解決前面所提出的加權(quán)數(shù)組相加問題:y_new =y_old +alpha *x 。關(guān)于執(zhí)行運(yùn)算的部份,我們把所有運(yùn)算都放在performComputation()這個(gè)函數(shù)中實(shí)現(xiàn)。一共有四個(gè)步驟:首先是激活內(nèi)核,然后用著色函數(shù)來分配輸入輸出數(shù)組的空間,接著是通過渲染一個(gè)適當(dāng)?shù)膸缀螆D形來觸發(fā)GPU的運(yùn)算,最后一步是簡單驗(yàn)證一下我們前面所列出的所有的基本理論。
準(zhǔn)備好運(yùn)算內(nèi)核
使用CG運(yùn)行時(shí)函數(shù)來激活運(yùn)算內(nèi)核就是顯卡著色程序。首先用enable函數(shù)來激活一個(gè)片段profile,然后把前面所寫的著色代碼傳送到顯卡上并綁定好。按規(guī)定,在同一時(shí)間內(nèi)只能有一個(gè)著色器是活動(dòng)的,更準(zhǔn)確的說,是同一時(shí)間內(nèi),只能分別激活一個(gè)頂點(diǎn)著色程序和一個(gè)片段著色程序。由于本教程中采用了固定的頂點(diǎn)渲染管線,所以我們只關(guān)注片段著色就行了,只需要下面兩行代碼便可以了。
[cpp] view plaincopy// enable fragment profile
cgGLEnableProfile(fragmentProfile);
// bind saxpy program
cgGLBindProgram(fragmentProgram);
如果使用的是GLSL著色語言,這一步就更容易實(shí)現(xiàn)了,如果我們的著色代碼已以被成功地編譯連接,那么剩下我們所需要做的就只是把程序作為渲染管線的一部分安裝好,代碼如下:
glUseProgramObjectARB(programObject);
建立用于輸入的數(shù)組和紋理
在CG環(huán)境中,我們先要把紋理的標(biāo)識(shí)與對應(yīng)的一個(gè)uniform樣本值關(guān)聯(lián)起來,然后激活該樣本。這樣該紋理樣本便可以在CG中被直接使用了。
[cpp] view plaincopy// enable texture y_old (read-only)
cgGLSetTextureParameter(yParam, y_oldTexID);
cgGLEnableTextureParameter(yParam);
// enable texture x (read-only)
cgGLSetTextureParameter(xParam, xTexID);
cgGLEnableTextureParameter(xParam);
// enable scalar alpha
cgSetParameter1f(alphaParam, alpha);
但在GLSL中,我們必須把紋理與不同的紋理單元綁定在一起(在CG中,這部分由程序自動(dòng)完成),然后把這些紋理單元傳遞給我們的uniform參數(shù)。
[cpp] view plaincopy// enable texture y_old (read-only)
glActiveTexture(GL_TEXTURE0);
glBindTexture(textureParameters.texTarget,yTexID[readTex]);
glUniform1iARB(yParam,0); // texunit 0
// enable texture x (read-only)
glActiveTexture(GL_TEXTURE1);
glBindTexture(textureParameters.texTarget,xTexID);
glUniform1iARB(xParam, 1); // texunit 1
// enable scalar alpha
glUniform1fARB(alphaParam,alpha);
建立用于輸出的紋理及數(shù)組
定義用于輸出的紋理,從本質(zhì)上講,這和把數(shù)據(jù)傳輸?shù)揭粋€(gè)FBO紋理上的操作是一樣的,我們只需要指定OpenGL函數(shù)參數(shù)的特定意義就可以了。這里我們只是簡單地改變輸出的方向,也就是,把目標(biāo)紋理與我們的FBO綁定在一起,然后使用標(biāo)準(zhǔn)的GL擴(kuò)展函數(shù)來把該FBO指為渲染的輸出目標(biāo)。
[cpp] view plaincopy// attach target texture to first attachment point
glFramebufferTexture2DEXT(GL_FRAMEBUFFER_EXT,
GL_COLOR_ATTACHMENT0_EXT,
