") 25篇視覺領(lǐng)域前沿論文的摘要解讀
25篇視覺領(lǐng)域前沿論文的摘要解讀

CVPR 2019錄取1299篇論文,其中騰訊優(yōu)圖實(shí)驗(yàn)室喜提25篇,本文帶來這25篇視覺領(lǐng)域前沿論文的摘要解讀。
CVPR 2019 即將于六月在美國(guó)長(zhǎng)灘召開,本屆大會(huì)總共錄取來自全球論文 1299 篇。CVPR 作為計(jì)算機(jī)視覺領(lǐng)域級(jí)別最高的研究會(huì)議,其錄取論文代表了計(jì)算機(jī)視覺領(lǐng)域在 2019 年最新和最高的科技水平以及未來發(fā)展潮流。
CVPR 官網(wǎng)顯示,今年有超過5165篇的大會(huì)論文投稿,錄取1299篇論文,比去年增長(zhǎng)了 32%(2017 年錄取 979 篇)。
其中,騰訊有超過58篇論文被本屆 CVPR 大會(huì)接收,其中騰訊優(yōu)圖實(shí)驗(yàn)室25篇、騰訊 AI Lab33篇。
被收錄的論文涵蓋深度學(xué)習(xí)優(yōu)化原理、視覺對(duì)抗學(xué)習(xí)、人臉建模與識(shí)別、視頻深度理解、行人重識(shí)別、人臉檢測(cè)等熱門及前沿領(lǐng)域。本文帶來騰訊優(yōu)圖實(shí)驗(yàn)室以及其他優(yōu)圖聯(lián)合高校實(shí)驗(yàn)室的 25 篇 CVPR論文的解讀。
25篇CVPR論文解讀
1. Unsupervised Person Re-identification by Soft Multilabel Learning
軟多標(biāo)簽學(xué)習(xí)的無監(jiān)督行人重識(shí)別
相對(duì)于有監(jiān)督行人重識(shí)別(RE-ID)方法,無監(jiān)督 RE-ID因其更佳的可擴(kuò)展性受到越來越多的研究關(guān)注,然而在非交疊的多相機(jī)視圖下,標(biāo)簽對(duì)(pairwise label)的缺失導(dǎo)致學(xué)習(xí)鑒別性的信息仍然是非常具有挑戰(zhàn)性的工作。
為了克服這個(gè)問題,我們提出了一個(gè)用于無監(jiān)督 RE-ID 的軟多標(biāo)簽學(xué)習(xí)深度模型。該想法通過將未標(biāo)注的人與輔助域里的一組已知參考者進(jìn)行比較,為未標(biāo)注者標(biāo)記軟標(biāo)簽(類似實(shí)值標(biāo)簽的似然向量)。
基于視覺特征以及未標(biāo)注目標(biāo)對(duì)的軟性標(biāo)簽的相似度一致性,我們提出了軟多標(biāo)簽引導(dǎo)的hard negative mining 方法去學(xué)習(xí)一種區(qū)分性嵌入表示(discriminative embedding)。由于大多數(shù)目標(biāo)對(duì)來自交叉視角,我們提出了交叉視角下的軟性多標(biāo)簽一致性學(xué)習(xí)方法,以保證不同視角下標(biāo)簽的一致性。為實(shí)現(xiàn)高效的軟標(biāo)簽學(xué)習(xí),引入了參考代理學(xué)習(xí)(reference agent learning)。
我們的方法在 Market-1501 和 DukeMTMC-reID 上進(jìn)行了評(píng)估,顯著優(yōu)于當(dāng)前最好的無監(jiān)督 RE-ID 方法。
2. Visual Tracking via Adaptive Spatially-Regularized Correlation Filters
基于自適應(yīng)空間加權(quán)相關(guān)濾波的視覺跟蹤研究
本文提出自適應(yīng)空間約束相關(guān)濾波算法來同時(shí)優(yōu)化濾波器權(quán)重及空間約束矩陣。
首先,本文所提出的自適應(yīng)空間約束機(jī)制可以高效地學(xué)習(xí)得到一個(gè)空間權(quán)重以適應(yīng)目標(biāo)外觀變化,因此可以得到更加魯棒的目標(biāo)跟蹤結(jié)果。
其次,本文提出的算法可以通過交替迭代算法來高效進(jìn)行求解,基于此,每個(gè)子問題都可以得到閉合的解形式。
再次,本文所提出的跟蹤器使用兩種相關(guān)濾波模型來分別估計(jì)目標(biāo)的位置及尺度,可以在得到較高定位精度的同時(shí)有效減少計(jì)算量。大量的在綜合數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果證明了本文所提出的算法可以與現(xiàn)有的先進(jìn)算法取得相當(dāng)?shù)母櫧Y(jié)果,并且達(dá)到了實(shí)時(shí)的跟蹤速度。
3. Adversarial Attacks Beyond the Image Space
超越圖像空間的對(duì)抗攻擊
