 基于80251的嵌入式語音識別
基于80251的嵌入式語音識別
語音識別技術,廣泛來說是指語意識別和聲紋識別;從狹義上來說指語音語義的理解識別,也稱為自動語音識別(ASR)。其關鍵技術包括選擇識別單元、語音端點檢測、特征參數提取、聲學模型及語音模型的建立。語音識別技術目前在桌面系統、智能手機、導航設備等嵌入式領域均有一定程度的應用。其主要技術難題是識別系統的適應性較差、受背景噪聲影響較大,未來的發展方向應是無限詞匯量連續語音非特定人語音識別系統。
(1)信號處理及特征提取模塊
該模塊的主要任務是從輸入信號中提取特征,供聲學模型處理。同時,它一般也包括了一些信號處理技術,以盡可能降低環境噪聲、信道、說話人等因素對特征造成的影響。
(2)統計聲學模型
典型系統多采用基于一階隱馬爾科夫模型進行建模。
(3)發音詞典
發音詞典包含系統所能處理的詞匯集及其發音。發音詞典實際提供了聲學模型建模單元與語言模型建模單元間的映射。
(4)語言模型
語言模型對系統所針對的語言進行建模。理論上,包括正則語言,上下文無關文法在內的各種語言模型都可以作為語言模型,但目前各種系統普遍采用的還是基于統計的N元文法及其變體。
(5)解碼器
解碼器是語音識別系統的核心之一,其任務是對輸入的信號,根據聲學、語言模型及詞典,尋找能夠以最大概率輸出該信號的詞串,從數學角度可以更加清楚的了解上述模塊之間的關系。
當今語音識別技術的主流算法,主要有基于動態時間規整(DTW)算法、基于非參數模型的矢量量化(VQ)方法、基于參數模型的隱馬爾可夫模型(HMM)的方法、基于人工神經網絡(ANN)和支持向量機等語音識別方法。
對于語音識別技術實現的描述是相當完整的,而且其可以作為語音識別技術在資源緊缺型嵌入式平臺實現的一個較好的參考。
語音識別技術介紹
1.應用分類
(1)特定人與非特定人識別,特定人識別相對簡單,訓練者的識別率高,但非訓練者的識別率很低。而非特定人不受此影響,但實現復雜,識別率也相對低一些。
(2)語音識別與身份識別,前者提取各個命令者發出的語音的共性特征,而后者提取差異性特征。基于語音的身份識別主要應用于門禁等安全領域。語音識別廣泛應用于詞語識別,工業控制等領域。
(3)連續與非連續(孤立詞)語音識別,很明顯,連續語音識別難度較大。嵌入式產品集中在孤立詞語音識別方面。
(4)小詞匯量和大詞匯量語音識別。兩者選擇的方法是不一樣的,會在識別率和識別速度上折中考慮。
(5)關鍵詞識別,如在一段語音中抽取帶有某個關鍵詞的句子,或者根據哼的曲子旋律去搜索對應的歌曲等等。
本系統受限80251的計算和存儲性能,主要實現基于特定人的孤立詞語音識別。
2. 實現原理
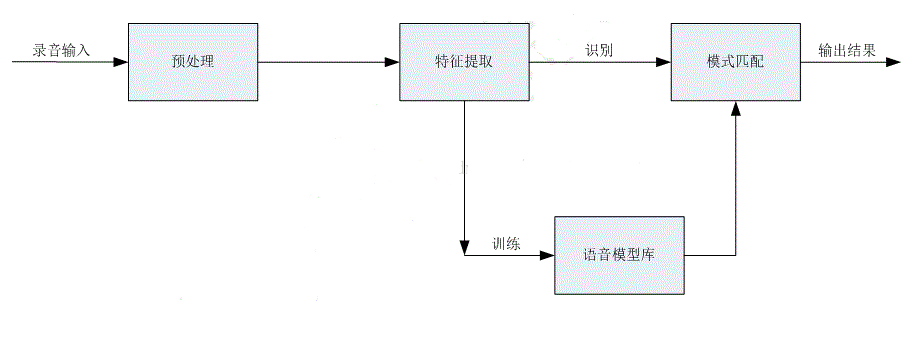
語音識別主要包括:預處理、特征提取、訓練和識別四個部分。
預處理主要包括去噪、預加重(去除口鼻輻射)、端點檢測(檢測有效語音段)等過程。
特征提取是對經過預處理后的語音信號進行特征參數分析。該過程就是從原始語音信號中抽取出能夠反映語音本質的特征參數,形成特征矢量序列。主要的特征參數包括:線性預測編碼參數(LPC)、線性預測倒譜參數(LPCC)、MEL倒譜參數(MFCC)等。
語音模式庫:即聲學參數模板,它是用聚類分析等方法,從一個講話者或多個講話者多次重復的語音參數中經過長時間訓練得到的。
語音模式匹配:將輸入語音的特征參數同訓練得到的語音模式庫進行比較分析,從而得到識別結果。常用的方法包括:動態時間規整(DTW)、神經網絡(ANN)、隱馬爾科夫(HMM)等。DTW比較簡單實用,適用于孤立詞語音識別。HMM比較復雜,適用于大詞匯量連續語音識別。
