 前谷歌工程師:你的AI技能沒有那么值錢!
前谷歌工程師:你的AI技能沒有那么值錢!

2019年AI仍舊風口,別說大牛,剛畢業就年薪百萬的博士都有。但前谷歌工程師、研究深度學習的Ryszard Scopa認為,AI技能并沒你想的那么值錢,甚至正在貶值!數據,勝過更好的架構。
我們正處于人工智能的繁榮時期,機器學習專家的薪水高得驚人,投資者與人工智能初創企業會晤時,往往樂于敞開心扉,慷慨解囊。
這么做是正確的:因為這是每一代都會發生一次的變革性技術之一,AI這項技術將會繼續存在,改變我們的生活。
但這并不意味著讓你的人工智能創業獲得成功是一件容易的事。
我認為,任何人在試圖圍繞AI開展業務之前,都會遇到一些重要的陷阱。
你的 AI 技能正在貶值
2015 年我還在 Google 工作,那會兒就開始鼓搗 DistBelief (后來改名為 TensorFlow)。這玩意兒那時候實在太槽糕了,寫起來非常笨拙,主要的抽象還不符合你的預期。
要想讓它在 Google 所構建的系統之外發揮作用?
那真是一個白日夢。
兒子與我,使用藝術風格遷移進行圖像處理,這項技術激發了我對深度學習的興趣
2016 年底,我正在進行一個概念證明的研究,就是在組織病理學圖像中檢測出乳腺癌。我想使用遷移學習:采用 Inception,這是 Google 當時最好的圖像分類架構,然后使用我的癌癥數據重新進行訓練。我使用了 Google 提供的經過預訓練的初始權重,只不過更改了頂層以便能夠匹配我所做的工作。我在 TensorFlow 中,經過長時間的反復實驗后,終于弄明白了如何操縱不同的層,并使其大部分發揮作用。這些都需要很大的毅力去閱讀 TensorFlow 的資料,但至少我不必太過擔心依賴關系,因為 TensorFlow 準備好了 Docker 鏡像,真是太貼心了!
在 2018 年初,由于缺乏復雜性,上述任務并不適合作為實習生的第一個項目。多虧了 Keras(TensorFlow 之上的一個框架),你只需幾行 Python 代碼就可以完成,而且不需要深入理解你在做什么。但有一個痛點,就是超參數調優。如果你有深度學習模型,那你可以調整多個參數,如層的數量和大小等等。但如何得到最優配置并非易事,一些直觀的算法(如網格搜索)效果并不怎么樣。你做了很多實驗,感覺更像是一門藝術,而不是一門科學。
在我寫下這些文字的時候(2019 年初),Google 和 Amazon 已經提供了自動模型調優服務(Cloud AutoML、SageMaker),Microsoft 也正在計劃提供這一服務。我預測,手動模型調優將會像渡渡鳥一樣滅亡,而對于機器學習工程師來說,這也算是一種很好的解脫。
我希望你們能明白其中的規律:困難的事情終將變得容易,你可以在獲得更多的同時而無需深入理解。過去那些偉大的工程壯舉,現在聽上去卻有些蹩腳。因此,我們不應該期望現在的壯舉在未來會變現得更好。
這是一件好事,也是取得驚人進步的標志。我們將這一進步歸功于像 Google 這樣的公司,正是它們在這些工具上投入巨資,然后免費給人們提供這些工具。它們之所以這樣做,主要有兩個原因。
你被商品化之后的辦公室
第一個原因,這是對它們實際產品(即云基礎設施)的商品化補充的嘗試。在經濟學中,如果你傾向于一起購買兩種商品的話,那么購買的這兩種商品往往是互補的。舉一些例子:汽車與汽油、牛奶與谷物、培根和雞蛋等。如果其中一種商品降價了,那么另一種商品的需求往往就會增加。對云計算來說,它的補充就是運行在云端之上的軟件;而人工智能有一個特點,就是需要大量的計算資源。因此,盡可能降低開發成本是很有意義的。
Google 如此熱衷人工智能的第二個原因是,與 Amazon 和 Microsoft 相比,Google 擁有比較明顯的優勢:起步更早。畢竟是 Google 普及了深度學習的概念,因此,它們成功搶走了很多人才。它們在開發人工智能產品方面有著更多的經驗,這些使得它們在開發必要的工具和服務方面占據了優勢。
盡管取得了令人興奮的進展,但對于那些在人工智能技能上投入巨資的公司和個人來說,并不是什么好消息。現在它們為你提供了堅實的競爭優勢,因為培養一個稱職的機器學習工程師,需要耗費大量的時間來閱讀論文,以及打下扎實的數學基礎。
然而,隨著工具的改進,情況就不再如此:它將會變為更多的是閱讀教程而不是科學論文。
如果你沒有很快意識到自己的優勢,那么圖書館的一群實習生可能就會搶走你的飯碗。特別是當實習生有更好的數據,這就引出了我的下一個觀點……
