 利用自壓縮實現大型語言模型高效縮減
利用自壓縮實現大型語言模型高效縮減

隨著語言模型規模日益龐大,設備端推理變得越來越緩慢且耗能巨大。一個直接且效果出人意料的解決方案是剪除那些對任務貢獻甚微的完整通道(channel)。我們早期的研究提出了一種訓練階段的方法 —— 自壓縮(Self-Compression)[1, 4],它通過反向傳播自動決定每個通道的比特寬度,從而逐步“淡化”那些無用的通道。這種方法可同時減少模型參數、數值精度,甚至可調超參數的數量,而不會影響模型的預測質量。
當我們將這一想法擴展應用于 Transformer 架構 [5] 時,觀察到了一個耐人尋味的現象:當某個通道的學習精度降低至零比特,所得模型的緊湊程度甚至超過了使用固定三值編碼(ternary code)的模型。由于該方法僅作用于標準的線性層,壓縮后的網絡無需修改運行時堆棧,便可在 CPU、GPU、DSP 和 NPU 上直接獲得性能提升,從而實現一個輕量模型在多種硬件平臺上的通用部署。
在本項工作中,我們更進一步,引入了基于塊的稀疏性模式(block-based sparsity pattern)。接下來的章節將介紹如何將自壓縮機制整合進基礎模型、它所產生的權重分布模式,以及這一方法在資源受限部署環境中的潛在影響。
自壓縮大型語言模型(LLM)
我們的參考模型是 nanoGPT [2],這是一個精簡版的 GPT 變體,訓練數據集為 shakespeare_char 語料庫。該模型擁有約 1100 萬個可訓練參數,規模足夠小以實現快速運行,同時又足夠大以展現完整的 Transformer 計算模式。
該模型包含以下結構:
詞嵌入層:將每個 token 映射為一個多維向量;
6 個相同的 Transformer 塊,每個塊包括:因果型多頭注意力機制(包含輸入和輸出的線性層),層歸一化(Layer Normalisation),一個前饋模塊,內部又包含兩個線性層;
輸出部分:最后的層歸一化,一個線性層,一個 Softmax 層,用于輸出各個候選 token 的概率分布。
