") 一種基于點(diǎn)云的Voxel(三維體素)特征的深度學(xué)習(xí)方法
一種基于點(diǎn)云的Voxel(三維體素)特征的深度學(xué)習(xí)方法

蘭州大學(xué)在讀碩士研究生,主要研究方向無(wú)人駕駛,深度學(xué)習(xí);蘭大未來(lái)計(jì)算研究院無(wú)人車團(tuán)隊(duì)負(fù)責(zé)人,自動(dòng)駕駛全棧工程師。
之前我們提到使用SqueezeSeg進(jìn)行了三維點(diǎn)云的分割,由于采用的是SqueezeNet作為特征提取網(wǎng)絡(luò),該方法的處理速度相當(dāng)迅速(在單GPU加速的情況下可達(dá)到100FPS以上的效率),然而,該方法存在如下的問(wèn)題:
第一,雖然采用了CRF改進(jìn)邊界模糊的問(wèn)題,但是從實(shí)踐結(jié)果來(lái)看,其分割的精度仍然偏低;
第二,該模型需要大量的訓(xùn)練集,而語(yǔ)義分割數(shù)據(jù)集標(biāo)注困難,很難獲得大規(guī)模的數(shù)據(jù)集。當(dāng)然,作者在其后的文章:SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud 中給出了改進(jìn)的方案,我將在后面的文章中繼續(xù)解讀。需要注意的是,在無(wú)人車環(huán)境感知問(wèn)題中,很多情況下并不需要對(duì)目標(biāo)進(jìn)行精確的語(yǔ)義分割,只需將目標(biāo)以一個(gè)三維的Bounding Box準(zhǔn)確框出即可(即Detection)。
本文介紹一種基于點(diǎn)云的Voxel(三維體素)特征的深度學(xué)習(xí)方法,實(shí)現(xiàn)對(duì)點(diǎn)云中目標(biāo)的準(zhǔn)確檢測(cè),并提供一個(gè)簡(jiǎn)單的ROS實(shí)現(xiàn),供大家參考。
VoxelNet結(jié)構(gòu)
VoxelNet是一個(gè)端到端的點(diǎn)云目標(biāo)檢測(cè)網(wǎng)絡(luò),和圖像視覺中的深度學(xué)習(xí)方法一樣,其不需要人為設(shè)計(jì)的目標(biāo)特征,通過(guò)大量的訓(xùn)練數(shù)據(jù)集,即可學(xué)習(xí)到對(duì)應(yīng)的目標(biāo)的特征,從而檢測(cè)出點(diǎn)云中的目標(biāo),如下:
VoxelNet的網(wǎng)絡(luò)結(jié)構(gòu)主要包含三個(gè)功能模塊:
(1)特征學(xué)習(xí)層;
(2)卷積中間層;
(3) 區(qū)域提出網(wǎng)絡(luò)( Region Proposal Network,RPN)。
特征學(xué)習(xí)網(wǎng)絡(luò)
特征學(xué)習(xí)網(wǎng)絡(luò)的結(jié)構(gòu)如下圖所示,包括體素分塊(Voxel Partition),點(diǎn)云分組(Grouping),隨機(jī)采樣(Random Sampling),多層的體素特征編碼(Stacked Voxel Feature Encoding),稀疏張量表示(Sparse Tensor Representation)等步驟,具體來(lái)說(shuō):
體素分塊
這是點(diǎn)云操作里最常見的處理,對(duì)于輸入點(diǎn)云,使用相同尺寸的立方體對(duì)其進(jìn)行劃分,我們使用一個(gè)深度、高度和寬度分別為(D,H,W)的大立方體表示輸入點(diǎn)云,每個(gè)體素的深高寬為(vD,vH,vW) ,則整個(gè)數(shù)據(jù)的三維體素化的結(jié)果在各個(gè)坐標(biāo)上生成的體素格(voxel grid)的個(gè)數(shù)為: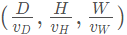
點(diǎn)云分組
將點(diǎn)云按照上一步分出來(lái)的體素格進(jìn)行分組,如上圖所示。
隨機(jī)采樣
很顯然,按照這種方法分組出來(lái)的單元會(huì)存在有些體素格點(diǎn)很多,有些格子點(diǎn)很少的情況,64線的激光雷達(dá)一次掃描包含差不多10萬(wàn)個(gè)點(diǎn),全部處理需要的計(jì)算力和內(nèi)存都很高,而且高密度的點(diǎn)勢(shì)必會(huì)給神經(jīng)網(wǎng)絡(luò)的計(jì)算結(jié)果帶來(lái)偏差。所以,該方法在這里插入了一層隨機(jī)采樣,對(duì)于每一個(gè)體素格,隨機(jī)采樣固定數(shù)目的點(diǎn),T 。
