") 超級計算機Top 500名單的更新,美國重回算例榜首但明顯損失份額
超級計算機Top 500名單的更新,美國重回算例榜首但明顯損失份額
就在剛才,美國超算確認登頂世界第一。
北京時間 6 月 25 日下午 15:00 左右,在德國法蘭克福召開的全球超算大會(ISC2018)公布了“超級計算機500強”(TOP500)最新榜單,其中,美國超算“Summit”排名第一,中國超算“神威·太湖之光”位列第二,第三名則是來自美國的“Sierra”。
在上一屆的榜單中,中國超算“神威·太湖之光”和“天河 2 號”分別位列 TOP500 第一、第二,美國的超算“Titan”則名列第五,也是 20 年來美國首次跌出該榜單的前三名。而這一次,美國重回全球超算霸主地位。

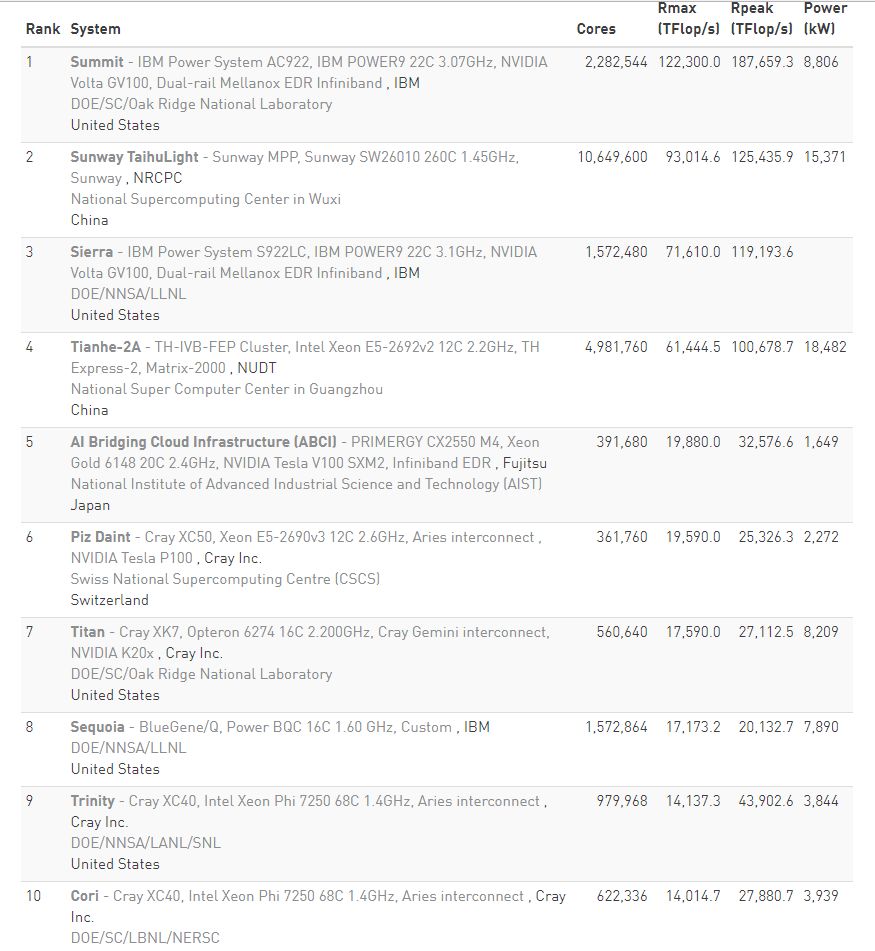
圖丨最新全球超算 TOP 500 榜單前 10 名
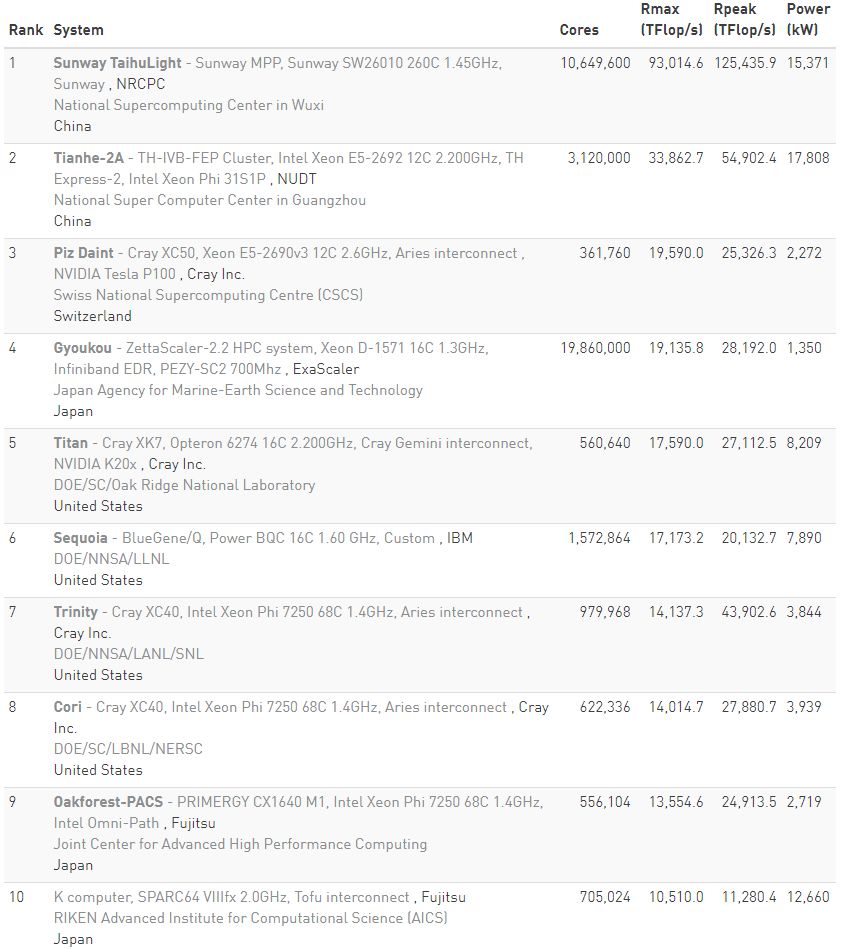
圖丨上一屆全球超算 TOP 500 榜單前 10 名
美國憑借著進入半導體產(chǎn)業(yè)早,相關技術積累深厚,多年來一直壟斷著 Top 500 超算冠軍,不僅算力高超,就連超算的數(shù)量也占據(jù)絕對優(yōu)勢,不過最近 10 年來中國超算技術奮起直追,入圍 Top 500 的超算越來越多,甚至最近 5 年 10 屆 Top 500 冠軍都是中國超算,入圍 Top 500 的超算數(shù)量也超過美國,直到美國前不久推出的 Summit 超算,才終于在算力反超中國的神威·太湖之光,成功奪回 Top 500 冠軍之位。
但除了中美以外,日本和其他國家也都積極推動超算的發(fā)展,日本最近公布的新版 Kyu 超算架構,基于 Arm 架構,其理論性能遠超太湖之光,甚至能輕松壓制美國的 Summit 超算,不過該架構仍在測試階段,還未量產(chǎn),最快也要 2018 下半年才有機會挑戰(zhàn) Top 500。
現(xiàn)在問題來了,各國在超算領域激烈競爭到底有什么意義呢? 答案是超算非常實用,但對大國來說,擁有超算帶來的軟實力、象征意義也很重要。
