") 使用NVIDIA GPU加速Apache Spark中Parquet數(shù)據(jù)掃描
使用NVIDIA GPU加速Apache Spark中Parquet數(shù)據(jù)掃描

隨著各行各業(yè)的企業(yè)數(shù)據(jù)規(guī)模不斷增長,Apache Parquet 已經(jīng)成為了一種主流數(shù)據(jù)存儲格式。Apache Parquet 是一種列式存儲格式,專為高效的大規(guī)模數(shù)據(jù)處理而設(shè)計。它按列而非按行的方式組織數(shù)據(jù),這使得 Parquet 在查詢時僅讀取所需的列,而無需掃描整行數(shù)據(jù),即可實現(xiàn)高性能的查詢和分析。高效的數(shù)據(jù)布局使 Parquet 在現(xiàn)代分析生態(tài)系統(tǒng)中成為了受歡迎的選擇,尤其是在 Apache Spark 工作負載中。
適用于 Apache Spark 的 RAPIDS 加速器基于 cuDF 構(gòu)建,支持 Parquet 數(shù)據(jù)格式,可在 GPU 上加速讀取和寫入數(shù)據(jù)。對于許多輸入數(shù)據(jù)量達到 TB 級別的大規(guī)模 Spark 工作負載而言,高效的 Parquet 掃描對于實現(xiàn)良好的運行時性能至關(guān)重要。
本文將討論如何緩解因較高的寄存器使用率導致的占用限制問題,并分享基準測試結(jié)果。
Apache Parquet 數(shù)據(jù)格式
Parquet 文件格式采用列式存儲結(jié)構(gòu),通過將列線程塊組裝成行組來實現(xiàn)數(shù)據(jù)存儲。其中元數(shù)據(jù)不同于數(shù)據(jù),可以根據(jù)需要拆分到多個文件中(如圖 1 所示)。
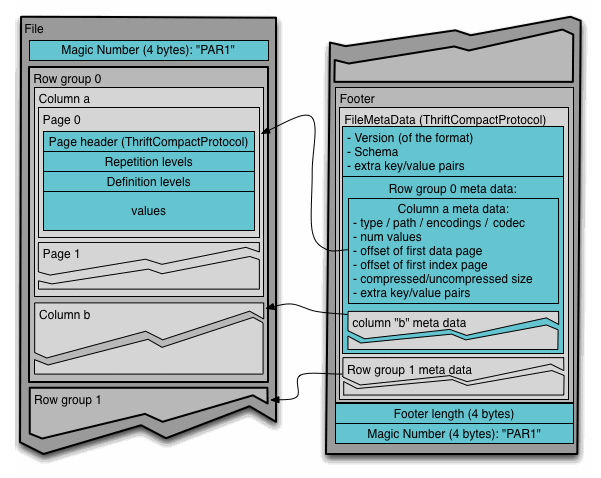
圖 1. Parquet 文件格式(來源:文件格式)
Parquet 格式支持多種數(shù)據(jù)類型。元數(shù)據(jù)規(guī)定了該如何解釋這些數(shù)據(jù)類型,從而能夠支持更復雜的邏輯類型表示,比如時間戳、字符串、小數(shù)等等。
元數(shù)據(jù)還可以用于說明更復雜的結(jié)構(gòu),如嵌套類型和列表。數(shù)據(jù)可以用多種不同的格式進行編碼,例如普通值、字典編碼、行程長度編碼、位打包(bit-packing)等等。
GPU 上 Parquet 的占用限制
