") 深度學(xué)習(xí)的方法總結(jié)
深度學(xué)習(xí)的方法總結(jié)

1. 參數(shù)初始化
訓(xùn)練之前一定要執(zhí)行參數(shù)初始化,否則可能減慢收斂速度,影響訓(xùn)練結(jié)果,或者造成Nan數(shù)值溢出等異常問題。
特別的,如果所有參數(shù)都是0,則反向傳播時,隱含層中所有參數(shù)的地位是一樣,導(dǎo)致每次更新后隱層的參數(shù)都是一樣的,導(dǎo)致學(xué)習(xí)失敗。
初始化方法:隨機初始化、高斯分布初始化、均勻初始化、與參數(shù)量 n 相關(guān)的平方、開放初始化等。
xavier初始化:xavier初始化方法由Bengio在2010年提出,基本思想是要保證前向傳播和反向傳播時每一層的方差一致,根據(jù)每層的輸入個數(shù)和輸出個數(shù)來決定參數(shù)隨機初始化的分布范圍,是一個通過該層的輸入和輸出參數(shù)個數(shù)得到的分布范圍內(nèi)的均勻分布。
2. 數(shù)據(jù)預(yù)處理
輸入數(shù)據(jù)歸一化到 [0,1]或者以 0 為中心的 [-1,1],一般要做精度提升。
輸入數(shù)據(jù)要做隨機排序。
3. 訓(xùn)練技巧相關(guān)
梯度歸一化:計算出來梯度之后,要除以minibatch的數(shù)量,這樣就不顯式依賴minibatch size。
梯度限制:限制最大梯度,超過閾值乘一個衰減系數(shù),防止梯度爆炸。
batchsize:batch size值增加,的確能提高訓(xùn)練速度。但是有可能收斂結(jié)果變差。batch size 太小,不能充分利用批量訓(xùn)練的優(yōu)點,可能使訓(xùn)練速度下降,嚴重的或不收斂。
學(xué)習(xí)率:太大的學(xué)習(xí)率,不收斂,導(dǎo)致在最優(yōu)解附近震蕩; 太小的學(xué)習(xí)率,收斂慢,陷入局部最優(yōu)解的可能增大。 可設(shè)置動態(tài)的學(xué)習(xí)率,逐步減小。
動量momentum:滑動平均模型,在訓(xùn)練的過程中不斷的對參數(shù)求滑動平均這樣能夠更有效的保持穩(wěn)定性,使其對當前參數(shù)更新不太敏感,保留之前梯度下降的方向,以加快收斂。一般動量選擇在0.9-0.95之間。
濾波器核大小:一般選奇數(shù)核,根據(jù)輸入尺寸大小調(diào)整。
dropout:一般選0.5, 測試時候記得關(guān)閉dropout。
Batch Normalization:加BN批規(guī)范化層。
池化的選擇:一般最大池化。
shortcut的位置選擇。
CNN中滑動步長。
網(wǎng)絡(luò)深度:非越深越好。
訓(xùn)練次數(shù)epoch:可以設(shè)置提前結(jié)束,防止過擬合。