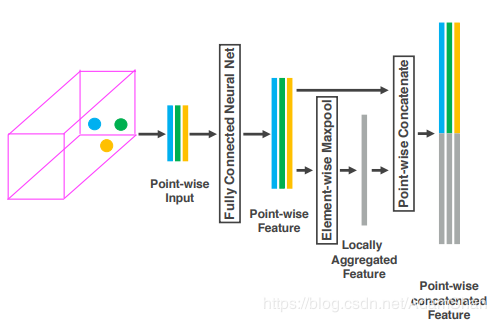
多個(gè)體素特征編碼(Voxel Feature Encoding,VFE)層
之后是多個(gè)體素特征編碼層,簡(jiǎn)稱為VFE層,這是特征學(xué)習(xí)的主要網(wǎng)絡(luò)結(jié)構(gòu),以第一個(gè)VFE層為例說(shuō)明:
對(duì)于輸入:
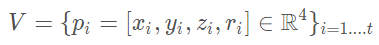
是一個(gè)體素格內(nèi)隨機(jī)采樣的點(diǎn)集,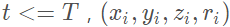 分別點(diǎn)的XYZ坐標(biāo)以及激光束的反射強(qiáng)度(即intensity),我們首先計(jì)算體素內(nèi)所有點(diǎn)的平均值 (vx,vy,vz)?作為體素格的形心(類似于Voxel Grid Filter),那么我們就可以將體素格內(nèi)所有點(diǎn)的特征數(shù)量擴(kuò)充為如下形式:
分別點(diǎn)的XYZ坐標(biāo)以及激光束的反射強(qiáng)度(即intensity),我們首先計(jì)算體素內(nèi)所有點(diǎn)的平均值 (vx,vy,vz)?作為體素格的形心(類似于Voxel Grid Filter),那么我們就可以將體素格內(nèi)所有點(diǎn)的特征數(shù)量擴(kuò)充為如下形式:
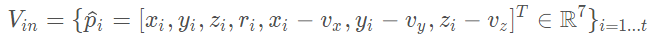
接著,每一個(gè)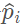 都會(huì)通過(guò)一個(gè)全連接網(wǎng)絡(luò)(Fully Connected,F(xiàn)C,論文中用的是FCN來(lái)簡(jiǎn)稱,實(shí)際上FCN更多的被用于表示全卷積網(wǎng)絡(luò),所以原文此處用FCN簡(jiǎn)稱實(shí)際上不妥)被映射到一個(gè)特征空間
都會(huì)通過(guò)一個(gè)全連接網(wǎng)絡(luò)(Fully Connected,F(xiàn)C,論文中用的是FCN來(lái)簡(jiǎn)稱,實(shí)際上FCN更多的被用于表示全卷積網(wǎng)絡(luò),所以原文此處用FCN簡(jiǎn)稱實(shí)際上不妥)被映射到一個(gè)特征空間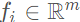 ,輸入的特征維度為7,輸出的特征維數(shù)變成m mm,全連接層包含了一個(gè)線性映射層,一個(gè)批標(biāo)準(zhǔn)化(Batch Normalization),以及一個(gè)非線性運(yùn)算(ReLU),得到逐點(diǎn)的(point-wise)的特征表示。
,輸入的特征維度為7,輸出的特征維數(shù)變成m mm,全連接層包含了一個(gè)線性映射層,一個(gè)批標(biāo)準(zhǔn)化(Batch Normalization),以及一個(gè)非線性運(yùn)算(ReLU),得到逐點(diǎn)的(point-wise)的特征表示。
接著我們采用最大池化(MaxPooling)對(duì)上一步得到的特征表示進(jìn)行逐元素的聚合,這一池化操作是對(duì)元素和元素之間進(jìn)行的,得到局部聚合特征(Locally Aggregated Feature),即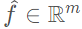 ?,最后,將逐點(diǎn)特征和逐元素特征進(jìn)行連接(concatenate),得到輸出的特征集合:
?,最后,將逐點(diǎn)特征和逐元素特征進(jìn)行連接(concatenate),得到輸出的特征集合:
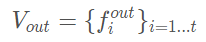
對(duì)于所有的非空的體素格我們都進(jìn)行上述操作,并且它們都共享全連接層(FC)的參數(shù)。我們使用符號(hào) 來(lái)描述經(jīng)過(guò)VFE以后特征的維數(shù)變化,那么顯然全連接層的參數(shù)矩陣大小為:
來(lái)描述經(jīng)過(guò)VFE以后特征的維數(shù)變化,那么顯然全連接層的參數(shù)矩陣大小為:
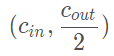
