 借助美光9550高性能SSD提升AI工作負載
借助美光9550高性能SSD提升AI工作負載

推理將成為數據中心最常見的工作負載,這一點毋庸置疑。隨著數據中日益廣泛采用NVIDIA H100,以及非NVL72系統開始部署NVIDIA DGX B200,計算能力正迎來爆炸式增長。
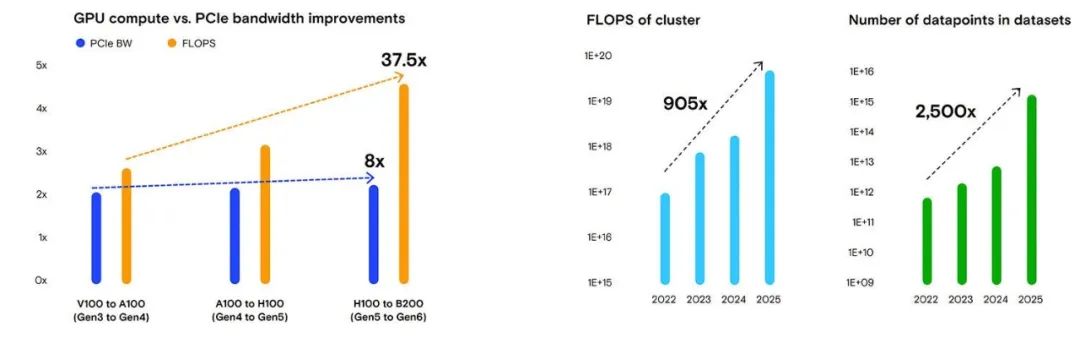
觀察PCIe各代產品帶寬擴展與計算能力增長的情況可以發現:從PCIe 3.0到6.0,帶寬增長了8倍,而GPU FLOPS在同一時期增長了37.5倍。
我們還發現,過去四年間,訓練集群的平均FLOPS增加了905倍,而訓練數據集中的數據點數量在同一時期增加了2,500倍。
雖然推理一直是且將繼續是計算密集型工作負載,但其對快速存儲的依賴正在迅速顯現。推理模型將推動大語言模型 (LLM) 的實用性、準確性和資源需求大幅提升。序列長度的增加促使LLM系統設計不斷創新,將KV緩存存儲到磁盤而非刷新后重新計算正在成為效率更高的做法。這將對企業用于推理的GPU本地系統提出更高的性能要求。
我們關注這一趨勢已有一段時間,并因此研發出了美光9550這款性能出色的SSD。其高IOP和卓越能效能夠有效契合這些新興工作負載的需求。
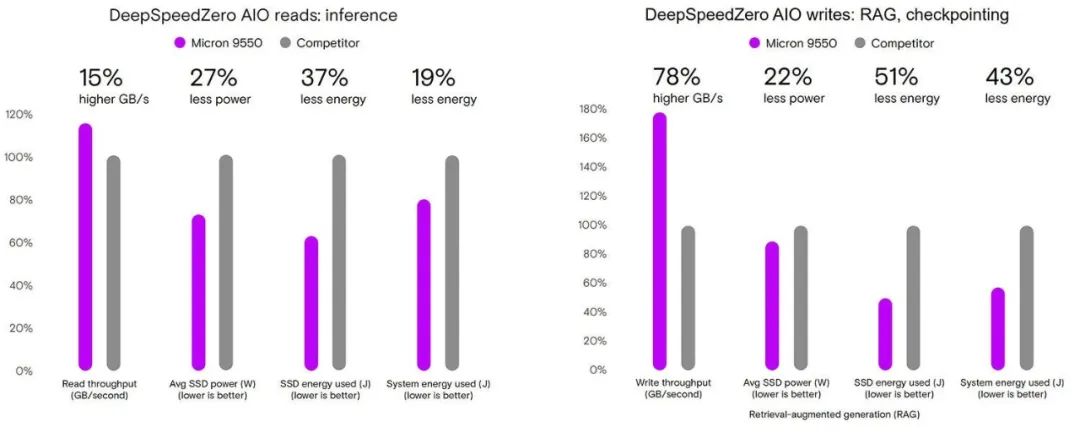
舉例而言,我們使用微軟的DeepSpeed ZeRO-Inference工具對美光9550與某前沿競品進行了測試。結果顯示,美光9550的讀取速度快15%,平均功耗低27%,從而使SSD能耗低37%、系統總能耗低19%。
盡管寫入操作只占推理工作負載的一小部分,但不同SSD在寫入性能方面存在顯著差異。美光9550的寫入速度快78%,同時平均功耗低22%。這表明美光9550完成推理任務的能耗僅為其他產品的一半,且系統總能耗低43%。
隨著計算能力的迅猛發展以及推理領域令人矚目的實用性創新成果不斷涌現,存儲技術亟待跟上步伐。數據中心SSD的開發周期較長;NAND制造、ASIC設計、功耗、散熱等環節均對AI系統中存儲的最終性能起著關鍵作用。美光多年來一直在測試人工智能 (AI) 工作負載,并將其視為美光9550以及其他新一代數據中心SSD開發工作的重要組成部分。我們深知,要打造契合未來AI工作負載需求的存儲解決方案,就必須在當下先人一步。
測試詳情:
DeepSpeed ZeRO AIO讀取——在GPU內部通過DeepSpeed庫模擬合成工作負載。
測試系統:2顆Intel Xeon Platinum 8568Y+、768GB DDR5 DRAM、2塊NVIDIA L40S GPU競品是一款PCIe 5.0高性能數據中心SSD,其在規格和目標用例方面與美光9550相似。
相關數據通過850次測試運行產生,測試歷時446小時。
本文作者
Ryan Meredith
美光存儲解決方案架構總監
-
SSD
+關注
關注
21文章
2981瀏覽量
119538 -
數據中心
+關注
關注
16文章
5222瀏覽量
73485 -
美光
+關注
關注
5文章
727瀏覽量
52376
原文標題:推理=IOPS:借助美光9550高性能SSD保持前沿地位
文章出處:【微信號:gh_195c6bf0b140,微信公眾號:Micron美光科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
美光推出自適應寫入技術與G9 QLC NAND的2600 NVMe SSD 兼顧出眾PCIe 4.0性能

美光科技推出兩款全新高性能固態硬盤
美光科技推出4600 PCIe 5.0 NVMe SSD
美光科技與Astera Labs合作升級SSD性能
美光發布60TB SSD新品,速率與能效再創新高
美光科技推出業界首款PCIe 5.0 60TB數據中心SSD
美光推出速率與能效領先的 60TB SSD
美光科技推出新款存儲解決方案






 工商網監
工商網監
評論