") RISC-V架構(gòu)下AI融合算力及其軟件棧實(shí)踐
RISC-V架構(gòu)下AI融合算力及其軟件棧實(shí)踐
面對(duì)未來(lái)大模型(LLM)、AIGC等智能化浪潮的挑戰(zhàn),進(jìn)迭時(shí)空在RISC-V方向全面布局,通過(guò)精心設(shè)計(jì)的RISC-V DSA架構(gòu)以及軟硬一體的優(yōu)化策略,將全力為未來(lái)打造高效且易用的AI算力解決方案。目前,進(jìn)迭時(shí)空已經(jīng)取得了顯著的進(jìn)展,成功推出了第一個(gè)版本的智算核(帶AI融合算力的智算CPU)以及配套的AI軟件棧。
軟件棧簡(jiǎn)介
AI算法部署旨在將抽象描述的多框架算法模型,落地應(yīng)用至具體的芯片平臺(tái),一般采用CPU、GPU、NPU等相關(guān)載體。在目前的邊緣和端側(cè)計(jì)算生態(tài)中,大家普遍認(rèn)為傳統(tǒng)CPU相較于NPU有極大的成本劣勢(shì),并且缺少基于CPU定制AI算力的能力或者相關(guān)授權(quán),導(dǎo)致在實(shí)際落地場(chǎng)景中,NPU的使用率很高。但是NPU有其致命的缺點(diǎn),各家NPU都擁有獨(dú)特的軟件棧,其生態(tài)相對(duì)封閉,缺乏與其他平臺(tái)的互操作性,導(dǎo)致資源難以共享和整合。對(duì)于用戶而言,NPU內(nèi)部機(jī)制不透明,使得基于NPU的二次開發(fā),如部署私有的創(chuàng)新算子,往往需要牽涉到芯片廠商,IP廠商和軟件棧維護(hù)方,研發(fā)難度較大。著眼于這些實(shí)際的需求和問(wèn)題,我們的智算核在設(shè)計(jì)和生態(tài)上采取了開放策略。以通用CPU為基礎(chǔ),結(jié)合少量DSA定制(符合RISC-V IME擴(kuò)展框架)和大量微架構(gòu)創(chuàng)新,以通用CPU的包容性最大程度復(fù)用開源生態(tài)的成果,在兼容開源生態(tài)的前提下,提供TOPS級(jí)別的AI算力,加速邊緣AI。