") 基于Keras實(shí)現(xiàn)雙向LSTM,可視化其注意力機(jī)制
基于Keras實(shí)現(xiàn)雙向LSTM,可視化其注意力機(jī)制

編者按:Datalogue的Zafarali Ahmed介紹了RNN和seq2seq的概念,基于Keras實(shí)現(xiàn)了一個(gè)雙向LSTM,并可視化了它的注意力機(jī)制。
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)在翻譯(谷歌翻譯)、語音識(shí)別(Cortana)和語言生成領(lǐng)域取得了巨大的成功。在Datalogue,我們處理大量的文本數(shù)據(jù),我們很有興趣幫助社區(qū)理解這一技術(shù)。
在這篇教程中,我們將基于Keras編寫一個(gè)RNN,將“November 5, 2016”、“5th November 2016”這樣的日期表達(dá)轉(zhuǎn)換為標(biāo)準(zhǔn)格式(“2016–11–05”)。具體來說,我們希望獲得一些神經(jīng)網(wǎng)絡(luò)是如何做到這些的直覺。我們將利用注意力概念生成一份類似下圖的映射,揭示哪些輸入字符在預(yù)測(cè)輸出字符上起著重要作用。
教程概覽
我們將從一些技術(shù)背景材料開始,接著編程模型!在教程中,我會(huì)提供指向更高級(jí)內(nèi)容的鏈接。
如果你想要直接查看代碼:
請(qǐng)?jiān)L問GitHub:datalogue/keras-attention
你需要了解
如果你想直接跳到本教程的代碼部分,你最好熟悉Python和Keras。你應(yīng)該熟悉下線性代數(shù),畢竟神經(jīng)網(wǎng)絡(luò)不過是應(yīng)用了非線性的一些權(quán)重矩陣。
下面我們將解釋RNN和seq2seq(序列到序列)模型的直覺。
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)
RNN是一個(gè)應(yīng)用同一變換(稱為RNN單元或步驟)至一個(gè)序列的每個(gè)元素的函數(shù)。RNN層的輸出是RNN單元應(yīng)用至序列的每個(gè)元素后的輸出。在文本情形下,這些通常是后續(xù)的單詞或字符。此外,RNN單元維護(hù)內(nèi)部記憶,總結(jié)了目前為止所見序列的歷史。

RNN層的輸出是一個(gè)編碼序列h,可以處理該序列,也可以將它傳給另一個(gè)網(wǎng)絡(luò)。RNN的輸入和輸出極為靈活:
多對(duì)一:使用完整的輸入序列做出單個(gè)預(yù)測(cè)h。
一對(duì)多:轉(zhuǎn)換單個(gè)輸入以生成序列h。
多對(duì)多:轉(zhuǎn)換整個(gè)輸入序列至另一個(gè)序列。
理論上,訓(xùn)練數(shù)據(jù)的序列長(zhǎng)度不用一樣。在實(shí)踐中,我們補(bǔ)齊或截?cái)嘈蛄械玫较嗤L(zhǎng)度,以利用TensorFlow的靜態(tài)計(jì)算圖的優(yōu)勢(shì)。
我們將重點(diǎn)關(guān)注第三種RNN,“多對(duì)多”,也稱為序列到序列(seq2seq)。
由于訓(xùn)練中梯度計(jì)算的不穩(wěn)定性,RNN很難學(xué)習(xí)長(zhǎng)序列。為了解決這一問題,可以將RNN單元替換為門控單元,比如門控循環(huán)單元(GRU)或長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(LSTM)。如果你想了解更多LSTM和門控單元,我強(qiáng)烈推薦Christopher Olah的博客(我就是從這篇開始理解RNN單元的)。從現(xiàn)在開始,當(dāng)我們談?wù)揜NN的時(shí)候,我們指的是門控單元。
seq2seq一般框架:編碼器-解碼器設(shè)定
幾乎所有處理seq2seq問題的神經(jīng)網(wǎng)絡(luò)都涉及:
編碼輸入序列為某種抽象表示。
處理這一編碼。
解碼至目標(biāo)序列。
編碼器和解碼器可以是任意種類的神經(jīng)網(wǎng)絡(luò)組合。在實(shí)踐中,大多數(shù)人編碼器和解碼器都使用RNN。

上圖顯示了一個(gè)簡(jiǎn)單的編碼器-解碼器設(shè)定。編碼步驟通常生成向量序列h,對(duì)應(yīng)輸入數(shù)據(jù)中的字符序列x。在一個(gè)RNN編碼器中,通過納入之前向量序列的信息生成每個(gè)向量。
在將h傳給解碼器之前,我們可以先處理一番。例如,我們也許選擇只使用最后的編碼(如下圖所示),因?yàn)槔碚撋纤钦麄€(gè)序列的總結(jié)。