生成對(duì)抗實(shí)例是理解深度神經(jīng)網(wǎng)絡(luò)工作機(jī)理的重要途徑。大多數(shù)現(xiàn)有的方法都會(huì)在圖像空間中產(chǎn)生擾動(dòng),即獨(dú)立修改圖像中的每個(gè)像素。
在本文中,我們更為關(guān)注與三維物理性質(zhì)(如旋轉(zhuǎn)和平移、照明條件等)有意義的變化相對(duì)應(yīng)的對(duì)抗性示例子集。可以說,這些對(duì)抗方法提出了一個(gè)更值得關(guān)注的問題,因?yàn)樗麄冏C明簡(jiǎn)單地干擾現(xiàn)實(shí)世界中的三維物體和場(chǎng)景也有可能導(dǎo)致神經(jīng)網(wǎng)絡(luò)錯(cuò)分實(shí)例。
在分類和視覺問答問題的任務(wù)中,我們?cè)诮邮?2D 輸入的神經(jīng)網(wǎng)絡(luò)前邊增加一個(gè)渲染模塊來拓展現(xiàn)有的神經(jīng)網(wǎng)絡(luò)。我們的方法的流程是:先將 3D 場(chǎng)景(物理空間)渲染成 2D 圖片(圖片空間),然后經(jīng)過神經(jīng)網(wǎng)絡(luò)把他們映射到一個(gè)預(yù)測(cè)值(輸出空間)。這種對(duì)抗性干擾方法可以超越圖像空間。在三維物理世界中有明確的意義。雖然圖像空間的對(duì)抗攻擊可以根據(jù)像素反照率的變化來解釋,但是我們證實(shí)它們不能在物理空間給出很好的解釋,這樣通常會(huì)具有非局部效應(yīng)。但是在物理空間的攻擊是有可能超過圖像空間的攻擊的,雖然這個(gè)比圖像空間的攻擊更難,體現(xiàn)在物理世界的攻擊有更低的成功率和需要更大的干擾。
4. Learning Context Graph for Person Search
基于上下文圖網(wǎng)絡(luò)的行人檢索模型
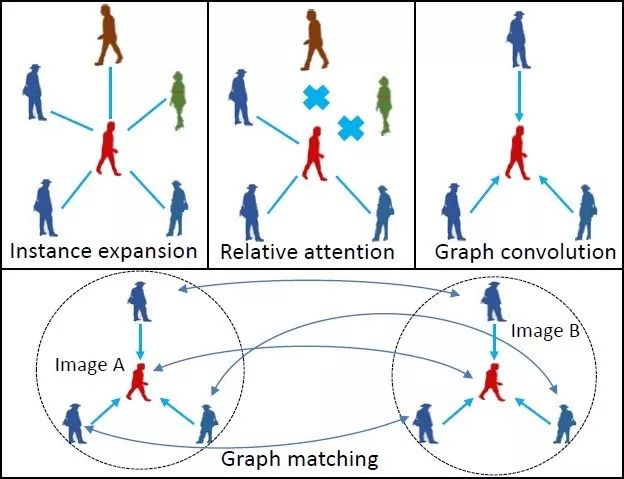
本文由騰訊優(yōu)圖實(shí)驗(yàn)室與上海交通大學(xué)主導(dǎo)完成。
近年來,深度神經(jīng)網(wǎng)絡(luò)在行人檢索任務(wù)中取得了較大的成功。但是這些方法往往只基于單人的外觀信息,其在處理跨攝像頭下行人外觀出現(xiàn)姿態(tài)變化、光照變化、遮擋等情況時(shí)仍然比較困難。
本文提出了一種新的基于上下文信息的行人檢索模型。所提出的模型將場(chǎng)景中同時(shí)出現(xiàn)的其他行人作為上下文信息,并使用卷積圖模型建模這些上下文信息對(duì)目標(biāo)行人的影響。我們?cè)趦蓚€(gè)著名的行人檢索數(shù)據(jù)集 CUHK-SYSU 和 PRW 的兩個(gè)評(píng)測(cè)維度上刷新了當(dāng)時(shí)的世界紀(jì)錄,取得了top1 的行人檢索結(jié)果。
5. Underexposed Photo Enhancement using Deep Illumination Estimation
基于深度學(xué)習(xí)優(yōu)化光照的暗光下的圖像增強(qiáng)
本文介紹了一種新的端到端網(wǎng)絡(luò),用于增強(qiáng)曝光不足的照片。
我們不是像以前的工作那樣直接學(xué)習(xí)圖像到圖像的映射,而是在我們的網(wǎng)絡(luò)中引入中間照明,將輸入與預(yù)期的增強(qiáng)結(jié)果相關(guān)聯(lián),這增強(qiáng)了網(wǎng)絡(luò)從專家修飾的輸入/輸出圖像學(xué)習(xí)復(fù)雜的攝影調(diào)整的能力。
基于該模型,我們制定了一個(gè)損失函數(shù),該函數(shù)采用約束和先驗(yàn)在中間的照明上,我們準(zhǔn)備了一個(gè)3000 個(gè)曝光不足的圖像對(duì)的新數(shù)據(jù)集,并訓(xùn)練網(wǎng)絡(luò)有效地學(xué)習(xí)各種照明條件的豐富多樣的調(diào)整。
通過這些方式,我們的網(wǎng)絡(luò)能夠在增強(qiáng)結(jié)果中恢復(fù)清晰的細(xì)節(jié),鮮明的對(duì)比度和自然色彩。我們對(duì)基準(zhǔn) MIT-Adobe FiveK 數(shù)據(jù)集和我們的新數(shù)據(jù)集進(jìn)行了大量實(shí)驗(yàn),并表明我們的網(wǎng)絡(luò)可以有效地處理以前的困難圖像。
6. Homomorphic Latent Space Interpolation for Unpaired Image-to-imageTranslation
基于同態(tài)隱空間插值的不成對(duì)圖片到圖片轉(zhuǎn)換
生成對(duì)抗網(wǎng)絡(luò)在不成對(duì)的圖像到圖像轉(zhuǎn)換中取得了巨大成功。循環(huán)一致性允許對(duì)沒有配對(duì)數(shù)據(jù)的兩個(gè)不同域之間的關(guān)系建模。
在本文中,我們提出了一個(gè)替代框架,作為潛在空間插值的擴(kuò)展,在圖像轉(zhuǎn)換中考慮兩個(gè)域之間的中間部分。
