") 國產GPU再下一城,群起突圍英偉達+AMD
國產GPU再下一城,群起突圍英偉達+AMD

電子發(fā)燒友網報道(文/黃晶晶)去年底以來國產GPU廠商陸續(xù)開啟上市輔導,最近摩爾線程、沐曦IPO獲受理。另消息稱,壁仞科技已完成新一輪約15億元融資,并計劃最快今年8月向港交所申請IPO,籌備赴港上市。
根據Jon Peddie Research的數據,獨立GPU市場英偉達一家獨大,近年來持續(xù)維持超80%的市場份額,而AMD公司則占據剩余近20%的市場份額。自人工智能市場爆發(fā)式增長以來,英偉達憑借優(yōu)越的產品性能和完善的CUDA 生態(tài)筑造了護城河,領先優(yōu)勢不斷擴大。根據TechInsights 數據,在GPU市場,2023年全球應用于智算中心的GPU總出貨量達到385萬顆,相比2022年的267萬顆增長了44.2%。其中,英偉達面向智算中心市場的GPU出貨量達到376萬顆,市場份額超過90%。
隨著國內GPU廠商經歷前期研發(fā)、產品市場驗證、走向資本市場等動作,國內GPU產品和應用生態(tài)越來越強,勢必在GPU市場爭取到一定的份額。
營收規(guī)模
近年來,摩爾線程把握市場發(fā)展機遇,專注于技術研發(fā)和產品創(chuàng)新,持續(xù)推出具有行業(yè)競爭力的全功能GPU產品。2024年公司營業(yè)收入超4億元,近三年營業(yè)收入復合增長率超過200%,持續(xù)經營能力不斷提升。
報告期各期,公司歸屬于母公司所有者的凈利潤分別為-183,955.22 萬元、-167,331.03 萬元及-149,193.77 萬元,扣除非經常性損益后歸屬于母公司所有者 的凈利潤分別為-141,200.30 萬元、-169,066.22 萬元和-150,690.72 萬元。2022年至2024年,公司營業(yè)收入由0.46億元增長至4.38億元,復合增長率為208.44%。