在 Transformer 網絡中,90% 以上的權重——也就是大部分的內存帶寬、DRAM 占用以及功耗——集中在 Transformer 塊內的四個大型線性層中。因此,在我們的實驗中,自壓縮僅針對這幾層線性層進行,其余的基準模型部分保持不變。
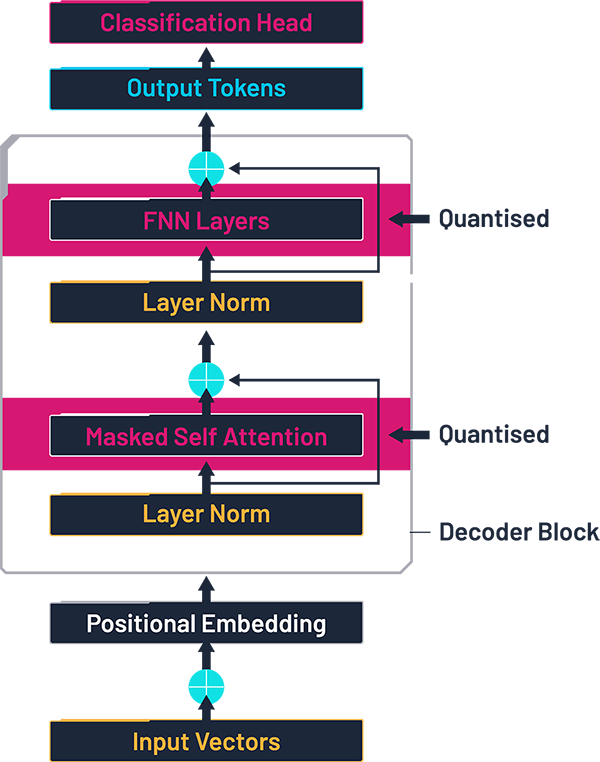
量化后的 Transformer 架構,基于文獻 [3] 中的圖示,并由作者修改。
后續章節將分析在各個塊(blocks)和通道(channels)中出現的稀疏性特征。了解哪些層最先變得稀疏,可以為我們提供有關大型語言模型(LLM)中哪些層相對不那么重要的有價值見解。這一發現可能有助于未來優化工作的定向開展,特別是在那些冗余自然積累的部分。
自壓縮的工作原理
自壓縮方法 [1, 4] 使網絡在常規神經網絡訓練過程中自主學習其通道寬度和數值精度。每個輸出通道都通過一個可微分的函數進行量化。
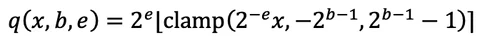
其中,比特深度 b≥0 和縮放指數 e 是可學習參數,其地位與神經網絡權重相同。我們使用直通估計器(straight-through estimator),將取整操作的導數視為 1,從而使 b 和 e 能夠接收正常的梯度。這種做法在如 PyTorch 等深度學習框架中實現起來非常簡單。
訓練過程旨在最小化原始任務損失 L(0),但我們額外引入了一個模型規模懲罰項 Q:
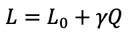
其中,Q 表示模型中每個通道平均使用的比特數,
γ 是由用戶設定的懲罰系數。
在適當選擇 γ 的情況下,該方法能夠在保留基線精度的同時顯著壓縮模型總比特數,并且整個流程仍屬于標準的訓練范式。
自壓縮后的權重表現
隨著訓練的進行,網絡中的平均比特數逐步下降,同時驗證損失也不斷降低。訓練初期,我們為每個權重分配了 4 比特,但在數百個 epoch 內,這一數值便下降了一半,最終逐漸穩定在約 每個權重 0.55 比特左右。
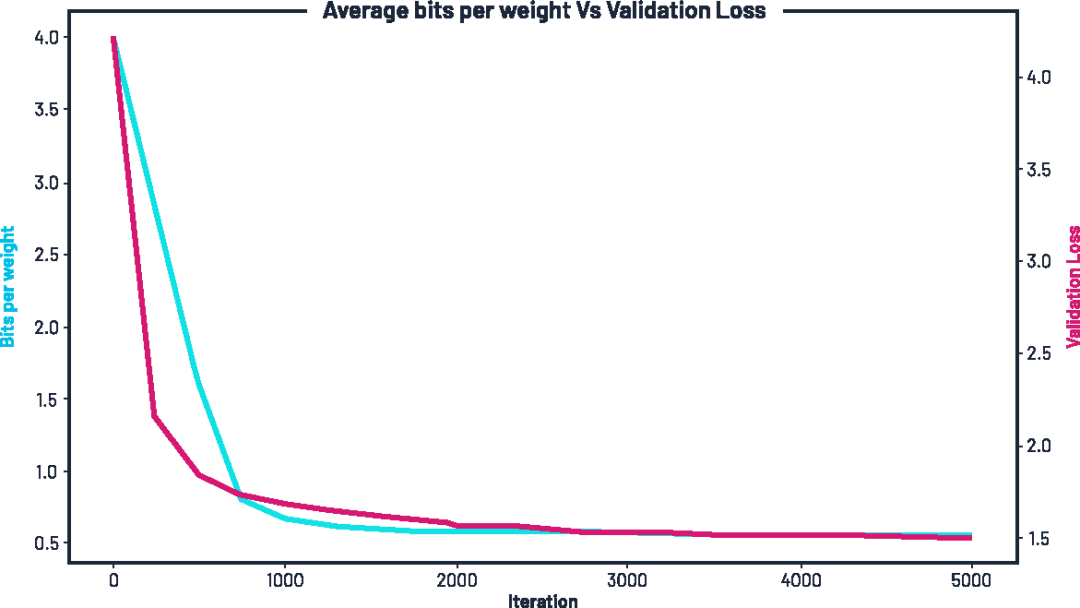