直觀地說,這類似總結(jié)整個(gè)輸入數(shù)據(jù)為單個(gè)表示,接著嘗試加以解碼。盡管對(duì)于情緒檢測(cè)這樣的分類問題(多對(duì)一),總結(jié)狀態(tài)可能已經(jīng)具備足夠信息,對(duì)于翻譯之類的問題,僅僅使用總結(jié)狀態(tài)可能不夠,需要考慮隱藏狀態(tài)的完整序列。
然而,人類不是這么翻譯日期的:我們并不讀取整個(gè)文本,然后單獨(dú)寫下每個(gè)字符的翻譯。從直覺上說,一個(gè)人會(huì)整體理解一組字符“Jan”對(duì)應(yīng)一月,“5”對(duì)應(yīng)日期,“2016”對(duì)應(yīng)年。如前所述,這一想法是RNN可以捕捉的注意,并且成功用于圖像說明生成(Xu等. 2015),語音識(shí)別(Chan等. 2015),還有機(jī)器翻譯(Bahdanau等. 2014)。最重要的是,它們生成可解釋的模型。
上面提到的圖像說明生成論文展示了一個(gè)注意力機(jī)制如何工作的可視化例子。在女孩和泰迪熊的復(fù)雜例子中,我們看到,生成單詞“girl”(女孩)時(shí),注意力機(jī)制成功地聚焦女孩,而不是泰迪熊!相當(dāng)聰明。這不僅可以生成效果很好的可視化圖像,同時(shí)便于作者診斷模型中的問題。
SpaCy的創(chuàng)造者寫了一篇編碼器-注意-解碼器范式的深度概覽:Embed, encode, attend, predict: The new deep learning formula for state-of-the-art NLP models。如果你想了解其他改動(dòng)RNN的方式,可以參考Distill上的Attention and Augmented Recurrent Neural Networks。
這篇教程將介紹使用單個(gè)雙向LSTM作為編碼器和注意解碼器。更具體地說,我們將實(shí)現(xiàn)Bahdanau等在2014年發(fā)表的Neural machine translation by jointly learning to align and translate論文中提出的模型的簡(jiǎn)化版本。我會(huì)講解部分?jǐn)?shù)學(xué),但如果你想了解細(xì)節(jié),我邀請(qǐng)你閱讀論文的附錄。
現(xiàn)在我們已經(jīng)了解了RNN這一概念,以及注意力機(jī)制背后的直覺,讓我們開始學(xué)習(xí)如何實(shí)現(xiàn)這一模型,接著取得一些漂亮的可視化結(jié)果。后續(xù)小節(jié)所有的代碼都可以在本文開頭給出的GitHub倉庫(datalogue/keras-attention)中找到,/models/NMT.py為模型的完整實(shí)現(xiàn)。
編碼器
Keras自帶了RNN(LSTM)實(shí)現(xiàn),可以通過以下方式調(diào)用:
BLSTM = Bidirectional(LSTM(encoder_units, return_sequences=True))
encoder_units參數(shù)是權(quán)重矩陣的大小。return_sequences=True表示我們需要完整的編碼序列,而不僅僅是最終總結(jié)狀態(tài)。
我們的BLSTM將接受輸入序列x=(x1,...,xT)中的字符作為輸入,并輸出編碼序列h=(h1,...,hT),其中T為日期的字符數(shù)。注意這和Bahdanau等論文有點(diǎn)不一樣,原論文中句子以單詞而不是字符為單位。我們也不像原論文那樣把編碼序列叫做注釋(annotations)。
解碼器
下面到了有趣的部分:解碼器。對(duì)序列t處的任意給定字符,解碼器接受編碼序列h=(h1,...,hT)、之前的隱藏狀態(tài)st-1(和解碼器單元共享)、字符yt-1。我們的解碼器層將輸出y=(y1,...,yT)(標(biāo)準(zhǔn)化日期中的字符)。上圖總結(jié)了我們的整體架構(gòu)。
等式
如前所示,解碼器相當(dāng)復(fù)雜。所以讓我們將它分解為嘗試預(yù)測(cè)字符t的解碼器單元執(zhí)行的步驟。在下式中,大寫字母變量表示可訓(xùn)練參數(shù)(注意,為了簡(jiǎn)明,我省去了偏置項(xiàng))。
根據(jù)編碼序列和解碼器單元的內(nèi)部隱藏狀態(tài)st-1,計(jì)算注意概率α=(α1,…,αT)。
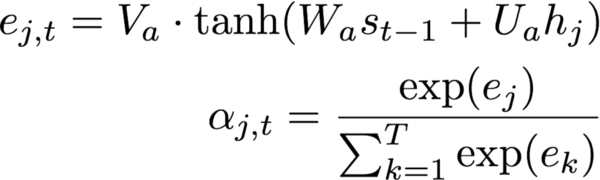
計(jì)算上下文向量,即帶關(guān)注概率的編碼序列加權(quán)和。直觀地說,這一向量總結(jié)了不同編碼字符在預(yù)測(cè)第t個(gè)字符上的作用。
