 繼HBM之后,英偉達帶火又一AI內存模組!顛覆AI服務器與PC
繼HBM之后,英偉達帶火又一AI內存模組!顛覆AI服務器與PC

電子發燒友網綜合報道,據韓媒報道,下一代低功耗內存模塊 “SOCAMM” 市場已全面拉開帷幕。英偉達作為 AI 領域的領軍企業,計劃在今年為其 AI產品部署60至80萬個 SOCAMM 內存模塊,不僅將用于數據中心AI服務器,也將有望應用于PC。這一舉措將對內存市場以及相關產業鏈產生深遠影響。
SOCAMM
SOCAMM 全稱為 Small Outline Compression Attached Memory Module,即小型化壓縮附加內存模組,是英偉達主導開發的一種新型內存模塊,是適用于數據中心 AI 服務器的新型高性能、低功耗內存。
它將低功耗 DRAM 與壓縮連接內存模塊(CAMM)搭配使用,以全新的外形尺寸提供卓越的性能和能效。基于 LPDDR5X 芯片,采用694個I/O端口,帶寬可達傳統 DDR5 的2.5倍。
在物理形態上,SOCAMM 尺寸僅為 14×90 毫米,外形類似U盤,相比傳統 RDIMM 體積減少66%,為實現更緊湊、高效的服務器設計提供了可能。SOCAMM 采用了可拆卸的模塊化插拔結構,改變了以往 LPDDR 內存必須焊接在主板上的限制,用戶可以像更換硬盤或 SSD那樣便捷地進行內存升級或替換,大大提高了系統的靈活性和可維護性。
SOCAMM 采用引線鍵合和銅互連技術,每個模塊連接 16 個 DRAM 芯片,這種銅基結構增強了散熱性能,對于 AI 系統的性能和可靠性至關重要。同時,SOCAMM 基于成熟的封裝工藝,顯著降低了部署門檻和制造難度,具備更強的成本控制能力和更廣泛的適用范圍。
于AI服務器和PC中采用
得益于 LPDDR5X 自身的低電壓設計和優化后的封裝工藝,SOCAMM 使服務器整體運行能耗減少約 45%,這種高效能與低功耗的平衡特性,使得 SOCAMM 不僅適用于集中式的數據中心,也能很好地服務于邊緣計算場景中對空間和能耗敏感的應用需求。NVIDIA 計劃將 SOCAM 率先應用于其 AI 服務器產品和 AI PC(工作站)產品。
在英偉達的規劃中,將率先采用SOCAMM的產品將是GB300 Blackwell 平臺。Blackwell 架構 GPU 具有 2080 億個晶體管,采用專門定制的臺積電 4NP 工藝制造。所有 Blackwell 產品均采用雙倍光刻極限尺寸的裸片,通過 10 TB/s 的片間互聯技術連接成一塊統一的GPU。其在性能、效率和規模方面取得了突破性進步。而 SOCAMM 內存模塊的加入,將進一步提升其在 AI 運算方面的表現。
此外,英偉達在今年5月GTC 2025上發布的個人 AI 超級計算機 “DGX Spark” 也采用了 SOCAMM 模塊。DGX Spark 采用 NVIDIA GB10 Grace Blackwell 超級芯片,能夠提供高性能 AI 功能,并支持多達 2000 億個參數的模型。隨著DGX Spark的推出,預計將推動SOCAMM向PC市場滲透,使更多消費者受益于這一先進的內存技術。
SOCAMM 與現有的筆記本電腦 DRAM 模塊(LPCAMM)相比,其 I/O 速度提升,數據傳輸速度加快,且結構緊湊,更易于更換和擴展。
隨著 SOCAMM 在 AI 服務器和 PC 中的應用不斷增長,其大規模出貨預計將對內存和 PCB 電路板市場產生積極影響。知情人士透露,“英偉達正在與內存和電路板行業分享 SOCAMM 的部署量(60 至 80 萬片),該模塊將應用于其 AI 產品”,目前內存和 PCB 電路板行業都在為訂單和供貨積極做準備。
從內存市場來看,SOCAMM 的應用將刺激對低功耗 DRAM 的需求,推動內存廠商加大在相關技術研發和產能擴充方面的投入。由于 SOCAMM 需要適配電路板設計,這將促使 PCB 廠商開發新的產品方案,帶動行業技術升級。
美光率先供應SOCAMM
目前在內存廠商中,美光的 SOCAMM已率先獲得英偉達量產批準。美光在內存解決方案領域一直積極探索創新,成為英偉達下一代內存供應商。而三星和 SK 海力士的 SOCAMM 目前尚未獲得英偉達認證,不過這兩家內存大廠也在積極與英偉達接洽,希望能夠供應SOCAMM。
美光 SOCAMM 是業界首款專為 AI 資料中心設計的資料中心級模塊化低功耗存儲器模塊。透過將美光業界領先的 LPDDR5X 與 CAMM 存儲器模塊結合在一起,這款次世代存儲器為更有效率的 AI 資料中心奠定了基礎。