texture_target, y_newTexID, 0);
// set the texture as render target
glDrawBuffer (GL_COLOR_ATTACHMENT0_EXT);
準(zhǔn)備運(yùn)算
讓們暫時(shí)先來回顧一下到目前為止,我們所做過了的工作:我們實(shí)現(xiàn)了目標(biāo)像素、紋理坐標(biāo)、要繪制的圖形三者元素一一對應(yīng)的關(guān)系。我們還寫好了一個(gè)片段著色器,用來讓每個(gè)片段渲染的時(shí)候都可以運(yùn)行一次。現(xiàn)在剩下來還要做的工作就是:繪制一個(gè)“合適的幾何圖形” ,這個(gè)合適的幾何圖形,必須保證保存在目標(biāo)紋理中的數(shù)據(jù)每個(gè)元素就會(huì)去執(zhí)行一次我們的片段著色程序。換句話來說,我們必須保證紋理中的每個(gè)數(shù)據(jù)頂在片段著色中只會(huì)被訪一次。只要指定好我們的投影及視口的設(shè)置,其它的工作就非常容易:我們所需要的就只是一個(gè)剛好能覆蓋整個(gè)視口的填充四邊形。我們定義一個(gè)這樣的四邊形,并調(diào)用標(biāo)準(zhǔn)的OpenGL函數(shù)來對其進(jìn)行渲染。這就意味著我們要直接指定四邊形四個(gè)角的頂點(diǎn)坐標(biāo),同樣地我們還要為每個(gè)頂點(diǎn)指定好正確的紋理坐標(biāo)。由于我們沒有對頂點(diǎn)著色進(jìn)行編程,程序會(huì)把四個(gè)頂點(diǎn)通過固定的渲染管線傳輸?shù)狡聊豢臻g中去。光冊處理器(一個(gè)位于頂點(diǎn)著色與片段著色之間的固定圖形處理單元)會(huì)在四個(gè)頂點(diǎn)之間進(jìn)行插值處理,生成新的頂點(diǎn)來把整個(gè)四邊形填滿。插值操作除了生成每個(gè)插值點(diǎn)的位置之外,還會(huì)自動(dòng)計(jì)算出每個(gè)新頂點(diǎn)的紋理坐標(biāo)。它會(huì)為四邊形中每個(gè)像素生成一個(gè)片段。由于我們在寫片段著色器中綁定了相關(guān)的語義,因此插值后的片段會(huì)被自動(dòng)發(fā)送到我們的片段著色程序中去進(jìn)行處理。換句話說,我們渲染的這個(gè)簡單的四邊形,就可以看作是片段著色程序的數(shù)據(jù)流生成器。由于目標(biāo)像素、紋理坐標(biāo)、要繪制的圖形三者元素都是一一對應(yīng)的,從而我們便可以實(shí)現(xiàn):為數(shù)組每個(gè)輸出位置觸發(fā)一次片段著色程序的運(yùn)行。也就是說通過渲染一個(gè)帶有紋理的四邊形,我們便可以觸發(fā)著色內(nèi)核的運(yùn)算行,著色內(nèi)核會(huì)為紋理或數(shù)組中的每個(gè)數(shù)據(jù)項(xiàng)運(yùn)行一次。
使用 texture rectangles 紋理坐標(biāo)是與像素坐標(biāo)相同的,我樣使用下面一小段代碼便可以實(shí)現(xiàn)了。
[cpp] view plaincopy// make quad filled to hit every pixel/texel
glPolygonMode(GL_FRONT,GL_FILL);
// and render quad
glBegin(GL_QUADS);
glTexCoord2f(0.0, 0.0);
glVertex2f(0.0, 0.0);
glTexCoord2f(texSize, 0.0);
glVertex2f(texSize, 0.0);
glTexCoord2f(texSize, texSize);
glVertex2f(texSize, texSize);
glTexCoord2f(0.0, texSize);
glVertex2f(0.0, texSize);
glEnd();
如果使用 texture2D ,就必須單位化所有的紋理坐標(biāo),等價(jià)的代碼如下:
[cpp] view plaincopy// make quad filled to hit every pixel/texel
glPolygonMode(GL_FRONT,GL_FILL);
// and render quad
glBegin(GL_QUADS);
glTexCoord2f(0.0, 0.0);
glVertex2f(0.0, 0.0);
glTexCoord2f(1.0, 0.0);
glVertex2f(texSize, 0.0);
glTexCoord2f(1.0, 1.0);
glVertex2f(texSize, texSize);
glTexCoord2f(0.0, 1.0);
glVertex2f(0.0, texSize);
glEnd();
