") 針對線性回歸模型和深度學習模型,介紹了確定訓練數(shù)據(jù)集規(guī)模的方法
針對線性回歸模型和深度學習模型,介紹了確定訓練數(shù)據(jù)集規(guī)模的方法
【導讀】對于機器學習而言,獲取數(shù)據(jù)的成本有時會非常昂貴,因此為模型選擇一個合理的訓練數(shù)據(jù)規(guī)模,對于機器學習是至關(guān)重要的。在本文中,作者針對線性回歸模型和深度學習模型,分別介紹了確定訓練數(shù)據(jù)集規(guī)模的方法。
數(shù)據(jù)是否會成為新時代的“原油”是人們近來常常爭論的一個問題。
無論爭論結(jié)果如何,可以確定的是,在機器學前期,數(shù)據(jù)獲取成本可能十分高昂(人力工時、授權(quán)費、設(shè)備運行成本等)。因此,對于機器學習的一個非常關(guān)鍵的問題是,確定能使模型達到某個特定目標(如分類器精度)所需要的訓練數(shù)據(jù)規(guī)模。
在本文中,我們將對經(jīng)驗性結(jié)果和研究文獻中關(guān)于訓練數(shù)據(jù)規(guī)模的討論進行簡明扼要的綜述,涉及的機器學習模型包括回歸分析等基本模型,以及復雜模型如深度學習。訓練數(shù)據(jù)規(guī)模在文獻中也稱樣本復雜度,本文將對如下內(nèi)容進行介紹:
針對線性回歸和計算機視覺任務(wù),給出基于經(jīng)驗確定訓練數(shù)據(jù)規(guī)模的限制;
討論如何確定樣本大小,以獲得更好的假設(shè)檢驗結(jié)果。雖然這是一個統(tǒng)計問題,但是該問題和確定機器學習訓練數(shù)據(jù)集規(guī)模的問題很相似,因此在這里一并討論;
對影響訓練數(shù)據(jù)集規(guī)模的因素,給出基于統(tǒng)計理論學習的結(jié)果;
探討訓練集增大對模型表現(xiàn)提升的影響,并著重分析深度學習中的情形;
給出一種在分類任務(wù)中確定訓練數(shù)據(jù)集大小的方法;
探討增大訓練集是否是應對不平衡數(shù)據(jù)集的最好方式。
基于經(jīng)驗確定訓練集規(guī)模的限制
首先,我們依據(jù)使用的模型類型,探討一些廣泛使用的經(jīng)驗性方法:
回歸分析:依據(jù)統(tǒng)計學中的“十分之一”經(jīng)驗法則(one-in-ten rule),每個預測器都需要使用 10 個實例訓練。這種經(jīng)驗法則還有其他版本,例如用于解決回歸系數(shù)縮減問題的“二十分之一”規(guī)則(one-in-twenty rule)。最近,《Sample Size For Binary Logistic Prediction Models: Beyond Events Per Variable Criteria》一文中還提出了一種有趣的二元邏輯回歸變體。在該文中,作者通過預測器中變量的個數(shù)、總樣本量,以及正樣本量與總樣本量的比值,對訓練數(shù)據(jù)規(guī)模進行了估計。
計算機視覺:對于利用深度學習的圖像分類問題,根據(jù)“經(jīng)驗法則”,建議每一個類別收集 1000 張圖像。如果使用預訓練模型,數(shù)據(jù)集的規(guī)模則可以大幅減少。
通過假設(shè)檢驗確定樣本規(guī)模
假設(shè)檢驗是數(shù)據(jù)科學常用的一種統(tǒng)計工具,一般也可以用于確定樣本規(guī)模。
舉個例子:某科技巨頭搬去 A 城后,A 城的房價便急劇上漲,而某記者想知道現(xiàn)在每套公寓的均價是多少。那么問題來了,在保證 95% 的置信度,60 K 的公寓價格標準差,且價格誤差在10K 以內(nèi)的條件下,計算多少棟公寓的均價較為合理?