就實用范圍而言,超算就是什么都能算,不只能夜觀天象,揭開宇宙的奧秘,還能把天有不測的風云抓出規(guī)律,告訴我們明天出門要不要帶傘;而在基礎產(chǎn)業(yè)推動方面,比如說材料的合成、礦產(chǎn)的探勘,超算扮演著極為重要的地位,美國從石油輸入國轉而成為產(chǎn)出國部分也是超算之助;超算甚至能代替神算出生命的奧秘,解析那些藏在我們身體里面的最神秘的法則,或者是組合出全新的生命型態(tài);超算幫助我們研發(fā)新藥,代替神農(nóng)嘗百草;流行的社群網(wǎng)絡分析,從大的社會風向,到小的個人人格特征定位也是超算在行的工作;面對金融體系的科技化,網(wǎng)絡化,以及區(qū)塊鏈化,這些都需要龐大的算力在背后推動;另外,軍事與武器研發(fā)更需要超算之助。
而就象征意義而言,因為算力對于人類社會的影響越來越深,擁有足夠的算力,不只代表對整體社會的發(fā)展脈絡更能有效控制,讓國家能夠更有效率的管理與發(fā)展,讓人民更幸福,同時,算力也代表了國家所能投入的資源及技術力,某種程度上也等同于國力的展現(xiàn),而這也是各國每年都拼盡全力一較算力高低的原因之一。
Top 500名單的更新,美國重回算例榜首,但明顯損失份額
而每年固定時間都會公布排名的全球超算 Top 500 名單也已經(jīng)公布,從名單中可以看出,美國的 Summit 架構已經(jīng)確定成為今年上半年 Top 500 超算的榜首,但與此同時,中國超算的份額又再度增加,較去年底的比重增加了 0.8%,達到 41.2%,美國則是再度衰退,僅剩 24.8%。
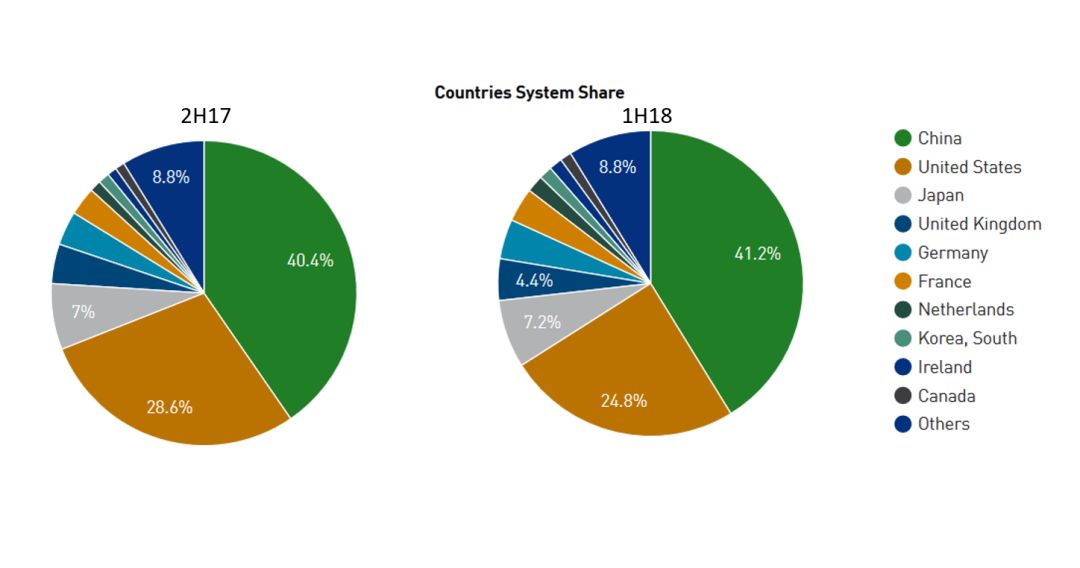
圖|雖然美國奪回超算榜首,但中國超算占 Top 500 比重達歷史新高
除了榜首的 Summit 超算以外,第三名的 Sierra 超算使用的是與 Summit 類似的 Power 架構+NVIDIA GPU,相較第二名的太湖之光,僅用了不到 1 成的核心就能輸出其 8 成的計算性能,明顯是走高能效路線。另外,日本超算幾乎清一色使用英特爾的平臺搭配 GPU 或 Xeon Phi 輔助加速器,自有架構可能要等待年底才會現(xiàn)身。
能耗是另一個值得關注的重點,Green 500 名單亦有重要意義
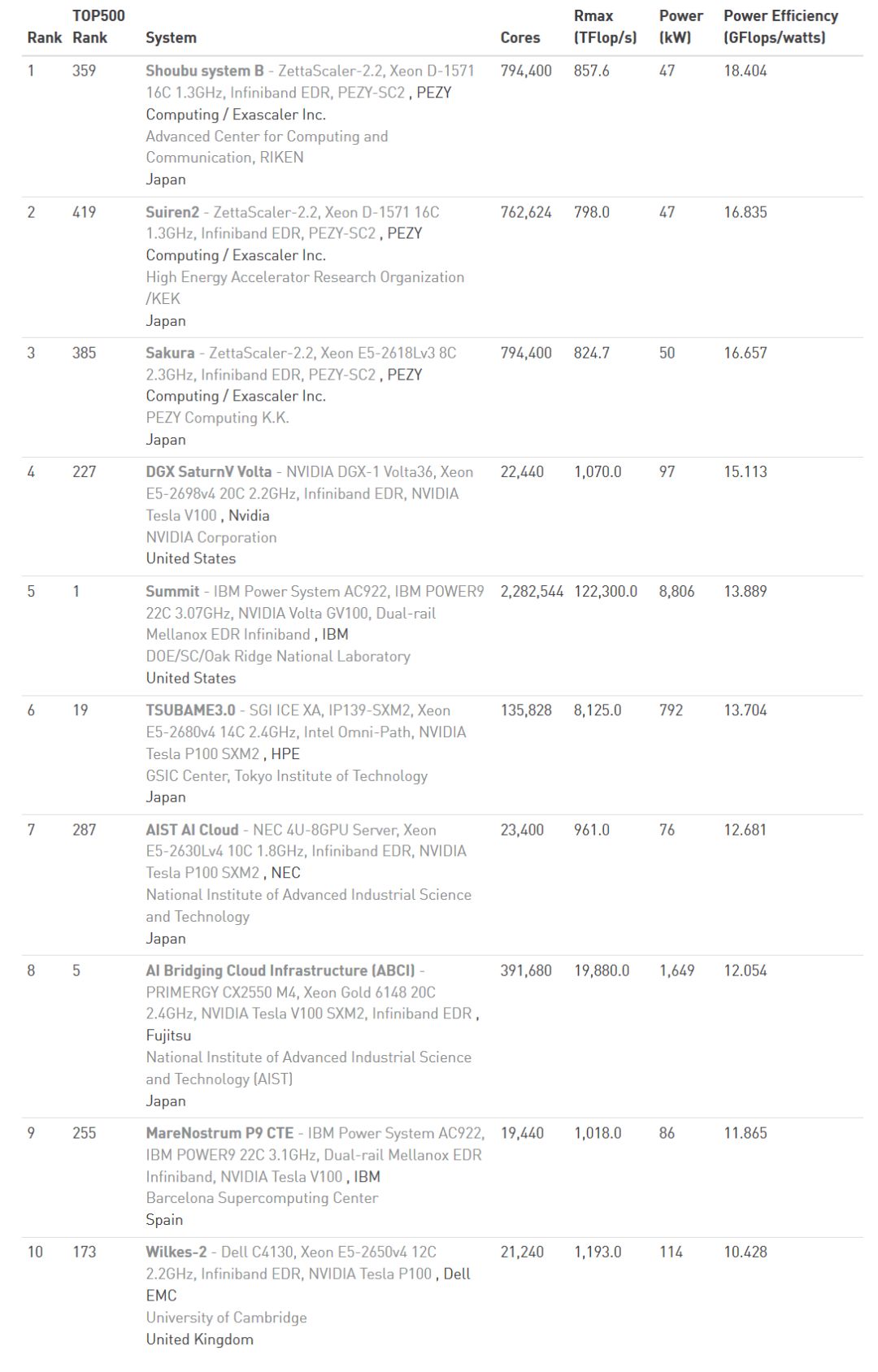
日本仍毫不意外的占據(jù)了 Green 500 前 10 大的絕對多數(shù),排名第一的 Shoubu System B 的能效表現(xiàn)已經(jīng)達到每瓦 18.4G Flops,創(chuàng)下了歷史新高。
另外,由于 Summit 超算使用基于 14nm 工藝的 Power 架構加上基于 12nm 的NVIDIA GPU,在每瓦能效表現(xiàn)方面要明顯比使用 28nm 工藝芯片的太湖之光更有優(yōu)勢,才用類似架構的第 3 名超算架構也有類似的能效表現(xiàn)。