該框架基于以下事實(shí):在平坦且光滑的潛在空間中,存在連接兩個(gè)采樣點(diǎn)的多條路徑。正確選擇插值的路徑允許更改某些圖像屬性,而這對(duì)于在兩個(gè)域之間生成中間圖像是非常有用的。我們還表明該框架可以應(yīng)用于多域和多模態(tài)轉(zhuǎn)換。廣泛的實(shí)驗(yàn)表明該框架對(duì)各種任務(wù)具有普遍性和適用性。
7. X2CT-GAN: Reconstructing CT from Biplanar X-Rays with GenerativeAdversarial Networks
基于生成對(duì)抗網(wǎng)絡(luò)的雙平面 X 光至 CT 生成系統(tǒng)
當(dāng)下 CT 成像可以提供三維全景視角幫助醫(yī)生了解病人體內(nèi)的組織器官的情況,來協(xié)助疾病的診斷。但是 CT 成像與 X 光成像相比,給病人帶來的輻射劑量較大,并且費(fèi)用成本較高。傳統(tǒng) CT 影像的三維重建過程中圍繞物體中心旋轉(zhuǎn)采集并使用了大量的 X 光投影,這在傳統(tǒng)的 X 光機(jī)中也是不能實(shí)現(xiàn)的。
在這篇文章中,我們創(chuàng)新性的提出了一種基于對(duì)抗生成網(wǎng)絡(luò)的方法,只使用兩張正交的二維 X 光圖片來重建逼真的三維 CT 影像。核心的創(chuàng)新點(diǎn)包括增維生成網(wǎng)絡(luò),多視角特征融合算法等。
我們通過實(shí)驗(yàn)與量化分析,展示了該方法在二維 X 光到三維 CT 重建上大大優(yōu)于其他對(duì)比方法。通過可視化 CT 重建結(jié)果,我們也可以直觀的看到該方法提供的細(xì)節(jié)更加逼真。在實(shí)際應(yīng)用中, 我們的方法在不改變現(xiàn)有 X 光成像流程的前提下,可以給醫(yī)生提供額外的類 CT 的三維影像,來協(xié)助他們更好的診斷。
8. Semantic Regeneration Network
語(yǔ)義再生網(wǎng)絡(luò)
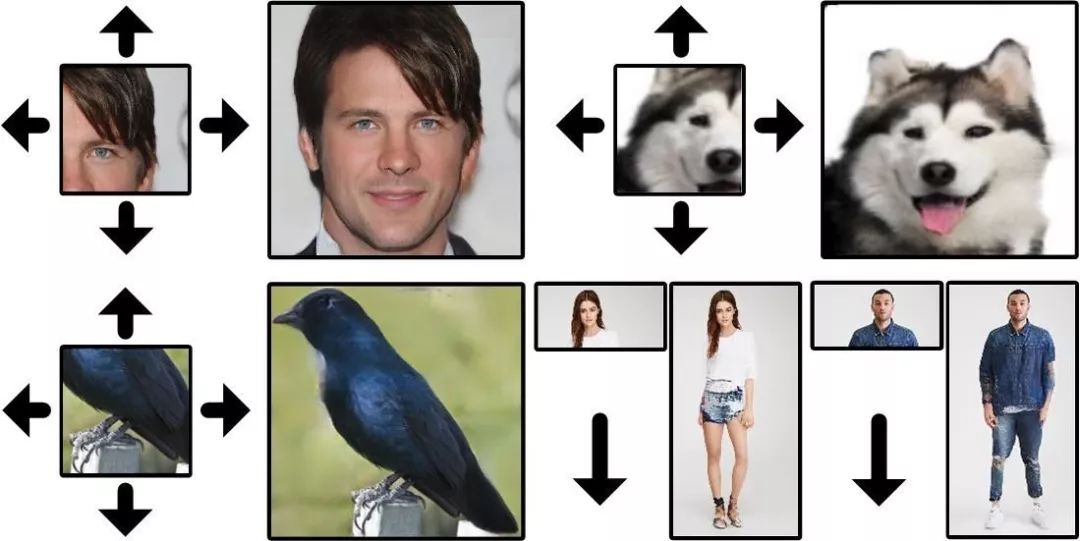
本文研究了使用深度生成模型推斷視覺上下文的基本問題,即利用合理的結(jié)構(gòu)和細(xì)節(jié)擴(kuò)展圖像邊界。這個(gè)看似簡(jiǎn)單的任務(wù)實(shí)際上面臨著許多關(guān)鍵的技術(shù)挑戰(zhàn),并且具有其獨(dú)特的性質(zhì)。任務(wù)里兩個(gè)主要問題是擴(kuò)展尺寸和單面約束。我們提出了一個(gè)具有多個(gè)特殊貢獻(xiàn)的語(yǔ)義再生網(wǎng)絡(luò),并使用多個(gè)空間相關(guān)的損失來解決這些問題。
本文最終的實(shí)驗(yàn)結(jié)果包含了高度一致的結(jié)構(gòu)和高品質(zhì)的紋理。我們對(duì)各種可能的替代方案和相關(guān)方法進(jìn)行了廣泛的實(shí)驗(yàn)。最后, 我們也探索了我們的方法對(duì)各種有趣應(yīng)用的潛力,這些應(yīng)用可以使各個(gè)領(lǐng)域的研究受益。
9. Towards Accurate One-Stage Object Detection with AP-Loss
利用 AP 損失函數(shù)實(shí)現(xiàn)精確的一階目標(biāo)檢測(cè)
一階的目標(biāo)檢測(cè)器通常是通過同時(shí)優(yōu)化分類損失函數(shù)和定位損失函數(shù)來訓(xùn)練。而由于存在大量的錨框,分類損失函數(shù)的效果會(huì)嚴(yán)重受限于前景-背景類的不平衡。
本文通過提出一種新的訓(xùn)練框架來解決這個(gè)問題。我們使用排序任務(wù)替換一階目標(biāo)檢測(cè)器中的分類任務(wù),并使用排序問題的中的評(píng)價(jià)指標(biāo) AP 來作為損失函數(shù)。由于其非連續(xù)和非凸,AP 損失函數(shù)不能直接通過梯度下降優(yōu)化。
為此,我們提出了一種新穎的優(yōu)化算法,它將感知機(jī)學(xué)習(xí)中的誤差驅(qū)動(dòng)更新方案和深度網(wǎng)絡(luò)中的反向傳播算法結(jié)合在一起。我們從理論上和經(jīng)驗(yàn)上驗(yàn)證了提出的算法的良好收斂性。
實(shí)驗(yàn)結(jié)果表明,在不改變網(wǎng)絡(luò)架構(gòu)的情況下,在各種數(shù)據(jù)集和現(xiàn)有最出色的一階目標(biāo)檢測(cè)器上,AP 損失函數(shù)的性能相比不同類別的分類損失函數(shù)有著顯著提高。
10. Amodal Instance Segmentation through KINS Dataset
通過 KINS 數(shù)據(jù)集進(jìn)行透視實(shí)例分割