來源:美光官網
美光宣稱其最新LPDDR5X芯片能效比競爭對手高出20%,這是其贏得英偉達訂單的關鍵因素。考慮到每臺AI服務器將搭載四個SOCAMM模塊(總計256個DRAM芯片),散熱效率的重要性尤為突出。
與美光此前生產的服務器 DDR 模塊RDIMM相比,SOCAMM的尺寸和功耗減少了三分之一,帶寬增加了 2.5 倍。
通過采用美光LPDDR5X 等創新型低功耗(LP)存儲器架構,資料中心可以大幅提高效能,并能夠避免傳統 DDR5 存儲器的能源損耗。與 DDR5 等傳統存儲器技術不同,LP 存儲器運行于較低的電壓,并通過減少功耗、降低發熱量、最佳化以節能為重點的電路設計等方式提高功耗和能源效率。
在大規模客戶支持環境中執行推理 Llama 3 70B,單個 GPU 管理復雜的AI互動,同時實時處理數千個錯綜復雜的客戶查詢。LP 存儲器的使用將這一密集型運算工作量轉化為能源效率更高的過程。
當我們測試 LPDDR5X 存儲器(在搭載 NVLink 的 NVIDIA GH200 Grace Hopper 超級芯片上)與傳統 DDR5 存儲器(在搭載 PCIe 連線 Hopper GPU 的 x86 系統上)時,結果表明 LP 存儲器實現了關鍵的效能提升。使用 Meta Llama 3 70B 測試推理效能時,LP 存儲器系統推理吞吐量提高了 5 倍、延遲減少了近 80%、能源消耗降低了 73%。
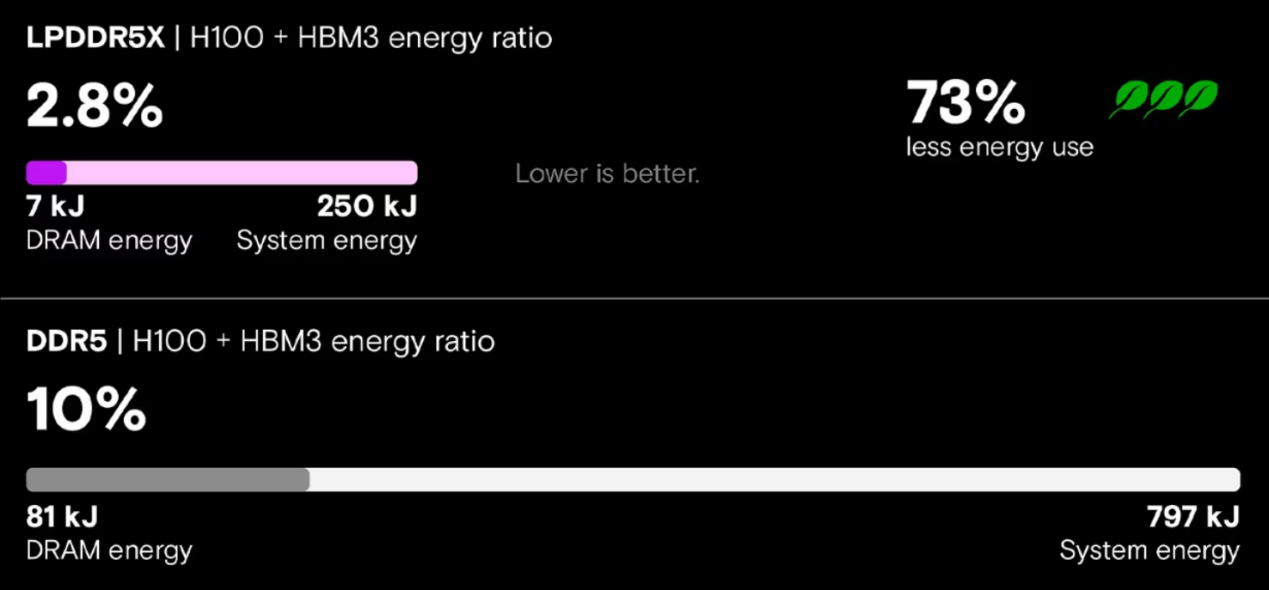
LLM 推理的能源效率 來源:美光官網
小結:
隨著英偉達對 SOCAMM 內存模塊的大規模部署,以及其在 AI 服務器和 PC 市場的逐步滲透,將推動整個 AI 產業鏈圍繞這一新型內存技術進行升級和發展。無論是內存廠商、PCB電路板廠商,還是服務器制造商和終端用戶,都將受益于SOCAMM帶來的影響。
發布評論請先 登錄






 工商網監
工商網監
評論