CPU 仍是超算主角,GPU滲透率雖持續(xù)增加但挑戰(zhàn)仍大
過去很長一段時間,超算主要架構是以 RISC 芯片為主,而后轉往 X86,但隨著深度學習等 AI 計算的需求增加,GPU 在超算架構中所占的份量越來越吃重,去年底公布的 Top 500 超算中就有將近 90 款超算平臺使用 GPU 來進行加速,這些超算架構也都屬于性能領先群。
雖然 GPU 或其他計算加速架構的引入越來越多,但是純 CPU 的超算架構仍占將近 8 成,而各國在 CPU 架構的推陳出新,也證明了這個傳統(tǒng)架構在超算領域仍然還有很大的發(fā)揮空間,不僅效能不輸給 GPU 加速,甚至能耗表現(xiàn)也能有一流的表現(xiàn)。
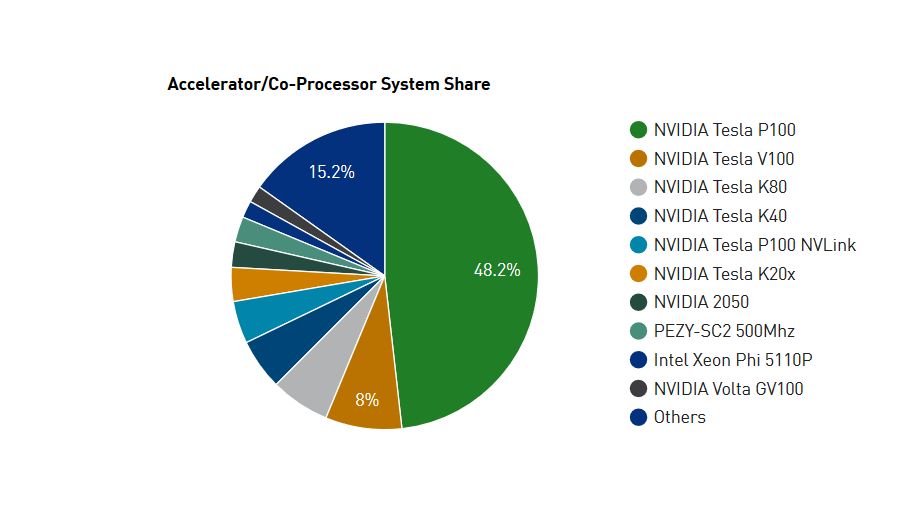
圖|在 Top 500 排名中已經(jīng)有超過98款超算采用 NVIDIA 的 GPU 架構,較 2017 年底的 87 款增加了 11 款。
雖然 GPU 已經(jīng)在很多計算領域證明了自己的價值,但是在超算平臺上,CPU 仍是絕對主流的架構,占了將近 8 成。不只是英特爾的 X86 CPU,MIPS、Arm,甚至是 Power 架構等傳統(tǒng) RISC 架構,以及中國自有的申威核心,都證明面對超算環(huán)境,也能輸出不下于 GPU 的性能,當然,應用到超算中的 CPU 架構已經(jīng)不是純粹的 CPU,更多包含了許多輔助的數(shù)學計算核心,甚至英特爾才剛推出的神經(jīng)網(wǎng)絡處理器就整合了 FPGA 架構,這些架構也都證明了自己的效能和效率都不下于 GPU,雖然 NVIDIA 的 GPU 架構在服務器當中擁有崇高的地位,但是在超算領域仍是挑戰(zhàn)者。
神威·太湖之光將退役架構改造成一流超算架構
中國的神威?太湖之光,采用了純 CPU 計算架構的組合,不使用英特爾的處理芯片,也不使用目前火熱的 GPU 計算架構,但其達到的算力卻超越除了 Summit 超算以外的其他架構的組合,不過在能耗方面略顯弱勢。
太湖之光所使用的申威 26010 在單一芯片中整合了超過 260 個核心,在整個超算系統(tǒng)中使用了 40960 顆芯片,核心數(shù)量高達 10649600 個,單純就數(shù)量而言,比上次排名第 4 的日本曉光 (Gyoukou) 超算少,但持續(xù)輸出性能遠遠超過同為中國產(chǎn)的超算平臺第 2 名天河二將近 3 倍之多,更是日本曉光超算性能的 4 倍。
