 DeepMind團隊游戲新突破,AI和人類進行組隊
DeepMind團隊游戲新突破,AI和人類進行組隊
我們還時常感嘆兩年前 AlphaGo 的一舉成名,今天Deep Mind 的另一個游戲項目獲得新的突破。不僅和人類進行一對一作戰,還可以進行團隊作戰,與人類進行組隊。
Deep Mind 在周二發表推文 “ 我們最新的工作演示了如何在一個復雜的第一人稱多人游戲中實現多人游戲的性能,甚至可以與人類隊友進行合作!”Deep Mind 開發了創新和強化學習技術,是人工智能系統在奪旗游戲中達到人類的水平,不僅各個人工智能獨立行動,同時學會配合,進行團隊戰。Deep Mind 表示這項工作凸顯了多智能體培訓對促進人工智能發展的潛力。不得不說,在看完模擬游戲的視頻確實覺得挺有意思的,今天人工智能頭條就為大家介紹這個首款具有“團隊精神” 的智能代理。
▌背景
Quake III Arena Capture the Flag——Quake III Arena 中文名稱:雷神之錘III競技場,是 1999 年在 PC 上推出的 一款FPS(第一人稱射擊類游戲)大作。Capture the flag 簡稱 CTF,CTF 在Quake 3 里分成藍紅兩邊在通常是一個對稱的(也有不對稱的)地圖中競賽。
競賽的目的是將對方的旗子帶回來,并且碰觸未被移動過的我方旗子,我隊就得一分,稱作一個 capture。一般會設定兩個要素,得分的極限以及時間極限,先到達分數極限的隊伍獲勝,若是兩隊勢均力敵而難以得分,則通常會由時間的設定來結束一個游戲(match)。在奪旗模式中,殺死對手得1分,自己非正常死亡扣1分,奪取對方旗子得3分,殺死奪旗者得2分,重新拿到己方旗子得1分,成功奪取一次旗子(將旗子送回己方基地中)得5分。
▌前言
掌握多人視頻游戲中涉及的策略,戰術理解和團隊配合一直是AI研究的關鍵性挑戰。如今,隨著強化學習的不斷發展,DeepMind 提出的的智能代理能夠在雷神之錘 III競技場奪旗游戲(Quake III Arena Capture the Flag) 中實現人類玩家的水平。
該游戲涉及復雜的多智能體環境,也是一個典型的 3D第一人稱視角的多人游戲。DeepMind 提出的智能代理展示了與人工智能體及人類玩家合作的能力。
下面我們將解讀 DeppMind 最新的這篇博文,進一步了解這個 AI 智能體背后的技術及其在游戲中的表現。
所謂的多智能體學習的設置:指的是多個單智能體必須獨立行動,并學會與其他智能體進行互動與合作。通過共適適應智能體,世界在不斷變化,因而這是一個非常困難的問題。
我們的智能代理面臨的挑戰是直接從原始像素中進行學習并產生動作,這種復雜性使得第一人稱視角的多人游戲,成為AI社區的一個碩果累累且活躍的研究領域。
在這項工作中,我們關注的游戲是 Quake III Arena(雷神之錘 III 競技場,我們從美學的角度對游戲進行部分修改,但所有游戲機制都保持不變。)Quake III Arena是現代許多第一人稱視頻游戲的基礎,并吸引了具備長期競爭力的電子競技場景。
我們訓練了一些能夠單獨學習并采取行動的智能代理,但它們必須要能夠在游戲中共同協作,以便抵御其他智能體 (不論是人工智能體還是人類游戲玩家) 的攻擊。
在這里CTF的規則很簡單,但其具有復雜的動態性。兩隊的游戲玩家要在給定的地圖上競爭,目標是在保護己方旗幟不被奪走的同時,奪取對方的旗幟。為了獲得戰術優勢,玩家可以射擊對方戰隊的玩家,并將它們送回復活點 (spawn point)。游戲時長為五分鐘,最終擁有旗幟最多的隊伍將獲勝。
從多智能代理的角度來看,CTF既要求玩家們能與己方隊友妥善合作,又要與敵方玩家相互競爭,同時還要靈活應變可能遇到的游戲風格的轉變。
