 基于深度學習的三維點云配準新方法
基于深度學習的三維點云配準新方法
一、摘要
本文介紹了一種基于深度學習的三維點云配準新方法。該架構由三個部分組成:
(1)編碼器由基于卷積圖的描述符組成,該描述符對每個點的近鄰進行編碼,并采用注意機制對表面法線的變化進行編碼,突出同一集合的點之間以及兩個集合的點之間的注意力;
(2)使用Sinkhorn算法估計對應矩陣的匹配過程;
(3)通過對應矩陣中的最佳分數Kc,利用RANSAC計算兩個點云之間的剛性變換。
最后,在ModelNet40數據集上進行實驗,提出的架構在大多數模擬配置中優于最先進的方法,包括部分重疊和高斯噪聲的數據增強。
二、網絡結構
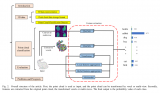
提出的RoCNet網絡結構如圖1所示,主要包含三個部分:1)由卷積圖網絡組成的描述符算子,進行編碼每個點的近鄰和一個編碼表面法線變化的注意機制;2) 使用Sinkhorn算法估計對應矩陣的匹配模塊;3) 利用RANSAC模塊中Kc來計算剛性變換,得到最佳匹配結果

圖1 網絡結構
三、方法
3.1 點云描述子
定義點云X和點云Y,存在部分重疊,故至少存在K(K<=min(M,N))對匹配點。令X中匹配點集為?,Y中匹配點集為數?。由于點云配準的精度取決于編碼描述子的質量。
因此,提出了一個新的描述符,通過將X和Y的初始集合投影到一個更高維度的新基中,比初始空間表示更具判別性且盡可能不受旋轉和平移的影響,主要結合了一個基于幾何的描述符、一個基于法向量的描述符和一個注意機制。
(1)基于幾何的描述符
這里選擇將DGCNN作為描述符的一部分,因為它可以更好地捕獲點云的局部幾何特征,同時保持排列不變性。DGCNN主要由EdgeConv卷積層組成,其中點代表以圓弧連接到編碼空間中最近的k個近鄰節點,以構建表示每個點周圍的局部幾何結構的圖,然后在更高級別(全局編碼)動態傳播信息。以fXi為點xi提取到的d維特征向量。
(2)基于法向量的描述符