Inception modeles:組成Inception的濾波器個數(shù)和濾波核大小,以及深度。
增加非線性:Relu函數(shù)等。
LSTM中遺忘門參數(shù)設(shè)置:開始時候設(shè)置較大的遺忘參數(shù),可能效果更好。
4. CNN的魅力
CNN可以很好的處理局部與整體,低層次特性到高層次特征的映射。
CNN的四個主要特點:局部連接/權(quán)值共享/池化操作/多層次結(jié)構(gòu)。
局部連接使網(wǎng)絡(luò)可以提取數(shù)據(jù)的局部特征;
權(quán)值共享大大降低了網(wǎng)絡(luò)的訓(xùn)練難度,一個Filter只提取一個特征,在整個圖片(或者語音/文本) 中進行卷積;
池化操作與多層次結(jié)構(gòu)一起,實現(xiàn)了數(shù)據(jù)的降維,將低層次的局部特征組合成為較高層次的特征。
5. LSTM與RNN
RNN 是包含循環(huán)的網(wǎng)絡(luò),允許信息的持久化。
LSTM可以緩解RNN中梯度消失問題,可以處理長期依賴問題。
LSTM中sigmoid和Tanh函數(shù)不同作用:sigmoid 用在各種gate上,作用是產(chǎn)生0~1之間的值,這個一般只有sigmoid最直接了。
tanh 用在了狀態(tài)和輸出上,是對數(shù)據(jù)的處理,這個用其他激活函數(shù)或許也可以。
6. 注意力模型 Attention機制
注意力機制即 Attention 機制在序列學(xué)習(xí)任務(wù)上具有巨大的提升作用,Attention機制的設(shè)計可以優(yōu)化傳統(tǒng)編碼解碼(Encode-Decode)結(jié)構(gòu)。
傳統(tǒng)編碼解碼結(jié)構(gòu):傳統(tǒng)編碼器-解碼器的RNN模型先用一些LSTM單元來對輸入序列進行學(xué)習(xí),編碼為固定長度的向量表示;然后再用一些LSTM單元來讀取這種向量表示并解碼為輸出序列。
傳統(tǒng)編碼解碼結(jié)構(gòu)存在的最大問題是:輸入序列不論長短都會被編碼成一個固定長度的向量表示,而解碼則受限于該固定長度的向量表示,尤其是當輸入序列比較長時,模型的性能會變得很差。
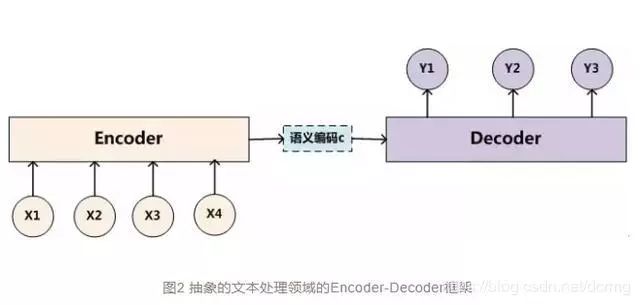
Attention機制的基本思想是,打破了傳統(tǒng)編碼器-解碼器結(jié)構(gòu)在編解碼時都依賴于內(nèi)部一個固定長度向量的限制。
Attention機制的實現(xiàn)是通過保留LSTM編碼器對輸入序列的中間輸出結(jié)果,然后訓(xùn)練一個模型來對這些輸入進行選擇性的學(xué)習(xí)并且在模型輸出時將輸出序列與之進行關(guān)聯(lián)。
使用attention機制便于理解在模型輸出過程中輸入序列中的信息是如何影響最后生成序列的。這有助于我們更好地理解模型的內(nèi)部運作機制以及對一些特定的輸入-輸出進行debug。
