") 神經(jīng)網(wǎng)絡(luò)如何正確初始化?
神經(jīng)網(wǎng)絡(luò)如何正確初始化?
初始化對訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)的收斂性有重要影響。簡單的初始化方案可以加速訓(xùn)練,但是它們需要小心避免常見的陷阱。
近期,deeplearning.ai就如何有效地初始化神經(jīng)網(wǎng)絡(luò)參數(shù)發(fā)表了交互式文章,圖靈君將結(jié)合這篇文章與您一起探索以下問題:
1、有效初始化的重要性
2、梯度爆炸或消失的問題
3、什么是正確的初始化?
4、Xavier初始化的數(shù)學(xué)證明
一、有效初始化的重要性
要構(gòu)建機器學(xué)習(xí)算法,通常需要定義一個體系結(jié)構(gòu)(例如Logistic回歸,支持向量機,神經(jīng)網(wǎng)絡(luò))并訓(xùn)練它來學(xué)習(xí)參數(shù)。 以下是神經(jīng)網(wǎng)絡(luò)的常見訓(xùn)練過程:
1、初始化參數(shù)
2、選擇優(yōu)化算法
3、重復(fù)這些步驟:
a、正向傳播輸入
b、計算成本函數(shù)
c、使用反向傳播計算與參數(shù)相關(guān)的成本梯度
d、根據(jù)優(yōu)化算法,使用梯度更新每個參數(shù)
然后,給定一個新的數(shù)據(jù)點,您可以使用該模型來預(yù)測它的類。
初始化步驟對于模型的最終性能至關(guān)重要,它需要正確的方法。 為了說明這一點,請考慮下面的三層神經(jīng)網(wǎng)絡(luò)。 您可以嘗試使用不同的方法初始化此網(wǎng)絡(luò),并觀察它對學(xué)習(xí)的影響。
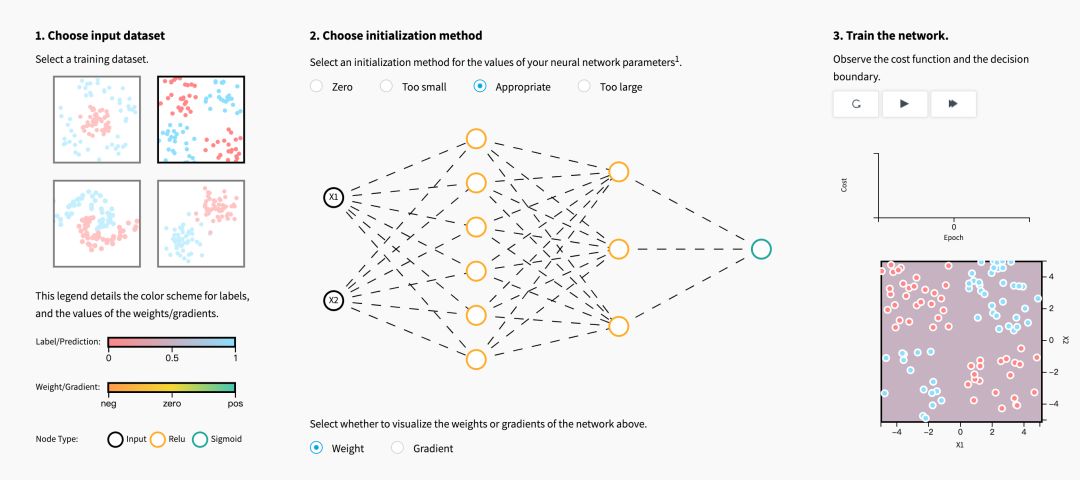
當(dāng)初始化方法為零時,對于梯度和權(quán)重,您注意到了什么?
用零初始化所有權(quán)重會導(dǎo)致神經(jīng)元在訓(xùn)練期間學(xué)習(xí)相同的特征。
實際上,任何常量初始化方案的性能表現(xiàn)都非常糟糕。 考慮一個具有兩個隱藏單元的神經(jīng)網(wǎng)絡(luò),并假設(shè)我們將所有偏差初始化為0,并將權(quán)重初始化為一些常數(shù)α。 如果我們在該網(wǎng)絡(luò)中正向傳播輸入(x1,x2),則兩個隱藏單元的輸出將為relu(αx1+αx2)。 因此,兩個隱藏單元將對成本具有相同的影響,這將導(dǎo)致相同的梯度。
因此,兩個神經(jīng)元將在整個訓(xùn)練過程中對稱地進化,有效地阻止了不同的神經(jīng)元學(xué)習(xí)不同的東西。
在初始化權(quán)重時,如果值太小或太大,關(guān)于成本圖,您注意到了什么?