描述符的主要思想是利用鄰近點的法線變化來編碼每個點周圍的表面信息,因為平坦表面上的法線不會變化,沿著脊的法線只在一個方向上變化,而頂點上的法線在所有方向上變化。因此,根據鄰域法線角度的變化可以得出曲面類型的信息。
利用主成分分析法來計算法線信息,每個點,定義為局部鄰域子集,令表示劃分集合點的大小,是以 為中心的球體的半徑,是 集合中包含的最大點數。協方差矩陣Cov(Si)的特征值分解允許將法向量定義為與最小特征值相關的向量,Cov(Si)表示為:
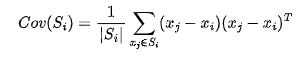
其中,表示為的點數。由于PCA可指向任一個方向的法向量,因此使用新的向量 ( 共線)來解決其模糊性。定義為
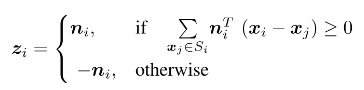
由于PCA可指向任一個方向的法向量,因此使用新的向量 (與 共線)來解決其模糊性。定義 為
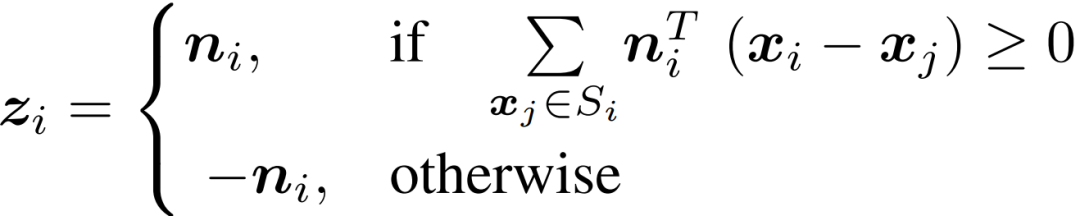
最后,使用不同頻率的正弦函數構建最終編碼。已知兩點和 的法線夾角為,則編碼法線向量為:
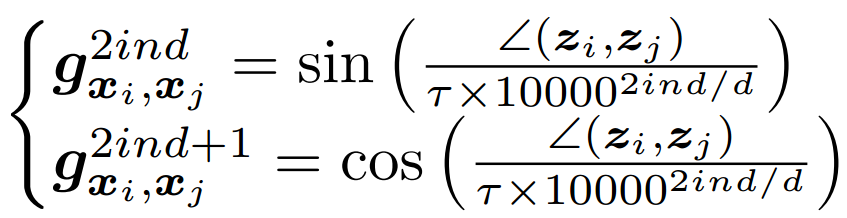
其中,為 當前值指數, 為歸一化系數, 是描述符數學公式: 的維數,將其固定為與基于幾何的描述符DGCNN相同的大小,然后對 用全連接層以獲得最終嵌入
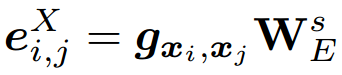
其中,是學習投影矩陣
(3)注意力機制
本文方法采用在每個集合X和Y中使用四個具有幾何自我注意的注意頭,分別對相關的法線嵌入 和 進行積分,然后在兩組點之間進行交叉注意,交替執行L次
(4)自注意力
自注意力層為點云的每個點預測一個基于注意力的特征。對點云X和Y中的所有點都使用相同的算法,即可得到每個query/key對應的注意力權重:
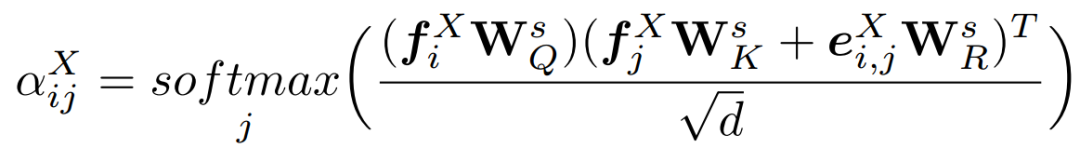
其中,是學習投影矩陣
(3)注意力機制
