 如何采用處理器和FPGA設計機器學習的計算平臺
如何采用處理器和FPGA設計機器學習的計算平臺

對于開發人員而言,機器學習(ML)硬件和軟件的進步有望將這些復雜的方法帶入物聯網(IoT)邊緣設備。然而,隨著這一研究領域的發展,開發人員可以輕松地發現自己沉浸在這些技術背后的深層理論中,而不是專注于當前可用的解決方案,以幫助他們將基于ML的設計推向市場。
本文簡要回顧了ML的目標和能力,ML開發周期,以及基本完全連接神經網絡和卷積神經網絡(CNN)的體系結構。然后討論了支持主流ML應用程序的框架,庫和驅動程序。
最后展示了通用處理器和FPGA如何作為實現機器學習算法的硬件平臺。
ML簡介
人工智能(AI)的一個子集,ML涵蓋了廣泛的方法和算法。作為一種強大的數據分類技術或在數據流中尋找感興趣的模式,它迅速受到關注。已經出現了廣泛的算法來解決特定類型的問題。
例如,聚類技術和其他無監督學習方法可以揭示大型數據集中不同類別的數據。強化學習提供了能夠探索未知狀態并選擇替代解決方案的方法,目的是學習識別這些狀態并在將來適當地做出響應。最后,監督學習方法使用表示所需輸出的預備輸入數據來教授算法如何對新輸入數據進行分類。
監督學習方法通過使用精心準備的訓練集來獲得他們的名字,這些訓練集將輸入數據配對(稱為特征向量),具有預期輸出(稱為標簽),以訓練算法模型,以便將來對未標記的輸入數據模式進行分類。例如,開發人員可能有幾個特征向量,包括不同的采樣傳感器值集合,這些值都代表某些工業過程中的安全條件,以及其他特征向量及其自身的傳感器樣本都表示不安全的情況。
監督學習方法可以使用這些代表性特征向量及其已知的安全/不安全標簽來訓練算法,以基于新的傳感器值識別其他安全和不安全的條件。
神經網絡
有監督的學習方法,神經網絡算法已迅速獲得其準確分類數據的能力。基本神經網絡有三個階段(圖1)。第一個是輸入層,其包括輸入特征向量中的每個特征的輸入。第二個是隱藏的一些神經元層,它們以不同的方式轉換這些特征。第三層是輸出層,其將該變換的結果呈現為一組概率,輸入特征向量可以用訓練期間提供的標簽之一進行分類。
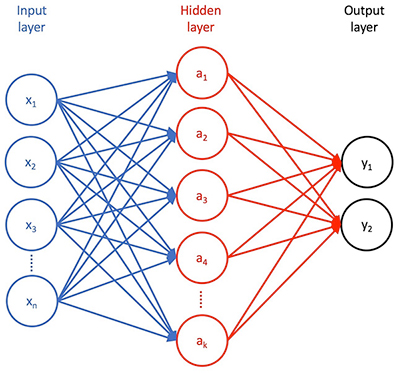
圖1:神經網絡包括輸入層,一個或多個隱藏轉換層,以及呈現該轉換結果的輸出層。 (圖像來源:Digi-Key Electronics)
此外,一層神經元與后續層神經元之間的每個連接都有一個相關的權重,有效地代表了該特定連接的相對強度。