這里提示一下那些做高級(jí)應(yīng)用的程序員:在我們的著色程序中,只用到了一組紋理坐標(biāo),但是我們也可以為每個(gè)頂點(diǎn)定義多組不同的紋理坐標(biāo),相關(guān)的更多細(xì)節(jié),可以查看一下glMultiTexCoord()函數(shù)的使用。
Back to top
GPGPU 概念 4: 反饋
當(dāng)運(yùn)算全部完成之后,的、得到的結(jié)果會(huì)被保存在目標(biāo)紋理y_new中。
多次渲染傳遞。
在一些通用運(yùn)算中,我們會(huì)希望把前一次運(yùn)算結(jié)果傳遞給下一個(gè)運(yùn)算用來作為后繼運(yùn)算的輸入變量。但是在GPU中,一個(gè)紋理不能同時(shí)被讀寫,這就意味著我們要?jiǎng)?chuàng)建另外一個(gè)渲染通道,并給它綁定不同的輸入輸出紋理,甚至要生成一個(gè)不同的運(yùn)算內(nèi)核。有一種非常重要的技術(shù)可以用來解決這種多次渲染傳遞的問題,讓運(yùn)算效率得到非常好的提高,這就是“乒乓”技術(shù)。
關(guān)于乒乓技術(shù)
乒乓技術(shù),是一個(gè)用來把渲染輸出轉(zhuǎn)換成為下一次運(yùn)算的輸入的技術(shù)。在本文中(y_new =y_old +alpha*x) ,這就意味我們要切換兩個(gè)紋理的角色,y_new 和y_old 。有三種可能的方法來實(shí)現(xiàn)這種技術(shù)(看一下以下這篇論文Simon Green‘s FBO slides ,這是最經(jīng)典的資料了):
為每個(gè)將要被用作渲染輸出的紋理指定一個(gè)綁定點(diǎn),并使用函數(shù)glBindFramebufferEXT()來為每個(gè)渲染通道綁定一個(gè)不同的FBO.
只使用一個(gè)FBO,但每次通道渲染的時(shí)候,使用函數(shù)glBindFramebufferEXT()來重新綁定渲染的目標(biāo)紋理。
使用一個(gè)FBO和多個(gè)綁定點(diǎn),使用函數(shù)glDrawBuffer()來交換它們。
由于每個(gè)FBO最多有4個(gè)綁定點(diǎn)可以被使用,而且,最后一種方法的運(yùn)算是最快的,我們在這里將詳細(xì)解釋一下,看看我們是如何在兩個(gè)不同的綁定點(diǎn)之間實(shí)現(xiàn)“乒乓” 的。
要實(shí)現(xiàn)這個(gè),我們首先需要一組用于管理控制的變量。
[cpp] view plaincopy// two textures identifiers referencing y_old and y_new
GLuint yTexID[2];
// ping pong management vars
int writeTex = 0;
int readTex = 1;
GLenum attachmentpoints[] = { GL_COLOR_ATTACHMENT0_EXT,
GL_COLOR_ATTACHMENT1_EXT
};
在運(yùn)算其間,我們只需要做的就是給內(nèi)核傳遞正確的參數(shù)值,并且每次運(yùn)算都要交換一次組組的索引值:
[cpp] view plaincopy// attach two textures to FBO
glFramebufferTexture2DEXT(GL_FRAMEBUFFER_EXT,
attachmentpoints[writeTex],
texture_Target, yTexID[writeTex], 0);
glFramebufferTexture2DEXT(GL_FRAMEBUFFER_EXT,
attachmentpoints[readTex],
texture_Target, yTexID[readTex], 0);
// enable fragment profile, bind program [。。。]
// enable texture x (read-only) and uniform parameter [。。。]
// iterate computation several times
for (int i=0; i《numIterations; i++) {
// set render destination
glDrawBuffer (attachmentpoints[writeTex]);
// enable texture y_old (read-only)
cgGLSetTextureParameter(yParam, yTexID[readTex]);
cgGLEnableTextureParameter(yParam);
// and render multitextured viewport-sized quad
// swap role of the two textures (read-only source becomes