三、嵌入式語音識別難點
語音識別的關鍵是識別率的高低。PC語音識別的識別率主要受限于系統選擇的方法,如端點檢測的精確度、特征參數的有效性、模式匹配方法的有效性等。而嵌入式的語音識別不僅受選擇方法的影響,而且受算法運算精度的影響。PC機主要采用浮點數,而嵌入式主要是采用定點算法,因此運算精度、誤差控制非常重要。語音識別算法包括多個模塊,多個算法運算過程,累積誤差對結果的影響是致命的。所以在算法設計過程中必須要仔細考慮定點數值的精度,既要盡量提高精度,又要防止運算結果溢出。
嵌入式語音識別還需要考慮識別速度。PC機運行速度比較快,中等詞匯量語音識別的用戶體驗還是蠻好的。但在嵌入式語音識別中,詞匯量的大小對用戶體驗的影響是相當嚴重的。即使識別率高,但識別速度很慢,那這個產品很難推廣。所以嵌入式語音識別需要在識別率和識別速度上折中考慮。識別速度不僅受限于選取算法的運算復雜度,還受嵌入式硬件的影響,如數據空間大小。如果數據RAM空間不夠大,那就需要以其他介質(如FLASH/CARD)作為緩存。后續處理頻繁范圍該介質將會嚴重影響識別速度。所以識別速度也受限于硬件條件。
四、80251平臺語音識別的硬件條件及其考慮
1. 80251平臺語音識別的硬件條件
這里我們假定SOC集成了251內核,而其能實現錄音的功能,這是語音識別的最基本要求。語音識別的硬件條件就是系統分配給錄音應用的所有資源。
錄音應用的資源一般包括:
1) audio buffer(512字節),其主要是作為audio錄音時采樣處理后的數據緩存,即采樣后audio會把512字節錄音數據放到該BUFFER,應用再調用文件系統寫接口把該BUFFER數據寫到FLASH。
2) EDATA變量數據空間(1024字節),其主要是錄音應用和中間件模塊的變量數據空間。錄音應用和中間件已經用掉622字節,剩下402字節。
3) PCMRAM(12K字節), 其主要是用于錄音時的數據采樣處理。
4) 代碼空間(9K字節),錄音應用和中間件代碼運行空間。
2. 80251平臺語音識別可用資源
在80251平臺上實現語音識別就需要在錄音應用基礎上增加語音識別功能,因此語音識別需要與錄音應用共享以上資源。語音識別分預處理、特征提取、訓練和匹配識別四個子過程,四個子過程在運行的時間上是不重復的。以下根據各個子過程的運行時間考慮以上資源的復用性。考慮到80251采用硬件BANK機制,所以語音識別的代碼空間不受影響。因此著重考慮數據空間的復用性。另外,語音識別一般是對PCM數據進行處理,80251的PCM數據的量化比特數為16BIT,即2個字節。人的有效語音頻率在4KHZ以下,所以采用率選擇8KHZ,滿足奈奎斯特采樣定理。
預處理的預加重比較簡單,是一個低通濾波器,不需占用額外的數據空間。對于去噪,本系統暫時不予考慮。預處理主要的部分在于語音端點檢測,即去除靜音段,保留有效語音段。類似于錄音中的聲控錄音,但語音識別的語音端點檢測比聲控錄音更加復雜,也要求更加精確。本系統采用實時在線的端點檢測算法,因此在端點檢測過程(即在偵聽命令的錄音過程)需要實時地對audio buffer的數據進行處理,檢測是否為有效語音。在這個過程,audio buffer和PCMRAM都是不可使用的。能夠使用的就是402字節的EDATA空間。由于語音識別各個過程都要進行分幀處理(后續再講),本系統設定每幀128點,因此需要申請一個256字節的幀處理BUFFER。剩下402-256 = 146字節作為語音識別的變量數據空間。