在完全連接的神經網絡中,每個i輸入神經元呈現其特征值xi,通過與下一個隱藏層中的每個目標神經元aj相關聯的加權因子wij進行縮放。每個隱藏層神經元aj對加權輸入w1jx1 + w2jx2 + ... + wnjxn(和一些偏差值)求和,然后應用一些激活函數,該函數縮放或以其他方式減少呈現給附加到其輸出的神經元的求和結果。此過程通過其他隱藏層和最終輸出層重復,其中該減少的值表示輸入要素向量[x1,x2,... xn]可被分類為標簽y1或y2的概率(對于圖1所示的簡單網絡)訓練過程通過調整權重和偏差值(統稱為模型的參數)來改進模型以實現訓練集向量與其相關標簽之間的最佳匹配。通常以一組隨機模型參數開始,訓練算法通過模型重復傳遞訓練數據集。對于每個完整的傳遞或紀元,訓練算法試圖減少預測標簽和已知標簽之間的差異 - 在每個時期由某種類型的特定損失函數計算的差異。
表示為函數在模型參數中,損失函數描述了與這些參數相關聯的多維空間中的表面。因此,經過良好調整的訓練過程基本上可以找到從起點(初始隨機模型參數)到多維參數空間上最小點的最快路徑(圖2)。
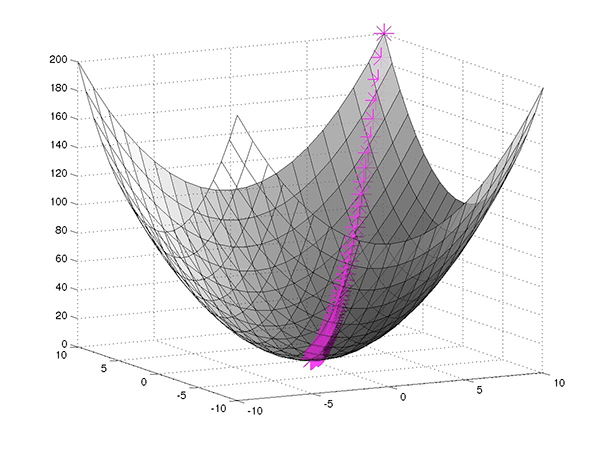
圖2:神經網絡訓練尋求找到最小化損失函數的參數集(預期輸出和計算輸出之間的差異),使用梯度下降找到最小損失點的最快路徑。 (圖片來源:Mathworks)
在任何曲線上,從任何特定點到最小點的變化方向和速率當然由曲線上該點的切線斜率來描述,即其導數(或其中的偏導數)多維參數空間)。例如,對于在多維表面上具有值w和正偏導數p的某個假設參數,可以通過設置w = w-αp將參數移向最小值,其中α是一個術語,稱為學習率,用于幫助避免p太大以至于wp單獨跳過最小值而永不收斂的情況。
神經網絡訓練算法使用這種技術,稱為梯度下降或其變化,在計算后修改模型參數每個時代的損失函數。通過計算每個時期的最小損失的最短路徑,訓練算法最終可以找到傳遞最小損失的特定模型參數,或者足夠接近最小損失的模型參數,通過附加歷元的迭代將對結果幾乎沒有增加。/p>
復雜神經網絡
這種通用訓練過程在概念上適用于任何神經網絡,無論它是否類似于圖1所示的基本架構,在深度神經網絡(DNN)設計中增加了許多隱藏層,或使用完全不同的架構。開發人員可以找到任意數量的神經網絡架構,旨在解決特定的應用問題。其中,CNN架構已成為圖像識別的首選方法。
CNN設計用于需要高級識別圖像,手寫和其他復雜表示的應用,CNN使用管道方法學習重要特征在所提供的輸入中,并在其輸出處對這些特征進行分類(圖3)。
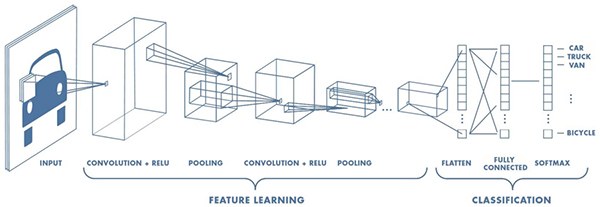
圖3:CNN結合了一個功能學習階段,包括通過多個感受域過濾圖像的轉換,以及將這些結果重新組合成分類階段的分類階段。最終輸出層。 (圖像來源:Mathworks)
CNN以用于預處理圖像的輸入層開始。特征學習階段通常包括多層卷積,整流線性單元(ReLU)和池化功能,這些功能組合起來識別圖像的邊緣,顏色分組和其他獨特元素等特征。
