") 研究人員開發(fā)出一個端到端的機器學習系統(tǒng)Audio2Face
研究人員開發(fā)出一個端到端的機器學習系統(tǒng)Audio2Face
浙江大學和網(wǎng)易伏羲AI實驗室的研究人員開發(fā)出一個端到端的機器學習系統(tǒng)Audio2Face,可以從音頻中單獨生成實時面部動畫,同時考慮到音高和說話風格。
我們都知道動畫里的人物說話聲音都是由后期配音演員合成的。
但即使利用CrazyTalk這樣的軟件,也很難將電腦生成的嘴唇、嘴型等與配音演員進行很好地匹配,尤其是當對話時長在數(shù)十甚至數(shù)百小時的情況下。
但不要氣餒,動畫師的福音來了——Audio2Face問世!
Audio2Face是一款端到端的機器學習系統(tǒng),由浙江大學與網(wǎng)易伏羲AI實驗室共同打造。
它可以從音頻中單獨生成實時的面部動畫,更厲害的是,它還能調(diào)節(jié)音調(diào)和說話風格。該成果已經(jīng)發(fā)布至arXiv:
arXiv地址:
https://arxiv.org/pdf/1905.11142.pdf
團隊試圖構(gòu)建一個系統(tǒng),既要逼真又要低延遲
“我們的方法完全是基于音軌設計的,沒有任何其他輔助輸入(例如圖像),這就使得當我們試圖從聲音序列中回歸視覺空間的過程將會越來越具有挑戰(zhàn)。”論文共同作者解釋道,“另一個挑戰(zhàn)是面部活動涉及臉部幾何表面上相關(guān)區(qū)域的多重激活,這使得很難產(chǎn)生逼真且一致的面部變形。”
該團隊試圖構(gòu)建一個同時滿足“逼真”(生成的動畫必須反映可見語音運動中的說話模式)和低延遲(系統(tǒng)必須能夠進行近乎實時的動畫)要求的系統(tǒng)。他們還嘗試將其推廣,以便可以將生成的動畫重新定位到其他3D角色。
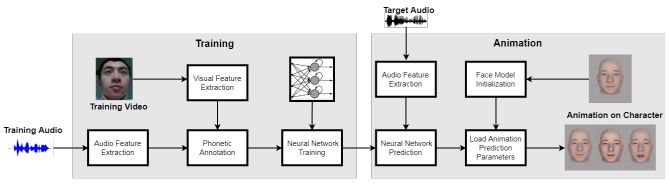
他們的方法包括從原始輸入音頻中提取手工制作的高級聲學特征,特別是梅爾頻率倒譜系數(shù)(MFC),或聲音的短期功率譜的表示。然后深度相機與mocap工具Faceshift一起,捕捉配音演員的面部動作并編制訓練集。

深度相機示意圖
之后研究人員構(gòu)建了帶有51個參數(shù)的3D卡通人臉模型,控制了臉部的不同部位(例如,眉毛,眼睛,嘴唇和下巴)。最后,他們利用上述AI系統(tǒng)將音頻上下文映射到參數(shù),產(chǎn)生唇部和面部動作。
1470個音頻樣本加持,機器學習模型的輸出“相當可以”
團隊使用一個訓練語料庫,其中包含兩個60分鐘、每秒30幀的女性和男性演員逐行閱讀劇本中臺詞的視頻,以及每個相應視頻幀的1470個音頻樣本(每幀總共2496個維度)。
團隊報告說,與ground truth相比,機器學習模型的輸出“相當可以”。它設法在測試音頻上重現(xiàn)準確的面部形狀,并且它一直“很好地”重新定位到不同的角色。此外,AI系統(tǒng)平均只需0.68毫秒即可從給定的音頻窗口中提取特征。
該團隊指出,AI無法跟隨演員的眨眼模式,主要是因為眨眼與言語的相關(guān)性非常弱。不過從廣義上講,該框架可能為適應性強、可擴展的音頻到面部動畫技術(shù)奠定基礎,這些技術(shù)幾乎適用于所有說話人和語言。
“評估結(jié)果顯示,我們的方法不僅可以從音頻中產(chǎn)生準確的唇部運動,還可以成功地消除說話人隨時間變化的面部動作,”他們寫道。
-
3D
+關(guān)注
關(guān)注
9文章
2949瀏覽量
109405 -
音頻
+關(guān)注
關(guān)注
29文章
3017瀏覽量
82996 -
機器學習
+關(guān)注
關(guān)注
66文章
8490瀏覽量
134022
原文標題:浙大研發(fā)AudioFace:隨心錄語音就能實時生成3D面部動畫
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
一文帶你厘清自動駕駛端到端架構(gòu)差異
研究人員開發(fā)出基于NVIDIA技術(shù)的AI模型用于檢測瘧疾
小米汽車端到端智駕技術(shù)介紹

【「具身智能機器人系統(tǒng)」閱讀體驗】+初品的體驗
端到端自動駕駛技術(shù)研究與分析
端到端在自動泊車的應用
端到端已來,智駕仿真測試該怎么做?

