 進迭時空同構融合RISC-V AI CPU的Triton算子編譯器實踐
進迭時空同構融合RISC-V AI CPU的Triton算子編譯器實踐

Triton是由OpenAI開發的一個開源編程語言和編譯器,旨在簡化高性能GPU內核的編寫。它提供了類似Python的語法,并通過高級抽象降低了 GPU 編程的復雜性,同時保持了高性能。目前Pytorch已能做到100%替換CUDA,國內也有智源研究院主導的FlagGems通用算子庫試圖構建起不依賴CUDA的AI計算生態,截至今日,FlagGems已進入Pytorch基金會生態項目體系。Triton生態內少有CPU架構的實踐,且多面向Host-Device的異構方案,進迭時空通過同構融合RISC-V AI CPU技術,結合Triton輕量化的交互式編程模式,將構建起比肩Triton GPGPU的AI高性能編程方案,從而推動AI應用的快速規模化落地。
為什么是Triton
▲
AI高性能編程模型趨于統一,多核并行的調度+Tile base的kernel基本成為固定范式。
▲
CUDA的話語權過高,為走出新AI架構的路,需要有獨立的前端編程語言支撐,而Triton DSL的社區活躍度足夠高,也有相當數量的大模型、CNN模型項目采用了Triton作為算子編程語言。
▲
Pytorch的成功表明,Python First讓更多開發者參與生態共建,降低介入門檻,也有利于新AI架構輸出自己的性能優化方案。
同構融合AI
常見的Host-Device的異構Triton方案,使得Triton算子編程的調試困難,內存模型復雜,不利于開發者靈活的實現自己的想法,而搭建于傳統CPU之上的Triton-CPU方案,也缺乏在AI高性能計算上的硬件支持,例如核內TensorCore、多核通信與訪存優化、多卡互聯等。
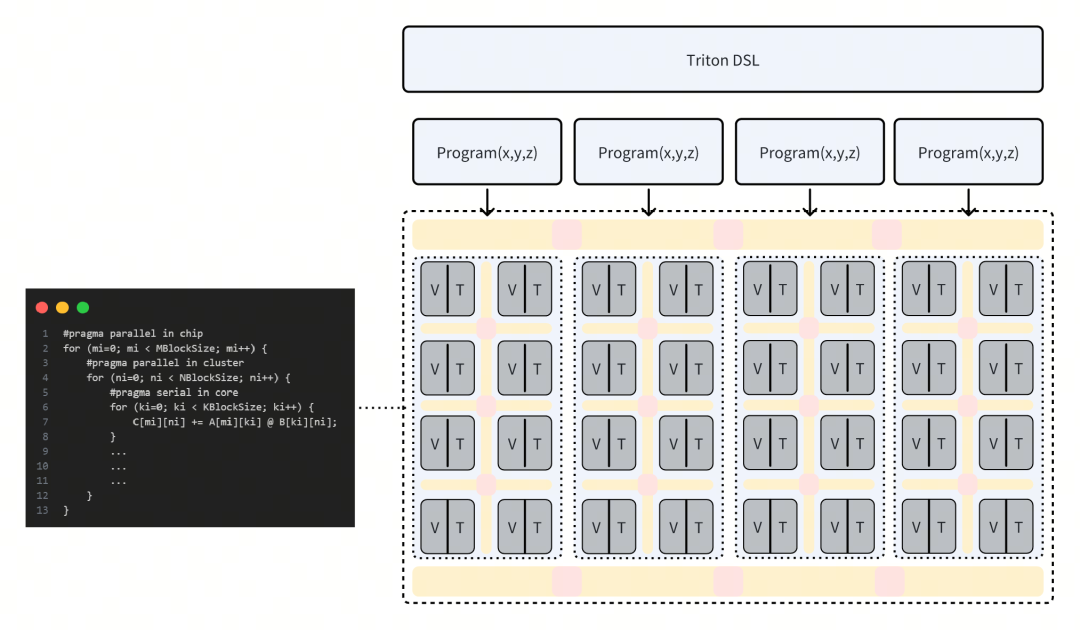
進迭時空踐行的同構融合技術,創新性地在CPU內集成TensorCore,以RISC-V指令集為統一的軟硬件接口,驅動Scalar標量算力、Vector向量算力和 Matrix AI算力,支持軟件和AI模型同時在RISC-V AI核上運行,并通過程序正常跳轉實現軟件和AI模型之間的事件和數據交互,進而完成整個AI應用執行。
基于同構融合RISC-V AI CPU架構的Triton方案,在編程調試視角看仍然類似于傳統CPU,并且消除了Host-Device的概念,采用統一內存,調用側與執行側是Linux軟件多線程的概念,這將極大的降低高性能算子的編程與調試難度。同時,在確保編程易用性的前提下,進迭時空通過集成TensorCore、緊密耦合內存、Core-to-Core coherence、Cluster-to-Cluster coherence、多核調度優化、AI編譯器優化等軟硬件創新,處理絕大部分性能優化點,最終交給用戶一個上手即用的算子開發工具鏈。
RISC-V AI CPU Triton軟件棧
前端層面,支持Pytorch Triton Kernel以及第三方Triton Kernel,例如FlagGems,支持Triton DSL的全部語義。
中端層面,通過TTIR、TTSIR(Triton Shared)至標準Linag IR,不做任何Dialect擴展。
后端層面,先驗調優的矩陣乘kernel與vector.contract并存,保證矩陣計算高效的同時,釋放更多vector codegen的可能性。
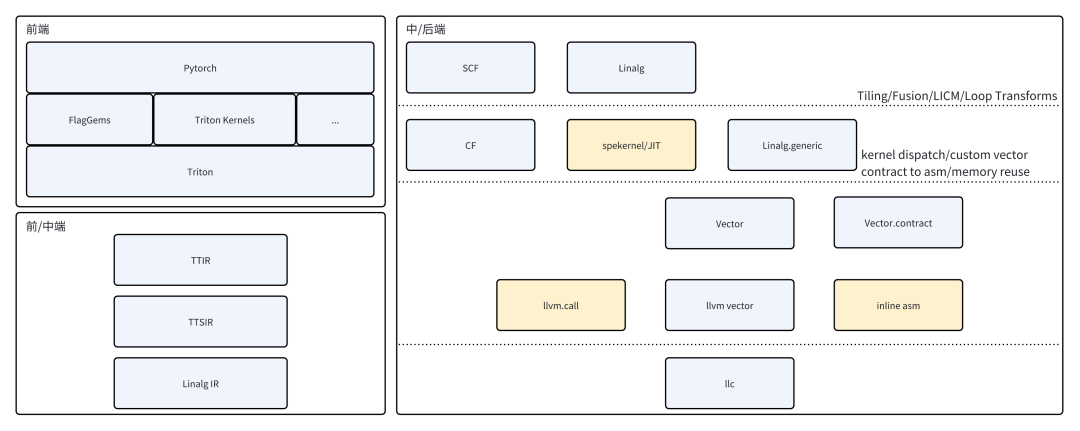