本文方法采用在每個集合X和Y中使用四個具有幾何自我注意的注意頭,分別對相關的法線嵌入和進行積分,然后在兩組點之間進行交叉注意,交替執行L次
(4)自注意力
自注意力層為點云的每個點預測一個基于注意力的特征。對點云X和Y中的所有點都使用相同的算法,即可得到每個query/key對應的注意力權重:
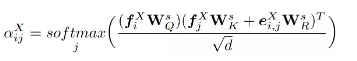
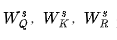 是學習到的用于query、key和基于法向量的嵌入投影矩陣,d是特征的維數和 。權重用于評估注意的一些元素,并獲得最終的基于自注意的特征 :
是學習到的用于query、key和基于法向量的嵌入投影矩陣,d是特征的維數和 。權重用于評估注意的一些元素,并獲得最終的基于自注意的特征 :
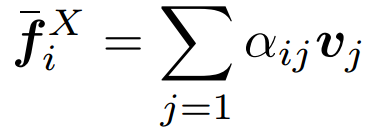
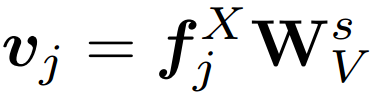
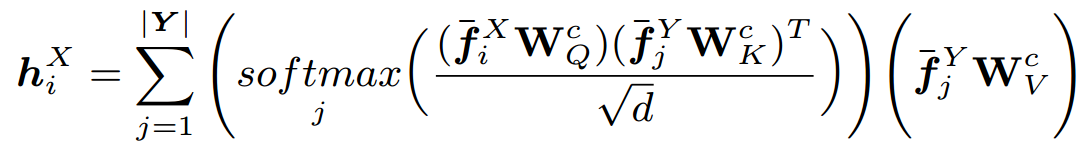
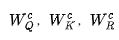 是交叉注意層中學習到的query、key和value的投影矩陣。
是交叉注意層中學習到的query、key和value的投影矩陣。
3.2 點匹配
在每個點數學公式: 之間估計一個分數矩陣C:
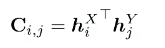
其中, 和是定義點和 的最終編碼。然后將C的維度分別增加到M+1和N+1,從而建立一個對應概率 的矩陣,再使用可微的Sinkhorn算法。
由于前面所有步驟都是可微的,因此可以通過引入損失函數來學習網絡的權重。為此,采用gap損失函數,表示為
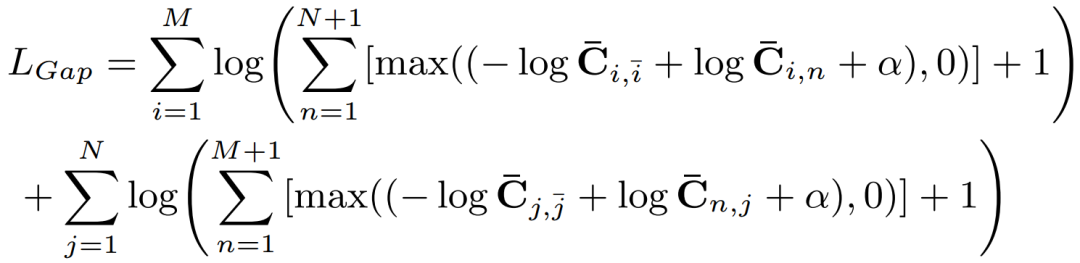
其中, 是一個值為0.5的正標量,和分別是點和的基本匹配分數。