這意味著我們可以避免低質(zhì)量的重復(fù)開發(fā),并充分利用開源資源的豐富性和靈活性,以較小的投入快速部署和使用智算核。這種開放性和兼容性不僅降低了部署大量現(xiàn)有AI模型的門檻,還為用戶提供了更多的創(chuàng)新可能性,使得AI解決方案不再是一個(gè)專門的領(lǐng)域,而是每個(gè)程序員都可以參與和創(chuàng)新的領(lǐng)域。
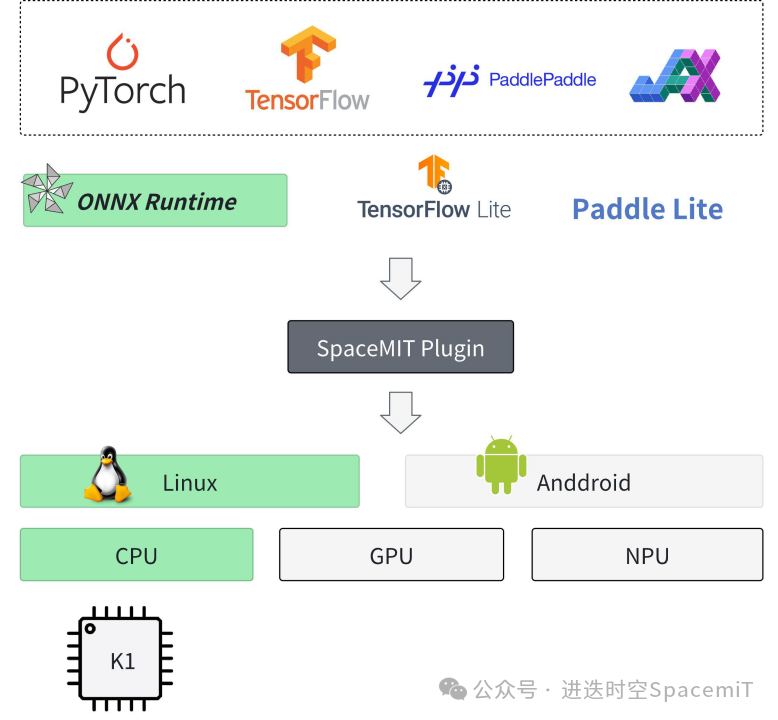
(圖一:進(jìn)迭時(shí)空AI軟件棧架構(gòu))如上圖所示,基于進(jìn)迭時(shí)空的AI技術(shù)路線,我們能輕松的以輕量化插件的方式,無(wú)感融入到每一個(gè)AI算法部署框架中,目前我們以O(shè)NNXRuntime為基礎(chǔ),結(jié)合深度調(diào)優(yōu)的加速后端,就可以成功的將模型高效的部署到我們的芯片上。對(duì)于用戶來(lái)說(shuō),如果有ONNXRuntime的使用經(jīng)驗(yàn),就可以無(wú)縫銜接。加入進(jìn)迭時(shí)空插件的使用方式如下:C/C++
C++ |
Python |
通過(guò)開放的軟件棧,使得我們的芯片能夠在短時(shí)間內(nèi)支持大量開源模型的部署,目前已累計(jì)驗(yàn)證了包括圖像分類、圖像分割、目標(biāo)檢測(cè)、語(yǔ)音識(shí)別、自然語(yǔ)言理解等多個(gè)場(chǎng)景的約150個(gè)模型的優(yōu)化部署,timm、onnx modelzoo、ppl modelzoo等開源模型倉(cāng)庫(kù)的支持通過(guò)率接近100%,而且理論上我們能夠支持所有的公開onnx模型。智算核的軟硬協(xié)同優(yōu)化
在保證通用性和易用性的同時(shí),我們利用智算核的特點(diǎn),極大優(yōu)化了模型推理效率。
離線優(yōu)化