爆火的端到端如何加速智駕落地?
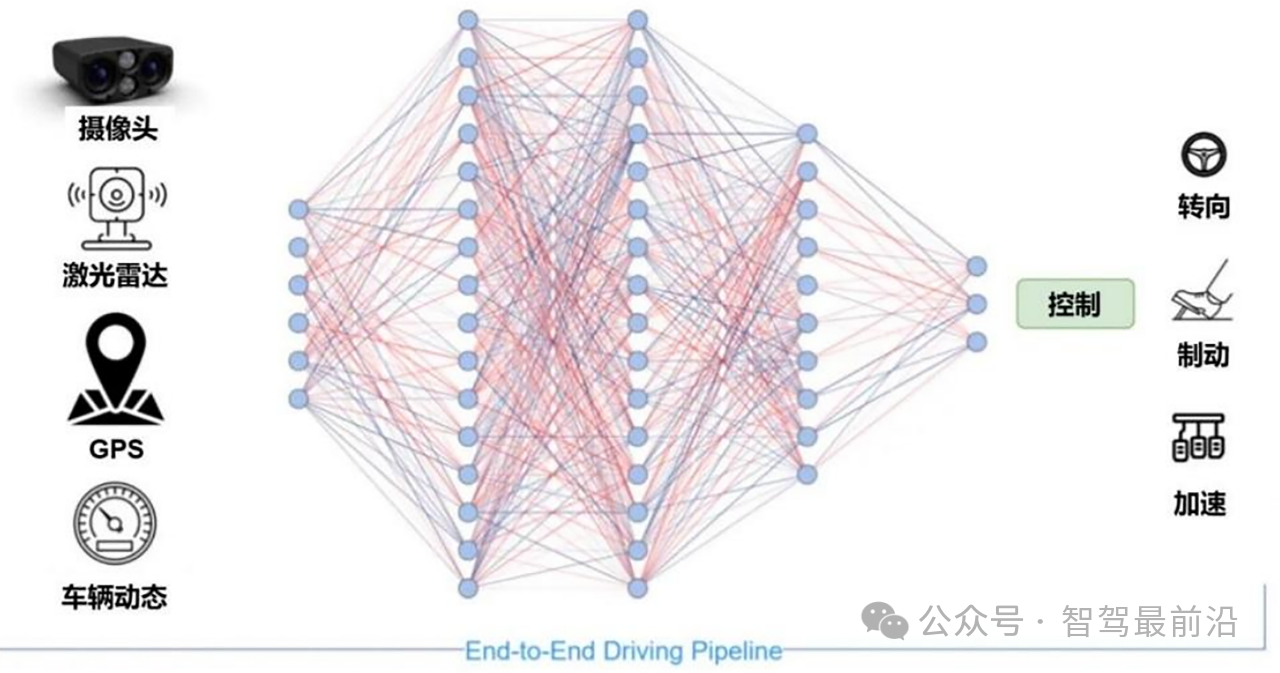
智己汽車“端到端”智駕方案推出,老司機真的會被取代嗎?