透視實(shí)例分割是實(shí)例分割的一個(gè)新方向,旨在模仿人類的能力對(duì)每個(gè)對(duì)象實(shí)例進(jìn)行分割包括其不可見被遮擋的部分。此任務(wù)需要推理對(duì)象的復(fù)雜結(jié)構(gòu)。盡管重要且具有未來感,但由于難以正確且一致地標(biāo)記不可見部分,這項(xiàng)任務(wù)缺乏大規(guī)模和詳細(xì)注釋的數(shù)據(jù),這為探索視覺識(shí)別的前沿創(chuàng)造了巨大的障礙。
在本文中,我們使用 8 個(gè)類別的更多實(shí)例像素級(jí)注釋來擴(kuò)充 KITTI,我們稱之為KITTI INStance 數(shù)據(jù)集(KINS)。我們提出了通過具有多分支編碼(MBC)的新多任務(wù)框架來推理不可見部分的網(wǎng)絡(luò)結(jié)構(gòu),該框架將各種識(shí)別級(jí)別的信息組合在一起。大量實(shí)驗(yàn)表明,我們的 MBC 有效地同時(shí)改善透視和非透視分割。KINS 數(shù)據(jù)集和我們提出的方法將公開發(fā)布。
11. Pyramidal Person Re-IDentification via Multi-Loss Dynamic Training
基于多損失動(dòng)態(tài)訓(xùn)練策略的金字塔式行人重識(shí)別
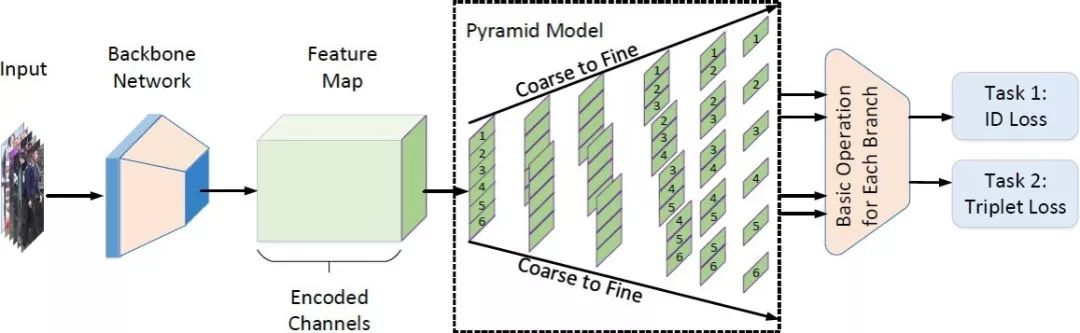
大多數(shù)已提出的行人重識(shí)別方法高度依賴于精準(zhǔn)的人體檢測(cè)以保證目標(biāo)間的相互對(duì)齊。然而在復(fù)雜的實(shí)際場(chǎng)景中,現(xiàn)有模型尚難以保證檢測(cè)的精準(zhǔn)性,不可避免地影響了行人重識(shí)別的性能。
在本文中,我們提出了一種新的由粗及細(xì)的金字塔模型,以放寬對(duì)檢測(cè)框的精度限制,金字塔模型整合了局部、全局以及中間的過渡信息,能夠在不同尺度下進(jìn)行有效匹配, 即便是在目標(biāo)對(duì)齊不佳情況下。
此外,為了學(xué)習(xí)具有判別性的身份表征,我們提出了一種動(dòng)態(tài)訓(xùn)練框架,以無縫地協(xié)調(diào)兩種損失函數(shù)并提取適當(dāng)?shù)男畔ⅰN覀冊(cè)谌齻€(gè)數(shù)據(jù)庫(kù)上達(dá)到了最好的效果。值得一提的,在最具挑戰(zhàn)性的 CUHK03 數(shù)據(jù)集上超過當(dāng)前最佳方法 9.5 個(gè)百分點(diǎn)。
12. Dynamic Scene Deblurring with Parameter Selective Sharing and Nested Skip Connections
基于選擇性參數(shù)共享和嵌套跳躍連接的圖像去模糊算法
動(dòng)態(tài)場(chǎng)景去模糊是一個(gè)具有挑戰(zhàn)的底層視覺問題因?yàn)槊總€(gè)像素的模糊是多因素共同導(dǎo)致,包括相機(jī)運(yùn)動(dòng)和物體運(yùn)動(dòng)。最近基于深度卷積網(wǎng)絡(luò)的方法在這個(gè)問題上取得了很大的提高。
相對(duì)于參數(shù)獨(dú)立策略和參數(shù)共享策略,我們分析了網(wǎng)絡(luò)參數(shù)的策略并提出了一種選擇性參數(shù)共享的方案。在每個(gè)尺度的子網(wǎng)絡(luò)內(nèi),我們?yōu)榉蔷€性變換的模塊提出了一種嵌套跳躍連接的結(jié)構(gòu)。此外,我們依照模糊數(shù)據(jù)生成的方法建立了一個(gè)更大的數(shù)據(jù)集并訓(xùn)練出效果更佳的去模糊網(wǎng)絡(luò)。
實(shí)驗(yàn)表明我們的選擇性參數(shù)共享,嵌套跳躍鏈接,和新數(shù)據(jù)集都可以提高效果,并達(dá)到最佳的去模糊效果。
13. Learning Shape-Aware Embedding for Scene Text Detection
一種基于實(shí)例分割以及嵌入特征的文本檢測(cè)方法
由于復(fù)雜多變的場(chǎng)景,自然場(chǎng)景下的任意形狀文本的檢測(cè)十分具有挑戰(zhàn)性,本文主要針對(duì)檢測(cè)任意形狀的文本提出了解決方案。
具體地,我們將文本檢測(cè)視作一個(gè)實(shí)例分割問題并且提出了一個(gè)基于分割的框架,該框架使用相互獨(dú)立的連通域來表示不同的文本實(shí)例。為了區(qū)分不同文本實(shí)例,我們的方法將圖片像素映射至嵌入特征空間當(dāng)中,屬于同一文本實(shí)例的像素在嵌入特征空間中會(huì)更加接近彼此,反之屬于不同文本實(shí)例的像素將會(huì)遠(yuǎn)離彼此。