3.3 位姿估計
在求值階段,通過以下算法構建一個硬賦值二進制矩陣a:
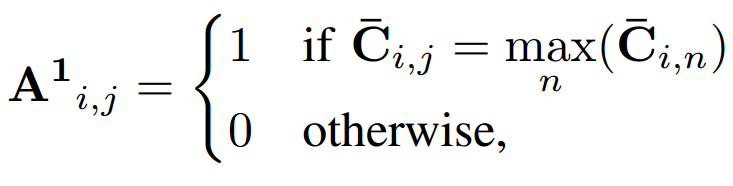
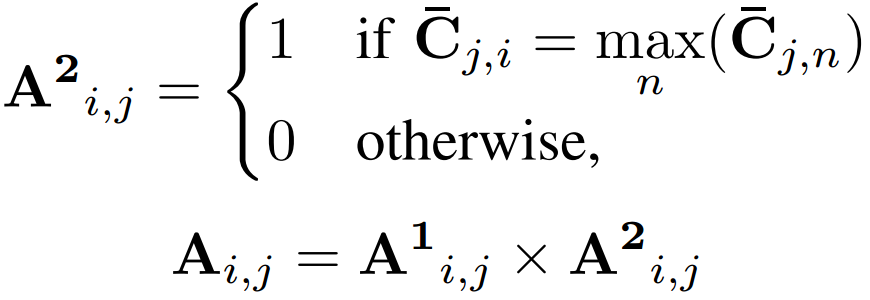
矩陣A分別用非零值的行向量和列向量重新索引原始點云X和Y,得到了兩個最終匹配點和的集合,匹配執行如圖3所示。建立了匹配點集后,本文使用基于預測對應的RANSAC來減少計算成本。此外,不考慮所有K個匹配點,只使用個最相關的點,同時在第一次迭代之前過濾異常值。
(a) (b) (c)
圖2 3D匹配示例((a)干凈數據;(b)部分重疊;(c)噪聲數據和部分重疊)
四、實驗結果
以下所有的對比結果均基于VRNet論文中的結果。首先在干凈的數據上進行性能對比,如表1所示。
可以發現,本文方法在RMSE和MAE方面的性能優于其他方法。然而,VRNet在旋轉性方面仍然是最好的,盡管與RoCNet相比差異很小,特別是在MAE(t)中,RoCNet排名第二。
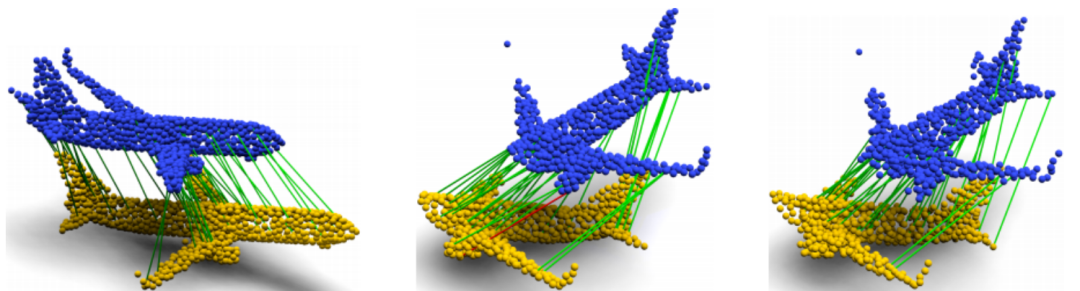
可視化實例如圖3所示,第一行顯示待對齊點云X和Y的初始位置,第二行顯示已執行的配準,第三行顯示地面真值
表1 使用無噪聲和遮擋的所有網絡性能對比
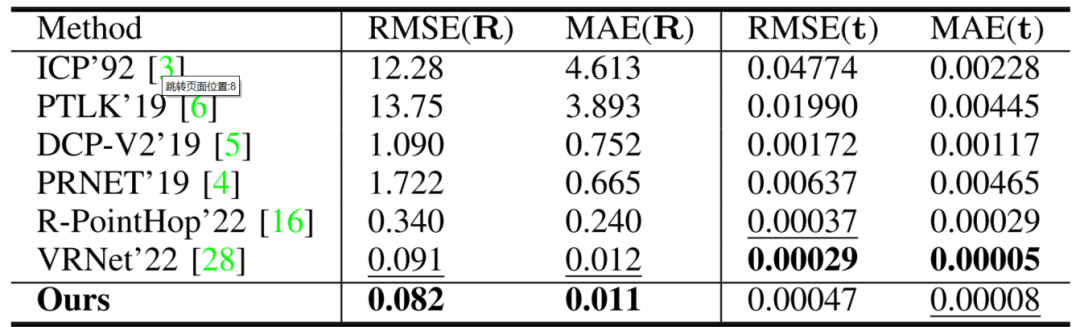

圖3干凈且無遮擋的情況下,RoCNet配準實例
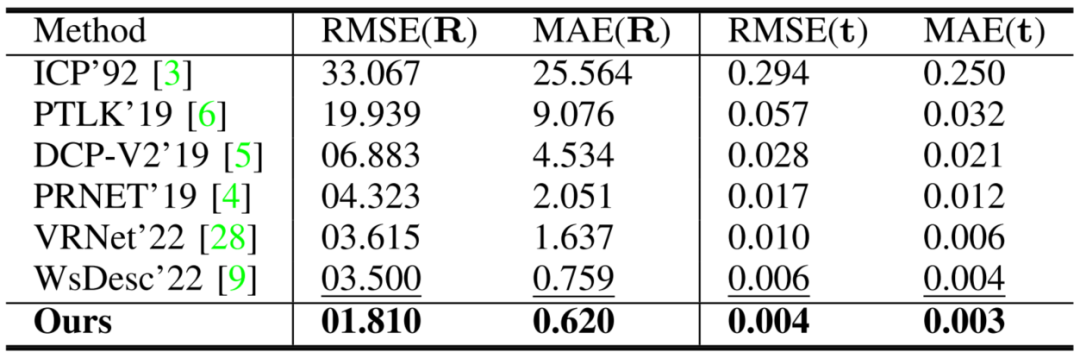
在帶有噪聲數據和部分遮擋的所有類別上訓練的模型結果如表2所示,RoCNet在所有指標上都優于其他方法,包括旋轉和平移。RoCNet允許顯著增強的配準誤差,從三分之二到四分之一不等,與WsDesc、VRNet相比,擁有對部分遮擋或噪聲或兩者同時的魯棒性。
表2 使用噪聲和部分遮擋的所有網絡性能對比
此外,為了直觀地評估所提出方法的魯棒性,通過逐步降低(從95%到50%)X和Y之間共享點的比率來進行不同的配準,如圖4所示。