// write-only target and the other way round):
swap();
}
Back to top
把所有東西放在一起
對本文附帶源代碼的一個(gè)簡要說明
在附帶的代碼例子中,使用到了本文所有闡述過的所有概念,主要實(shí)現(xiàn)了以下幾個(gè)運(yùn)算:
為每個(gè)數(shù)組生成一個(gè)浮點(diǎn)的紋理。
把初始化的數(shù)據(jù)傳輸?shù)郊y理中去 。
使用CG或者GLSL來生成一個(gè)片段著色器。
一個(gè)多次重復(fù)運(yùn)算的模塊,主要是用來演試“乒乓”技術(shù)。
把最終的運(yùn)算結(jié)果返回到主內(nèi)存中。
把結(jié)果與CPU的參考結(jié)果進(jìn)行比較。
執(zhí)行過行中的可變化部份
在代碼中,我們使用了一系列的結(jié)構(gòu)體來保存各種可能的參數(shù),主要是為了方便OpenGL的調(diào)用,例如:不同類型的浮點(diǎn)紋理擴(kuò)展,不同的紋理格式,不同的著色器之間的細(xì)微差別,等等。下面這段代碼就是這樣一個(gè)結(jié)構(gòu)體的示例,采用LUMINANCE格式,RECTANGLES紋理,及NV_float_buffer的擴(kuò)展。
[cpp] view plaincopyrect_nv_r_32.name = “TEXRECT - float_NV - R - 32”;
rect_nv_r_32.texTarget = GL_TEXTURE_RECTANGLE_ARB;
rect_nv_r_32.texInternalFormat = GL_FLOAT_R32_NV;
rect_nv_r_32.texFormat = GL_LUMINANCE;
rect_nv_r_32.shader_source = “float saxpy (”
“in float2 coords : TEXCOORD0,”
“uniform samplerRECT textureY,”
“uniform samplerRECT textureX,”
“uniform float alpha ) : COLOR {”
“float y = texRECT (textureY, coords);”
“float x = texRECT (textureX, coords);”
“return y+alpha*x; }”;
為了給不同的情況取得一個(gè)合適的工作版本,我們只須要查找和替換就可以了。或者使用第二個(gè)命令行參數(shù)如:rect_nv_r_32。在應(yīng)用程序中,一個(gè)全局變量textureParameters 指向我們實(shí)現(xiàn)要使用的結(jié)構(gòu)體。
命令行參數(shù)
在程序中,使用命令行參數(shù)來對程序進(jìn)行配置。如果你運(yùn)行該程序而沒帶任何參數(shù)的話,程序會(huì)輸出一個(gè)對各種不同參數(shù)的解釋。提醒大家注意的是:本程序?qū)γ钚袇?shù)的解釋是不穩(wěn)定的,一個(gè)不正確的參數(shù)有可能會(huì)造成程序的崩潰。因此我強(qiáng)烈建義大家使用輸出級(jí)的參數(shù)來顯示運(yùn)算的結(jié)果,這樣可以降低出現(xiàn)問題的可能性,尤其是當(dāng)你不相信某些運(yùn)算錯(cuò)誤的時(shí)候。請查看包含在示例中的批處理文件。
測試模式
本程序可以用來對一個(gè)給定的GPU及其驅(qū)動(dòng)的 結(jié)合進(jìn)行測試,主要是測試一下,看看哪種內(nèi)部格式及紋理排列是可以在FBO擴(kuò)展中被組合在一起使用的。示例中有一個(gè)批處理文件叫做:run_test_*.bat,是使用各種不同的命令行參數(shù)來運(yùn)行程序,并會(huì)生成一個(gè)報(bào)告文件。如果是在LINUX下,這個(gè)文件也可能當(dāng)作一個(gè)shell腳本來使用,只需要稍作修改就可以了。這ZIP文檔中包含有對一些顯卡測試后的結(jié)果。
基準(zhǔn)模式
這種模式被寫進(jìn)程序中,完全是為了好玩。它可以對不同的問題產(chǎn)成一個(gè)運(yùn)算時(shí)序,并在屏幕上生成MFLOP/s速率圖,和其它的一些性能測試軟件一樣。它并不代表GPU運(yùn)算能力的最高值,只是接近最高值的一種基準(zhǔn)性能測試。想知道如何運(yùn)行它的話,請查看命令行參數(shù)。
Back to top
附言
簡單對比一下Windows 和 Linux,NVIDIA 和 ATI 之間的差別
對于NVIDIA的顯卡,不管是Windows還是Linux,它們都提供了相同的函數(shù)來實(shí)現(xiàn)本教程中的例子。但如果是ATI的顯卡,它對LINUX的支持就不是很好。因此如果是ATI顯卡,目前還是建義在Windows下使用。