盡管打破了對稱性,但是用值(i)太小或(ii)太大來初始化權(quán)重分別導(dǎo)致(i)學(xué)習(xí)緩慢或(ii)發(fā)散。
為高效訓(xùn)練選擇適當(dāng)?shù)某跏蓟凳潜匾摹N覀儗⒃谙乱还?jié)進一步研究。
二、梯度的爆炸或消失問題
考慮這個9層神經(jīng)網(wǎng)絡(luò)。

在優(yōu)化循環(huán)的每次迭代(前向,成本,后向,更新)中,我們觀察到當(dāng)您從輸出層向輸入層移動時,反向傳播的梯度要么被放大,要么被最小化。 如果您考慮以下示例,此結(jié)果是有意義的。
假設(shè)所有激活函數(shù)都是線性的(標(biāo)識函數(shù))。 然后輸出激活是:
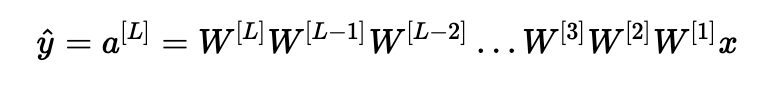
其中,L=10,W[1],W[2],…,W[L?1]都是大小為(2,2)的矩陣,因為層[1]到[L-1]有2個神經(jīng)元,接收2個輸入。考慮到這一點,為了便于說明,如果我們假設(shè)W[1]=W[2]=?=W[L?1]=W,輸出預(yù)測是y^=W[L]WL?1x(其中WL?1將矩陣W取為L-1的冪,而W[L]表示Lth矩陣)。
初始化值太小,太大或不合適的結(jié)果是什么?
情形1:過大的初始化值會導(dǎo)致梯度爆炸
考慮這樣一種情況:初始化的每個權(quán)重值都略大于單位矩陣。
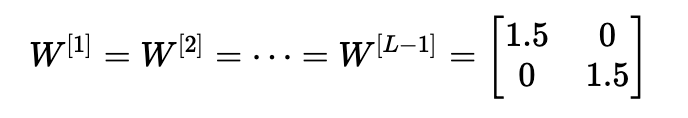
這簡化為y^=W[L]1.5L?1x,并且a[l]的值隨l呈指數(shù)增加。 當(dāng)這些激活用于反向傳播時,就會導(dǎo)致梯度爆炸問題。 也就是說,與參數(shù)相關(guān)的成本梯度太大。 這導(dǎo)致成本圍繞其最小值振蕩。
情形2:初始化值太小會導(dǎo)致梯度消失
類似地,考慮這樣一種情況:初始化的每個權(quán)重值都略小于單位矩陣。
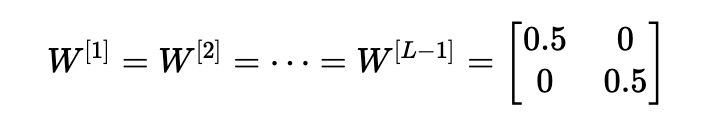
這簡化為y^=W[L]0.5L?1x,并且激活a [l]的值隨l呈指數(shù)下降。 當(dāng)這些激活用于反向傳播時,這會導(dǎo)致消失的梯度問題。 相對于參數(shù)的成本梯度太小,導(dǎo)致在成本達到最小值之前收斂。
總而言之,使用不適當(dāng)?shù)闹党跏蓟瘷?quán)重將導(dǎo)致神經(jīng)網(wǎng)絡(luò)訓(xùn)練的發(fā)散或減慢。雖然我們用簡單的對稱權(quán)重矩陣說明了梯度爆炸/消失問題,但觀察結(jié)果可以推廣到任何太小或太大的初始化值。
