") Python爬蟲 你真的會(huì)寫爬蟲嗎?
Python爬蟲 你真的會(huì)寫爬蟲嗎?

咱們直接進(jìn)入今天的主題---你真的會(huì)寫爬蟲嗎?為啥標(biāo)題是這樣,因?yàn)槲覀內(nèi)粘懶∨老x都是一個(gè)py文件加上幾個(gè)請(qǐng)求,但是如果你去寫一個(gè)正式的項(xiàng)目時(shí),你必須考慮到很多種情況,所以我們需要把這些功能全部模塊化,這樣也使我們的爬蟲更加的健全。
2基礎(chǔ)爬蟲的架構(gòu)以及運(yùn)行流程
首先,給大家來(lái)講講基礎(chǔ)爬蟲的架構(gòu)到底是啥樣子的?JAP君給大家畫了張粗糙的圖:
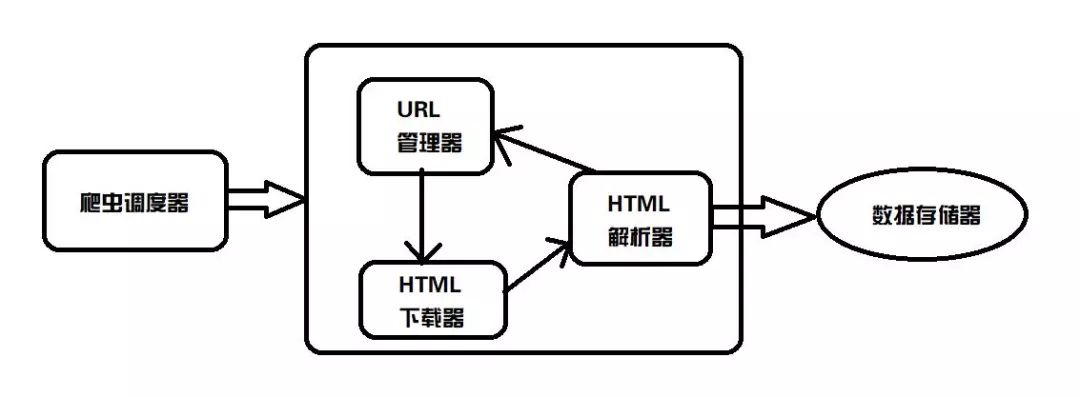
從圖上可以看到,整個(gè)基礎(chǔ)爬蟲架構(gòu)分為5大類:爬蟲調(diào)度器、URL管理器、HTML下載器、HTML解析器、數(shù)據(jù)存儲(chǔ)器。
下面給大家依次來(lái)介紹一下這5個(gè)大類的功能:
爬蟲調(diào)度器,主要是配合調(diào)用其他四個(gè)模塊,所謂調(diào)度就是取調(diào)用其他的模板
URL管理器,就是負(fù)責(zé)管理URL鏈接的,URL鏈接分為已經(jīng)爬取的和未爬取的,這就需要URL管理器來(lái)管理它們,同時(shí)它也為獲取新URL鏈接提供接口。
HTML下載器,就是將要爬取的頁(yè)面的HTML下載下來(lái)
HTML解析器,就是將要爬取的數(shù)據(jù)從HTML源碼中獲取出來(lái),同時(shí)也將新的URL鏈接發(fā)送給URL管理器以及將處理后的數(shù)據(jù)發(fā)送給數(shù)據(jù)存儲(chǔ)器。
數(shù)據(jù)存儲(chǔ)器,就是將HTML下載器發(fā)送過(guò)來(lái)的數(shù)據(jù)存儲(chǔ)到本地
3實(shí)戰(zhàn)爬取菜鳥筆記信息
差不多就介紹這么些東西,相信大家對(duì)整體的架構(gòu)有了初步的認(rèn)識(shí),下面我簡(jiǎn)單找了個(gè)網(wǎng)站給大家演示一遍用爬蟲架構(gòu)來(lái)爬取信息:
(目標(biāo)站點(diǎn))
我們來(lái)獲取上面列表中的信息,這里我就省略了分析網(wǎng)站的一步,如果大家不會(huì)分析,可以去看我之前寫的爬蟲項(xiàng)目。
首先,我們來(lái)寫一下URL管理器(URLManage.py)
class URLManager(object): def __init__(self): self.new_urls = set() self.old_urls = set() def has_new_url(self): # 判斷是否有未爬取的url return self.new_url_size()!=0 def get_new_url(self): # 獲取一個(gè)未爬取的鏈接 new_url = self.new_urls.pop() # 提取之后,將其添加到已爬取的鏈接中 self.old_urls.add(new_url) return new_url def add_new_url(self, url): # 將新鏈接添加到未爬取的集合中(單個(gè)鏈接) if url is None: return if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) def add_new_urls(self,urls): # 將新鏈接添加到未爬取的集合中(集合) if urls is None or len(urls)==0: return for url in urls: self.add_new_url(url) def new_url_size(self): # 獲取未爬取的url大小 return len(self.new_urls) def old_url_size(self): # 獲取已爬取的url大小 return len(self.old_urls)
在這里主要就是兩個(gè)集合,一個(gè)是已爬取URL的集合,另一個(gè)是未爬取URL的集合。這里我使用的是set類型,因?yàn)閟et自帶去重的功能。
接下來(lái),HTML下載器(HTMLDownload.py)
importrequestsclassHTMLDownload(object): def download(self, url): if url is None: return s = requests.Session() s.headers['User-Agent'] ='Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 63.0.3239.132Safari / 537.36' res = s.get(url) # 判斷是否正常獲取 if res.status_code == 200: res.encoding='utf-8' res = res.text return resreturnNone
可以看到這里我們只是簡(jiǎn)單的獲取了,url中的html源碼
接著看HTML解析器(HTMLParser.py)
import refrombs4importBeautifulSoupclass HTMLParser(object): def parser(self, page_url, html_cont): ''' 用于解析網(wǎng)頁(yè)內(nèi)容,抽取URL和數(shù)據(jù) :param page_url: 下載頁(yè)面的URL :param html_cont: 下載的網(wǎng)頁(yè)內(nèi)容 :return: 返回URL和數(shù)據(jù) ''' if page_url is None or html_cont is None: return soup = BeautifulSoup(html_cont, 'html.parser') new_urls = self._get_new_urls(page_url, soup) new_data = self._get_new_data(page_url, soup) return new_urls, new_data def _get_new_urls(self,page_url,soup): ''' 抽取新的URL集合 :param page_url:下載頁(yè)面的URL :param soup: soup數(shù)據(jù) :return: 返回新的URL集合 ''' new_urls = set() for link in range(1,100): # 