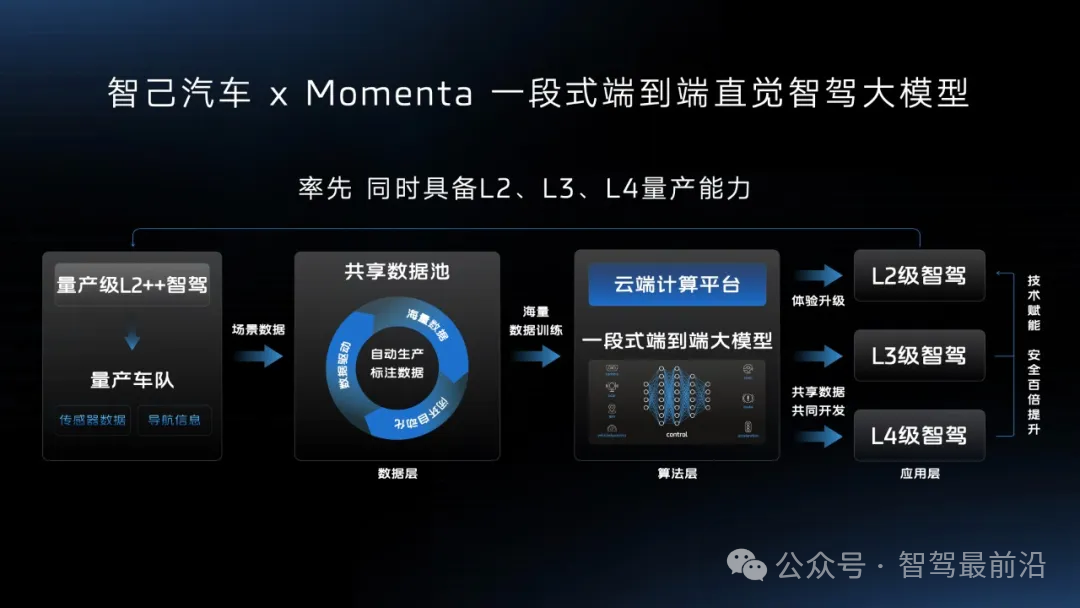
端到端讓智駕強者愈強時代來臨?
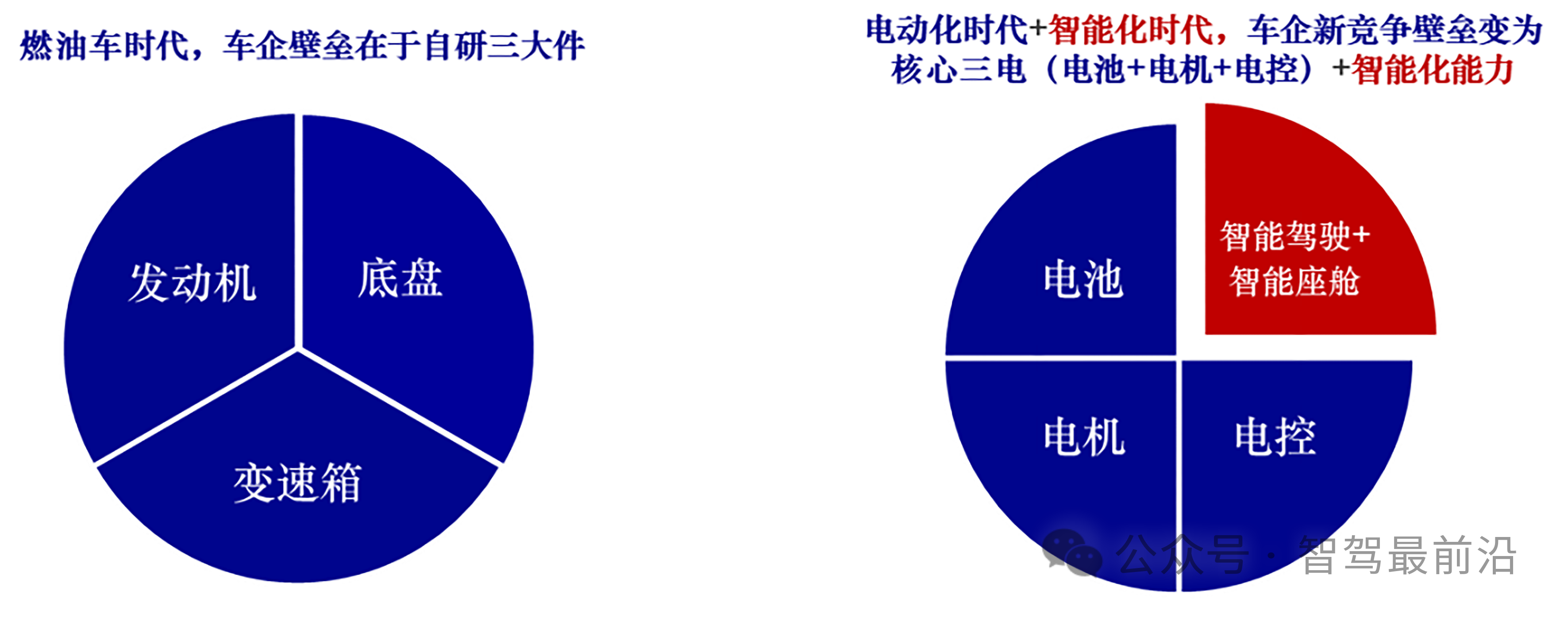
Mobileye端到端自動駕駛解決方案的深度解析

實現(xiàn)自動駕駛,唯有端到端?