三、如何找到合適的初始化值
為了防止網(wǎng)絡(luò)激活的梯度消失或爆炸,我們將堅持以下經(jīng)驗法則:
1、激活的平均值應(yīng)為零。
2、激活的方差應(yīng)該在每一層保持不變。
在這兩個假設(shè)下,反向傳播的梯度信號不應(yīng)該在任何層中乘以太小或太大的值。 它應(yīng)該移動到輸入層而不會爆炸或消失。
更具體地考慮層l, 它的前向傳播是:
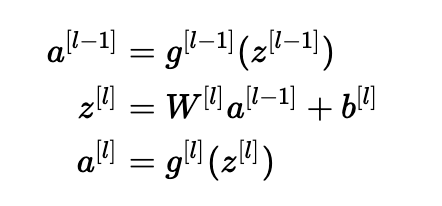
我們希望以下內(nèi)容:
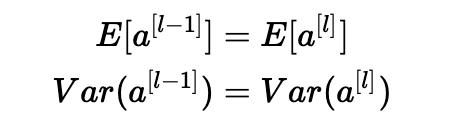
確保零均值并保持每層輸入方差的值不會產(chǎn)生爆炸/消失信號,我們稍后會解釋。 該方法既適用于前向傳播(用于激活),也適用于反向傳播傳播(用于激活成本的梯度)。 推薦的初始化是Xavier初始化(或其派生方法之一),對于每個層l:
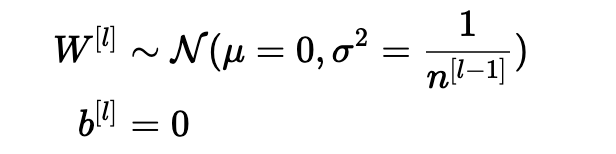
換句話說,層l的所有權(quán)重是從正態(tài)分布中隨機選取的,其中均值μ= 0且方差σ2= n [l-1] 1其中n [l-1]是層l-1中的神經(jīng)元數(shù)。 偏差用零初始化。
下面的可視化說明了Xavier初始化對五層全連接神經(jīng)網(wǎng)絡(luò)的每個層激活的影響。
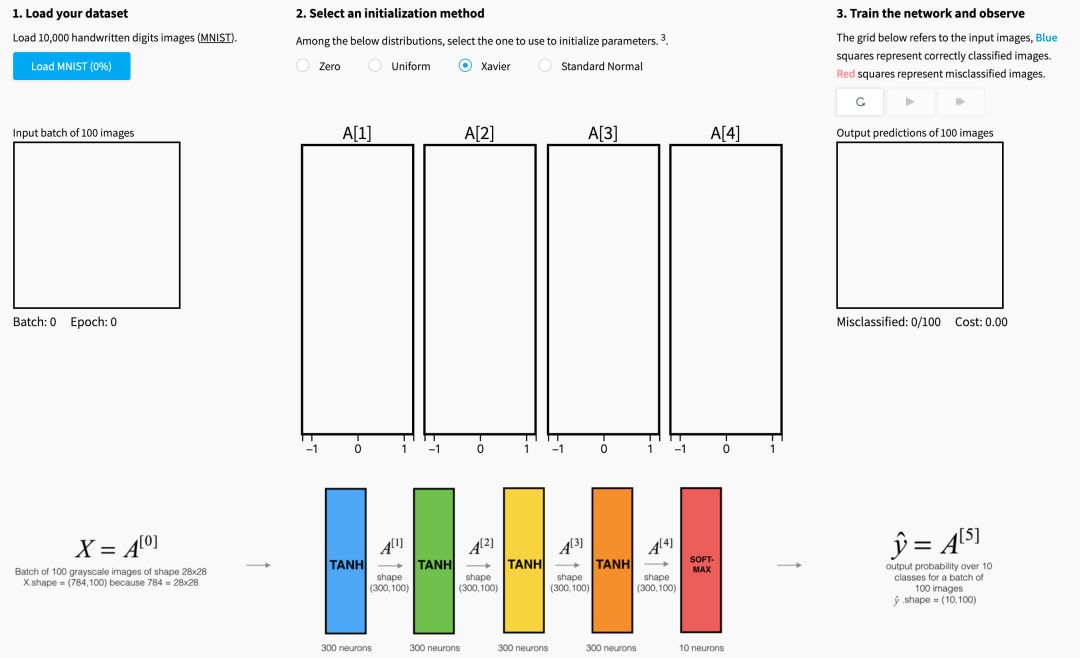
您可以在Glorot等人中找到這種可視化背后的理論。(2010年)。 下一節(jié)將介紹Xavier初始化的數(shù)學(xué)證明,并更準(zhǔn)確地解釋為什么它是一個有效的初始化。
四、Xavier初始化的合理性
在本節(jié)中,我們將展示Xavier初始化使每個層的方差保持不變。 我們假設(shè)層的激活是正態(tài)分布在0附近。 有時候,理解數(shù)學(xué)原理有助于理解概念,但不需要數(shù)學(xué),就可以理解基本思想。
讓我們對第(III)部分中描述的層l進行處理,并假設(shè)激活函數(shù)為tanh。 前向傳播是:
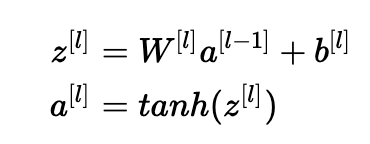
目標(biāo)是導(dǎo)出Var(a [l-1])和Var(a [l])之間的關(guān)系。 然后我們將理解如何初始化我們的權(quán)重,使得:Var(a[l?1])=Var(a[l])。