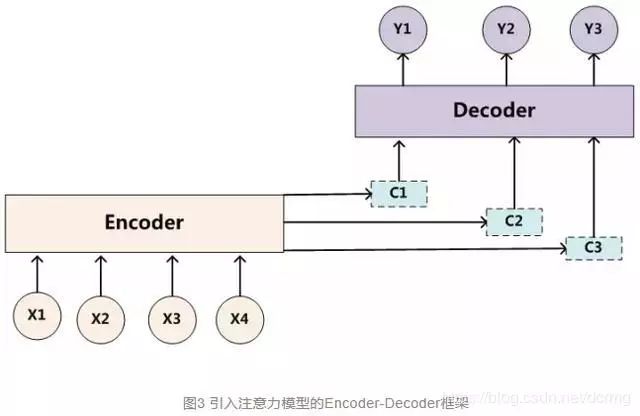
深度學(xué)習(xí)中的注意力機制從本質(zhì)上講和人類的選擇性視覺注意力機制類似,核心目標也是從眾多信息中選擇出對當前任務(wù)目標更關(guān)鍵的信息。
7. 過擬合和正則化
過擬合問題往往源于過多的特征,對訓(xùn)練集的擬合能力很強,但是到測試集上,輕微的數(shù)據(jù)偏差就導(dǎo)致結(jié)果上較大的偏差。
解決過擬合的方法:
① 減少特征的數(shù)量,保留較關(guān)鍵的信息;
② 使用正則化方法。
正則化方法會保留所有的特征,但是增加了對特征的約束,每一個特征都會對預(yù)測y貢獻一份合適的力量。具體做法是給需要訓(xùn)練的目標函數(shù)加上一些規(guī)則(限制)項,控制參數(shù)的幅度,不至于波動太大。
L1正則化:L1正則化是指權(quán)值向量(系數(shù))w中各個元素的絕對值之和。一般都會在正則化項之前添加一個系數(shù),系數(shù)越大,正則化作用越明顯。
L1正則化有助于生成一個稀疏權(quán)值矩陣,進而可以用于特征選擇。相當于減少了特征數(shù)量,所以說是進行了特征選擇。系數(shù)越大,正則化作用越明顯。
L2正則化:L2正則化是指權(quán)值向量w中各個元素的平方和然后再求平方根一般都會在正則化項之前添加一個系數(shù)。
L2正則化傾向于讓權(quán)值盡可能小,最后構(gòu)造一個所有參數(shù)都比較小的模型。因為一般認為參數(shù)值小的模型比較簡單,能適應(yīng)不同的數(shù)據(jù)集(由于參數(shù)比較小,數(shù)據(jù)本身的波動對結(jié)果影響不至于太大),也在一定程度上避免了過擬合現(xiàn)象。
8. Relu激活函數(shù)的優(yōu)點
sigmoid函數(shù)范圍[0,1], tanh函數(shù)范圍[-1,1], Relu函數(shù)范圍[0,無窮]。
計算量上,Sigmoid和T函數(shù)含有指數(shù),Relu函數(shù)是簡單的線性,所以Relu的計算量小很多。
梯度消失上,Sigmoid和T函數(shù)在接近飽和區(qū)時,梯度很小,更新緩慢,Relu不存在梯度過小情況。
稀疏性能上,Relu函數(shù)會使一部分神經(jīng)元的輸出為0,這樣就造成了網(wǎng)絡(luò)的稀疏性,并且減少了參數(shù)的相互依存關(guān)系,緩解了過擬合問題的發(fā)生。
9. 梯度彌散與梯度爆炸
梯度彌散現(xiàn)象:靠近輸出層的隱藏層梯度大,參數(shù)更新快,所以很快就會收斂;而靠近輸入層的隱藏層梯度小,參數(shù)更新慢,幾乎就和初始狀態(tài)一樣,隨機分布。這種現(xiàn)象就是梯度彌散。指的是反向傳播過程中,梯度開始很大,但是很快就降低到一個很小的值。