相應公式見下圖,其中 N 為所需的樣本規(guī)模,1.96 為標準正態(tài)分布在 95% 置信度下所對應的常數(shù):
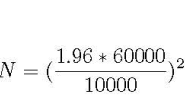 ? ? ?
? ? ?
樣本量估計
根據(jù)上述公式,該記者需要考慮大概 138 棟公寓的價格。
該公式將隨著檢驗問題的不同而改變,但是都要通過置信區(qū)間、可容忍誤差和標準差值來計算。
訓練數(shù)據(jù)規(guī)模的統(tǒng)計學習理論
我們先介紹一下著名的 VC 維(Vapnik-Chevronenkis dimension)。VC 維是一種模型復雜度的度量;模型越復雜,它的 VC 維就越高。下面介紹根據(jù) VC 維來確定訓練數(shù)據(jù)規(guī)模的公式。
首先,通過一個例子來看一下 VC 維是如何計算的:假設(shè)一個二維平面上有三個點需要被分類,而我們的分類器為該平面上的一條直線。無論這三點怎樣組合(均為正例,兩正一負、一正兩負等),這條直線都能正確地將正負樣本歸類/分開。那么,我們就認為一個線性分類器可以劃分這三點中的任意一點,因而它的 VC 維至少為 3。
另外,由于存在四個點的組合不能被一條直線準確分開,所以這個線性分類器的 VC 維為 3。可以證明,訓練數(shù)據(jù)規(guī)模 N 是 VC 維的一個函數(shù):
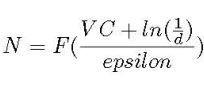
由 VC 維估計訓練數(shù)據(jù)規(guī)模
其中 d 為失敗率, epsilon 為學習中的誤差率。由此可見,學習模型所需的樣本量取決于模型的復雜度。但該方法有一個弊端,就是在面對神經(jīng)網(wǎng)絡(luò)顯著的復雜度時,會要求十分龐大的訓練數(shù)據(jù)規(guī)模。
當訓練集增大時,模型的表現(xiàn)會持續(xù)提升嗎?在深度學習任務(wù)又如何呢?
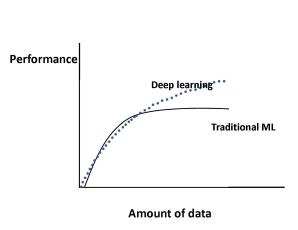
上圖展示了隨著數(shù)據(jù)規(guī)模的增長,傳統(tǒng)的機器學習算法(回歸等)和深度學習表現(xiàn)的變化。
具體來看,對于傳統(tǒng)的機器學習算法,模型的表現(xiàn)先是遵循冪定律(power law),之后趨于平緩;而對于深度學習,該問題還在持續(xù)不斷地研究中,不過圖一為目前較為一致的結(jié)論,即隨著數(shù)據(jù)規(guī)模的增長,深度學習模型的表現(xiàn)會按照冪定律持續(xù)提升。例如,有人曾用深度學習方法對三億張圖像進行分類,發(fā)現(xiàn)模型的表現(xiàn)隨著訓練數(shù)據(jù)規(guī)模的增長按對數(shù)關(guān)系提升。
值得注意的是,在深度學習中也有一些與上述例子不同的結(jié)果。比如,在《Learning Visual Features from Large Weakly Supervised Data》一文中,作者使用了一億條 Flickr 上的圖片和標簽來訓練卷積神經(jīng)網(wǎng)絡(luò),剛開始模型表現(xiàn)會隨著數(shù)據(jù)規(guī)模的增大而提升,但超過五千萬張圖片后模型的效果提升就不太明顯了。
文章《How Training Data Affect the Accuracy and Robustness of Neural Networks for Image Classification》的作者還發(fā)現(xiàn),隨著訓練數(shù)據(jù)規(guī)模的增加,圖像分類的準確度確實會上升;但是,模型的魯棒性會在數(shù)據(jù)規(guī)模到達一定程度后開始下降。
分類任務(wù)中確定訓練數(shù)據(jù)集大小的方法
該方法基于我們所熟知的學習曲線,一般而言,學習曲線圖的縱軸為誤差,橫軸為訓練數(shù)據(jù)集大小。《Tutorial: Learning Curves for Machine Learning in Python》和《Learning Curve》是很好的參考資料,可以用于進一步了解機器學習中的學習曲線,以及它們是如何隨著偏差或方差的增加而變化的。Python 在 scikit-learn 中提供了一種學習曲線函數(shù)。