圖|申威架構雖非原創(chuàng),但在研究人員的巧手下化身中國自有高效能超算核心
申威 26010 處理器架構來源是出自于已經(jīng)退出市場的 DEC Alpha 微架構,不過在經(jīng)過研發(fā)人員的徹底改造之后,轉而變成類似 IBM Power 微架構的芯片,成為針對大規(guī)模平行計算環(huán)境優(yōu)化的高效率計算架構,單芯片 260 個核心同時運作的功耗只有 15.371 W。雖然其技術出處并非原創(chuàng),但是在超算這種大規(guī)模計算環(huán)境中得以凸顯其優(yōu)勢,甚至超越了以英特爾與 NVIDIA 為主流組合的眾多超算架構。
但是申威 26010 架構因為過于特化,其單核心的效率非常低,甚至比英特爾的 Atom 和主流 Arm 架構還要低,也不適合用在主流的一般消費性計算上。其優(yōu)勢在于強大的互聯(lián)與協(xié)同工作能力,突破過去超算架構在計算芯片數(shù)量達到一定程度時,計算效能的增長就會逐步降低的傳統(tǒng)天險。
不過申威架構在太湖之中也不是完全沒有后顧之憂。目前太湖之光使用的光纖互聯(lián)技術還是來自美國,而且是屬于上一代的技術,雖然能在中國超算中發(fā)揚光大,但也代表這方面的技術還是受制于人。
MIPS 與 Arm 助力日本主打最高能效比的自有架構
從 2017 年底的 Top 500 的排名當中,我們可以看到日本的超算架構雖然性能不是最優(yōu),但是在能耗方面,前 10 大能耗比最高的超算平臺中,日本就占了 7 個,而今年 Top 500 性能排第 359 名的 Shoubu System B,在能耗排名中也高達第 1 名,相較之下,太湖之光雖然性能第 2,但能耗方面僅拿到第 23 名,換算每瓦雖然也算是很靠前的 6GFlops,但日本 Shoubu System B 則是達到每瓦 18.4GFlops 的驚人程度。
然而到 2018 上半年的排名,日本仍維持混用英特爾、NVIDIA 以及自有 PEZY 計算架構的混合計算型態(tài),雖然最佳排名是 AI Bridging Cloud Infrastructure (ABCI) 的第 5 名,性能仍然離榜首有段距離,但多款超算的能效表現(xiàn)仍成功在 Green 500 排名中的前 10 名拿下 6 個席次。