梯度爆炸現(xiàn)象:靠近輸出層的隱藏層梯度很小,參數(shù)更新慢,幾乎不會收斂,而靠近輸入層的隱藏層梯度變得很大,參數(shù)更新快,很快就會收斂。這種現(xiàn)象就是梯度爆炸。指的是反向傳播過程中,梯度開始時候很小,但是梯度以指數(shù)級增長。
梯度爆炸與梯度彌散的特點是梯度相當不穩(wěn)定(unstable),學(xué)習(xí)效果很差。
導(dǎo)致梯度彌散與梯度爆炸現(xiàn)象的原因:
在使用sigmoid作為激活函數(shù)的網(wǎng)絡(luò)中,如果使用均值為0,方差為1的高斯分布初始化參數(shù)w,有|w| < 1。
又知sigmoid函數(shù)的特性是把+∞~-∞之間的輸入壓縮到0~1之間,所以反向傳播時,梯度會以指數(shù)級減小,靠近輸入層的系數(shù)得不到更新,導(dǎo)致梯度彌散。而如果初始化時候采用|w| > 1 的系數(shù),又會導(dǎo)致梯度以指數(shù)級增大,靠近輸入層的系數(shù)得到的梯度過大,導(dǎo)致梯度爆炸。
解決梯度彌散與梯度爆炸
① 使用Relu激活函數(shù)可以緩解梯度的不穩(wěn)定情況,Relu的導(dǎo)數(shù)不是0就是1,不會指數(shù)級縮小或擴大。
② 加入BN層,約束輸出到一個范圍。BN添加在每層激活函數(shù)之前,就是做均值和方差歸一化
③ 梯度裁剪,如果梯度大于或小于某個值,就將梯度按比例縮小或擴大。
為什么LSTM在預(yù)防梯度彌散與梯度爆炸上性能由于RNN
傳統(tǒng)RNN對狀態(tài)的維護是通過乘積的方式,這導(dǎo)致在鏈式求導(dǎo)梯度時,梯度被表示為連積的形式,造成梯度爆炸或彌散。
LSTM對狀態(tài)的維護是通過累加的方式,不至于使得梯度變化過快。
10. 常見損失函數(shù)
分類算法中,損失函數(shù)通常可以表示成損失項和正則項的和。
損失項常用損失函數(shù):
0-1損失函數(shù): 預(yù)測相符為1,不符為0。實際中需要設(shè)置判定區(qū)間。
log對數(shù)損失函數(shù)
exp指數(shù)損失函數(shù)
平方差損失函數(shù)
交叉熵損失函數(shù)
絕對損失函數(shù)
11. 明星CNN模型

12. rcnn、fast-rcnn和faster-rcnn
RCNN系列是把檢測定位問題轉(zhuǎn)換為分類問題來實現(xiàn)的。
RCNN:RCNN使用了region proposal(建議區(qū)域)得到可能是目標的若干局部區(qū)域,使用CNN分別提取這些區(qū)域的特征,再使用SVM分類器做分類判斷。
fast-rcnn:rcnn的若干局部區(qū)域(約1000個)存在特征重復(fù)計算的問題,fast-rcnn把這些局部區(qū)域映射到最后一層的特征圖上,一張圖僅需要提取一次特征就行了,大大提高了計算速度。