由于VFE層中包含了逐點(diǎn)特征和逐元素特征的連接,經(jīng)過(guò)多層VFE以后,我們希望網(wǎng)絡(luò)可以自動(dòng)學(xué)習(xí)到每個(gè)體素內(nèi)的特征表示(比如說(shuō)體素格內(nèi)的形狀信),那么如何學(xué)習(xí)體素內(nèi)的特征表示呢?原論文的方法下圖所示:
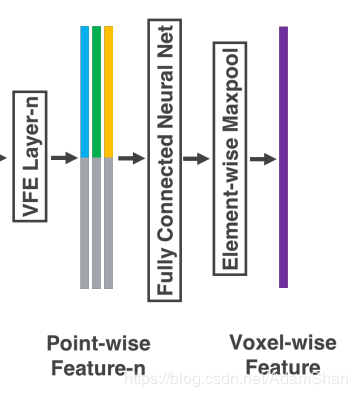
通過(guò)對(duì)體素格內(nèi)所有點(diǎn)進(jìn)行最大池化,得到一個(gè)體素格內(nèi)特征表示 C 。
稀疏張量表示
通過(guò)上述流程處理非空體素格,我們可以得到一系列的體素特征(Voxel Feature)。這一系列的體素特征可以使用一個(gè)4維的稀疏張量來(lái)表示:
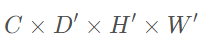
雖然一次lidar掃描包含接近10萬(wàn)個(gè)點(diǎn),但是超過(guò)90%的體素格都是空的,使用稀疏張量來(lái)描述非空體素格在于能夠降低反向傳播時(shí)的內(nèi)存和計(jì)算消耗。
對(duì)于具體的車輛檢測(cè)問(wèn)題,我們?nèi)⊙刂鳯idar坐標(biāo)系的(Z,Y,X) (Z,Y,X)(Z,Y,X)方向取[?3,1]×[?40,40]×[0,70.4] [?3, 1] × [?40, 40] × [0, 70.4][?3,1]×[?40,40]×[0,70.4]立方體(單位為米)作為輸入點(diǎn)云,取體素格的大小為:
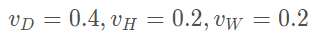
那么有

我們?cè)O(shè)置隨機(jī)采樣的T=35 T = 35T=35,并且采用兩個(gè)VFE層:VFE-1(7, 32) 和 VFE-2(32, 128),最后的全連接層將VFE-2的輸出映射到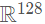 ?。最后,特征學(xué)習(xí)網(wǎng)絡(luò)的輸出即為一個(gè)尺寸為 (128×10×400×352) 的稀疏張量。整個(gè)特征網(wǎng)絡(luò)的TensorFlow實(shí)現(xiàn)代碼如下:
?。最后,特征學(xué)習(xí)網(wǎng)絡(luò)的輸出即為一個(gè)尺寸為 (128×10×400×352) 的稀疏張量。整個(gè)特征網(wǎng)絡(luò)的TensorFlow實(shí)現(xiàn)代碼如下:
classVFELayer(object):def__init__(self,out_channels,name):super(VFELayer,self).__init__()self.units=int(out_channels/2)withtf.variable_scope(name,reuse=tf.AUTO_REUSE)asscope:self.dense=tf.layers.Dense(self.units,tf.nn.relu,name='dense',_reuse=tf.AUTO_REUSE,_scope=scope)self.batch_norm=tf.layers.BatchNormalization(name='batch_norm',fused=True,_reuse=tf.AUTO_REUSE,_scope=scope)defapply(self,inputs,mask,training):#[K,T,7]tensordot[7,units]=[K,T,units]pointwise=self.batch_norm.apply(self.dense.apply(inputs),training)#n[K,1,units]aggregated=tf.reduce_max(pointwise,axis=1,keep_dims=True)#[K,T,units]repeated=tf.tile(aggregated,[1,cfg.VOXEL_POINT_COUNT,1])#[K,T,2*units]concatenated=tf.concat([pointwise,repeated],axis=2)mask=tf.tile(mask,[1,1,2*self.units])concatenated=tf.multiply(concatenated,tf.cast(mask,tf.float32))returnconcatenatedclassFeatureNet(object):def__init__(self,training,batch_size,name=''):super(FeatureNet,self).