SpineTriton(即進迭時空Triton解決方案)作為Triton的第三方后端,對Pytorch提供RISCV AI-CPU底層加速,兼容社區已有的Triton Kernel,充分融入現有基于Triton構建的AI加速生態。同時,針對AI-CPU核內擴展指令、Core-to-Core高速緩存、異步訪存等特性,對tl.make_block_ptr進行了專門特化,開發者在使用Triton DSL中的塊級訪存與計算時,獲得更大的優化收益。
RISC-V AI CPU Triton實踐
前端
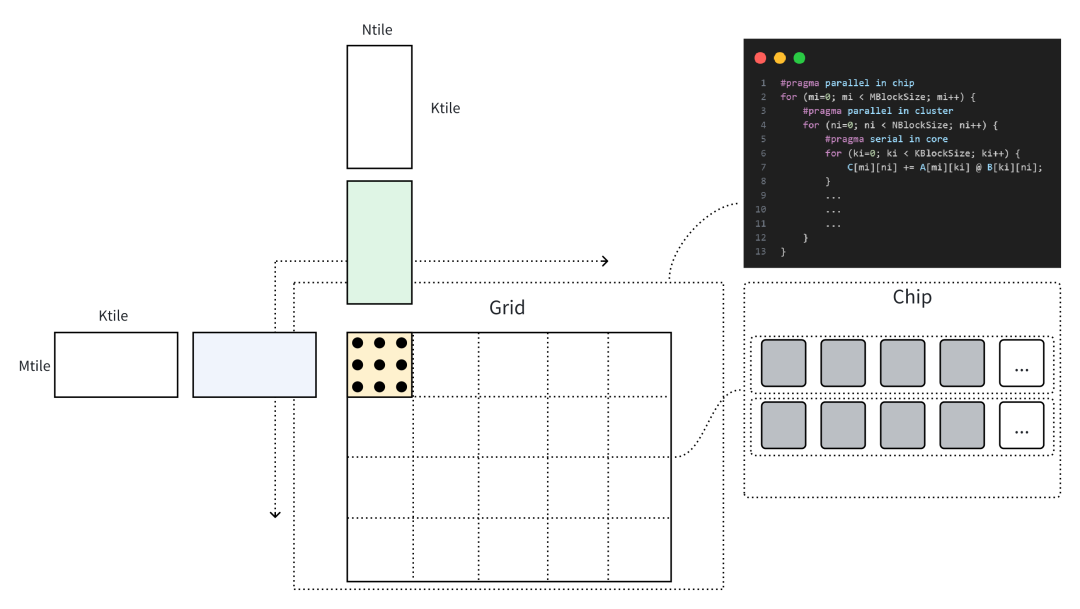
以一個矩陣乘的Triton Kernel為例,使用tl.make_block_ptr進行訪存與計算。
pid_m = tl.program_id(0)pid_n = tl.program_id(1)# load matmul a and ba_block_ptr = tl.make_block_ptr( base=a_ptr, shape=[M, K], strides=[stride_am, stride_ak], offsets=[pid_m * BLOCK_SIZE_M, 0], block_shape=[BLOCK_SIZE_M, BLOCK_SIZE_K], order=[1, 0])b_block_ptr = ...accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)for k in range(0, tl.cdiv(K, BLOCK_SIZE_K)): a = tl.load(a_block_ptr, boundary_check=(0, 1)) b = tl.load(b_block_ptr, boundary_check=(0, 1)) accumulator += tl.dot(a, b, allow_tf32=False) a_block_ptr = tl.advance(a_block_ptr, (0, BLOCK_SIZE_K)) b_block_ptr = tl.advance(b_block_ptr, (BLOCK_SIZE_K, 0))c = accumulator.to(dot_out_dtype)# maybe some epilogue for cc_block_ptr = tl.make_block_ptr( base=c_ptr, shape=[M, N], strides=[stride_cm, stride_cn], offsets=[pid_m * BLOCK_SIZE_M, pid_n * BLOCK_SIZE_N], block_shape=[BLOCK_SIZE_M, BLOCK_SIZE_N], order=[1, 0],)tl.store(c_block_ptr, c, boundary_check=(0, 1))
上文Triton Kernel描述的矩陣乘計算對應于下圖計算過程,當以一個Cluster進行捆綁調度時,SPMD中的Single Program指向一個Cluster上的執行程序,通過Program ID區分輸入與輸出數據位置。以開發者的視角看,Cluster上的編程是線性的,且不需要關心異步數據的訪問邏輯,后端編譯器將分析用戶代碼邏輯的潛在并行性,在Cluster內完成并行化,以及使用高速緩存合并Cluster內多核的訪存。
中后端