除此之外,我們提出的Shape-Aware 損失可以使得模型能夠自適應(yīng)地去根據(jù)文本實(shí)例復(fù)雜多樣的長(zhǎng)寬比以及實(shí)例間的狹小縫隙來調(diào)整訓(xùn)練,同時(shí)加以我們提出的全新后處理算法,我們的方法能夠產(chǎn)生精準(zhǔn)的預(yù)測(cè)。我們的實(shí)驗(yàn)結(jié)果在三個(gè)具有挑戰(zhàn)性的數(shù)據(jù)集上(ICDAR15、MSRA-TD500 以及 CTW1500)驗(yàn) 證了我們工作的有效性。
14. PointWeb: Enhancing Local Neighborhood Features for Point Cloud Processing
PointWeb: 通過局部近鄰特征增強(qiáng)點(diǎn)云處理
本文提出一種新的在局部近鄰點(diǎn)云中提取上下文特征的方法:PointWeb。與之前的方法不同,為了明確每個(gè)基于局部區(qū)域特性的點(diǎn)特征,我們密集地連接在局部近鄰里的所有點(diǎn), 這樣可以更好地表征該區(qū)域。
我們提出了“自適應(yīng)特征調(diào)整”模塊(AFA),計(jì)算兩點(diǎn)之間的相互作用。對(duì)于每個(gè)局部區(qū)域,通過特征差分圖計(jì)算點(diǎn)對(duì)之間對(duì)應(yīng)每個(gè)元素影響程度的“影響圖”。根據(jù)自適應(yīng)學(xué)習(xí)到的影響因子,每個(gè)特征都會(huì)被相同區(qū)域內(nèi)的其他特征“推開”或“拉近”。調(diào)整過的特征圖更好地編碼區(qū)域信息,類似點(diǎn)云分割和分類的點(diǎn)云識(shí)別任務(wù),將從中受益。
實(shí)驗(yàn)結(jié)果表明我們的模型在語(yǔ)義分割和形狀分類數(shù)據(jù)集上,超出當(dāng)前最優(yōu)的算法。代碼和訓(xùn)練好的模型將同論文一起發(fā)布。
15. Associatively Segmenting Instances and Semantics in Point Clouds
聯(lián)合分割點(diǎn)云中的實(shí)例和語(yǔ)義
一個(gè) 3D 點(diǎn)云精細(xì)和直觀的描述了一個(gè)真實(shí)場(chǎng)景。但是迄今為止怎樣在這樣一個(gè)信息豐富的三維場(chǎng)景分割多樣化的元素,仍然很少得到討論。
在本文中,我們首先引入一個(gè)簡(jiǎn)單且靈活的框架來同時(shí)分割點(diǎn)云中的實(shí)例和語(yǔ)義。進(jìn)一步地,我們提出兩種方法讓兩個(gè)任務(wù)從彼此中受益,得到雙贏的性能提升。具體來說,我們通過學(xué)習(xí)富有語(yǔ)義感知的實(shí)例嵌入向量來使實(shí)例分割受益于語(yǔ)義分割。同時(shí),將屬于同一個(gè)實(shí)例的點(diǎn)的語(yǔ)義特征融合在一起,從而更準(zhǔn)確地對(duì)每個(gè)點(diǎn)進(jìn)行語(yǔ)義預(yù)測(cè)。我們的方法大幅超過目前最先進(jìn)的 3D 實(shí)例分割方法,在 3D 語(yǔ)義分割上也有顯著提升。
代碼和模型已經(jīng)開源:https://github.com/WXinlong/ASIS.
16. Cyclic Guidance for Weakly Supervised Joint Detection and Segmentation
基于循環(huán)指導(dǎo)的弱監(jiān)督聯(lián)合檢測(cè)和分割
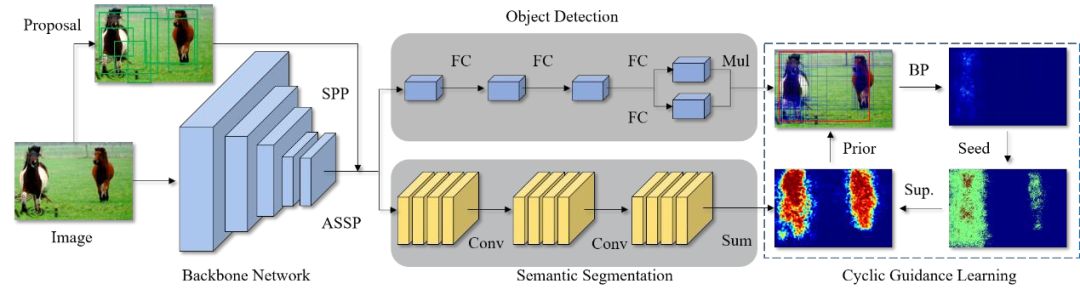
本文由騰訊優(yōu)圖實(shí)驗(yàn)室與廈門大學(xué)紀(jì)榮嶸教授團(tuán)隊(duì)主導(dǎo)完成。
我們首次提出使用多任務(wù)學(xué)習(xí)機(jī)制聯(lián)合弱監(jiān)督檢測(cè)和分割任務(wù),并基于兩個(gè)任務(wù)各自的互補(bǔ)失敗模式來改進(jìn)對(duì)方。這種交叉任務(wù)的增強(qiáng)使得兩個(gè)任務(wù)更能逃離局部最小值。
我們的方法 WS-JDS 有兩個(gè)分支并共享同一個(gè)骨干模型,分別對(duì)應(yīng)兩個(gè)任務(wù)。在學(xué)習(xí)過程中,我們提出循環(huán)指導(dǎo)范式和特地的損失函數(shù)來改進(jìn)雙方。實(shí)驗(yàn)結(jié)果表明該算法取得了的性能提升。
17. ROI Pooled Correlation Filters for Visual Tracking
基于感興趣區(qū)域池化的相關(guān)濾波跟蹤研究
基于 ROI 的池化算法在樣本被提取的感興趣區(qū)域進(jìn)行池化操作,并已經(jīng)在目標(biāo)檢測(cè)等領(lǐng)域取得了較大的成功。該池化算法可以較好的壓縮模型的尺寸,并且保留原有模型的定位精度,因此非常適合視覺跟蹤領(lǐng)域。盡管基于 ROI 的池化操作已經(jīng)被不同領(lǐng)域證明了其有效性,其在相關(guān)濾波領(lǐng)域仍然沒有得到很好的應(yīng)用。