__init__()self.training=training#scalarself.batch_size=batch_size#[ΣK,35/45,7]self.feature=tf.placeholder(tf.float32,[None,cfg.VOXEL_POINT_COUNT,7],name='feature')#[ΣK]self.number=tf.placeholder(tf.int64,[None],name='number')#[ΣK,4],eachrowstores(batch,d,h,w)self.coordinate=tf.placeholder(tf.int64,[None,4],name='coordinate')withtf.variable_scope(name,reuse=tf.AUTO_REUSE)asscope:self.vfe1=VFELayer(32,'VFE-1')self.vfe2=VFELayer(128,'VFE-2')#booleanmask[K,T,2*units]mask=tf.not_equal(tf.reduce_max(self.feature,axis=2,keep_dims=True),0)x=self.vfe1.apply(self.feature,mask,self.training)x=self.vfe2.apply(x,mask,self.training)#[ΣK,128]voxelwise=tf.reduce_max(x,axis=1)#car:[N*10*400*352*128]#pedestrian/cyclist:[N*10*200*240*128]self.outputs=tf.scatter_nd(self.coordinate,voxelwise,[self.batch_size,10,cfg.INPUT_HEIGHT,cfg.INPUT_WIDTH,128])
卷積中間層
每一個(gè)卷積中間層包含一個(gè)3維卷積,一個(gè)BN層(批標(biāo)準(zhǔn)化),一個(gè)非線性層(ReLU),我們用:

來(lái)描述一個(gè)卷積中間層,Conv3D表示是三維卷積,cin,cout分別表示輸入和輸出的通道數(shù),k是卷積核的大小,它是一個(gè)向量,對(duì)于三維卷積而言,卷積核的大小為(k,k,k);s即stride,卷積操作的步長(zhǎng);p即padding,填充的尺寸。
對(duì)于車輛檢測(cè)而言,設(shè)計(jì)的卷積中間層如下:
Conv3D(128,64,3,(2,1,1),(1,1,1))Conv3D(64,64,3,(1,1,1),(0,1,1))Conv3D(64,64,3,(2,1,1),(1,1,1))
卷積中間層的TensorFlow代碼如下:
defConvMD(M,Cin,Cout,k,s,p,input,training=True,activation=True,bn=True,name='conv'):temp_p=np.array(p)temp_p=np.lib.pad(temp_p,(1,1),'constant',constant_values=(0,0))withtf.variable_scope(name)asscope:if(M==2):paddings=(np.array(temp_p)).repeat(2).reshape(4,2)pad=tf.pad(input,paddings,"CONSTANT")temp_conv=tf.layers.conv2d(pad,Cout,k,strides=s,padding="valid",reuse=tf.AUTO_REUSE,name=scope)if(M==3):paddings=(np.array(temp_p)).repeat(2).reshape(5,2)pad=tf.pad(input,paddings,"CONSTANT")temp_conv=tf.layers.conv3d(pad,Cout,k,strides=s,padding="valid",reuse=tf.AUTO_REUSE,name=scope)ifbn:temp_conv=tf.layers.batch_normalization(temp_conv,axis=-1,fused=True,training=training,reuse=tf.AUTO_REUSE,name=scope)ifactivation:returntf.nn.relu(temp_conv)else:returntemp_conv#convolutinalmiddlelayerstemp_conv=ConvMD(3,128,64,3,(2,1,1),(1,1,1),self.input,name='conv1')temp_conv=ConvMD(3,64,64,3,(1,1,1),(0,1,1),temp_conv,name='conv2')temp_conv=ConvMD(3,64,64,3,(2,1,1),(1,1,1),temp_conv,name='conv3')temp_conv=tf.transpose(temp_conv,perm=[0,2,3,4,1])temp_conv=tf.reshape(temp_conv,[-1,cfg.INPUT_HEIGHT,cfg.INPUT_WIDTH,128])