離線優(yōu)化包含常見的等價(jià)計(jì)算圖優(yōu)化(如常量折疊、算子融合、公共子表達(dá)式消除等)、模型量化等,其中模型量化將浮點(diǎn)計(jì)算映射為低位定點(diǎn)計(jì)算,是其中效果最顯著的優(yōu)化方式。在智算核融合算力的加持下,算子可編程性很高,相較于NPU固化的量化計(jì)算方式,智算核能夠根據(jù)模型應(yīng)用特點(diǎn),匹配更寬泛的數(shù)據(jù)分布,實(shí)現(xiàn)量化計(jì)算的精細(xì)化、多樣化,以便于在更小的計(jì)算與帶寬負(fù)載下,實(shí)現(xiàn)更高的推理效率。
運(yùn)行時(shí)優(yōu)化
區(qū)別于NPU系統(tǒng)中,AI算子會(huì)根據(jù)NPU支持與否,優(yōu)先調(diào)度到NPU上執(zhí)行,并以host CPU作為備選執(zhí)行的方式。進(jìn)迭時(shí)空的智算核采用了擴(kuò)展AI指令的設(shè)計(jì),以強(qiáng)大的vector算力和scalar算力作為支撐,確保任意算子都能夠在智算核上得到有效執(zhí)行,無(wú)需擔(dān)心算子支持或調(diào)度問(wèn)題。這種設(shè)計(jì)不僅簡(jiǎn)化了用戶的操作流程,還大大提高了模型的執(zhí)行效率和穩(wěn)定性。
此外,進(jìn)迭時(shí)空的智算核還支持多核協(xié)同工作,進(jìn)一步提升了AI算力。用戶只需在運(yùn)行時(shí)通過(guò)簡(jiǎn)單的線程調(diào)度,即可靈活調(diào)整所使用的AI算力資源。
AI算力指令基礎(chǔ)
智算核的AI算力主要來(lái)自擴(kuò)展的AI指令。我們針對(duì)AI應(yīng)用中算力占比最高的卷積和矩陣乘法,基于RISCV Vector 1.0 基礎(chǔ)指令,新增了專用加速指令。遵從RISCV社區(qū)IME group的方式,復(fù)用了Vector寄存器資源,以極小的硬件代價(jià),就能給AI應(yīng)用帶來(lái)10倍以上的性能提升。
AI擴(kuò)展指令按功能分為點(diǎn)積矩陣乘累加指令(后面簡(jiǎn)稱矩陣?yán)奂又噶睿┖突包c(diǎn)積矩陣乘累加指令(后面簡(jiǎn)稱滑窗累加指令)兩大類,矩陣?yán)奂又噶詈突袄奂又噶罱M合,可以轉(zhuǎn)化成卷積計(jì)算指令。