基于此,本文提出了新穎的具有ROI 池化功能的相關(guān)濾波算法進(jìn)行魯棒的目標(biāo)跟蹤。通過嚴(yán)謹(jǐn)?shù)臄?shù)學(xué)推導(dǎo),我們證明了相關(guān)濾波中的 ROI 池化可以通過在學(xué)習(xí)到的濾波器上引入附加的約束來等效實(shí)現(xiàn),這樣就使得我們可以在不必明確提取出訓(xùn)練樣本的情況下完成池化操作。我們提出了一個(gè)高效的相關(guān)濾波算法,并給出了基于傅立葉的目標(biāo)函數(shù)求解算法。
我們?cè)?OTB-2013、OTB-2015 及 VOT-2017 上對(duì)所提出的算法進(jìn)行測(cè)試,大量的實(shí)驗(yàn)結(jié)果證明了本文所提出算法的有效性。
18. Exploiting Kernel Sparsity and Entropy for Interpretable CNN Compression
基于卷積核稀疏性與密度熵的神經(jīng)網(wǎng)絡(luò)壓縮方法
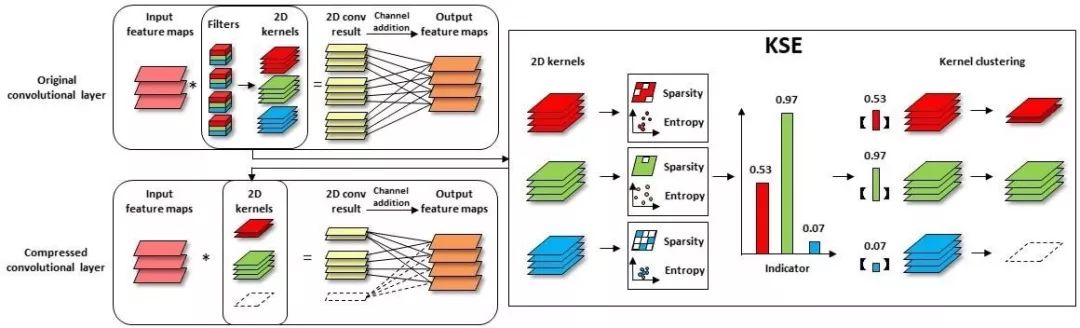
本文由騰訊優(yōu)圖實(shí)驗(yàn)室與廈門大學(xué)紀(jì)榮嶸教授團(tuán)隊(duì)主導(dǎo)完成。
我們從神經(jīng)網(wǎng)絡(luò)的解釋性角度出發(fā),分析卷積神經(jīng)網(wǎng)絡(luò)特征圖的冗余性問題,發(fā)現(xiàn)特征圖的重要性取決于它的稀疏性和信息豐富度。但直接計(jì)算特征圖的稀疏性與信息豐富度,需要巨大計(jì)算開銷。
為克服此問題,我們建立了特征圖和其對(duì)應(yīng)二維卷積核之間的聯(lián)系,通過卷積核的稀疏性和密度熵來表征對(duì)應(yīng)特征圖的重要程度,并得到判定特征圖重要性的得分函數(shù)。在此基礎(chǔ)上,我們采用較為細(xì)粒度壓縮的卷積核聚類代替?zhèn)鹘y(tǒng)的剪枝方式壓縮模型。大量的實(shí)驗(yàn)結(jié)果表明,我們所提出的基于卷積核稀疏性與密度熵的壓縮方法可以達(dá)到更高的壓縮率和精度。
19. MMFace: A Multi-Metric Regression Network for Unconstrained Face Reconstruction
MMFace: 用于無約束三維人臉重建的多度量回歸網(wǎng)絡(luò)
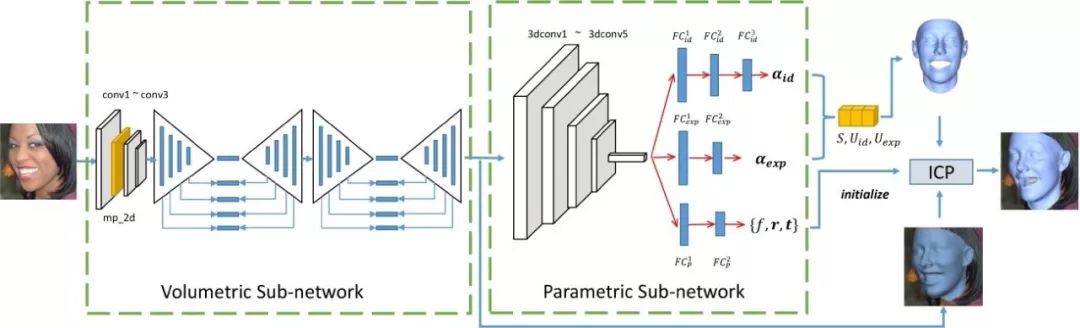
本文提出了一個(gè)用于進(jìn)行無約束三維人臉重建的多度量回歸網(wǎng)絡(luò)。
其核心思想是利用一個(gè)體素回歸子網(wǎng)絡(luò)從輸入圖像生成一個(gè)人臉幾何結(jié)構(gòu)的中間表達(dá),再?gòu)脑撝虚g表達(dá)回歸出對(duì)應(yīng)的三維人臉形變模型參數(shù)。我們從包括人臉身份、表情、頭部姿態(tài),以及體素等多個(gè)度量對(duì)回歸結(jié)果進(jìn)行了約束,使得我們的算法在夸張的表情,大頭部姿態(tài)、局部遮擋、復(fù)雜光照環(huán)境都有很好的魯棒性。
相比于目前的主流算法,我們的方法在公開的三維人臉數(shù)據(jù)集LS3D-W 和 Florence 上都得到了顯著的提升。此外,我們的方法還直接應(yīng)用到對(duì)視頻序列的處理。
20. Towards Optimal Structured CNN Pruning via Generative Adversarial Learning
基于生成對(duì)抗學(xué)習(xí)的最優(yōu)結(jié)構(gòu)化卷積神經(jīng)網(wǎng)絡(luò)剪枝方法
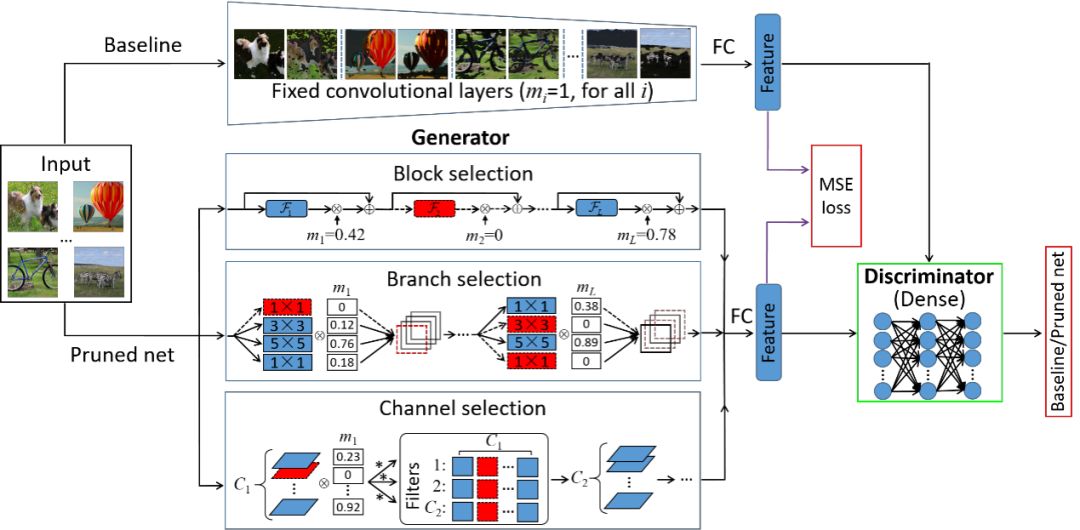
本文由騰訊優(yōu)圖實(shí)驗(yàn)室與廈門大學(xué)紀(jì)榮嶸教授團(tuán)隊(duì)主導(dǎo)完成。
我們提出了一種基于生成對(duì)抗學(xué)習(xí)的最優(yōu)結(jié)構(gòu)化網(wǎng)絡(luò)剪枝方法,利用無監(jiān)督端對(duì)端訓(xùn)練剪枝網(wǎng)絡(luò)中冗余的異質(zhì)結(jié)構(gòu),有效解決了傳統(tǒng)結(jié)構(gòu)化剪枝方法存在剪枝效率低、缺乏松弛性、強(qiáng)標(biāo)簽依賴等問題。該方法對(duì)每個(gè)模型結(jié)構(gòu)引入了軟掩碼,并對(duì)其加入稀疏限制,使其表征每個(gè)結(jié)構(gòu)的冗余性。