為了讓這件事情更有意思,在這項工作中我們考慮CTF游戲的一種變體,其中每場游戲中的地圖布局都會發生變化。因此,我們的智能代理必須要學會一種通用的策略,而非記住某種游戲地圖的布局。此外,為了保證游戲競爭環境的公平,我們的智能體需要以與人類玩家類似的方式體驗CTF游戲世界:即通過觀察圖像的像素流,模擬游戲控制器并采取相應的行動。
▌FTW 智能體
奪旗游戲是在程序生成的不同環境中進行的,因此智能體必須能夠泛化到未知的地圖。智能體必須從零開始學習如何在未知的環境中進行觀察,行動,合作及競爭,每場游戲都是一個單獨的強化信號:他們的團隊是否獲得勝利。這是一個具有挑戰性的學習問題,其解決方案主要基于強化學習的三個基本概念:
我們不是訓練一個單獨的智能體,而是訓練一群的智能體。他們互相學習,合作,甚至競爭,彼此成為隊友或對手,以便適應多樣化的游戲方式。
智能體們都需要各自學習自身內部的獎勵信號,這將促使智能體能夠生成自身內部的目標,如奪取一面旗幟。雙重優化過程 (two-tier) 可直接優化智能體內部的獲勝獎勵,并基于內部獎勵,運用強化學習方法來進一步地學習智能體的游戲策略。
智能體分別以快速和慢速兩種時間尺度開始游戲,這有助于提高它們使用內存和生成一致動作序列的能力。
FTW(for the win) 智能體的結構示意圖
該智能體的結構結合了快速和慢速時間尺度上的循環神經網絡(Fast RNN & Slow RNN),其中包括一個共享記憶模塊,并學習從游戲點到內部的獎勵轉換。
由此產生的智能體,我們稱之為For The Win(FTW) 智能體,它學會了以非常高的標準玩CTF。更重要的是,該智能體學習到的游戲策略對地圖的大小,隊友的數量以及團隊中的其他玩家都是穩健魯棒的。
▌FTW的性能
下面演示了探索一些室外環境的游戲(其中FTW智能體互相競爭),以及一些智能體與人類玩家在室內環境中一起玩的游戲。
交互式的CTF 游戲瀏覽器,具有室內和室外的程序生成環境游戲
室外環境的游戲是 FTW 智能體之間的游戲,而室內環境下則是混合了人類玩家和 FTW 智能體的游戲。
在原文中通過6個不同場景,每個場景下3個不同角度的攝像頭為大家呈現更多的游戲過程,如果大家希望看到所有場景與角度的視頻,可以通過文章最后的原文鏈接進行查看。
我們進行了一場包括 40 名人類玩家的游戲比賽,在比賽中人類和智能體隨機配對,既有可能成為對手,也可能成為隊友。
在早前的一場 CTF 測試賽中,比賽雙方是經過訓練的智能體與人類玩家組成的隊伍
經過訓練學習,FTW 智能體已經比強大的基線方法更強大,并且超過了人類玩家的勝率。事實上,在一份對游戲參與者的調查報告中顯示它們比人類玩家更具有合作性。
智能體在訓練中的表現
FTW智能體的 Elo 評級 -- 獲勝概率超過了人類玩家和 Self-play + RS、Self-play 等基線方法。
此外,我們不僅僅只對智能體進行了性能評估,還進一步探索了這些智能體的行為及內部表征的復雜度。
▌FTW的表征
為了理解智能體內部是如何表征游戲狀態,我們觀察并在平面上繪制智能體中神經網絡的激活模式。下圖中的點表示游戲中的情形,鄰近的點表示相似的激活模式。這些點根據不同的 CTF 游戲狀態進行相應地著色,這些狀態包括:智能體在哪個房間?旗幟的狀態怎樣?可以看到哪些隊友和對手?我們觀察到同樣顏色的簇表示該智能體以相似的方式表示類似的高級游戲狀態。
智能體是如何表征游戲世界狀態?智能體將不同情況下相同的游戲狀態進行相似的表征。訓練后的智能體甚至能夠直接用一些人工神經元來編碼特定情況。
我們的智能體從未得知任何的游戲規則,卻能夠學習基本的游戲概念并有效地發展對CTF游戲的直觀認識。實際上,我們可以發現,智能體中某些特定的神經元可直接對最重要的游戲狀態進行編碼,例如當智能體的旗幟被奪走時,某個神經元就會被激活;或者當智能體的隊友奪取旗幟時,某個神經元就將被激活等。我們的論文提供了進一步的分析,涉及的內容包括智能體在游戲過程中是如何利用記憶和視覺注意力機制的。
▌FTW的行為
除了豐富的游戲狀態表征外,智能體在游戲中又是如何采取行動的呢?