在端點檢測過程中,根據當前幀的短時能量或者過零率確認語音開始時,對該幀數據的處理有兩種,一是將當前512字節數據(一個扇區)COPY到一段語音BUFFER,另一種是調用文件系統寫接口寫到FLASH中。對于前者,其速度肯定優于后者,因為其不需要在處理的過程中調用文件系統接口。還有,突然的脈沖噪聲也會讓系統誤認為語音的開始,所以在確認噪聲后又需重新開始檢查。如果有一塊大的語音BUFFER,語音識別的性能將會大幅提高。一般認為一個人說出的孤立詞語音持續時間在2秒以內,即2×8000×2 ≈ 32K字節。但80251平臺明顯沒有這個資源。所以選擇了將當前扇區數據寫入文件,即用FLASH作為語音BUFFER使用。另外,80251文件有個缺陷,寫操作不能調用FSEEK。這樣會帶來端點檢測速度的下降。如前所講,脈沖噪聲會滿足語音開始的條件,因此脈沖噪聲起始點之后的一段聲音數據都會寫入到FLASH文件中,檢測算法后來發現前面是脈沖噪聲會將之前的數據沖掉,沖頭再寫。如果能調用FSEEK,那一條語句就完成。但因為該缺陷,因此需要調用FSCLOSE關閉文件,再調用FS_REMOVE刪除文件,接著調用FS_CREATE重新創建一個文件。
語音識別后面的3個子過程運行在非錄音時態,因此可以利用audio buffer和PCMRAM。由于后續的處理過程都需要從FLASH的文件中讀取數據來處理,每次一個扇區,所以用audio buffer作為緩沖。因此語音識別的后續過程可采用的數據空間即是12K字節的PCMRAM。
語音識別的特征提取過程主要需要一個緩沖特征參數的BUFFER。其他需要申請的BUFFER都可以放到FAR DATA空間(即代碼空間當數據用,但只允許當前BANK代碼能夠使用)。如果在對語音分幀進行特征提取并立刻寫數據到FLASH特征文件,那也不需要緩沖特征參數的BUFFER,但目前80251平臺的文件系統暫不支持一邊讀一邊寫,所以必須給特征參數分配緩存BUFFER,等每個語音命令處理后再一起寫進FLASH特征文件。以一個命令語音最長2秒計,幀移為64點,則共有2×8000/64 = 250幀,而每幀數據的LPC特征參數個數選16(即算法選16階LPC,每個參數2個字節),因此共需250×16×2 = 8000字節。考慮到在做模式匹配識別時需要緩沖模塊庫的一個參考詞條的特征參數和待識別詞條的特征參數,2個8000字節將超過12K的PCMRAM。所以特征參數的緩沖BUFFER最多只能分配6K。有兩個選擇,一是特征參數個數選16,那最大的有效語音持續時間為:6×1024/(2×16×(8000/64) = 1.536秒。正常一個人說一個命令的時間約束是可以滿足在1.5秒以內的。另一個辦法是縮小每幀數據的LPC參數個數,一般語音識別選12階,本程序為了處理更快,選的是16階。如果選8階那會更快,但精度下降。
語音識別的模式匹配過程主要是需要以上講述的兩個緩沖特征參數的BUFFER。由于采用DTW算法,因此算法涉及的中間緩存都分配在FAR DATA空間。
綜上所述,80251平臺能夠在速度受限的情況下實現語音識別功能。
五、語音識別算法設計



六、PC端語音識別算法設計
任何一個移植到嵌入式平臺的算法都應該在PC環境上調試驗證通過后再進行移植,而為了移植的高效,PC環境的算法設計應該建立在熟悉目標平臺的硬件結構和編譯集成環境的基礎上。盡可能深刻地熟悉兩者,將為后面的移植帶來極大的好處,否則事倍功半。
1.模擬80251錄音過程進行端點檢測
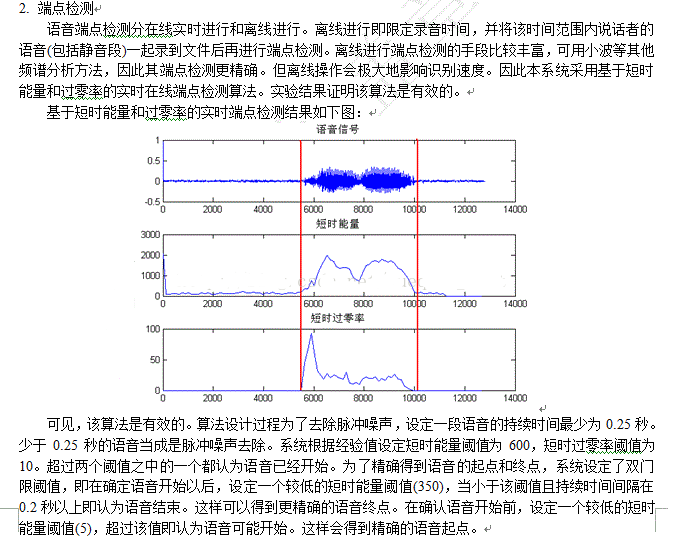