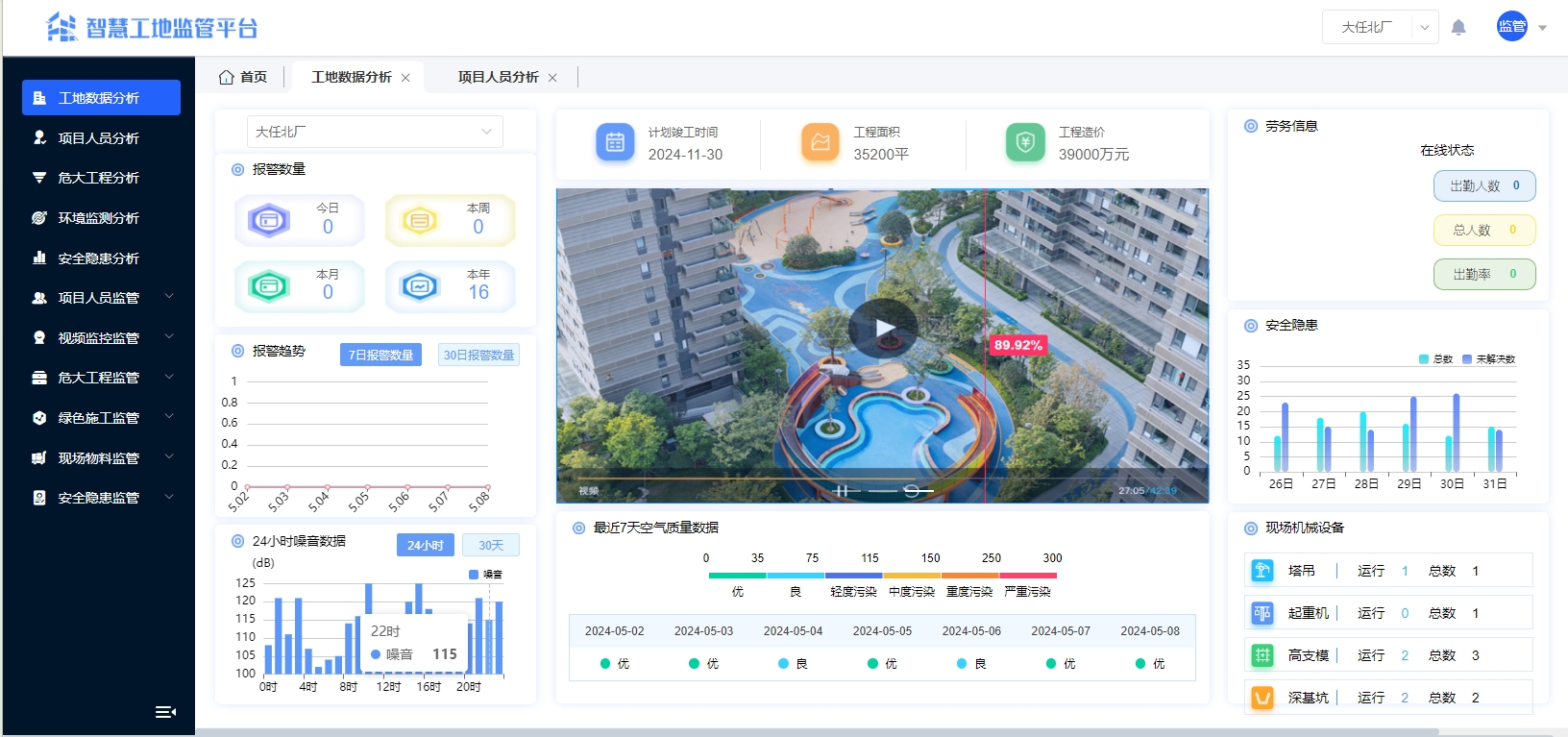
saas模式的一套智慧工地云平臺源碼,支持多端展示:PC端、大屏端、手機端、平板端
從C端到B端:我的前端技術(shù)進階之路





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論