在適用于 Apache Spark 的 RAPIDS 加速器之前,Parquet 掃描是通過一個單一 cuDF 內(nèi)核實現(xiàn)的,它在一組處理代碼中支持所有 Parquet 列類型。
使用 Parquet 數(shù)據(jù)的客戶越來越多地在 GPU 上采用 Spark。鑒于 Parquet 掃描對性能有關(guān)鍵影響,人們投入了更多時間來了解其性能特征。以下是幾個會影響內(nèi)核運行效率的常見因素:
流式多處理器(SM):GPU 的主要處理單元,負責執(zhí)行計算任務(wù)。
共享內(nèi)存:GPU 上集成的內(nèi)存,按線程塊分配,同一線程塊中的所有線程都可以訪問相同的共享內(nèi)存。
寄存器:GPU 上集成的快速內(nèi)存,存儲單個線程使用的信息,用于流式多處理器執(zhí)行的計算操作。
我們在分析 Parquet 掃描時發(fā)現(xiàn),由于遇到寄存器限制,GPU 的總體占用率低于預(yù)期。寄存器的使用情況,取決于 CUDA 編譯器如何根據(jù)內(nèi)核邏輯和數(shù)據(jù)管理來生成代碼。
對于 Parquet 單內(nèi)核而言,支持所有列類型的復雜性導致了內(nèi)核龐大且復雜,其共享內(nèi)存和寄存器使用率都很高。盡管單一內(nèi)核可能將代碼整合在了一起,但其復雜性限制了可能的優(yōu)化類型,并在大規(guī)模應(yīng)用時導致了性能受限。
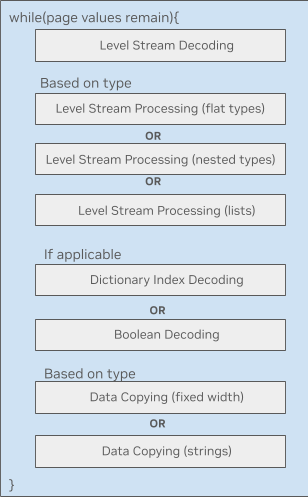
圖 2. GPU 上的 Parquet 單內(nèi)核
圖 2 展示了 GPU 上的 Parquet 數(shù)據(jù)處理循環(huán)。每個模塊都是大量復雜的內(nèi)核代碼,可能都有各自的共享內(nèi)存需求。許多線程塊依賴于數(shù)據(jù)類型,這導致加載到內(nèi)存中的內(nèi)核變得極為臃腫。
具體而言,其中一個限制在于 Parquet 塊在線程束(warp)內(nèi)的解碼方式。線程束在處理自身線程塊前,需要按順序等待先前調(diào)度的線程束完成操作。這種機制雖然允許不同線程束并行處理解碼過程的不同階段,但卻造成了 GPU 上引入了低效的任務(wù)依賴關(guān)系,導致效率低下。
轉(zhuǎn)向采用塊級解碼算法對提升性能至關(guān)重要,但由于其增加了數(shù)據(jù)共享和同步的復雜性,可能會進一步增加寄存器數(shù)量并限制占用率。
cuDF 中的 Parquet 微內(nèi)核