PC機用讀文件的形式模擬80251錄音的過程,詳細的端點檢測過程如下圖:
為了數據的一致性,PC機調試的文件都是80251錄出來的錄音文件(8K,PCM,16BIT,單聲道)。另外,因為80251是分BANK處理語音識別的四個子過程,為了讓各個模塊去耦合,在WAV文件頭的一些保留區寫入語音端點檢測的有效幀數。這樣參數提取過程就可以從文件中直接讀出該參數并進行處理。
80251錄音結束時會自動準備好文件頭所屬的一個扇區數據,而這個文件頭是包括直接的靜音段,所以最后寫入文件頭時需要對文件頭的一些參數(如文件長度)進行修改再寫入。
其實,語音數據完全可以作為一個單獨的二進制文件存在,并不需要文件頭信息。但為了調試的有效性,仍然寫入正確的文件頭,這樣語音端點檢測結果仍然是一個WAV文件,通過聽這個WAV文件就知道算法是否有效。
算法的結果如果能夠圖形化那會比較直觀,所以借助了MATLAB工具進行畫圖,以輔助調試,加快調試進度。
2.數據處理精度
80251平臺的PCM數據為16比特量化,但事實上語音處理時采用8比特量化就足夠了。因此對錄音數據的處理都是取高8位。這樣減少了一半的運算量,也防止計算溢出。
雖然采用高8位數據進行處理,但為了程序的整體運算平滑過渡,仍然用一個16位有符號短整型去表述每一個采樣點。VC為short int,80251為signed int。其獲取的特征參數也選用16位有符號短整型去表述。而在運算過程有時會采用32位有符號整型以提高運算精度。
3.類型移植
如上節所講,為了方便移植,必須讓VC中程序的變量和KEIL代碼的變量的類型一致。因此在VC中需要重定義一份KEIL環境的typeext.h文件。如:
#define int16signed short int
#define int32signed int
等等。
這樣VC的主要算法可以不做任何改動就可以放入KEIL環境進行編譯調試。
4.浮點算法定點化
這是語音識別的最關鍵部分。如果在浮點算法定點化的過程中控制好累積誤差,是本系統最關鍵的問題。第四部分所闡述的算法都是浮點算法。PC上語音識別的識別率很高很大程度一部分原因是因為其選擇復雜的算法,另一部分原因是因為它使用浮點數,較好地控制了累積誤差。其所有的參數均通過歸一化使得運算都在-1到1之間進行。
浮點庫對于嵌入式平臺是一個極大的負擔,而且運算速度很慢。所以嵌入式產品的關鍵也在于浮點算法定點化過程中如何更好地控制誤差。控制誤差的一個很有效的方法就是提高數據運算精度,但是一味地提高運算精度會導致運算溢出,所以必須在兩者之間折中考慮,以獲得一個平衡。
調試此部分功能時曾遇到一個很大的困難就是求取LPC參數時的對E的處理,因為其在循環過程中曾被作為除數進行處理,如果在循環的過程中沒做好誤差控制,那其就會在某次運算過程中為0,所以造成結果溢出。調試過程還算比較艱辛,曾經讓自己想起要不用浮點庫試試。但最后還是堅持下來用定點算法繼續調試。
針對本系統的算法,浮點算法定點化過程主要做了以下幾個方面的考慮。
1. 如5.2節所講,錄音數據采用高8位進行處理。
2. LPC算法的自相關系統進行歸一化處理,取12比特有效數據,即R(0) = 4096。而且在運算過程中若發現累積和大于0x7fff時就進行相應移位,保證累積和在0x7fff以內。因為所有自相關系統同時除以一個值,對后面的結果沒有影響。
3. LPC算法的E取32位有符號數,算法運算的中間變量也取32位。
4. LPC算的a,k等參數取12位有效數值,即在4096以內。
5. LPC算法中的除法精度到0.5以內,即考慮余數與除數的關系。