以256位的向量矩陣配合4*8*4的mac單元為例,量化后的8比特輸入數(shù)據(jù)在向量寄存器中的排布,需要被看成是4行8列的二維矩陣;而量化后的8比特權(quán)重?cái)?shù)據(jù)在寄存器中的排布,會(huì)被看成是8行4列的二維矩陣,兩者通過(guò)矩陣乘法,得到4行4列輸出數(shù)據(jù)矩陣,由于輸出數(shù)據(jù)是32比特的,需要兩個(gè)向量寄存器存放結(jié)果。
如圖二所示,為矩陣?yán)奂又噶睿斎霐?shù)據(jù)只從VS1中讀取,權(quán)重?cái)?shù)據(jù)從VS2中讀取,兩者進(jìn)行矩陣乘法。
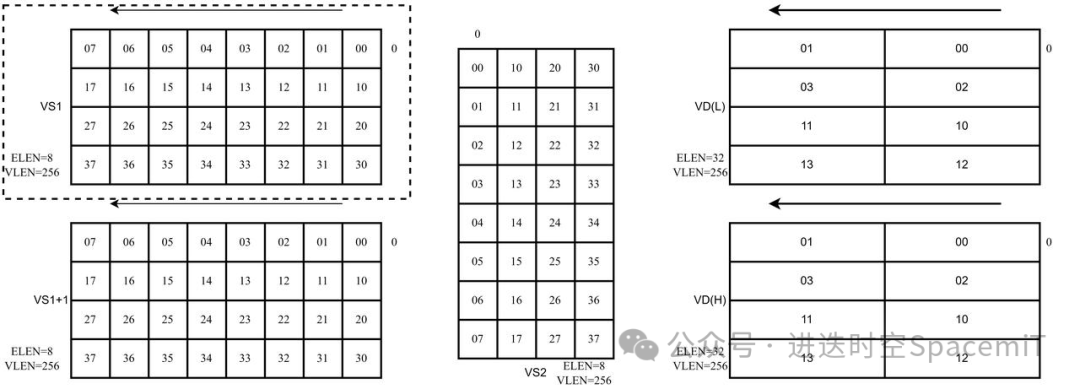
(圖二:矩陣?yán)奂又噶顢?shù)據(jù)排布示例)
如圖三所示,為滑窗累加指令,輸入數(shù)據(jù)從VS1和VS1+1中讀取,讀取的數(shù)據(jù),通過(guò)滑動(dòng)的大小決定(大小為8的倍數(shù)),權(quán)重?cái)?shù)據(jù)從VS2中讀取,兩者進(jìn)行矩陣乘法。
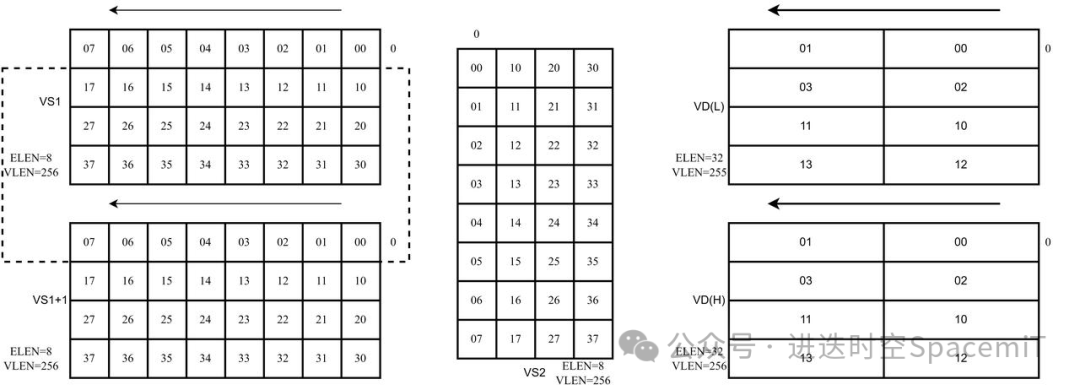
(圖三:滑窗累加指令數(shù)據(jù)排布示例)
如下圖所示,9個(gè)紅點(diǎn)對(duì)應(yīng)的9行輸入數(shù)據(jù)(1*k維)和權(quán)重進(jìn)行乘累加計(jì)算,就得到了一個(gè)卷積值。在做卷積計(jì)算的時(shí)候,可以把矩陣乘法看成是滑動(dòng)為零的滑窗指令。通過(guò)滑動(dòng)0,1,2三條指令的計(jì)算,就可以完成kernel size 為3x1的的卷積計(jì)算。然后通過(guò)h維度的三次循環(huán),就可以得到kernel size 為3x3的卷積計(jì)算。
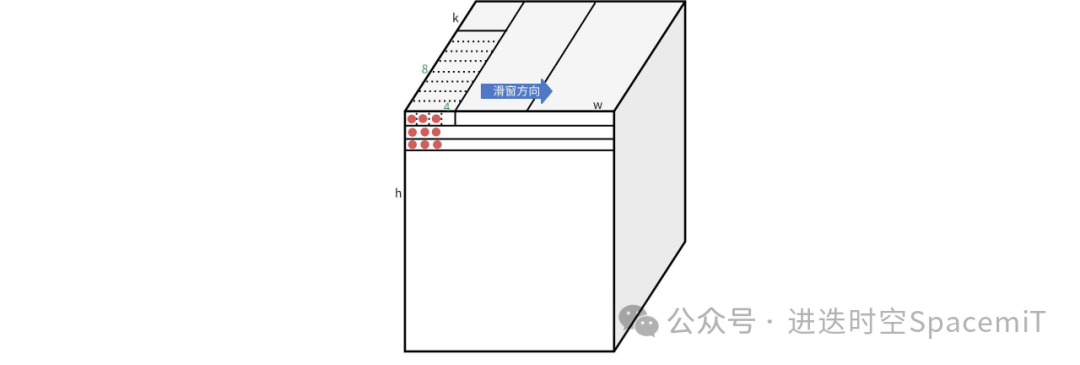
(圖四:滑窗累加指令結(jié)合矩陣?yán)奂又噶钣?jì)算卷積示例)
同樣通過(guò)滑動(dòng)0,1,2,0,1五條指令的計(jì)算,和h維度五次循環(huán),就可以完成kernel size為5x5的卷積計(jì)算,以此類推,可以得到任意kernel size的卷積計(jì)算。