區(qū)域提出網(wǎng)絡(luò)(RPN)
RPN實(shí)際上是目標(biāo)檢測(cè)網(wǎng)絡(luò)中常用的一種網(wǎng)絡(luò),下圖是VoxelNet中使用的RPN:
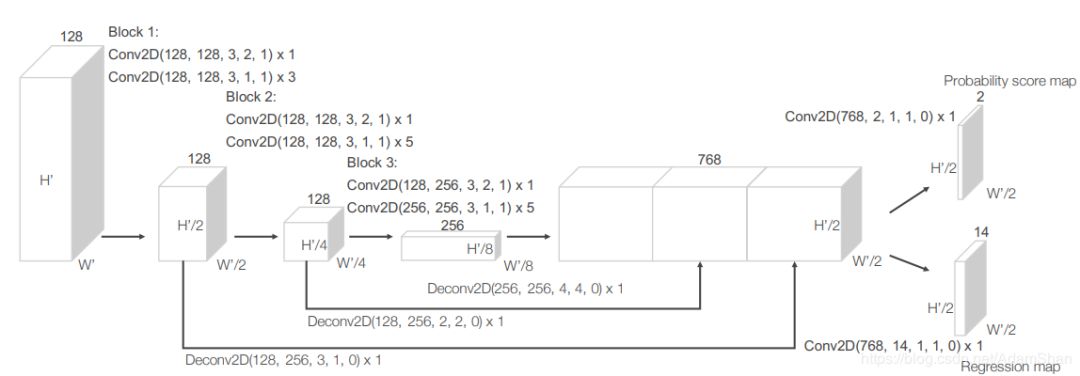
如圖所示,該網(wǎng)絡(luò)包含三個(gè)全卷積層塊(Block),每個(gè)塊的第一層通過(guò)步長(zhǎng)為2的卷積將特征圖采樣為一半,之后是三個(gè)步長(zhǎng)為1的卷積層,每個(gè)卷積層都包含BN層和ReLU操作。將每一個(gè)塊的輸出都上采樣到一個(gè)固定的尺寸并串聯(lián)構(gòu)造高分辨率的特征圖。最后,該特征圖通過(guò)兩種二維卷積被輸出到期望的學(xué)習(xí)目標(biāo):
概率評(píng)分圖(Probability Score Map )
回歸圖(Regression Map)
使用TensorFlow實(shí)現(xiàn)該RPN如下(非完整代碼,完整代碼請(qǐng)見文末鏈接)):
defDeconv2D(Cin,Cout,k,s,p,input,training=True,bn=True,name='deconv'):temp_p=np.array(p)temp_p=np.lib.pad(temp_p,(1,1),'constant',constant_values=(0,0))paddings=(np.array(temp_p)).repeat(2).reshape(4,2)pad=tf.pad(input,paddings,"CONSTANT")withtf.variable_scope(name)asscope:temp_conv=tf.layers.conv2d_transpose(pad,Cout,k,strides=s,padding="SAME",reuse=tf.AUTO_REUSE,name=scope)ifbn:temp_conv=tf.layers.batch_normalization(temp_conv,axis=-1,fused=True,training=training,reuse=tf.AUTO_REUSE,name=scope)returntf.nn.relu(temp_conv)#rpn#block1:temp_conv=ConvMD(2,128,128,3,(2,2),(1,1),temp_conv,training=self.training,name='conv4')temp_conv=ConvMD(2,128,128,3,(1,1),(1,1),temp_conv,training=self.training,name='conv5')temp_conv=ConvMD(2,128,128,3,(1,1),(1,1),temp_conv,training=self.training,name='conv6')temp_conv=ConvMD(2,128,128,3,(1,1),(1,1),temp_conv,training=self.training,name='conv7')deconv1=Deconv2D(128,256,3,(1,1),(0,0),temp_conv,training=self.training,name='deconv1')#block2:temp_conv=ConvMD(2,128,128,3,(2,2),(1,1),temp_conv,training=self.training,name='conv8')temp_conv=ConvMD(2,128,128,3,(1,1),(1,1),temp_conv,training=self.training,name='conv9')temp_conv=ConvMD(2,128,128,3,(1,1),(1,1),temp_conv,training=self.training,name='conv10')temp_conv=ConvMD(2,128,128,3,(1,1),(1,1),temp_conv,training=self.training,name='conv11')temp_conv=ConvMD(2,128,128,3,(1,1),(1,1),temp_conv,training=self.training,name='conv12')temp_conv=ConvMD(2,128,128,3,(1,1),(1,1),temp_conv,training=self.training,name='conv13')deconv2=Deconv2D(128,256,2,(2,2),(0,0),temp_conv,training=self.training,name='deconv2')#block3:temp_conv=ConvMD(2,128,256,3,(2,2),(1,1),temp_conv,training=self.training,name='conv14')temp_conv=ConvMD(2,256,256,3,(1,1),(1,1),temp_conv,training=self.training,name='conv15')temp_conv=ConvMD(2,256,256,3,(1,1),(1,1),temp_conv,training=self.training,name='conv16')temp_conv=ConvMD(2,256,256,3,(1,1),(1,1),temp_conv,training=self.training,name='conv17')temp_conv=ConvMD(2,256,256,3,(1,1),(1,1),temp_conv,training=self.training,name='conv18')temp_conv=ConvMD(2,256,256,3,(1,1),(1,1),temp_conv,training=self.training,name='conv19')deconv3=Deconv2D(256,256,4,(4,4),(0,0),temp_conv,training=self.training,name='deconv3')#final:temp_conv=tf.concat([deconv3,deconv2,deconv1],-1)#Probabilityscoremap,scale=[None,200/100,176/120,2]p_map=ConvMD(2,768,2,1,(1,1),(0,0),temp_conv,training=self.training,activation=False,bn=False,name='conv20')#Regression(residual)map,scale=[None,200/100,176/120,14]r_map=ConvMD(2,768,14,1,(1,1),(0,0),temp_conv,training=self.training,activation=False,bn=False,name='conv21')
損失函數(shù)
我們首先定義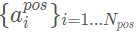 為正樣本集合,
為正樣本集合,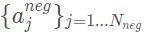 為負(fù)樣本集合,使用
為負(fù)樣本集合,使用 來(lái)表示一個(gè)真實(shí)的3D標(biāo)注框,其中
來(lái)表示一個(gè)真實(shí)的3D標(biāo)注框,其中
表示標(biāo)注框中心的坐標(biāo),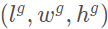 表示標(biāo)注框的長(zhǎng)寬高,
表示標(biāo)注框的長(zhǎng)寬高,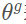 表示偏航角(Yaw)。相應(yīng)的,
表示偏航角(Yaw)。相應(yīng)的,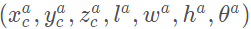 表示正樣本框。那么回歸的目標(biāo)為一下七個(gè)量:
表示正樣本框。那么回歸的目標(biāo)為一下七個(gè)量:
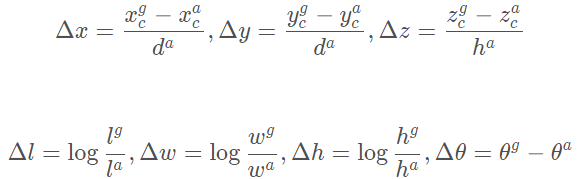
其中

是正樣本框的對(duì)角線。我們定義損失函數(shù)為:
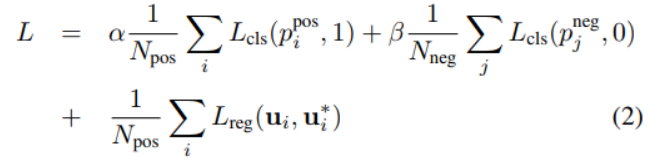
其中 分別表示正樣本
分別表示正樣本 和負(fù)樣本