6. DTW算法運算使用32位運算精度。
浮點算法定點化調試的一個好的經驗時在VC中用兩個工程分別實現浮點算法和定點算法,然后跟蹤每一步的運算結果。發現誤差過大就及時修改調整。
5.速度優化
算法設計時考慮到80251的乘除運算能力有限,所以盡肯能地采用移位,查表操作,以提高運算速度。舉例如下:
1. 預加重等過程需要乘以0.9375,就先乘120,再右移7位,即除以128。
2. 窗化處理時如果按公式調用cos等數學函數,那代碼量的增長和運算速度的影響都是致命的。在這里使用查表的方式進行處理。即在MATLAB中用hamming(128)得到127點信號點,由于該信號點是-1到1的小數,所以再將其放大1024倍,將這些數值保存到一張表中(使用FAR DATA空間),代碼運算時先分別相乘,再右移10位就可以了。所以這里巧妙地避免了除法操作。
七、 80251平臺語音識別實現
1.算法移植
由于PC端的算法已經盡可能地考慮了80251的錄音過程和KEIL C環境約束,所以算法移植還算比較順利,尤其是語音端點檢測部分。幾乎不做任何算法改動就實現了該部分功能。當然錄音應用是需要進行調整的。主要的改動主要是UI控制和顯示,以及中間件錄音流程的修改。即在之前的寫入操作前加入調用wav_vad函數進行端點檢測,確定語音開始才寫進FLASH錄音文件。
對于特征提取、訓練識別部分的調整,主要是分配好代碼運行空間和FAR DATA空間。DTW算法運算過程中的中間變量近1k字節,但由于只有該部分使用,所以都分配在FAR DATA空間。
2. VC和KEIL C的比較
調試過程中還是發現了VC和KEIL C編譯器有不一致的地方。但由于比較隱藏,所以發現這部分特性也花費了不少時間。列舉幾點:
1. int32 m = (int32)(int16 val1* int16 val2);VC會自動把32位的相乘結果賦給m,而KEIL C是將32位相乘結果的高16位清零再付給m。這個好像挺奇怪的,但事實就是這樣。只有把前面的強制類型轉換去掉才正確。所以有時強制類型轉換也未必是好事。
2. VC中用到的一部分BUFFER會自動初始化為0,而KEIL C中不會。所以LPC算法運算結果出現偏差。因為小機和PC的識別率差別很大,所以只好用同一個文件在小機上和PC機上同時調試,以跟蹤每一步結果,最終才發現這個問題。其實是編程習慣不夠好,一般在使用某段BUFFER前都應該先清零才行。
3. VC中的short int左移會向32位擴展,而KEIL C左移時其數值范圍并沒有加大,即丟棄超過16位的數值,沒能真正實現左移相乘的目的。
八、 80251平臺語音識別結果及其分析
80251平臺語音識別的識別率可以控制在93%以上(詞匯量在50以下,憑經驗),50以上還沒測試過。
-
嵌入式
+關注
關注
5141文章
19525瀏覽量
314817 -
神經網絡
+關注
關注
42文章
4806瀏覽量
102748 -
語音識別
+關注
關注
39文章
1773瀏覽量
113895
發布評論請先 登錄
Spansion與Nuance共推嵌入式語音識別創新
怎么設計基于嵌入式系統的語音口令識別系統?
基于STM32嵌入式的孤立詞語音識別系統設計
怎樣去設計基于嵌入式Linux的語音識別系統
如何利用ARM實現嵌入式語音識別模塊的設計
嵌入式語音識別系統中的電路設計是如何的
基于UniSpeech芯片和語音識別算法實現嵌入式語音識別系統的設計

基于STM32的嵌入式語音識別模塊設計實現






 工商網監
工商網監
評論