首先,需要注意的是我們的智能體有非常快的反應時間及非常準確的命中率,這能解釋它們在游戲中的卓越表現。人為地減少反應時間并降低命中率后,這僅是智能體獲得成功的其中一個因素。
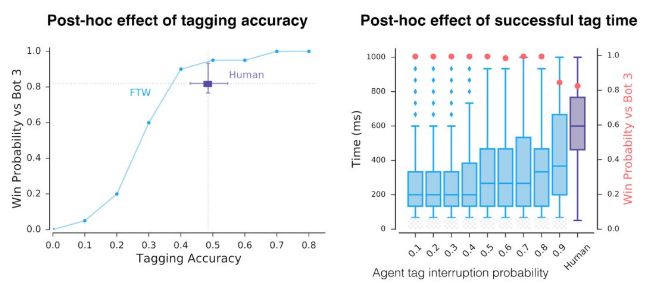
訓練后,我們人為地減少反應時間和降低命中率,智能體所取得的游戲表現。即使是與人類玩家保持相近的反應時間和準確率,我們的智能體的游戲表現也優于人類玩家。
通過無監督學習的方式,我們在智能體和人類的原型行為之間建立聯系,研究發現實際上智能體能夠學習了類似人類的行為,例如跟隨隊友并敵方的基地扎營等行為。

已訓練的智能體所展示的三個行為示例行為
在訓練過程中,這些行為是伴隨著強化學習和群體級進化而出現的。隨著智能體以更加互補的方式進行學習合作,諸如在訓練初期跟隨隊友的類似行為將逐漸變少。
FTW 智能體群體的訓練進展
左上角展示了 30 個智能體在訓練和互相演化過程中的 Elo 評級評分。右上角展示了這些演化事件的遺傳樹。底部展示了智能體訓練過程中知識、內部獎勵和行為概率的情況。
▌結束語
研究界最近在星際爭霸II 和 Dota 2這樣的復雜游戲中做了非常令人印象深刻的工作,雖然我們的研究側重于奪旗游戲,但研究貢獻是具有普遍性的,我們很高興看到其他人如何在不同的復雜環境中建立我們的技術。在未來,我們還希望進一步改進目前的強化學習和基于人口的培訓方法。總的來說,我們認為這項工作突出了多智能體培訓推動人工智能發展的潛力
-
人工智能
+關注
關注
1804文章
48717瀏覽量
246543
原文標題:DeepMind在團隊游戲領域取得新突破,AI和人類一起游戲真是越來越6了
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
DeepMind創始人預計年內有AI設計藥物進入臨床試驗
谷歌加速AI部門整合:AI Studio團隊并入DeepMind
名單公布!【書籍評測活動NO.55】AI Agent應用與項目實戰
馬斯克預言:AI將全面超越人類智力
巨人網絡發布“千影”大模型,加速“游戲+AI”布局
AI智能體逼真模擬人類行為
谷歌Vertex AI助力企業生成式AI應用
谷歌研究人員推出革命性首個AI驅動游戲引擎
戴爾重組銷售架構,成立AI新團隊
網易副總裁龐大智暢談"AI+游戲"無限潛能
平衡創新與倫理:AI時代的隱私保護和算法公平
MediaTek天璣開發者大會2024揭秘:AI Coaching游戲教學技術革新游戲體驗
谷歌AI新突破:為無聲視頻智能配音
智謀紀 AI+Multi LED 打開人類健康新寶藏






 工商網監
工商網監
評論