與太湖之光不同的是,日本的超算架構并沒有堅持自有路線,由 PEZY Computing 所打造的芯片架構主要還是作為輔助計算之用。最新的 SC2 整合了 2,048 個內(nèi)核以及每個內(nèi)核 8 路 SMT 支持,總共 16,384 個線程,是其前身的兩倍。PEZY-SC2 是 2017 年底幫助日本多款超算打進頂級 Green500 超算能效排名的最大背后功臣,通過 PEZY-SC2 與英特爾與 NVIDIA 芯片的混搭使用,達到更高層次的能效表現(xiàn)。

圖|以個別芯片為單位來比較,二代 PEZY 核心在互聯(lián)與功耗控制能力方面仍略勝太湖之光的申威架構一籌
日本自有的 PEZY 核心包含了 6 個 P-Class P6600 MIPS(MIPS64R6) 處理器,并擁有 128 個稱為 city 的輔助計算單元。相較之下,舊版 PEZY-SC 僅依靠 2 個輕量級的 ARM926 內(nèi)核,成為性能的最大瓶頸。SC2 擁有 40 MIB 共享最后緩存,不僅可以在所有處理核心區(qū)塊共享,還可以通過 MIPS 內(nèi)核共享。為了進一步提高性能,MIPS 內(nèi)核和 PEZY 內(nèi)核現(xiàn)在共享相同的地址空間,從而減少數(shù)據(jù)傳輸開銷。值得注意的是,通過使用功能強大的 MIPS 內(nèi)核以及異構計算核心,PEZY Computing 在與其他計算架構搭配之后,在成本與能耗方面達到世界一流水平。
雖然初代 PEZY 核心因為 Arm 架構的落后而表現(xiàn)不佳,但日本也沒有放棄 Arm 架構超算潛力的挖掘。
由富士通所推出,曾幫助日本奪得 Top 500 超算第一名的 Kyo 核心,就從 SPARC 轉向Arm 架構。前不久富士通宣佈推出自主研發(fā)的 ARMv8 SVE(可伸縮矢量擴展) 的新款 Kyo 超算芯片,使用了512bit 浮點運算單元,每個節(jié)點使用 48 核+2 輔助核,IO 及計算節(jié)點則是 48 核+4 輔助核結構。而其效能評估是目前仍佔據(jù)超算 Top 500 第 10 名的 Kyo超算的 100 倍,而功耗只增加了 3 倍。
通過新版的 Kyo 的推出,富士通可望扭轉近年日本超算核心在性能落后中美的狀況,不僅理論性能超越中國太湖之光 10 倍以上,也能壓倒美國 Summit 超算的算力表現(xiàn)。
圖|由富士通研發(fā)的新一代 Kyo 超算平臺誓言要讓日本重回 Top 500 超算榜首