執行在這種識別中,卷積層用多組神經元檢查圖像的輸入體積,稱為深度列,它們都連接到輸入圖像中的相同局部區域(它們的感受野)并接收其所有顏色通道。為了產生卷積,這組神經元(稱為濾波器或內核)將其感知場滑過圖像。在此過程中,內核計算前面描述的相同類型的輸入加權和。類似地,ReLU層用作前面描述的激活功能。池化層提供了一種專門的功能,可以有效地對從連接的內核接收的結果進行采樣。
CNN的最終分類階段重新連接所有單個內核輸出,并生成輸出,指示輸入圖像對應于在標記圖像訓練期間使用的特定標簽之一的概率。
開發人員可以找到具體的CNN架構的例子,從原始的LeNet,AlexNet和CIFAR ConvNet等相對較淺的模型,到22層模型GoogleNet架構等大型模型,以及每年在ImageNet大規模視覺中常用的數百層的非常深的模型認可比賽。諸如此類的DNN能夠進行顯著的非線性變換,以提取特征并以非常低的錯誤率對復雜圖像進行分類。
然而,直到最近,實施CNN的能力需要深入了解概率,統計和線性代數的基礎數學至少是。今天,開發人員可以利用基于軟件堆棧的復雜機器學習框架,顯著簡化包括CNN在內的復雜神經網絡架構的實現。
ML框架
機器學習框架,如MATLAB for Machine學習,Microsite的認知工具包,Google的TensorFlow,三星的Veles以及許多其他人提供設計,訓練和部署神經網絡模型所需的資源。在這些框架內,開發人員使用機器學習庫(如Keras或TensorFlow Estimators)來描述神經網絡層并實現訓練算法。反過來,這些庫使用優化的數學庫(如NumPy)來處理用于梯度下降和損失函數計算的復雜矩陣運算。對于這些操作所需的特定數值計算,這些庫構建在較低級別的庫上,例如Basic Linear Algebra Subroutines(BLAS)。為了加速訓練,這些環境通常嚴重依賴于具有相應GPU啟用庫的一個或多個圖形處理單元(GPU),例如NumPy兼容CuPy,BLAS兼容cuBLAS或NVIDIA自己的CUDA深度神經網絡庫(cuDNN)等。最后,這些不同的庫利用甚至更低級別的驅動程序,包括跨平臺OpenCL或NVIDIA CUDA,用于支持GPU的環境。
這種對數字數學處理優化庫的深度依賴反映了矩陣操作在神經網絡發展。特別地,一般操作,一般矩陣乘法(gemm),主導神經網絡中使用的計算類型,特別是CNN(圖4)。
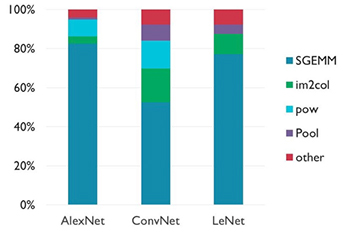
圖4:雖然其影響的具體情況因CNN架構的不同而有所不同,但單精度浮動通用矩陣乘法(SGEMM)操作主導了培訓和推理。 (圖像來源:Arm ?)