效果演示視頻
通過(guò)以上軟硬件協(xié)同優(yōu)化,我們?cè)诙嗳蝿?wù)推理時(shí),也有非常高的性能。展望
前文提到,通過(guò)ONNX與ONNXRuntime的結(jié)合,我們能夠便捷地接入開源生態(tài),但這僅僅是實(shí)現(xiàn)接入的眾多方式之一。實(shí)際上,我們還可以充分利用當(dāng)前備受矚目的MLIR生態(tài),進(jìn)一步融入開源的廣闊天地。這種方式不僅充滿想象力,而且具備諸多優(yōu)勢(shì)。
首先,它能夠?qū)崿F(xiàn)模型的直接原生部署。舉例來(lái)說(shuō),當(dāng)我們擁有一個(gè)PyTorch模型時(shí),借助torch.compile功能,我們可以直接將模型部署到目標(biāo)平臺(tái)上,無(wú)需繁瑣的轉(zhuǎn)換和適配過(guò)程,極大地提升了部署的便捷性。
其次,MLIR生態(tài)與LLVM的緊密結(jié)合為我們提供了強(qiáng)大的codegen能力。這意味著我們可以利用LLVM豐富的生態(tài)系統(tǒng)和工具鏈,進(jìn)行代碼生成和優(yōu)化,從而進(jìn)一步降低AI軟件棧的開發(fā)成本。通過(guò)codegen,我們可以將高級(jí)別的模型描述轉(zhuǎn)化為底層高效的機(jī)器代碼,實(shí)現(xiàn)性能的最優(yōu)化。
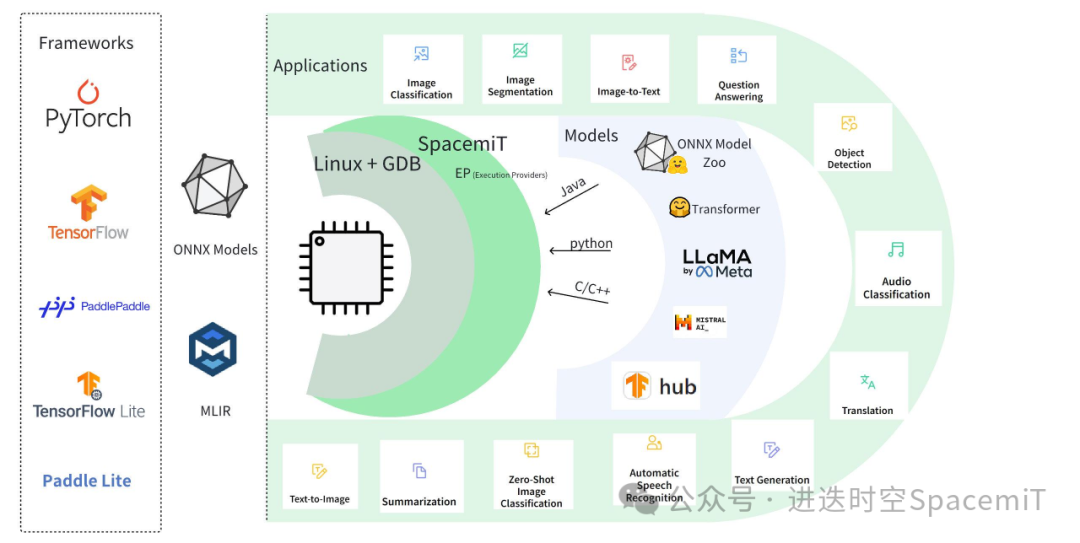
(圖五:進(jìn)迭時(shí)空AI軟件棧架構(gòu)規(guī)劃)
-
AI
+關(guān)注
關(guān)注
87文章
34274瀏覽量
275463 -
RISC-V
+關(guān)注
關(guān)注
46文章
2498瀏覽量
48291
發(fā)布評(píng)論請(qǐng)先 登錄
Banana Pi BPI-F3 進(jìn)迭時(shí)空RISC-V架構(gòu)下,AI融合算力及其軟件棧實(shí)踐





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論