IDM Power 架構協(xié)同 NVIDIA 的純美國芯重回 Top 500 榜首
帶領美國重回超算 Top 500 榜首的Summit 超算中,包括了 4,608 個服務主機,搭載了超過 9,000 個 IBM 的 22 核心 Power9 處理器和超過 27,000 個 NVIDIA Tesla V100 GPU。采用的 IBM Power 9 架構,可以說是完全針對 NVIDIA 的 GPU 架構優(yōu)化而來,其采用的 NVLINK 2.0 規(guī)格可帶來高達 300GB/s 的頻寬表現(xiàn),很大程度上解決了資料傳輸過程的瓶頸,且因為 NVLIN 支援了快取一致性設計,也同時能夠有效提升 GPU 的計算性能。
然而Power 架構的優(yōu)勢還不止于此,根據(jù)官方資料,IBM Power 9 的最大 I/O 頻寬是 Intel x86 處理器的 9.5 倍,可支援存儲器容量是 2.6 倍,高效能核心數(shù)量為 x86 的 2 倍,存儲器頻寬則是 x86 的 1.8 倍。更重要的是,通過 NVLINK 2.0,CPU 與 GPU 之間的互連頻寬達到 X86 服務器目前使用的 PCIe 3.0 的 9 倍,大大舒緩了 GPU 等待資料傳輸所造成的計算能力浪費。
圖|通過與 NVIDIA 的緊密合作,IBM 的 Power 架構在超算領域成功重奪眾人目光
Power 9 也不是指標對了 NVIDIA 的計算架構作優(yōu)化,事實上,它針對的是所有平臺,Summit 中使用的 Power9 AC922 服務器采用的是 OpenCAPI 技術。OpnCAPI 是 IBM 與 AMD、Google、Mellanox、Micron、Xilinx 等行業(yè)巨頭聯(lián)合發(fā)布一種全新的“OpenCAPI”(開放式一致性加速器界面) 標準,由此推動一致性高性能總線界面,滿足高性能異構計算的需求。
不過基于 Power 架構+NVIDIA 美國芯組合的 Summit 超算還只是剛開始,美國目前已經(jīng)決定要提高下一期先進計算領域的預算達 39%,期望能通過資本投入的增加,繼續(xù)維持其在超算地位的領先。
潛力架構:英特爾的 Nervana 平臺
雖然在此次 Top 500 名單中沒有太多表現(xiàn),但英特爾的 Nervana 在計算上的潛力仍不容忽視。