faster-rcnn:將Region proposal的工作也交給CNN(其實也是一個fast-rcnn)網(wǎng)絡(luò)來做,這個網(wǎng)絡(luò)把圖片固定劃分為n×n的區(qū)域,分別輸出建議的位置和前后景分類,再把結(jié)果送入fast-rcnn做精細判斷。
faster-rcnn把圖片做物理上的切割,有可能忽略了局部相關(guān)性信息,準確度有可能降低。
目標檢測方法
第一類:傳統(tǒng)目標檢測算法: 級聯(lián)+特征+分類器
第二類:基于候選區(qū)域的檢測方法: RCNN系列
第三類:基于回歸方法的檢測: YOLO、SSD等
13. 防止過擬合的方法
① Dropout
② L1、L2正則化
③ BatchNormalization
④ 網(wǎng)絡(luò)bagging(略等于Dropout方法)
⑤ 數(shù)據(jù)預(yù)處理
14. 嘗試調(diào)參解決深度學(xué)習(xí)中的過擬合問題
① 檢查batch size
② 檢查損失函數(shù)
③ 檢查激活函數(shù)
④ 檢查學(xué)習(xí)率
⑤ 檢查動量設(shè)置
⑥提前停止
⑦ 設(shè)置權(quán)重衰減
⑧ 檢查Dropout
⑨ 嘗試BN
15. Bounding-Box regression 邊框回歸是什么操作
通常預(yù)測出來的目標的邊界跟Ground Truth之間有差異,需要經(jīng)過邊框回歸來微調(diào)這個邊界窗口,使檢測結(jié)果更準確。
目標窗口一般使用四維向量(x,y,w,h)來表示,分別表示窗口的中心點坐標和寬高。邊框回歸的目標是使得候選框逼近與真實框。如何實現(xiàn)邊框回歸,二個框的差異體現(xiàn)在位置和大小上,所以對其修正也可以從平移+縮放實現(xiàn)。分別是X方向上的平移、縮放和Y方向上的平移和縮放,一共4個映射關(guān)系。
4個映射關(guān)系的求解:輸入候選框?qū)?yīng)的CNN特征,跟Ground Truth框?qū)?yīng)的特征做損失函數(shù),輸出平移和縮放參數(shù)。
16. 非極大值抑制(NMS)是什么操作
RCNN中檢出的n個框可能彼此重合,進行非極大值抑制就是根據(jù)n個框的分類概率從大到小,依次合并的算法。
① 從最大概率矩形框F開始,分別判斷A~E與F的重疊度IOU是否大于某個設(shè)定的閾值;
② 假設(shè)B、D與F的重疊度超過閾值,那么就扔掉B、D;并標記第一個矩形框F,是我們保留下來的。
③ 從剩下的矩形框A、C、E中,選擇概率最大的E,然后判斷E與A、C的重疊度,重疊度大于一定的閾值,那么就扔掉;并標記E是我們保留下來的第二個矩形框。
就這樣一直重復(fù),找到所有被保留下來的矩形框。
非極大值抑制(NMS)顧名思義就是抑制不是極大值的元素,搜索局部的極大值。這個局部代表的是一個鄰域。
17. 深度學(xué)習(xí)中加快訓(xùn)練速度方法