看一看這片相關(guān)的文章 table summarizing renderable texture formats on various hardware.
本文中提供下載的源代碼,是在NV4X以上的顯卡上編譯通過的。對于ATI的用戶,則要作以下的修改才行:在transferToTexture() 函數(shù)中,把NVIDIA相應(yīng)部份的代碼注釋掉,然使用ATI版本的代碼,如這里所描述的。
Cg 1.5 combined with the precompiled freeglut that ships with certain Linus distributions somehow breaks “true offscreen rendering” since a totally meaningless empty window pops up. There are three workarounds: Live with it. Use “real GLUT” instead of freeglut. Use plain X as described in the OpenGL.org wiki (just leave out the mapping of the created window to avoid it being displayed)。
問題及局限性
對于ATI顯卡,當(dāng)我們把數(shù)據(jù)傳送到紋理中去時(shí),如果使用glTexSubImage2D(),會(huì)產(chǎn)生一個(gè)非常奇怪的問題:就是原本是RGBA排列的數(shù)據(jù),會(huì)被改變?yōu)锽GRA格式。這是一個(gè)已得到確認(rèn)的BUG,希望在以后的版本中能得到修正,目前只能用glDrawPixels() 來代替。
而對于NV3X系列顯卡,如果想用glDrawPixels() ,則要求一定要在GPU中綁定一個(gè)著色程序。因此這里用glTexSubImage()函數(shù)代替(其實(shí)對于所有的NVIDIA 的顯卡,都推薦使用該函數(shù))。
ATI顯卡,在GLSL中不支持rectangles紋理采樣,甚至這樣的著色代碼沒法被編譯通過。samplerRect 或sampler2DRect 被指定為保留的關(guān)鍵字,ARB_texture_rextangle的擴(kuò)展說明書中得到定義,但驅(qū)動(dòng)沒有實(shí)現(xiàn)對它們的支持。可以用CG來代替。
在ATI中,當(dāng)我們使用glDrawPixels() 下載一個(gè)紋理的時(shí)候,如果紋理是被enable的,則會(huì)導(dǎo)致下載失敗,這不是一個(gè)BUG,但是也是一個(gè)有爭議性的問題,因?yàn)檫@樣會(huì)使程序難以調(diào)試。
對于NVIDIA的顯卡,我們不能把紋理渲染到紋理最大值的最后一行中去。也就是說,盡管我們用函數(shù)glGetIntegerv(GL_MAX_TEXTURE_SIZE,&maxtexsize); 得到的值是4096,但是你也只能渲染一張4095 x 4095 紋理。這是一個(gè)已知的BUG,同樣也希望以后能得到修正。
檢查OpenGL的錯(cuò)誤
高度推薦大家在代碼中經(jīng)常使用以下函數(shù)來檢測OpenGL運(yùn)行過程中產(chǎn)生的錯(cuò)誤。
[cpp] view plaincopyvoid checkGLErrors(const char *label) {
GLenum errCode;
const GLubyte *errStr;
if ((errCode = glGetError()) != GL_NO_ERROR) {
errStr = gluErrorString(errCode);
printf(“OpenGL ERROR: ”);
printf((char*)errStr);
printf(“(Label: ”);
printf(label);
printf(“) .”);
}
}
檢查FBO中的錯(cuò)誤
EXT_framebuffer_object 擴(kuò)展,定義了一個(gè)很好用的運(yùn)行時(shí)Debug函數(shù)。這里只列出了它的一些常見的反回值作參考,要詳細(xì)解釋這些返回信息,請查看規(guī)格說明書的framebuffer completeness 部分。
[cpp] view plaincopybool checkFramebufferStatus() {
GLenum status;
status=(GLenum)glCheckFramebufferStatusEXT(GL_FRAMEBUFFER_EXT);