為了緩解因寄存器使用率較高而導致的占用受限問題,最初嘗試的方法是為 Parquet 中的預(yù)處理列表類型數(shù)據(jù)創(chuàng)建一個較小的內(nèi)核。從單內(nèi)核中分離出一段代碼,形成一個獨立的內(nèi)核,結(jié)果令人振奮——基準測試的整體結(jié)果顯示運行時間更快,并且 GPU 跟蹤數(shù)據(jù)也表明占用率有所提高。
隨后對不同的列類型也采用了相同的方法。針對各種數(shù)據(jù)類型的微內(nèi)核使用 C++ 模板來實現(xiàn)功能復用,這簡化了每種類型的代碼維護和調(diào)試工作。

圖 3. GPU 上的 Parquet 微內(nèi)核方法
Parquet 微內(nèi)核方法充分利用編譯時優(yōu)化,僅執(zhí)行處理給定類型所需的代碼路徑。與包含所有可能代碼路徑的單一內(nèi)核不同,該方法可以生成許多單獨的微內(nèi)核,而每個微內(nèi)核僅包含該路徑所需的代碼。
這一過程可以通過在編譯時使用 if constexpr 來實現(xiàn)。這樣一來,使得代碼保持自然可讀的結(jié)構(gòu),但不會包含特定數(shù)據(jù)屬性組合(字符串或固定寬度、有列表或無列表等)永遠不會執(zhí)行的代碼路徑。
以下是一個處理固定寬度類型列的簡單示例。可以看到,在新的微內(nèi)核方法中,大部分不必要的處理步驟都被跳過了。這種數(shù)據(jù)類型只需要復制數(shù)據(jù)。
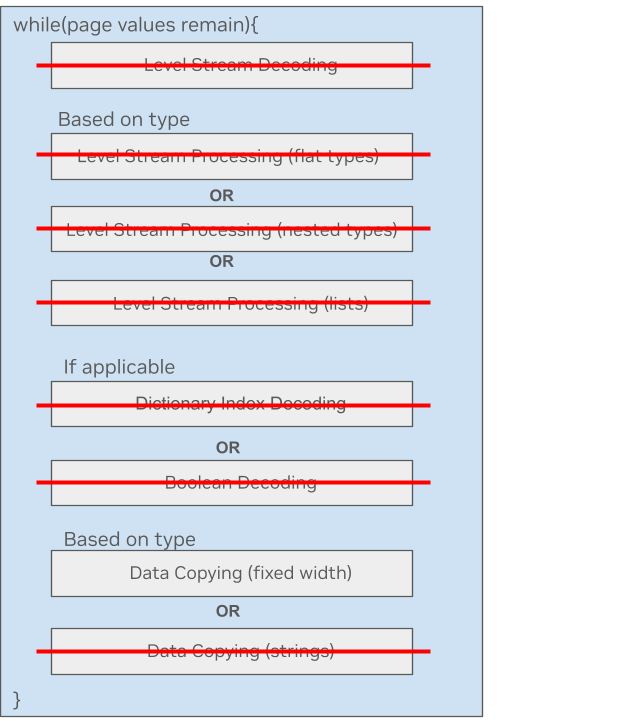
圖 4.固定寬度類型的 Parquet 微內(nèi)核方法
為了解決線程束之間的瓶頸問題,新的微內(nèi)核使每個步驟都能處理整個線程塊,使得線程束可以更高效地獨立處理數(shù)據(jù)。這對于字符串處理尤為重要,它使得 GPU 上包含 128 個線程的完整線程塊都能用于復制字符串,而之前的實現(xiàn)方式僅使用一個線程束來復制字符串。
在使用了一塊具有 24 GB GPU 顯存的 NVIDIA RTX A5000 顯卡的本地基準測試中,設(shè)備緩沖區(qū)中預(yù)先加載了 512MB 使用 Snappy 壓縮的 Parquet 數(shù)據(jù)。為了測試分塊讀取,每次讀取 500-KB 的塊。測試數(shù)據(jù)包含以下幾種變化:
基數(shù)為 0 和 1000
運行長度為 1 和 32
1% 的空值
如果數(shù)據(jù)有重復,則使用自適應(yīng)字典編碼
圖 5 展示了在 GPU 上使用新的微內(nèi)核方法后,不同 Parquet 列類型在吞吐量方面的提升情況。
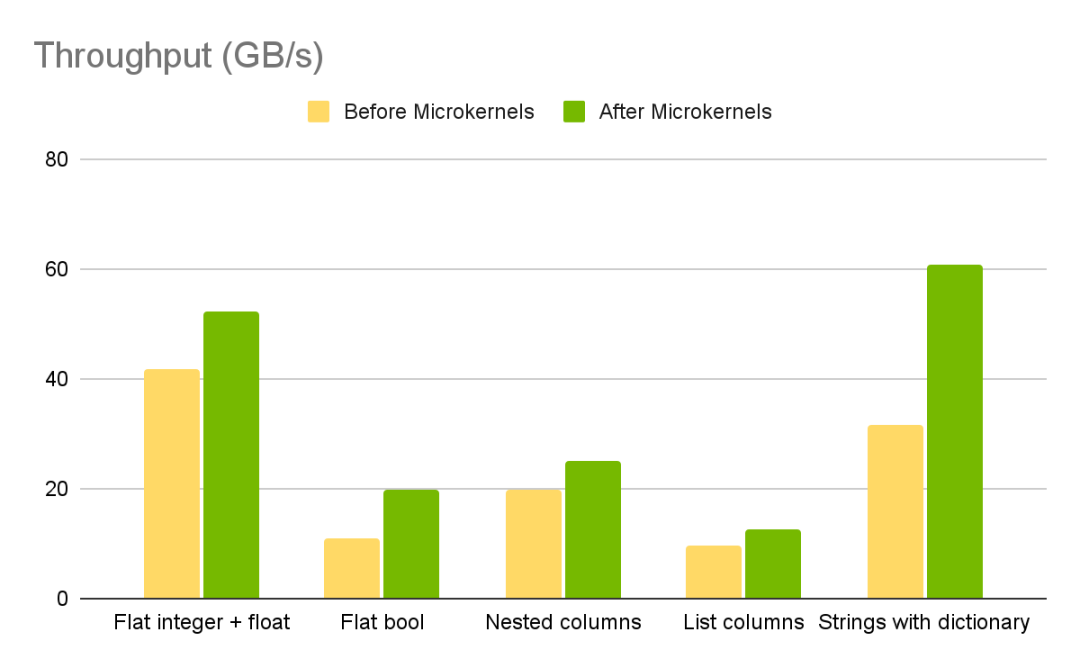
圖 5. GPU 上使用 Parquet 微內(nèi)核方法的吞吐量提升