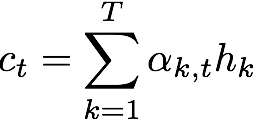
我們接著更新隱藏狀態(tài)。如果你熟悉LSTM單元的等式,這些也許會(huì)喚起你的回憶,重置門r,更新門z,以及提議狀態(tài)。st-1用于創(chuàng)建提議隱藏狀態(tài)。更新門控制在新的隱藏狀態(tài)st中包括多少提議。(沒有頭緒?看這篇逐步講解LSTM的文章)
根據(jù)上下文向量、隱藏狀態(tài)、之前字符,使用一個(gè)簡(jiǎn)單的單層神經(jīng)網(wǎng)絡(luò)計(jì)算第t個(gè)字符。相比原論文,這里做了一點(diǎn)改動(dòng),原論文用了一個(gè)maxout層。這一改動(dòng)是因?yàn)槲覀兿胍屇P捅M可能地簡(jiǎn)單。
上面的這些等式應(yīng)用于編碼序列中的每個(gè)字符,以生成解碼序列y,該序列表示每個(gè)位置出現(xiàn)某個(gè)轉(zhuǎn)譯字符的概率。
代碼
models/custom_recurrent.py實(shí)現(xiàn)了我們的定制層。這一部分比較復(fù)雜,因?yàn)槲覀冃枰獙?duì)整個(gè)編碼序列進(jìn)行處理。多思考一下能幫助你看懂代碼。我保證,如果你一邊看等式,一邊看代碼,會(huì)容易不少。
最低限度的定制Keras層需要實(shí)現(xiàn)這些方法:__init__,compute_output_shape,build,call。出于完整性考慮,我們也實(shí)現(xiàn)了get_config,這讓我們可以很容易地重新加載模型到內(nèi)存之中。此外,Keras循環(huán)層實(shí)現(xiàn)了step方法,包括單元中的所有計(jì)算。
下面我們首先分步講解下樣板代碼:
__init__是在初始化層時(shí)調(diào)用的方法。它設(shè)定將逐漸用于初始化權(quán)重、正則化、限制的函數(shù)。由于我們的層輸出是序列,我們硬編碼了self.return_sequences=True。
build是在運(yùn)行Model.compile(…)時(shí)調(diào)用的方法。由于我們的模型相當(dāng)復(fù)雜,你可以看到這里初始化了一大堆權(quán)重。self.add_weight調(diào)用自動(dòng)處理初始化權(quán)重,并將權(quán)重設(shè)為模型的可訓(xùn)練參數(shù)。下標(biāo)為a的權(quán)重用于計(jì)算上下文向量(第1步和第2步)。下標(biāo)為r、z、p的權(quán)重用于計(jì)算第3步的新隱藏狀態(tài)。最后,下標(biāo)為o的權(quán)重將計(jì)算層輸出。
我們還實(shí)現(xiàn)了一些輔助函數(shù):compute_output_shape為任意給定輸入計(jì)算輸出形狀;get_config讓我們從保存文件中加載模型(完成訓(xùn)練之后)。
現(xiàn)在讓我們來看單元邏輯:
默認(rèn)情況下,單元的每次執(zhí)行只具備上一時(shí)步的信息。由于我們需要訪問單元內(nèi)的完整編碼序列,我們需要將它保存在某處。
def call(self, x):
# 儲(chǔ)存完整序列
self.x_seq = x
# 對(duì)序列的時(shí)間維度應(yīng)用一個(gè)密集層。
# 由于它不依賴任何之前的步驟,
# 我們可以在這里應(yīng)用,以節(jié)省計(jì)算時(shí)間:
self._uxpb = _time_distributed_dense(self.x_seq, self.U_a, b=self.b_a,
input_dim=self.input_dim,
timesteps=self.timesteps,
output_dim=self.units)
return super(AttentionDecoder, self).call(x)
下面我們將講解代碼最重要的部分,執(zhí)行單元邏輯的step函數(shù)。回憶一下,step應(yīng)用于輸入序列的每個(gè)元素。
def step(self, x, states):
# 獲取上一時(shí)步的元素
ytm, stm = states
## ## ## ## ## ## ## ## ##
# 等式 1
# > 重復(fù)隱藏狀態(tài)至序列長(zhǎng)度
_stm = K.repeat(stm, self.timesteps)
# > 權(quán)重矩陣乘以
# 重復(fù)隱藏狀態(tài)
_Wxstm = K.dot(_stm, self.W_a)
# > 計(jì)算未歸一化的概率
et = K.dot(activations.tanh(_Wxstm + self._uxpb),