圖示:訓練過程中平均比特寬度的變化(藍色,左軸)與驗證損失(紅色,右軸),在施加壓縮懲罰項 γ 的條件下。
更有趣的現象出現在稀疏率及其隨模型深度的變化上。我們觀察到:稀疏性在模型更深層逐漸增強,這表明后期層的“信息密度”較低。在注意力模塊中,深層 block 的線性層變得極為稀疏,第 4 和第 5 個 block 中有超過 95% 的權重被移除;前饋網絡(feed-forward)中的線性層也變得非常稀疏,約有 85% 的權重被剪除;相比之下,第 0 層(最前層)保留了超過一半的權重,這可能是因為淺層在捕捉數據中的基本模式時至關重要。
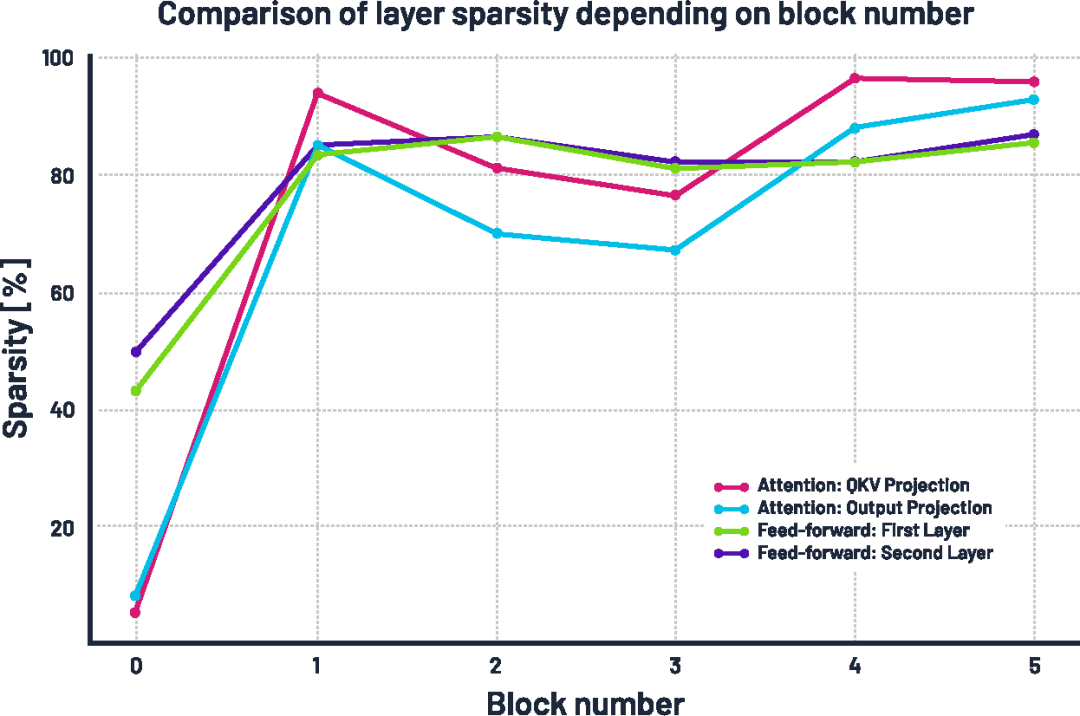
所有 Transformer 塊中各線性層的稀疏率(即被清零權重所占百分比)。
如果這一現象能夠推廣到其他語言模型和任務中,那么即使不使用自壓縮機制,也有可能通過在網絡后段減少特征維度來獲得性能收益。
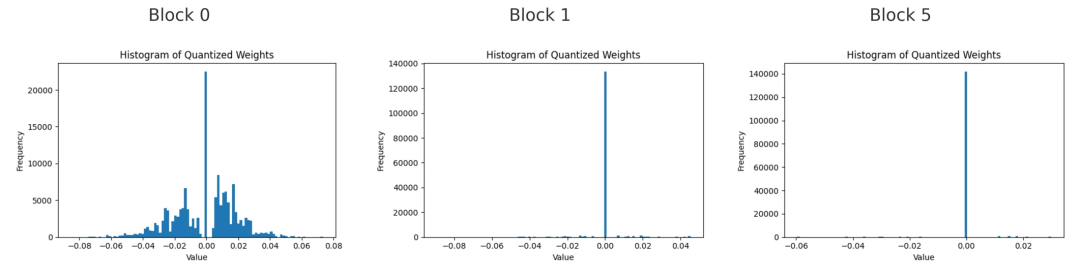
第0、1和5號塊中,第一個前饋線性層的量化權重直方圖。
當我們觀察這三個塊中權重的直方圖時,會發現非零權重主要集中在靠近零的小數值附近,尤其是在較深的塊中。這表明即使權重未被置零,模型也傾向于保持權重較小。塊越深,剩余的大權重越少。這說明模型并不會通過增大剩余權重的幅度來彌補被剪除通道的損失。
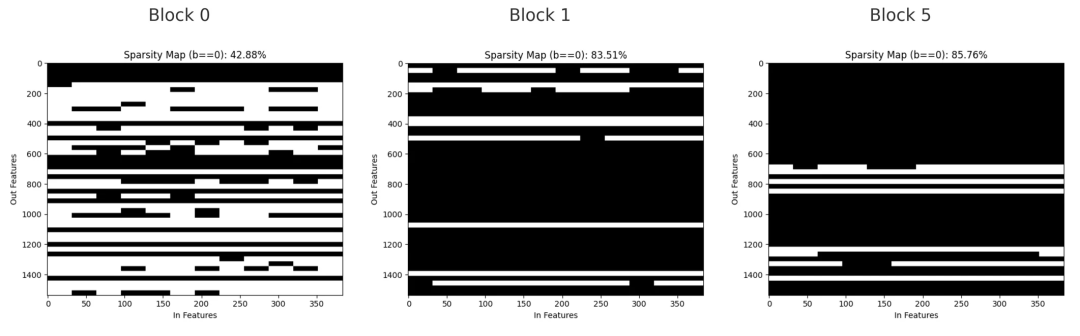
第0、1和5號塊中,第一個前饋線性層的二值掩碼圖,黑色表示被剪除的權重,白色表示保留的權重。
稀疏掩碼展示了被剪除權重的分布情況。在第0塊,剪枝較為分散,呈現小間隙和細線條狀,反映出個別通道被移除;在第1塊,較大范圍的權重被同時剪除,形成了橫向帶狀區域,顯示整個輸出通道被刪除;到第5塊時,該層大部分權重已被剪除,只剩下少數幾個通道保留。
結論
自壓縮(Self-Compression)[1, 4] 同時降低了權重的比特寬度和活躍權重數量,同時形成了易于理解且在硬件上高效利用的通道稀疏模式。淺層大多保持稠密,以保留重要信息,而深層則變得高度稀疏。剩余的少數權重保持較小且接近零。這些結果表明,自壓縮有助于構建更小、更快的模型,使其適合在資源受限的環境中運行,如邊緣設備。