目前英特爾在超算領域其實面對的挑戰(zhàn)越來越多,不只是 IBM 的 Power 架構,中國的申威,甚至連行將就木的 MIPS 也都把英特爾的架構,而過去總被認為只能在移動計算領域的 Arm,如今也成為 Kyo 的架構核心,其能效表現(xiàn)更把目前的英特爾遠遠拋在腦后。
如果繼續(xù)維持現(xiàn)有的 CPU 計算架構,那么英特爾早晚會被超算架構所淘汰,而英特爾自然也不能夠坐以待斃。前幾年收購 Altera 與 Nervana 也將迎來開花結果。
英特爾其實鉆研專用加速計算架構已經(jīng)有相當久的歷史,其成果包含 Xeno Phi 系列,該架構采用的是龐大數(shù)量的小核心所組合起來的單一芯片架構,其實與申威、PEZY 的作法相當類似,但是成本高,而能效也沒有特別出色,導致使用率一直無法有效提高,Xeon Phi 最新架構 Lake Crest 雖然性能較就款已有成長,但相較起對手的成長幅度,已經(jīng)有明顯落后的趨勢,因此英特爾今年改端出基于與 Altera FGPA 架構作異質(zhì)整合,代號為 Spring Crest 的新一代 Nervana 神經(jīng)網(wǎng)絡處理器,根據(jù)英特爾給的數(shù)據(jù),該神經(jīng)網(wǎng)絡架構的性能已經(jīng)是 Lake Crest 架構 Xeon Phi 的 3 倍以上。
過去 Xeon Phi 在 Top 500 超算中的應用比例遠低于 NVIDIA,主要還是性能價格比較弱,及針對目前已經(jīng)成為主流的 AI 加速應用的生態(tài)完整度還是有落差,英特爾期望能通過結合 Nervana、Altera 以及既有優(yōu)勢 CPU 技術的 Spring Crest 架構,確保其在服務器領域的優(yōu)勢地位能夠維持下去。
其他挑戰(zhàn)者
當然,目前還有更多計算架構仍在發(fā)展中,比如說量子計算、光子計算,甚至是光量子計算,這種性能超越傳統(tǒng)計算從百倍到百萬倍的新架構預計也會對未來的超算架構產(chǎn)生一定的影響。
尤其是在能耗方面,傳統(tǒng)半導體架構帶來的熱和運作能耗是難以解決的問題,這也導致超算的持續(xù)運作維持成本可能要高于建構成本,若運作成本持續(xù)攀高,恐怕會限制未來超算的發(fā)展空間。而這也是超算排名有了依照絕對性能排名的 Top 500,還要另外有以能耗比例為比較基準的 Green 500 的原因。
超算競爭的背后是個別國家基礎科學發(fā)展的擘劃,但也成為推動人類成長的動力