可以看到,RoCNet即使只使用50%的數據也可以很容易地配準點云。但另一方面,對于完全對稱的物體,當重疊度較低時,該方法顯示出其局限性。
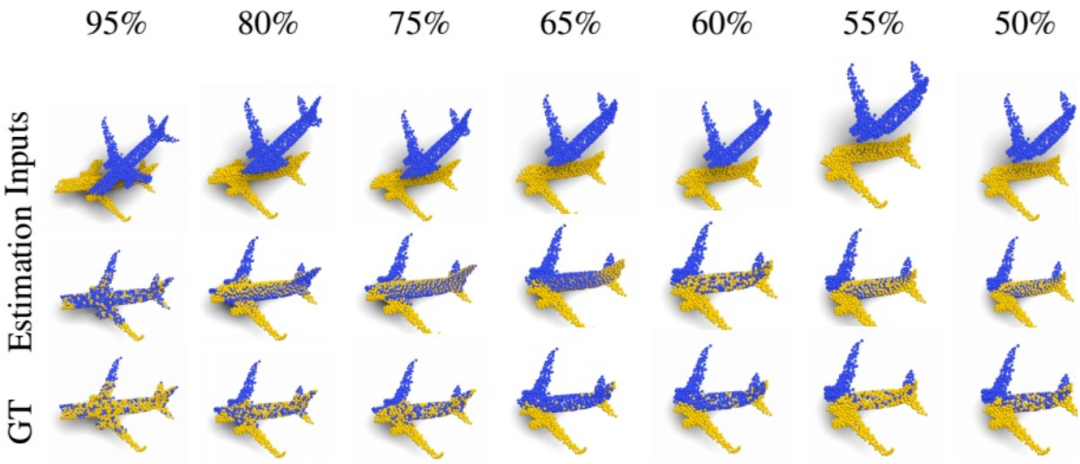
圖4 RoCNet魯棒性證明
五、結論
本文提出了一種基于深度學習的三維點云配準和姿態估計方法。所提出的體系結構由三個主要部分組成:1)新設計的描述符編碼每個點的鄰域和編碼表面法線變化的注意機制;2)使用Sinkhorn算法估計對應矩陣的匹配方法;3)使用RANSAC應用于對應矩陣的K^c最佳匹配來估計剛性變換。使用ModelNet40數據集在不同的配置下對所提出的架構進行了評估。
實驗證明,本文方法優于相關的最先進的算法,特別是在噪聲的數據和部分遮擋的條件下。
未來,打算將這項工作擴展到一種新的方法,在這種方法中,描述符將在頻率范圍內表示。這當然會提高我們架構的準確性,但也提高了它對噪聲和部分遮擋的魯棒性。
六、感悟
這是一篇十分標準的基于深度學習的點云配準的論文,整體結構可以作為借鑒學習,所提出的編碼算法的性能很好,最終也在ModelNet40數據集上進行測試所提算法的有效性。同時,該方法可以擴展接入其余點云配準的方法,希望源碼早日公開,進行學習。
責任編輯:彭菁
-
三維
+關注
關注
1文章
516瀏覽量
29353 -
數據集
+關注
關注
4文章
1222瀏覽量
25273 -
深度學習
+關注
關注
73文章
5554瀏覽量
122469
原文標題:RoCNet:一種利用深度學習的魯棒性3D點云配準
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
一種快速的三維點云自動配準方法
圖瑪深維發布四款智能診斷新品,均采用深度學習和AI領域的最新方法
基于分層策略的三維非剛性模型配準算法



一個基于學習的LiDAR點云3D線特征分割和描述模型
基于深度學習的三維點云分類方法





 工商網監
工商網監
評論