K.expand_dims(self.V_a))
## ## ## ## ## ## ## ## ##
# 等式 2
at = K.exp(et)
at_sum = K.sum(at, axis=1)
at_sum_repeated = K.repeat(at_sum, self.timesteps)
# 向量 (batch大小, 時(shí)步, 1)
at /= at_sum_repeated
## ## ## ## ## ## ## ## ##
# 等式 3
context = K.squeeze(
K.batch_dot(at,
self.x_seq,
axes=1),
axis=1)
# ~~~> 計(jì)算新隱藏狀態(tài)
# 等式 4 (重置門)
rt = activations.sigmoid(
K.dot(ytm, self.W_r)
+ K.dot(stm, self.U_r)
+ K.dot(context, self.C_r)
+ self.b_r)
# 等式 5 (更新門)
zt = activations.sigmoid(
K.dot(ytm, self.W_z)
+ K.dot(stm, self.U_z)
+ K.dot(context, self.C_z)
+ self.b_z)
# 等式 6 (提議狀態(tài))
s_tp = activations.tanh(
K.dot(ytm, self.W_p)
+ K.dot((rt * stm), self.U_p)
+ K.dot(context, self.C_p)
+ self.b_p)
# 等式 7 (新隱藏狀態(tài))
st = (1-zt)*stm + zt * s_tp
# 等式 8
# 出現(xiàn)每個(gè)字符的概率
yt = activations.softmax(
K.dot(ytm, self.W_o)
+ K.dot(st, self.U_o)
+ K.dot(context, self.C_o)
+ self.b_o)
# 方便我們返回
# 可視化注意的開關(guān)
if self.return_probabilities:
return at, [yt, st]
else:
return yt, [yt, st]
在這個(gè)單元中,我們想要訪問從states獲得的之前字符ytm和隱藏狀態(tài)stm(代碼第4行)。
我們?cè)诘?1-18行實(shí)現(xiàn)了等式1的一個(gè)版本,一次性計(jì)算序列中的所有字符。
在第24-28行我們以向量形式為整個(gè)序列實(shí)現(xiàn)了等式2. 使用repeat讓我們可以根據(jù)各自的總和劃分每個(gè)時(shí)步。
為了計(jì)算上下文向量,我們要記得self.x_seq和at有一個(gè)“batch維度”,因此我們需要使用batch_dot以免在那個(gè)維度上相乘。squeeze操作不過是移除殘留維度。(代碼第33-37行。)
之后的代碼是等式4-8的比較直接的實(shí)現(xiàn)。
現(xiàn)在我們需要一點(diǎn)先見之明,我們想要計(jì)算文章開頭那樣酷炫的注意映射,所以需要一個(gè)切換開關(guān)。
訓(xùn)練
數(shù)據(jù)
Faker庫可以生成虛假日期,我用這個(gè)庫生成了日期,并用Babel庫生成不同語言和格式的日期(借鑒了rasmusbergpalm/normalization的做法)。如果你想要了解細(xì)節(jié),我邀請(qǐng)你直接去看data/generate.py中的代碼(歡迎改進(jìn))。
這個(gè)腳本同時(shí)生成了轉(zhuǎn)換字符至整數(shù)的詞匯表,以便神經(jīng)網(wǎng)絡(luò)理解字符。data/reader.py腳本可以讀取數(shù)據(jù),并為神經(jīng)網(wǎng)絡(luò)準(zhǔn)備數(shù)據(jù)。
模型
如前所述,我們實(shí)現(xiàn)的模型見models/NMT.py。你可以通過python run.py運(yùn)行這個(gè)模型(我設(shè)定了一些默認(rèn)參數(shù),詳見Readme)。我建議在GPU上訓(xùn)練模型,因?yàn)樵?a target="_blank">CPU上訓(xùn)練會(huì)比較慢。
如果你想要跳過訓(xùn)練部分,那我在weights/中提供了一些權(quán)重。
可視化
visualizer.py是可視化部分的代碼,兩次加載權(quán)重:一次用于預(yù)測(cè)模型,一次用于獲取概率。
from models.NMT import simpleNMT
predictive_model = simpleNMT(...)