假設(shè)我們使用適當(dāng)?shù)闹党跏蓟覀兊木W(wǎng)絡(luò),并且輸入被標(biāo)準(zhǔn)化。 在訓(xùn)練初期,我們處于tanh的線性狀態(tài)。 值足夠小,因此tanh(z[l])≈z[l],意思是:
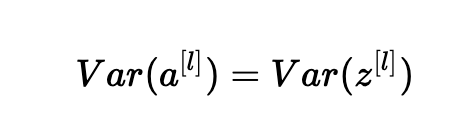
此外,z[l]=W[l]a[l?1]+b[l]=向量(z1[l],z2[l],…,zn[l][l])其中zk[l]=∑j=1n[l?1]wkj[l]aj[l?1]+bk[l]。 為簡單起見,我們假設(shè)b[l]=0(考慮到我們將選擇的初始化選擇,它將最終為真)。 因此,在前面的方程Var(a[l?1])=Var(a[l])中逐個元素地看,現(xiàn)在給出:
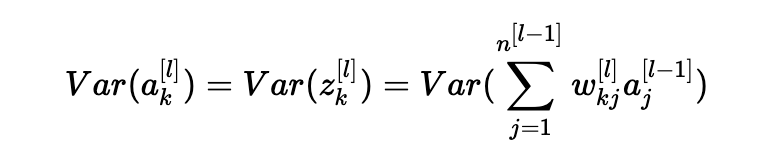
常見的數(shù)學(xué)技巧是在方差之外提取求和。 為此,我們必須做出以下三個假設(shè):
1、權(quán)重是獨立的,分布相同;
2、輸入是獨立的,分布相同;
3、權(quán)重和輸入是相互獨立的。
因此,現(xiàn)在我們有:
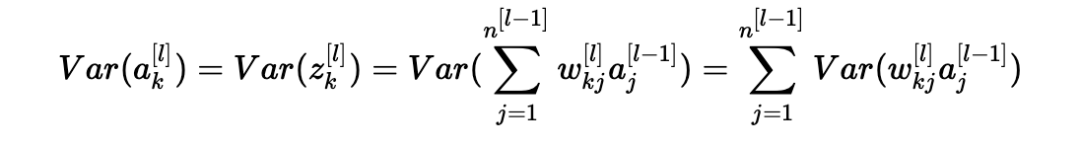
另一個常見的數(shù)學(xué)技巧是將乘積的方差轉(zhuǎn)化為方差的乘積。公式如下:
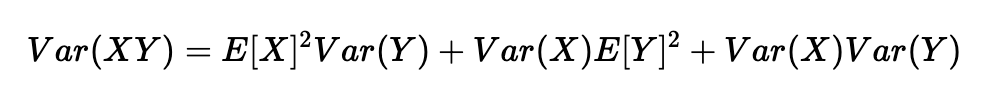
使用X=wkj[l]和Y=aj[l?1]的公式,我們得到:
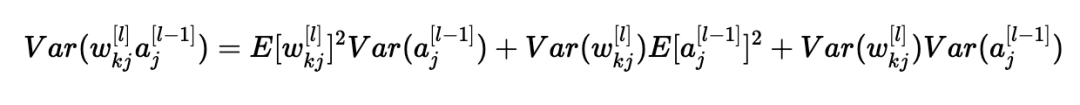
我們差不多完成了! 第一個假設(shè)導(dǎo)致E[wkj[l]]2=0,第二個假設(shè)導(dǎo)致E[aj[l?1]]2=0,因為權(quán)重用零均值初始化,輸入被歸一化。 從而:
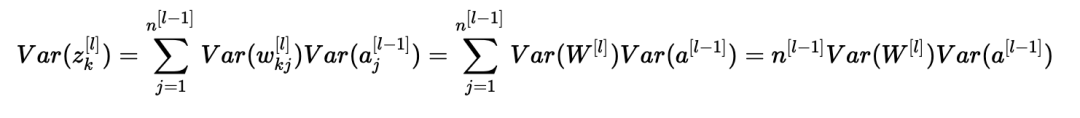
上述等式源于我們的第一個假設(shè),即:
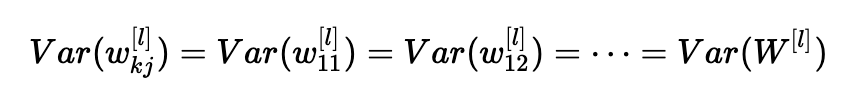
同樣,第二個假設(shè)導(dǎo)致:
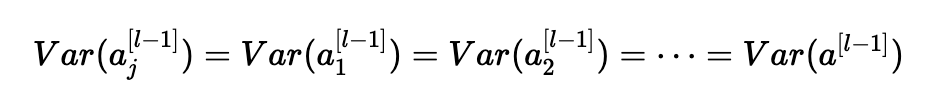
同樣的想法:
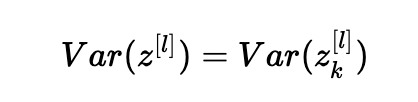
總結(jié)一下,我們有:
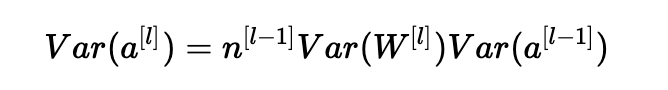