為了更好學(xué)習(xí)模型參數(shù)和掩碼,我們利用無類別標(biāo)簽生成對(duì)抗學(xué)習(xí)框架,構(gòu)建新的結(jié)構(gòu)化剪枝目標(biāo)函數(shù),并利用快速的迭代閾值收縮算法解決該優(yōu)化問題,穩(wěn)定移除冗余結(jié)構(gòu)。通過大量的實(shí)驗(yàn)結(jié)果表明,相比于目前最先進(jìn)的結(jié)構(gòu)化剪枝方法,我們所提出的剪枝方法可以獲得更好的性能。
21. Semantic Component Decomposition for Face Attribute Manipulation
基于語(yǔ)義成分分解的人臉屬性編輯
最近,基于深度神經(jīng)網(wǎng)絡(luò)的方法已被廣泛研究用于面部屬性編輯。然而,仍然存在兩個(gè)主要問題,即視覺質(zhì)量不佳以及結(jié)果難以由用戶控制。這限制了現(xiàn)有方法的適用性,因?yàn)橛脩艨赡軐?duì)不同的面部屬性具有不同的編輯偏好。
在本文中,我們通過提出一個(gè)基于語(yǔ)義組件的模型來解決這些問題。該模型將面部屬性分解為多個(gè)語(yǔ)義成分,每個(gè)語(yǔ)義成分對(duì)應(yīng)于特定的面部區(qū)域。這不僅允許用戶基于他們的偏好來控制不同部分的編輯強(qiáng)度,而且還使得有效去除不想要的編輯效果。此外,每個(gè)語(yǔ)義組件由兩個(gè)基本元素組成,它們分別確定編輯效果和編輯區(qū)域。此屬性允許我們進(jìn)行更細(xì)粒度的交互式控制。實(shí)驗(yàn)表明,我們的模型不僅可以產(chǎn)生高質(zhì)量的結(jié)果,還可以實(shí)現(xiàn)有效的用戶交互。
22. Memory-Attended Recurrent Network for Video Captioning
一種針對(duì)視頻描述的基于記憶機(jī)制的循環(huán)神經(jīng)網(wǎng)絡(luò)
傳統(tǒng)的視頻描述生成的模型遵循編碼-解碼 (encoder-decoder) 的框架,對(duì)輸入的視頻先進(jìn)行視頻編碼,然后解碼生成相應(yīng)的視頻描述。這類方法的局限在于僅能關(guān)注到當(dāng)前正在處理的一段視頻。而在實(shí)際案例中,一個(gè)詞或者短語(yǔ)可以同時(shí)出現(xiàn)在不同但語(yǔ)義相似的視頻中,所以基于編碼-解碼的方法不能同時(shí)抓取一個(gè)詞在多個(gè)相關(guān)視頻中的上下文語(yǔ)義信息。
為了解決這個(gè)局限性,我們提出了一種基于記憶機(jī)制的循環(huán)神經(jīng)網(wǎng)絡(luò)模型,設(shè)計(jì)了一種獨(dú)特的記憶結(jié)構(gòu)來抓取每個(gè)詞庫(kù)中的詞與其所有相關(guān)視頻中的對(duì)應(yīng)語(yǔ)義信息。因此,我們的模型可以對(duì)每個(gè)詞的語(yǔ)義有更全面和深入的理解,從而提高生成的視頻描述的質(zhì)量。另外,我們?cè)O(shè)計(jì)的記憶結(jié)構(gòu)能夠評(píng)估相鄰詞之間的連貫性。充足的實(shí)驗(yàn)證明我們的模型比現(xiàn)有的其他模型生成的視頻描述質(zhì)量更高。
23. Distilled Person Re-identification: Towards a More Scalable System
蒸餾的行人重識(shí)別:邁向更具可擴(kuò)展性的系統(tǒng)
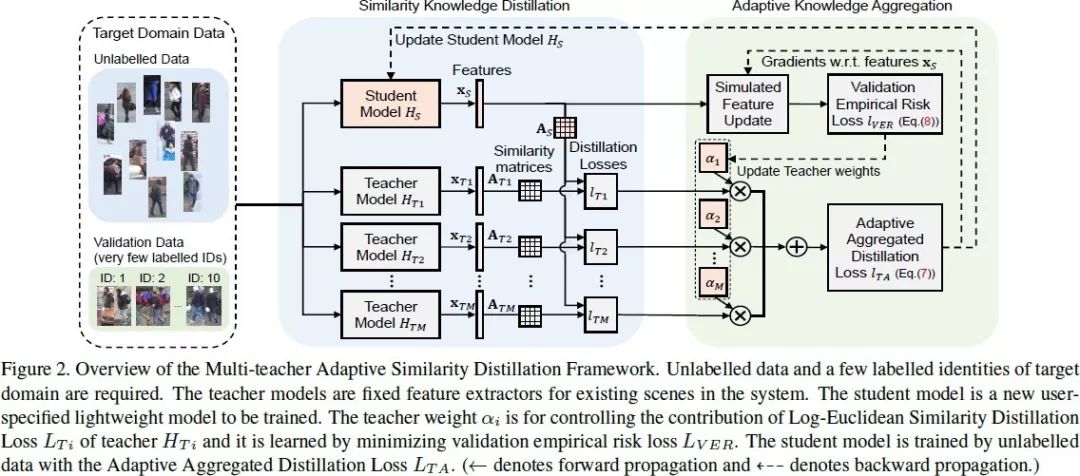
行人重識(shí)別(Re-ID),作為面向非交疊相機(jī)視角下的行人比對(duì)技術(shù),在具備豐富標(biāo)簽數(shù)據(jù)下有監(jiān)督學(xué)習(xí)領(lǐng)域的研究已取得了長(zhǎng)足的進(jìn)步。然而可擴(kuò)展性問題仍然是系統(tǒng)走向大規(guī)模應(yīng)用的瓶頸。
我們從三個(gè)方面考慮 Re-ID 的可擴(kuò)展性問題:(1)減少標(biāo)簽規(guī)模來降低標(biāo)注成本,(2)復(fù)用已有知識(shí)來降低遷移成本(3)使用輕量模型來降低預(yù)測(cè)成本。
為解決這些問題,我們提出了一種多教師自適應(yīng)的相似度蒸餾框架,僅需要少量有標(biāo)注的目標(biāo)域身份, 即可將多種教師模型中的知識(shí)遷移到訂制的輕量級(jí)學(xué)生模型,而無需利用源域數(shù)據(jù)。為有效選擇教師模型,完成知識(shí)遷移,我們提出了 Log-Euclidean 的相似度蒸餾損失函數(shù),并進(jìn)一步整合了 Adaptive Knowledge Aggregator。大量的實(shí)驗(yàn)評(píng)估結(jié)果論證了方法的可擴(kuò)展性,在性能上可與當(dāng)前最好的無監(jiān)督和半監(jiān)督 Re-ID 方法相媲美。
24. DSFD: Dual Shot Face Detector
雙分支人臉檢測(cè)器