本文所展示的實驗驗證了自壓縮方法能夠成功縮減 Transformer 模型(此處以在字符級莎士比亞數據集上訓練的 nanoGPT [3] 為例),且不會損害其預測質量。通過讓模型自主決定保留哪些通道和權重,該方法避免了繁瑣的手動調優,同時生成了結構清晰的塊稀疏(block-sparse)模型,便于在 CPU、GPU、NPU 及其他硬件上高效部署。這意味著同一個緊湊模型可以無須額外修改,即可在整個邊緣計算棧中通用。
未來的工作可以探索將該方法應用于更大型的語言模型、多模態 Transformer,或針對特定任務微調的模型,同時也可以嘗試將自壓縮與知識蒸餾等其他技術結合,以進一步提升效率。
關于作者
Jakub Przybyl是 Imagination Technologies 的中期實習生。他在弗羅茨瓦夫理工大學(Wroc?aw University of Science and Technology,簡稱 WUST)完成了機電一體化(Mechatronics)學士學位,同時攻讀 IT 自動化系統碩士學位,專攻人工智能方向。他的研究興趣包括機器學習、語言建模以及先進的網絡壓縮技術。
-
語言模型
+關注
關注
0文章
563瀏覽量
10823 -
LLM
+關注
關注
1文章
327瀏覽量
867
發布評論請先 登錄
大型語言模型在關鍵任務和實際應用中的挑戰
探索高效的大型語言模型!大型語言模型的高效學習方法
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】大語言模型的基礎技術
KT利用NVIDIA AI平臺訓練大型語言模型
NVIDIA AI平臺為大型語言模型帶來巨大收益
利用大語言模型做多模態任務
淺析AI大型語言模型研究的發展歷程
基于Transformer的大型語言模型(LLM)的內部機制

大型語言模型的應用
基于CPU的大型語言模型推理實驗

如何利用大型語言模型驅動的搜索為公司創造價值






 工商網監
工商網監
評論