鑒于矩陣運算的優勢,底層硬件的功能在確定神經網絡的訓練時間和推理中起著核心作用完成模型的時間。實際上,這意味著如果目標應用程序具有適度的性能要求,即使是相對低級別的通用系統(如Raspberry Pi)也可用于CNN培訓和推理。事實上,任何圍繞通用處理器設計的系統,如Arm Cortex ? MCU都可以作為ML平臺。
為了幫助開發人員在其Cortex MCU上部署神經網絡,Arm提供針對Arm Cortex-A系列MCU優化的專用計算庫,例如Texas Instruments Sitara MCU,NXP i.MX6 MCU和NXP i.MX8 MCU。對于基于Arm Cortex-M的MCU,Arm提供CMSIS-NN,這是針對Arm Cortex-M系列器件的Cortex微控制器軟件接口標準(CMSIS)中的神經網絡特定庫(圖5)。 CMSIS-NN庫設計為Arm Cortex微控制器軟件接口標準(CMSIS)的附加軟件包,增強了CMSIS-CORE,優化了卷積層,池,激活(例如:ReLU)以及其他常用功能。神經網絡模型。
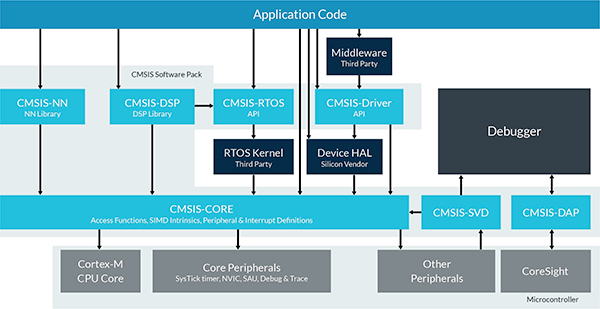
圖5:CMSIS-NN庫通過神經網絡模型中常用的優化函數增強了CMSIS-CORE。 (圖像源:Arm)
例如,使用CMSIS-NN庫,開發人員可以在STMicroelectronics Mbed兼容的NUCLEO-F746ZG開發板上實現模型,該開發板使用基于Arm Cortex-M7的STM32F746ZG MCU 。
專業的AI芯片最終將為神經網絡和其他機器學習算法提供顯著的性能增強,但是這些芯片仍然處于規劃階段,同時算法也在鞏固。
需要增加的開發人員現在,性能可以轉向現成的FPGA,例如Intel Arria 10 GX,Lattice Semiconductor iCE40 UltraPlus或Lattice ECP5。這類FPGA集成了能夠加速GEMM操作的DSP模塊,并嵌入了存儲器模塊以減少存儲器訪問瓶頸,從而限制了這些計算密集型操作的性能。
Lattice Semiconductor使基于FPGA的模型邁出了一步通過提供機器學習FPGA IP和神經網絡編譯器,進一步提高SensAI堆棧。使用SensAI,開發人員可以在可用的Lattice FPGA開發平臺上實現高級神經網絡,包括Lattice ICE40UP5K-MDP-EVN移動開發板和Lattice LF-EVDK1-EVN嵌入式視覺開發套件。
雖然速度更快硬件平臺通常意味著更快的訓練和推理時間,目標平臺中有限的資源通常需要仔細平衡推理時間,延遲,內存占用和功耗。機器學習專家通過對每個神經網絡架構的進一步改進來響應這些要求。諸如模型參數和激活函數的減少比特量化的方法導致早期方法的存儲器占用減少3倍至4倍。進一步的改進繼續減少模型大小和復雜性,以實現更快的計算,從而縮短推理時間,降低延遲并降低功耗。
創新模型架構,培訓方法和專用硬件的結合繼續使先進的機器學習方法更接近任何開發人員的優勢。
結論
機器學習正在成為用戶識別,對象識別以及智能產品中所需的許多其他功能的強大解決方案。盡管機器學習技術曾被人工智能專家限制使用,但機器學習框架的廣泛應用為主流開發人員的廣泛應用打開了大門。
即使機器學習能力繼續快速發展,開發人員也可以已經開始將這些框架與通用處理器和FPGA結合使用,以便在廣泛的應用中使用機器學習。
-
處理器
+關注
關注
68文章
19882瀏覽量
234964 -
FPGA
+關注
關注
1645文章
22034瀏覽量
618000 -
神經網絡
+關注
關注
42文章
4814瀏覽量
103508 -
機器學習
+關注
關注
66文章
8501瀏覽量
134550
發布評論請先 登錄
采用Xilinx FPGA加速機器學習應用
Project Trillium-提供業界最具擴展性、應用范圍最廣的機器學習計算平臺
采用專用處理器實現電機驅動方案
如何正確使用處理器參數?
利用處理器FPGA與液晶顯示模塊的圖形顯示的編程技術
DSP處理器與通用處理器的比較
采用FPGA處理器的刀片管理控制器原理及設計
什么是通用處理器
流水線操作,應用處理器,應用處理器的結構和原理是什么?
應用處理器之爭如火如荼
寒武紀科技將發布深度學習專用處理器

服務器處理器與家用處理器有什么區別
應用處理器芯片行業科普

一文讀懂i.MX 91應用處理器:為邊緣平臺提供安全、高效的Linux計算能力!






 工商網監
工商網監
評論