本文由南京理工大學(xué)計(jì)算機(jī)科學(xué)與工程學(xué)院 PCALab 與騰訊優(yōu)圖實(shí)驗(yàn)室合作完成。
近年來,卷積神經(jīng)網(wǎng)絡(luò)在人臉檢測(cè)中取得了很大的成功。然而這些方法在處理人臉中多變的尺度,姿態(tài),遮擋,表情,光照等問題時(shí)依然比較困難。
本文提出了一種新的方法,分別處理了人臉檢測(cè)方向的三個(gè)關(guān)鍵點(diǎn),包括更好的特征學(xué)習(xí),漸進(jìn)式的損失函數(shù)設(shè)計(jì)以及基于錨點(diǎn)分配的數(shù)據(jù)擴(kuò)充。
首先,我們提出了一種特征增強(qiáng)單元,以增強(qiáng)特征能力的方式將單分支擴(kuò)展到雙分支結(jié)構(gòu)。其次,我們采用漸進(jìn)式的錨點(diǎn)損失函數(shù),通過給雙分支不同尺度的錨點(diǎn)集更有效地促進(jìn)特征學(xué)習(xí)。最后,我們使用了一種改進(jìn)的錨點(diǎn)匹配方法,為回歸器提供了更好的初始化數(shù)據(jù)。
由于上述技術(shù)都與雙分支的設(shè)計(jì)相關(guān),我們將本文方法命名為雙分支人臉檢測(cè)器。我們?cè)趦蓚€(gè)著名的人臉檢測(cè)數(shù)據(jù)集 WIDER FACE 和 FDDB 的 5 個(gè)評(píng)測(cè)維度上均刷新了當(dāng)時(shí)的世界紀(jì)錄,取得了 Top1 的人臉檢測(cè)結(jié)果。
25. 3D Motion Decomposition for RGBD Future Dynamic Scene Synthesis
基于 3D 運(yùn)動(dòng)分解合成 RGBD 未來動(dòng)態(tài)場(chǎng)景
視頻中未來時(shí)刻的幀,是由相機(jī)自身運(yùn)動(dòng)和場(chǎng)景中物體運(yùn)動(dòng)后的 3D 場(chǎng)景投影到 2D 形成的。因此,從根本上說,精確預(yù)測(cè)視頻未來的變化,需要理解場(chǎng)景的 3D 運(yùn)動(dòng)和幾何特性。
在這篇文章中,我們提出了通過3D 運(yùn)動(dòng)分解來實(shí)現(xiàn)的 RGBD 場(chǎng)景預(yù)測(cè)模型。我們首先預(yù)測(cè)相機(jī)運(yùn)動(dòng)和前景物體運(yùn)動(dòng),它們共同用來生成 3D 未來場(chǎng)景,然后投影到 2D 相機(jī)平面來合成未來的運(yùn)動(dòng)、RGB 圖像和深度圖。我們也可以把語(yǔ)義分割信息融入系統(tǒng),以預(yù)測(cè)未來時(shí)刻的語(yǔ)義圖。
我們?cè)?KITTI 和 Driving 上的結(jié)果說明,我們的方法超過了當(dāng)前最優(yōu)的預(yù)測(cè)RGBD 未來場(chǎng)景的方法
-
濾波器
+關(guān)注
關(guān)注
162文章
8136瀏覽量
182027 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103581 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5561瀏覽量
122793
原文標(biāo)題:騰訊優(yōu)圖25篇CVPR解讀:視覺對(duì)抗學(xué)習(xí)、視頻深度理解等
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
格靈深瞳六篇論文入選ICCV 2025
理想汽車八篇論文入選ICCV 2025
后摩智能四篇論文入選三大國(guó)際頂會(huì)
云知聲四篇論文入選自然語(yǔ)言處理頂會(huì)ACL 2025

老板必修課:如何用NotebookLM 在上下班路上吃透一篇科技論文?
人工智能視覺識(shí)別技術(shù)的應(yīng)用領(lǐng)域及場(chǎng)景
美報(bào)告:中國(guó)芯片研究論文全球領(lǐng)先
海伯森亮相VisionCon合肥視覺系統(tǒng)技術(shù)設(shè)計(jì)會(huì)議
后摩智能5篇論文入選國(guó)際頂會(huì)

直播報(bào)名丨AIGC技術(shù)在工業(yè)視覺領(lǐng)域的應(yīng)用

CMPA601C025F 6-12GHz頻段的25瓦GaN功率放大器

經(jīng)緯恒潤(rùn)功能安全AI 智能體論文成功入選EMNLP 2024!

NVIDIA視覺生成式AI的最新進(jìn)展
深視智能參編《2024智能檢測(cè)裝備產(chǎn)業(yè)發(fā)展研究報(bào)告:機(jī)器視覺篇》

地平線科研論文入選國(guó)際計(jì)算機(jī)視覺頂會(huì)ECCV 2024





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論