①提高學(xué)習(xí)率
②增加batch size
③預(yù)訓(xùn)練
④動量
⑤增加步長
⑥使用殘差
18. 如何使網(wǎng)絡(luò)跳出局部極小值
調(diào)整學(xué)習(xí)率,使用變化(衰減)的學(xué)習(xí)率。也可以嘗試分段的學(xué)習(xí)率,在后期較小的學(xué)習(xí)率上增加一個大一點的學(xué)習(xí)率,有可能借此跳出局部最有解。
設(shè)置更優(yōu)的初始化參數(shù)。 初始化參數(shù)的設(shè)定定義了訓(xùn)練起始點的位置。
增加或調(diào)整動量,一般動量參數(shù)設(shè)置0.9~0.95
使用隨機梯度下降或者調(diào)整batch size
嘗試Adam算法
Adam算法即自適應(yīng)時刻估計方法(Adaptive Moment Estimation),能計算每個參數(shù)的自適應(yīng)學(xué)習(xí)率。這個方法不僅存儲了AdaDelta先前平方梯度的指數(shù)衰減平均值,而且保持了先前梯度M(t)的指數(shù)衰減平均值,這一點與動量類似。
在實際應(yīng)用中,Adam方法效果良好。與其他自適應(yīng)學(xué)習(xí)率算法相比,其收斂速度更快,學(xué)習(xí)效果更為有效,而且可以糾正其他優(yōu)化技術(shù)中存在的問題,如學(xué)習(xí)率消失、收斂過慢或是高方差的參數(shù)更新導(dǎo)致?lián)p失函數(shù)波動較大等問題。
19. 梯度下降法和其他無約束優(yōu)化算法的比較
無約束優(yōu)化算法,除了梯度下降以外,還有最小二乘法、牛頓法和擬牛頓法。
梯度下降法和最小二乘法相比,梯度下降法需要選擇學(xué)習(xí)率(步長),而最小二乘法不需要。
梯度下降法是迭代求解,最小二乘法是計算解析解。
如果樣本量不算很大,且存在解析解,最小二乘法比起梯度下降法要有優(yōu)勢,計算速度很快。
但是如果樣本量很大,用最小二乘法由于需要求一個超級大的逆矩陣,這時就很難或者很慢才能求解解析解了,使用迭代的梯度下降法比較有優(yōu)勢。
梯度下降法和牛頓法/擬牛頓法相比,兩者都是迭代求解,不過梯度下降法是梯度求解,是一階的方法,而牛頓法/擬牛頓法是用二階的海森矩陣的逆矩陣或偽逆矩陣求解。
相對而言,使用牛頓法/擬牛頓法收斂更快。但是每次迭代的時間比梯度下降法長。
牛頓法其實就是通過切線與x軸的交點不斷更新切線的位置,直到達到曲線與x軸的交點得到方程解。
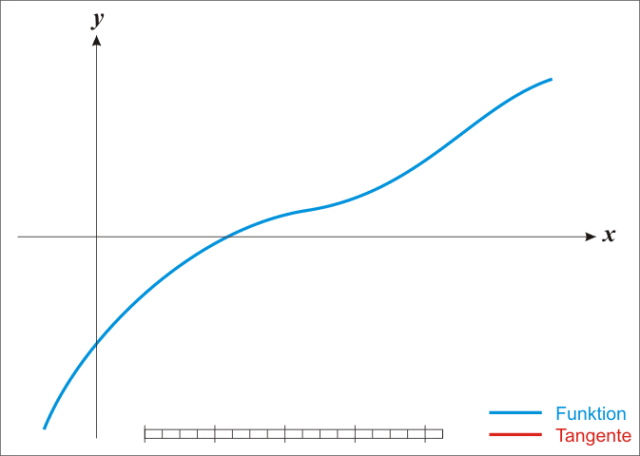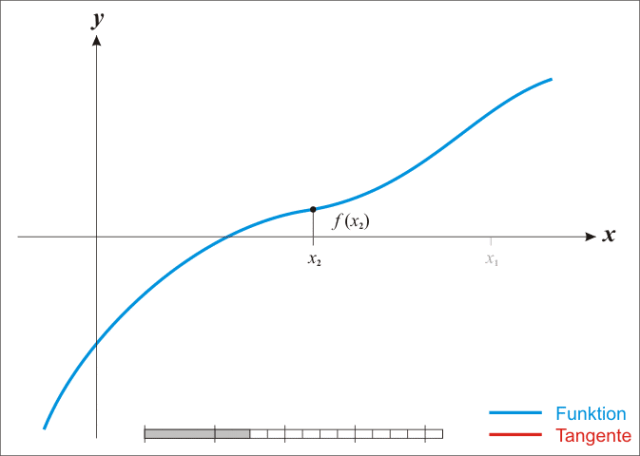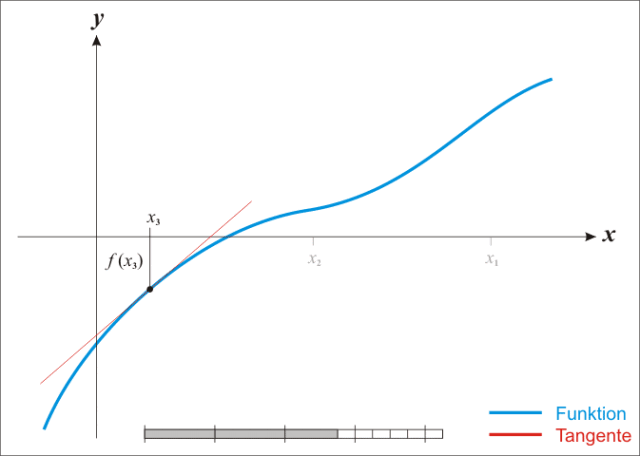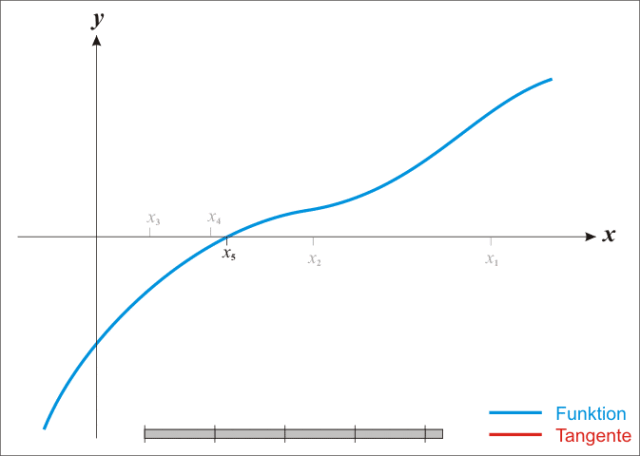