為何發(fā)展超算如此重要?超算的性能可以衡量一個國家的技術實力,但這是個狹義的衡量標準,因為速度只是計算性能的要素之一。另一個重要元素在于軟件,軟件可以賦予計算機生命,通過軟件的發(fā)展,我們就可以把算力分散到各種產(chǎn)業(yè),協(xié)助產(chǎn)業(yè)的發(fā)展。
圖|超算代表的是一個國家對自己技術根基的投入程度,和國力的展現(xiàn)
前面也提到,目前從基礎科學、材料、生醫(yī)、金融、航天、軍事,甚至未來的宇宙理論與太空探勘發(fā)展,都需要龐大算力的支持,過去土法煉鋼,或分頭進擊的方式已經(jīng)沒有效率可言,而通過國家力量的投入,超算已經(jīng)形成未來推動人類視野發(fā)展的最大武器。
目前超算的算力競爭很多還是出自于期望借相關發(fā)展來提高對核心技術的掌握與對基礎科研的支持,從而幫助各自產(chǎn)業(yè)的發(fā)展,雖然出自私心,但其實也在相當程度上共同推動了人類社會的發(fā)展。
-
半導體產(chǎn)業(yè)
+關注
關注
6文章
510瀏覽量
34748 -
超級計算機
+關注
關注
2文章
469瀏覽量
42316 -
超算
+關注
關注
1文章
117瀏覽量
9299
原文標題:最新“全球超算500強”今宣布:美國時隔五年重奪榜首,中國位列第二!
文章出處:【微信號:Anxin-360ic,微信公眾號:芯師爺】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
NVIDIA助力全球最大量子研究超級計算機
NVIDIA 宣布推出 DGX Spark 個人 AI 計算機

NVIDIA推出個人AI超級計算機Project DIGITS
云端超級計算機使用教程
NVIDIA加速全球大多數(shù)超級計算機推動科技進步

量子計算機與普通計算機工作原理的區(qū)別
丹麥推出首臺AI超級計算機Gefion
NVIDIA助力丹麥發(fā)布首臺AI超級計算機
云端超級計算機怎么用
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
借助NVIDIA超級計算機加速量子計算發(fā)展
算力系列基礎篇——算力與計算機性能:解鎖超能力的神秘力量!

1454億元!最新全球MEMS廠商TOP 30排名公布,這5家中國公司殺入!(附全名單)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論