switch(status) {
case GL_FRAMEBUFFER_COMPLETE_EXT:
return true;
case GL_FRAMEBUFFER_INCOMPLETE_ATTACHMENT_EXT:
printf(“Framebuffer incomplete,incomplete attachment ”);
return false;
case GL_FRAMEBUFFER_UNSUPPORTED_EXT:
printf(“Unsupported framebuffer format ”);
return false;
case GL_FRAMEBUFFER_INCOMPLETE_MISSING_ATTACHMENT_EXT:
printf(“Framebuffer incomplete,missing attachment ”);
return false;
case GL_FRAMEBUFFER_INCOMPLETE_DIMENSIONS_EXT:
printf(“Framebuffer incomplete,attached images
must have same dimensions ”);
return false;
case GL_FRAMEBUFFER_INCOMPLETE_FORMATS_EXT:
printf(“Framebuffer incomplete,attached images
must have same format ”);
return false;
case GL_FRAMEBUFFER_INCOMPLETE_DRAW_BUFFER_EXT:
printf(“Framebuffer incomplete,missing draw buffer ”);
return false;
case GL_FRAMEBUFFER_INCOMPLETE_READ_BUFFER_EXT:
printf(“Framebuffer incomplete,missing read buffer ”);
return false;
}
return false;
}
檢查CG的錯(cuò)誤
在CG中檢查錯(cuò)誤有一些細(xì)微的不同,一個(gè)自寫入的錯(cuò)誤處理句柄被傳遞給CG的錯(cuò)誤處理回調(diào)函數(shù)。
[cpp] view plaincopy// register the error callback once the context has been created
cgSetErrorCallback(cgErrorCallback);
// callback function
void cgErrorCallback(void) {
CGerror lastError = cgGetError();
if(lastError) {
printf(cgGetErrorString(lastError));
printf(cgGetLastListing(cgContext));
}
}
檢查GLSL的錯(cuò)誤
使用以下的函數(shù)來查看編譯的結(jié)果:
[cpp] view plaincopy/**
* copied from
* http://www.lighthouse3d.com/opengl/glsl/index.php?oglinfo
*/
void printInfoLog(GLhandleARB obj) {
int infologLength = 0;
int charsWritten = 0;
char *infoLog;
glGetObjectParameterivARB(obj,
GL_OBJECT_INFO_LOG_LENGTH_ARB,
&infologLength);
if (infologLength 》 1) {
infoLog = (char *)malloc(infologLength);
glGetInfoLogARB(obj, infologLength,
&charsWritten, infoLog);
printf(infoLog);
printf(“ ”);
free(infoLog);
}
}
大多數(shù)情況下,你可以使用以上查詢函數(shù),詳細(xì)內(nèi)容可以查看一下GLSL的規(guī)格說明書。還有另一個(gè)非常重要的查詢函數(shù),是用來檢查程序是否可以被連接:
[cpp] view plaincopyGLint success;
glGetObjectParameterivARB(programObject,
GL_OBJECT_LINK_STATUS_ARB,
&success);
if (!success) {
printf(“Shader could not be linked! ”);
}












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論