添加新的urlnew_url="http://www.runoob.com/w3cnote/page/"+str(link) new_urls.add(new_url) print(new_urls) return new_urls def _get_new_data(self,page_url,soup): ''' 抽取有效數(shù)據(jù) :param page_url:下載頁(yè)面的url :param soup: :return: 返回有效數(shù)據(jù) ''' data={} data['url'] = page_url title = soup.find('div', class_='post-intro').find('h2') print(title) data['title'] = title.get_text() summary = soup.find('div', class_='post-intro').find('p') data['summary'] = summary.get_text()returndata
在這里,我們將HTML下載器的源碼進(jìn)行了分析和解析,從而得到了我們想要拿到的數(shù)據(jù),如果BeautifulSoup不懂的可以去看一下我之前寫的文章。
繼續(xù)看,數(shù)據(jù)存儲(chǔ)器(DataOutput.py)
importcodecsclass DataOutput(object): def __init__(self): self.datas = [] def store_data(self,data): if data is None: return self.datas.append(data) def output_html(self): fout = codecs.open('baike.html', 'a', encoding='utf-8') fout.write("") fout.write("
") fout.write("") fout.write("| %s | "%data['url']) fout.write("《%s》 | " % data['title']) fout.write("[%s] | " % data['summary']) fout.write("
大家可能發(fā)現(xiàn)我這里是將數(shù)據(jù)存儲(chǔ)到一個(gè)html的文件當(dāng)中,在這里你當(dāng)然也可以存在Mysql或者csv等文件當(dāng)中,這個(gè)看自己的選擇,我這里只是為了演示所以就放在了html當(dāng)中。
最后一個(gè),爬蟲調(diào)度器(SpiderMan.py)
from base.DataOutput import DataOutputfrom base.HTMLParser import HTMLParserfrom base.HTMLDownload import HTMLDownloadfrom base.URLManager import URLManagerclass SpiderMan(object): def __init__(self): self.manager = URLManager() self.downloader = HTMLDownload() self.parser = HTMLParser() self.output = DataOutput() def crawl(self, root_url): # 添加入口URL self.manager.add_new_url(root_url) # 判斷url管理器中是否有新的url,同時(shí)判斷抓取多少個(gè)url while(self.manager.has_new_url() and self.manager.old_url_size()<100): try: # 從URL管理器獲取新的URL new_url = self.manager.get_new_url() print(new_url) # HTML下載器下載網(wǎng)頁(yè) html = self.downloader.download(new_url) # HTML解析器抽取網(wǎng)頁(yè)數(shù)據(jù) new_urls, data = self.parser.parser(new_url, html) print(new_urls) # 將抽取的url添加到URL管理器中 self.manager.add_new_urls(new_urls) # 數(shù)據(jù)存儲(chǔ)器存儲(chǔ)文件 self.output.store_data(data) print("已經(jīng)抓取%s個(gè)鏈接" % self.manager.old_url_size()) except Exception as e: print("failed") print(e) # 數(shù)據(jù)存儲(chǔ)器將文件輸出成指定的格式 self.output.output_html()if __name__ == '__main__': spider_man = SpiderMan()????spider_man.crawl("http://www.runoob.com/w3cnote/page/1")
相信這里大家都能看懂,我就是將前面我們寫的四個(gè)模板在這里把它們調(diào)用了一下,我們運(yùn)行后的結(jié)果:
4總結(jié)
我們這里簡(jiǎn)單的講解了一下,爬蟲架構(gòu)的五個(gè)模板,無(wú)論是大型爬蟲項(xiàng)目還是小型的爬蟲項(xiàng)目都離不開這五個(gè)模板,希望大家能夠照著這些代碼寫一遍,這樣有利于大家的理解,大家以后寫爬蟲項(xiàng)目也要按照這種架構(gòu)去寫,這樣你的爬蟲看起來(lái)就會(huì)更加的規(guī)范、健全。
-
URL
+關(guān)注
關(guān)注
0文章
140瀏覽量
15829 -
python
+關(guān)注
關(guān)注
56文章
4825瀏覽量
86465 -
爬蟲
+關(guān)注
關(guān)注
0文章
83瀏覽量
7438
原文標(biāo)題:Python爬蟲|你真的會(huì)寫爬蟲嗎?
文章出處:【微信號(hào):magedu-Linux,微信公眾號(hào):馬哥Linux運(yùn)維】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
?如何在虛擬環(huán)境中使用 Python,提升你的開發(fā)體驗(yàn)~






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論