對列表列分塊讀取的優(yōu)化還使 500-KB 讀取的吞吐量提高了 117%。
在 GPU 上開始使用 Apache Spark
Parquet 是一種廣泛用于大數(shù)據(jù)處理的關(guān)鍵數(shù)據(jù)格式。通過使用 cuDF 中經(jīng)過優(yōu)化的微內(nèi)核,GPU 可以加速在 Apache Spark 中掃描 Parquet 數(shù)據(jù)的進程。
企業(yè)可以利用適用于 Apache Spark 的 RAPIDS 加速器,將 Apache Spark 工作負載無縫遷移到 NVIDIA GPU。適用于 Apache Spark 的 RAPIDS 加速器結(jié)合了 RAPIDS cuDF 庫的強大功能和 Spark 分布式計算框架的規(guī)模,利用 GPU 加速處理。通過使用適用于 Apache Spark 的 RAPIDS 加速器插件 JAR 文件啟動 Spark,無需更改代碼即可在 GPU 上運行現(xiàn)有的 Apache Spark 應(yīng)用程序。
-
加速器
+關(guān)注
關(guān)注
2文章
828瀏覽量
39149 -
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7259瀏覽量
92018 -
gpu
+關(guān)注
關(guān)注
28文章
4955瀏覽量
131398
原文標題:使用 GPU 加速 Apache Spark 上的 Apache Parquet 掃描
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
RDMA技術(shù)在Apache Spark中的應(yīng)用

《CST Studio Suite 2024 GPU加速計算指南》
如何使用Apache Spark 2.0
Apache Spark 1.6預(yù)覽版新特性展示
NVIDIA為全球領(lǐng)先的數(shù)據(jù)分析平臺Apache Spark提速
Apache Spark 3.2有哪些新特性
NVIDIA RAPIDS加速器可將工作分配集群中各節(jié)點
利用Apache Spark和RAPIDS Apache加速Spark實踐
使用Apache Spark和NVIDIA GPU加速深度學習
NVIDIA TensorRT與Apache Beam SDK的集成
NVIDIA加速的Apache Spark助力企業(yè)節(jié)省大量成本






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論