和負(fù)樣本 的Softmax輸出,分別表示神經(jīng)網(wǎng)絡(luò)的正樣本輸出的標(biāo)注框和真實(shí)標(biāo)注框。損失函數(shù)的前兩項(xiàng)表示對(duì)于正樣本輸出和負(fù)樣本輸出的分類損失(已經(jīng)進(jìn)行了正規(guī)化),其中表示交叉熵,是兩個(gè)常數(shù),它們作為權(quán)重來(lái)平衡正負(fù)樣本損失對(duì)于最后的損失函數(shù)的影響。
的Softmax輸出,分別表示神經(jīng)網(wǎng)絡(luò)的正樣本輸出的標(biāo)注框和真實(shí)標(biāo)注框。損失函數(shù)的前兩項(xiàng)表示對(duì)于正樣本輸出和負(fù)樣本輸出的分類損失(已經(jīng)進(jìn)行了正規(guī)化),其中表示交叉熵,是兩個(gè)常數(shù),它們作為權(quán)重來(lái)平衡正負(fù)樣本損失對(duì)于最后的損失函數(shù)的影響。 表示回歸損失,這里采用的是Smooth L1函數(shù)。
表示回歸損失,這里采用的是Smooth L1函數(shù)。
ROS實(shí)踐
我們?nèi)匀皇褂玫诙┛偷臄?shù)據(jù)(截取自KITTI),下載地址:https://pan.baidu.com/s/1kxZxrjGHDmTt-9QRMd_kOA
我們直接采用qianguih提供的訓(xùn)練好的模型(參考:https://github.com/qianguih/voxelnet ,大家也可以基于該項(xiàng)目自己訓(xùn)練模型)。
安裝項(xiàng)目依賴環(huán)境:
python3.5+
TensorFlow (tested on 1.4)
opencv
shapely
numba
easydict
ROS
jsk package
準(zhǔn)備數(shù)據(jù)
下載上面的數(shù)據(jù)集,解壓到項(xiàng)目(源碼地址見文末)的data文件夾下,目錄結(jié)構(gòu)為:
data----lidar_2d--------0000...1.npy--------0000...2.npy--------.......
運(yùn)行
catkin_make
roscd voxelnet/script/
python3 voxelnet_ros.py & python3 pub_kitti_point_cloud.py
注意不能使用rosrun,因?yàn)閂oxelNet代碼為Python 3.x
rqt節(jié)點(diǎn)圖

使用Rviz可視化
存在的問(wèn)題
實(shí)例的模型的性能不佳,由于論文作者沒有開源其代碼,許多參數(shù)仍然有待調(diào)整
調(diào)整速度慢,沒有實(shí)現(xiàn)作者提出的高效策略
-
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1224瀏覽量
25444 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5561瀏覽量
122786
原文標(biāo)題:無(wú)人駕駛汽車系統(tǒng)入門:基于VoxelNet的激光雷達(dá)點(diǎn)云車輛檢測(cè)及ROS實(shí)現(xiàn)
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
基于深度學(xué)習(xí)的三維點(diǎn)云配準(zhǔn)方法
深入分析深度學(xué)習(xí)三維重建的網(wǎng)絡(luò)架構(gòu)和訓(xùn)練技巧
通過(guò)多模態(tài)特征融合來(lái)設(shè)計(jì)三維點(diǎn)云分類模型
基于深度學(xué)習(xí)的三維點(diǎn)云語(yǔ)義分割研究分析

一種興趣點(diǎn)分層學(xué)習(xí)的全監(jiān)督算法

基于激光雷達(dá)點(diǎn)云的三維目標(biāo)檢測(cè)算法
針對(duì)復(fù)雜場(chǎng)景處理的點(diǎn)云深度學(xué)習(xí)網(wǎng)絡(luò)
點(diǎn)云的概念以及與三維圖像的關(guān)系

什么樣的點(diǎn)可以稱為三維點(diǎn)云中的關(guān)鍵點(diǎn)呢?
深度學(xué)習(xí)背景下的圖像三維重建技術(shù)進(jìn)展綜述
一文詳解點(diǎn)云及三維圖像處理技術(shù)
基于深度學(xué)習(xí)的三維點(diǎn)云配準(zhǔn)新方法

什么是三維點(diǎn)云分割
基于深度學(xué)習(xí)的三維點(diǎn)云分類方法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論