在分類任務(wù)中,我們往往會使用學習曲線的一種輕微變體,在該曲線圖中,縱軸為分類準確度,橫軸為訓練數(shù)據(jù)集大小。訓練集規(guī)模的確定十分簡單:只需針對你的問題,先確定學習曲線的確切形狀,然后找到曲線上你預期的分類準確度所對應的訓練數(shù)據(jù)集大小即可。
例如,在文章《Predicting Sample Size Required for Classification Performance》和《How Much Data Is Needed to Train A Medical Image Deep Learning System to Achieve Necessary High Accuracy?》中,作者們將學習曲線的方法應用到了醫(yī)學領(lǐng)域,并且給出了一個相應的冪函數(shù):
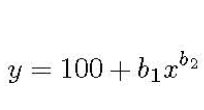
學習曲線公式
其中,y 為分類準確度,x 為訓練集,b1,b2 分別為學習率和衰減率。根據(jù)問題的不同,參數(shù)會有所不同,可以通過非線性回歸或加權(quán)非線性回歸對參數(shù)進行估計。
增大訓練集是應對不平衡數(shù)據(jù)集的最好方式?
文章《Precision-Recall Versus Accuracy and the Role of Large Data Sets》對該問題進行了討論。該文作者提出了一個很有意思的觀點:在不平衡的數(shù)據(jù)集下,準確度并不是一個分類器表現(xiàn)好壞的最佳度量。
原因很簡單,對于一個負樣本為主的數(shù)據(jù)集,模型往往通過將大部分樣本分類為負樣本,以提高準確度。為了更好地衡量模型效果,他們將準確率和召回率(又稱敏感性)作為不平衡數(shù)據(jù)集下度量模型表現(xiàn)的合理標準。
除了上述提到的關(guān)于準確度的問題,作者們還指出,對于存在不平衡數(shù)據(jù)的問題而言,模型的準確率往往對其更加重要。比如一個醫(yī)院的警報系統(tǒng)而言,高精確率就意味著當警鈴響起時,很有可能確實有病人遇到了麻煩。
之后,該文章分別使用較大的非平衡訓練集和不平衡學習包(imbalanced-learn, 基于Python scikit-learn)對模型進行了訓練,并使用準確率和召回率對訓練效果進行了分別的度量。
第一個模型使用了一個包含5萬個樣本的藥物研發(fā)數(shù)據(jù),并構(gòu)建了使用不平衡矯正方法的K-近鄰模型。第二個模型使用了一個包含大約100萬個樣本的數(shù)據(jù)集上,構(gòu)建了一個簡單的K-近鄰模型。
其中,不平衡矯正方法包括欠采樣、過采樣和集成學習。文章作者重復了200次實驗,其結(jié)論為,當把精確率和召回率作為度量時,沒有任何一種不平衡矯正方法比增加更多訓練數(shù)據(jù)的效果更好。
-
機器學習
+關(guān)注
關(guān)注
66文章
8488瀏覽量
134012 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1222瀏覽量
25264 -
深度學習
+關(guān)注
關(guān)注
73文章
5554瀏覽量
122443
原文標題:如何確定最佳訓練數(shù)據(jù)集規(guī)模?6 大必備“錦囊”全給你了 | 技術(shù)頭條
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】大語言模型的預訓練
【微信精選】手把手跟我入門機器學習:手寫體識別模型
TensorFlow實現(xiàn)簡單線性回歸
TensorFlow實現(xiàn)多元線性回歸(超詳細)
人工智能基本概念機器學習算法
深度學習模型是如何創(chuàng)建的?
基于預訓練模型和長短期記憶網(wǎng)絡(luò)的深度學習模型
深度學習如何訓練出好的模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論