predictive_model.load_weights(..., return_probabilities=False)
probability_model = simpleNMT(..., return_probabilities=True)
probability_model.load_weights(...)
運(yùn)行以下命令可以查看提供的命令行選項(xiàng):
python visualizer.py -h
可視化例子
現(xiàn)在讓我們檢視下probability_model生成的關(guān)注。我們可以在y軸上看到上面的probability_model返回的轉(zhuǎn)換后日期。在x軸上則是我們的輸入日期。下圖顯示了在預(yù)測(cè)y軸上的輸出字符時(shí)用到了哪些x軸上的輸入字符。顏色越淡,字符的權(quán)重越高。
下面是一些我覺得相當(dāng)有趣的例子。
毫不在意星期幾這樣的無關(guān)信息:
下面則是一個(gè)轉(zhuǎn)換錯(cuò)誤的例子,因?yàn)槲覀兲峤坏臉颖镜捻樞虿缓铣R?guī):“January 2016 05”被轉(zhuǎn)換成“2016–01–02”,而不是“2016–01–05”。
我們可以看到,模型將2016的“20”錯(cuò)誤地解讀為幾號(hào),不過這一激活很薄弱,部分甚至和實(shí)際日期“5”的激活相當(dāng)。這給我們提供了如何更好地訓(xùn)練模型的洞見。
結(jié)語
我希望這篇教程能讓你了解如何從頭到尾求解一個(gè)機(jī)器學(xué)習(xí)問題。此外,我也希望它有助于你嘗試可視化用于seq2seq問題的循環(huán)神經(jīng)網(wǎng)絡(luò)。如果我遺漏了什么,或者你發(fā)現(xiàn)了什么可以改進(jìn)的地方,歡迎在twitter上聯(lián)系我(zafarali),或者在本文的配套代碼倉庫上提交工單。
-
編碼器
+關(guān)注
關(guān)注
45文章
3786瀏覽量
137610 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4812瀏覽量
103213 -
可視化
+關(guān)注
關(guān)注
1文章
1256瀏覽量
21734
原文標(biāo)題:可視化循環(huán)神經(jīng)網(wǎng)絡(luò)的注意力機(jī)制
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
利用Keras實(shí)現(xiàn)四種卷積神經(jīng)網(wǎng)絡(luò)(CNN)可視化
Keras可視化神經(jīng)網(wǎng)絡(luò)架構(gòu)的4種方法
keras可視化介紹
深度分析NLP中的注意力機(jī)制
如何使用多注意力長(zhǎng)短時(shí)記憶進(jìn)行實(shí)體屬性的情感分析
基于注意力機(jī)制的深度學(xué)習(xí)模型AT-DPCNN

基于通道注意力機(jī)制的SSD目標(biāo)檢測(cè)算法
LSTM和注意力機(jī)制相結(jié)合的機(jī)器學(xué)習(xí)模型

基于深度LSTM和注意力機(jī)制的金融數(shù)據(jù)預(yù)測(cè)方法

基于注意力機(jī)制等的社交網(wǎng)絡(luò)熱度預(yù)測(cè)模型
計(jì)算機(jī)視覺中的注意力機(jī)制

PyTorch教程11.4之Bahdanau注意力機(jī)制





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論