瞧! 如果我們希望方差在各層之間保持不變(Var(a[l])=Var(a[l?1])),我們需要Var(W[l])=n[l?1]1。 這證明了Xavier初始化的方差選擇是正確的。
請注意,在前面的步驟中,我們沒有選擇特定的層ll。 因此,我們已經(jīng)證明這個表達式適用于我們網(wǎng)絡(luò)的每一層。 讓LL成為我們網(wǎng)絡(luò)的輸出層。 在每一層使用此表達式,我們可以將輸出層的方差鏈接到輸入層的方差:
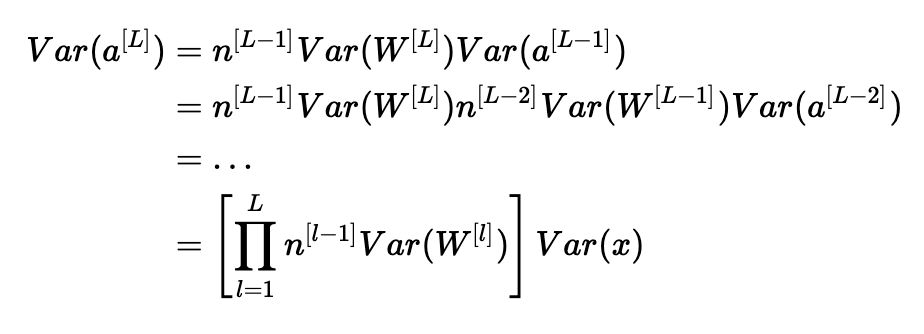
根據(jù)我們?nèi)绾纬跏蓟瘷?quán)重,我們的輸出和輸入的方差之間的關(guān)系會有很大的不同。 請注意以下三種情況。
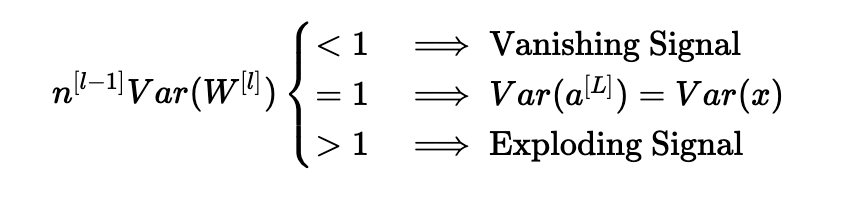
因此,為了避免正向傳播信號的消失或爆炸,我們必須通過初始化Var(W[l])=n[l?1]1來設(shè)置n[l?1]Var(W[l])=1。
在整個證明過程中,我們一直在處理在正向傳播期間計算的激活。對于反向傳播的梯度也可以得到相同的結(jié)果。這樣做,您將看到,為了避免梯度消失或爆炸問題,我們必須通過初始化Var(W[l])=n[l]1來設(shè)置n[l]Var(W[l])=1。
結(jié)論
實際上,使用Xavier初始化的機器學(xué)習(xí)工程師會將權(quán)重初始化為N(0,n[l?1]1)或N(0,n[l?1]+n[l]2)。 后一分布的方差項是n [l-1] 1和n [1] 1的調(diào)和平均值。
這是Xavier初始化的理論依據(jù)。 Xavier初始化與tanh激活一起工作。 還有許多其他初始化方法。 例如,如果您正在使用ReLU,則通常的初始化是He初始化(He et al,Delving Deep into Rectifiers),其中權(quán)重的初始化方法是將Xavier初始化的方差乘以2。雖然這種初始化的理由稍微復(fù)雜一些,但它遵循與tanh相同的思考過程。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4806瀏覽量
102688 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5554瀏覽量
122443
原文標(biāo)題:吳恩達團隊:神經(jīng)網(wǎng)絡(luò)如何正確初始化?
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論