更多的數據比花哨的 AI 架構更重要
假設你認識兩個人工智能初創公司的創始人:Alice 和 Bob。他們的公司籌集到的資金大致相當,而且在同一個市場上激烈競爭。Alice 在最好的工程師和擁有豐富的人工智能研究經驗的博士上進行投資,而 Bob 則雇傭了平庸但能干的工程師,并投資給她 (“Bob” 是 Robreta 的簡稱!)以獲得更好的數據。那么,你會在哪個公司身上下注呢?
我會在 Bob 身上下注。為什么呢?
因為,從本質上來說,機器學習的工作原理就是通過從數據集中提取信息并將其傳遞給模型權重中。在這一過程中,更好的模型會更有效(就時間和(或)綜合質量而言),但是假設某個足夠的基線(即模型實際上正在學習某些東西),擁有更好的數據將會勝過更好的架構。
為了說明這一點,讓我們做一個快速而粗略的測試。我創建了兩個簡單的卷積網絡,其中,一個是 “更好” 的網絡,一個是 “更差” 的網絡。那個 “更好” 模型的最后一層全連接層 (Dense Layer) 有 128 個神經元,而 “更差” 的模型則只有 64 個。我在 MNIST 數據集的不斷增大的子集上對這兩個模型進行訓練,并繪制出了模型在測試集上的正確率與訓練的樣本數的關系圖。
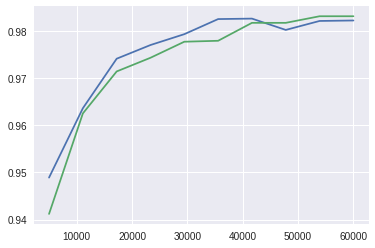
藍色曲線代表 “更好” 的模型,綠色曲線代表 “更差” 的模型
訓練數據集大小的積極作用是顯而易見的(至少在模型開始出現過擬合和正確率達到穩定之前是這樣)。代表 “更好” 模型的藍色曲線明顯優于代表 “更差” 模型的綠色曲線。然而,我想要指出的是,就正確率而言,在 4 萬個樣本上訓練的 “更差” 模型的表現,要比在 3 萬個樣本上訓練的 “更好” 模型更好!
在我這個小例子中,我們處理的是一個相對簡單的問題,并且我們還有一個全面的數據集。然而在現實生活中,我們可沒有這么奢侈的條件。在許多情況下,你永遠也無法避免圖表中增加數據集具有如此顯著效果的部分。
而且,Alice 的工程師們實際上不僅僅是與 Bob 的工程師競爭。由于人工智能社區的開放文化及其對知識共享的重視,他們還與 Google、Facebook、Microsoft 和全球數千所大學的研究人員競爭。
如果你的目標只是解決問題(而非對科學做出原創貢獻),那么采用目前文獻中描述的表現最好的架構,并根據你自己的數據對其進行重新訓練,這是一個經過實戰考驗的策略。如果現在沒有什么可用的東西的話,通常只需等待一兩個季度,直到有人提出解決方案。特別值得一提的是,你可以做一些事情,比如舉辦一場 Kaggle 競賽來激勵研究人員研究你的特定問題。
良好的工程設計始終很重要,但如果你做的是人工智能的話,那么數據就是形成競爭優勢的關鍵因素。然而,最重要的問題是,你是否能夠保持住自己的優勢。
保持 AI 競爭優勢是很困難的
憑借出色的數據集,Bob 成功地與 Alice 展開競爭,她做得很好:推出了自己的產品,市場份額穩步增長。她甚至可以開始聘用更好的工程師,因為坊間傳言她的公司是合適的選擇。
Chunk 想要趕進度,不過他比 Bob 有更多的錢。這一點在構建數據集時很重要。通過砸錢來加速一個工程項目是非常困難的。事實上,指派太多的新人反而有可能會阻礙項目的進展。然而,創建數據集卻是另外一種問題。通常來說,創建數據集需要大量的人工勞動,但你可以通過雇傭更多的勞動力來輕松擴展規模。或者可能某人擁有數據,那么你只需做的事就是向他支付許可費用。無論如何,有錢就是好辦事。
那么問題來了,為什么 Chunk 能夠比 Bob 籌到更多的資金呢?
當創始人發起新一輪融資時,他們會試圖平衡兩個可能存在沖突的目標。他們需要籌集到足夠的資金才能勝出。但是,他們又不能籌集太多的資金,因為這樣以來就會導致公司股權被過度稀釋。接受外部投資者就意味著出售公司的一部分。創始團隊必須在初創公司中保持足夠份額的股份,以免他們失去創業的動力(要知道,創業可是一項艱苦的工作!)
另一方面,投資者也希望他們的投資是投在有著巨大潛力的點子上,但他們必須控制風險。隨著感知風險的增加,他們會要求公司為他們支付的每一美元提供更多的股票份額。
當 Bob 籌集資金的時候,這是信心上的一次飛躍:人工智能能夠真正提升她的產品。不管她作為創始人的素質如何,也不管她的團隊有多優秀,毫無疑問,她一直在努力攻克的問題難以解決。而 Chunk 的情況非常不同,他知道這個問題是很容易解決的,因為 Bob 的產品就是活生生的證據!