牛頓法不需要設(shè)置步長,要求函數(shù)是二階可導(dǎo)的。
擬牛頓法:不用二階偏導(dǎo)而是構(gòu)造出Hessian矩陣的近似正定對稱矩陣的方法稱為擬牛頓法
20. DenseNet
DenseNet是CVPR 2017最佳論文,在ResNet及Inception網(wǎng)絡(luò)基礎(chǔ)上做了優(yōu)化,主要優(yōu)化是(在稠密連接模塊里)做了密集連接,緩解了梯度消失問題,減少了參數(shù)量。
在DenseNet中,任何兩層之間都有直接的連接,也就是說,網(wǎng)絡(luò)每一層的輸入都是前面所有層輸出的并集,而該層所學(xué)習(xí)的特征圖也會被直接傳給其后面所有層作為輸入。下圖是 DenseNet 的一個dense block示意圖:
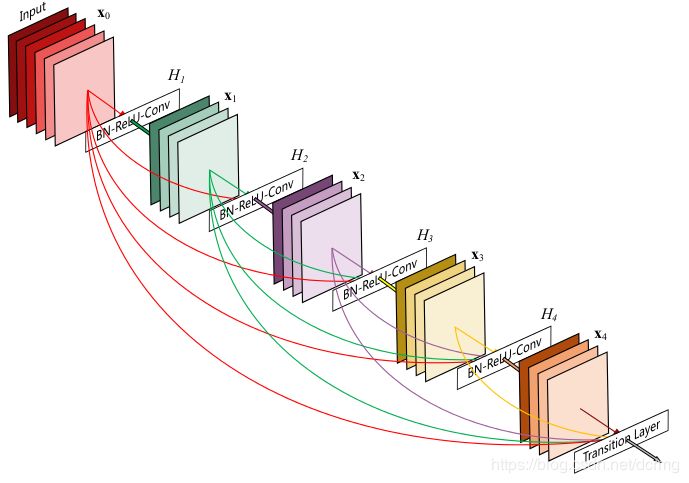
需要明確一點,dense connectivity 僅僅是在一個dense block里的,不同dense block 之間是沒有dense connectivity的,在稠密連接模塊之間以一個卷積和池化層連接:
DenseNet通過稠密連接,降低了參數(shù)量,但是由于要保存很多網(wǎng)絡(luò)先前的計算狀態(tài),所以在內(nèi)存占用方面很恐怖。
-
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5561瀏覽量
122778
原文標題:深度學(xué)習(xí)的一些方法
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
卷積神經(jīng)網(wǎng)絡(luò)—深度卷積網(wǎng)絡(luò):實例探究及學(xué)習(xí)總結(jié)
基于深度學(xué)習(xí)的異常檢測的研究方法
基于深度學(xué)習(xí)的異常檢測的研究方法
什么是深度學(xué)習(xí)?使用FPGA進行深度學(xué)習(xí)的好處?
嵌入式linux學(xué)習(xí)方法總結(jié)
采用無監(jiān)督學(xué)習(xí)的方法,用深度摘要網(wǎng)絡(luò)總結(jié)視頻
深度學(xué)習(xí)優(yōu)化器方法及學(xué)習(xí)率衰減方式的詳細資料概述
FPGA做深度學(xué)習(xí)加速的技能總結(jié)
分析總結(jié)基于深度神經(jīng)網(wǎng)絡(luò)的圖像語義分割方法

基于模板、檢索和深度學(xué)習(xí)的圖像描述生成方法
基于深度學(xué)習(xí)的信息級聯(lián)預(yù)測方法研究綜述

深度學(xué)習(xí)中的時間序列分類方法
Pytorch深度學(xué)習(xí)訓(xùn)練的方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論