在矩陣乘內部計算過程的轉換時,將完整的tl.dot即linalg.matmul進行分塊分析,充分使用寄存器資源與近核緩存,在中端轉為linalg.mmt4d、linalg.pack、linalg.unpack及結構化循環體的表示。linalg.mmt4d與手寫kernel直接映射并利用到Tensor算力,而其他的算子,則采用affine進行向量化使用Vector算力。
由于采用了IME的方式擴展AI指令(參考進迭時空AI擴展指令Spec,https://github.com/spacemit-com/riscv-ime-extension-spec),在linalg.mmt4d這樣的ukernel的轉換過程時,可以直接使用vector進行交互,避免在延遲更高的存儲結構上進行交互,這是IME的一大優點。
// load b// %acc: vector<16x32xf32>%0 = vector.load [...] : memref, vector<4x32xf32>// load a%1 = vector.load [...] : memref, vector<2x32xf32>// vfmadot -> 2x8x4 @ 4x8x4 => 2x4x8x8%2 = vector.contract {...} %1, %0, %acc : vector<2x32xf32>, vector<4x32xf32> into vector<16x32xf32>
在mlir-llvm的結合部分,通過vector.contract構造了大量先驗的手寫匯編序列,以確保最終性能的可靠性。
結束語
Triton目前仍然是一個GPGPU架構主導的Python DSL及算子編譯器,在CPU架構上發展緩慢,僅存在一些在x86架構下的TritonCPU編程的社區工作,且不是最優適配。RISC-V同構融合AI算力的方式,利于打破算子內多種計算模式(Scalar、Vector、Tensor)的隔閡,同時統一內存、統一OS的軟硬件架構,使得調試難度降低,系統內多種軟硬件資源的交互難度降低。此外,未來也將逐步開源SpineTriton的軟件棧部分,共同建設RISCV Triton高性能編程社區。
-
gpu
+關注
關注
28文章
4943瀏覽量
131209 -
編譯器
+關注
關注
1文章
1662瀏覽量
50203 -
RISC-V
+關注
關注
46文章
2562瀏覽量
48788
發布評論請先 登錄
RISC-V架構下AI融合算力及其軟件棧實踐

高校賽事 | 進迭時空攜手藍橋杯,誠邀全國高校學子共啟RISC-V人工智能應用創新賽道
大象機器人攜手進迭時空推出 RISC-V 全棧開源六軸機械臂產品
大象機器人×進迭時空聯合發布全球首款RISC-V全棧開源小六軸機械臂

香蕉派 BPI-CM6 工業級核心板采用進迭時空K1 8核 RISC-V 芯片開發
RISC-V+OpenHarmony5.0:進迭時空與中科院共筑數字世界新基石
進迭時空完成A+輪數億元融資 加速RISC-V AI CPU產品迭代
進迭時空亮相RISC-V產業發展大會:新AI CPU引領大模型時代

Triton編譯器功能介紹 Triton編譯器使用教程
業內首顆8核RISC-V終端AI CPU量產芯片K1,進迭時空與中國移動用芯共創AI+時代
Banana Pi BPI-F3 進迭時空RISC-V架構下,AI融合算力及其軟件棧實踐
RISC-V架構下DSA-AI算力的更多可能性:Banana Pi BPI-F3進迭時空





 工商網監
工商網監
評論