Bob 應對這一挑戰的可能反應之一是發起另一輪新的挑戰。她應該處于有利地位,因為(目前)她在這場競賽中仍然保持領先。然而,情況可能會更復雜。如果 Chunk 可以通過戰略關系確保能夠對數據的訪問呢?遇到這種情況該怎么辦?例如,假設我們正在討論一家癌癥診斷初創公司,那么 Chunk 可以利用他在一家重要醫療機構的內部地位,與該機構達成私下交易,而 Bob 很可能無法做到這點。
你的產品應該是可防御的,最好是有一條很深的護城河
那么,你將如何為人工智能產品構建可維護的競爭優勢呢?
前段時間我有幸與 Microsoft 研究院的 Antonio Criminisi 交談。他的想法是,這個項目的秘密武器不應該只由人工智能組成。例如,他的 InnerEye 項目除了利用了人工智能外,還用到了經典(不是基于機器學習)的計算機視覺來分析放射圖像。
從某種程度上來說,這可能和你創辦人工智能初創公司的初衷不一樣。不過,將數據扔到模型并看到它工作的能力還是非常有吸引力的。然而,傳統的軟件組件更難重現,因為這種組件往往需要程序員思考算法,并利用一些難以獲得的領域知識才能構建。
人工智能最好像杠桿一樣使用
對業務進行分類的一種方法是,看它是直接增加價值,還是為某些其他價值來源提供杠桿作用。讓我們以一家電子商務公司為例。如果你創建了新的產品系列,那么你可以做到直接增加價值。以前什么都沒有,現在有了小商品,客戶就可以為它們支付費用。另一方面,建立新的分銷渠道相當于起到杠桿作用。比如,通過開始在 Amazon 上銷售你的小商品,你就可以將銷售量翻倍。削減成本也是一種杠桿,如果你與中國的小商品供應商達成更好的交易談判,那么,你的毛利率將會翻一番。
相比直接施力,杠桿更有可能推得更遠。但是,杠桿只有在與直接價值來源耦合時才會起作用。如果你將微小的數進行加倍,它就不會停止變小。如果你沒有小商品出售的話,那么,獲得新的分銷渠道就是浪費時間。
在這種情況下,我們應該如何看待人工智能呢?有很多公司試圖將人工智能作為它們的直接產品(如用于圖像識別的 API 等)。如果你是人工智能專家,那么這個想法可能非常誘人。然而,這實在是一個非常槽糕的主意。首先,你是在與 Google、Amazon 等公司競爭。其次,制造真正有用的通用人工智能產品是非常困難的。比如,我一直想使用 Google 的 Vision API。 不幸的是,我們還沒有遇到這樣的一個客戶:他的需求與我們的產品完全匹配。它要么是太多,要么是不夠,總是這樣。定制開發可比在圓孔中釘入方形樁釘要好多了。
綜上所述,我們可以得出一個結論:將人工智能視為杠桿是更好的選擇。你可以采用現有的、可行的商業模式,并通過人工智能來增強它。例如,如果你有個流程依賴于人類的認識勞動力,那么,將這一流程自動化可以提高你的毛利率。我能想到的一些例子是心電圖分析、工業檢查、衛星圖像分析等等。同樣令人興奮的是,因為人工智能留在后端,所以你有一些非 AI 選擇來形成并保持你的競爭優勢。
結論:真正重要的是比對手擁有更好的數據
人工智能是一種真正的革命性技術。但是,將你的初創公司建立在人工智能之上可是一件非常棘手的事情。你不應該僅僅依賴于你的人工智能技能,因為,它們會因更大的市場趨勢而貶值。
構建人工智能模型可能是一件非常有趣的事情,但真正重要的事情是擁有比競爭對手更好的數據。要知道,保持住競爭優勢是很難的事情,特別是如果遇到的是比你更有錢的競爭對手時,而你剛有了人工智能的點子,那么這種情況很可能會發生。
因此,你的目標應該是創建一個可擴展的數據收集過程,這個過程很難被競爭對手復制。人工智能非常適合顛覆依賴低資質人員認知工作的行業,因為它允許自動化這類工作。
-
谷歌
+關注
關注
27文章
6231瀏覽量
108134 -
AI
+關注
關注
88文章
35143瀏覽量
279818 -
人工智能
+關注
關注
1806文章
49018瀏覽量
249464
原文標題:前谷歌工程師:你的 AI 技能正在貶值!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄


電源工程師的核心技能樹體系
物聯網工程師為什么要學Linux?
一個優秀的射頻測試工程師需要具備哪些技能?


硬件工程師手冊(全套)
Allegro工程師能力升級建議 工程師技能如何升級進階



如何成為嵌入式開發工程師?







 工商網監
工商網監
評論