報告期內公司研發(fā)費用金額較高,報告期內分別為111,649.37 萬元、133,442.57 萬元、135,868.90 萬元。合計研發(fā)投入金額380,960.84萬元;發(fā)行人最近3年累計研發(fā)投入占最近三年累計營業(yè)收入比例為626.03%
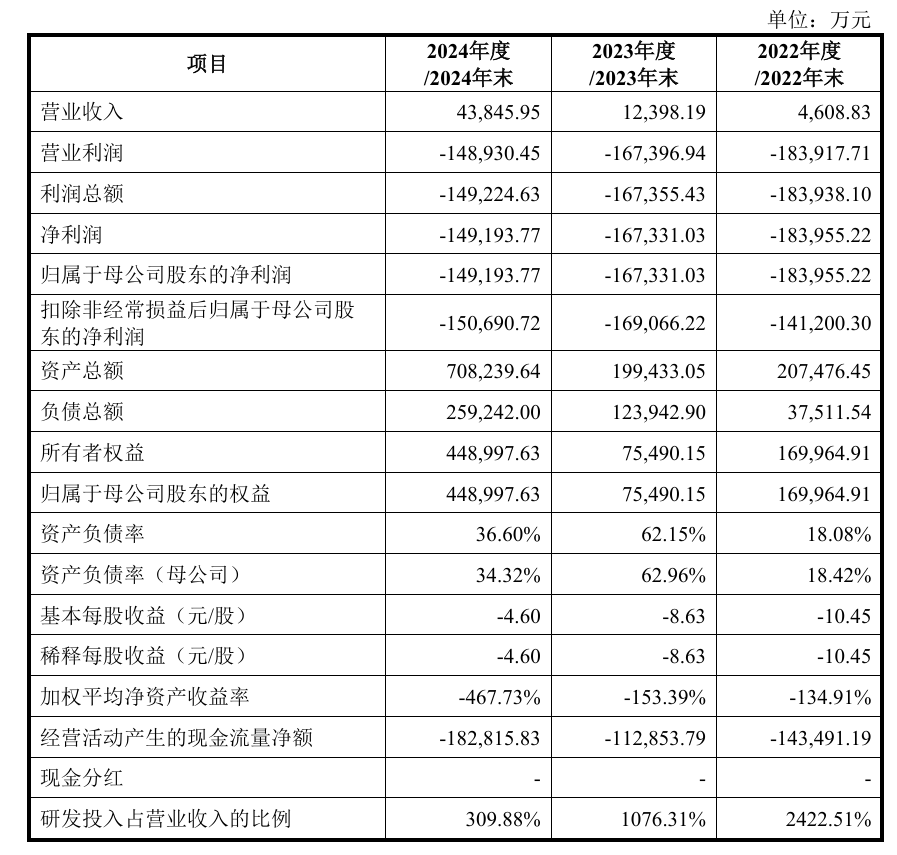
沐曦報告期各期,公司營業(yè)收入分別為42.64萬元、5,302.12萬元、74,307.16萬 元和 32,041.53 萬元,歸屬于母公司所有者的凈利潤分別為-77,696.52 萬元、-87,115.82 萬元、-140,887.94 萬元和-23,251.22 萬元,尚未實現盈利。
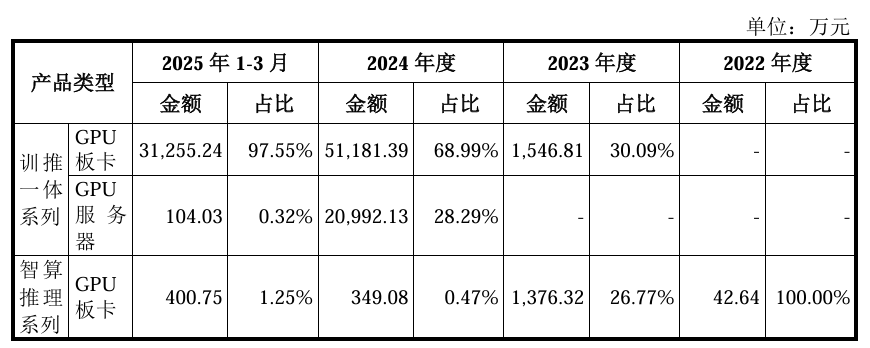
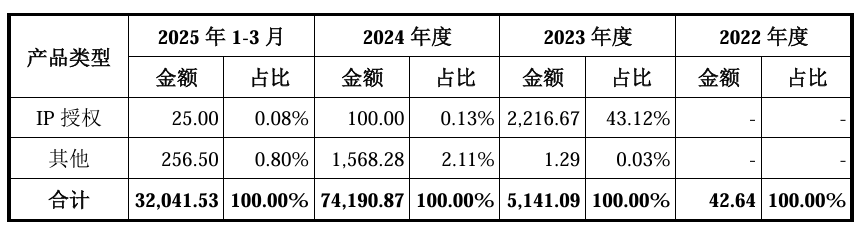
報告期內,沐曦主要收入來源為核心產品訓推一體芯片曦云C500系列的銷售。2023 年度、2024 年度和2025 年1-3月,發(fā)行人訓推一體芯片曦云C500 系列收入分別為1,546.81萬元、72,173.52萬元和31,359.27萬元,占同期主營業(yè)務收入的比例分別為30.09%、97.28%和97.87%,最近一年一期占比較大。發(fā)行人正在研發(fā)基于國產供應鏈的新一代訓推一體芯片曦云 C600 系列和 C700 系列,以及智算推理GPU曦思N系列、圖形渲染GPU曦彩G系列的新產品。
相比于國際巨頭英偉達、AMD的營業(yè)收入、凈利潤、毛利率、研發(fā)投入等,國內廠商都還相去甚遠。其中2024年海光信息毛利率達63.72%。不過可以看到國內企業(yè)研發(fā)投入率高位數,其中沐曦的研發(fā)投入率達121.24%。
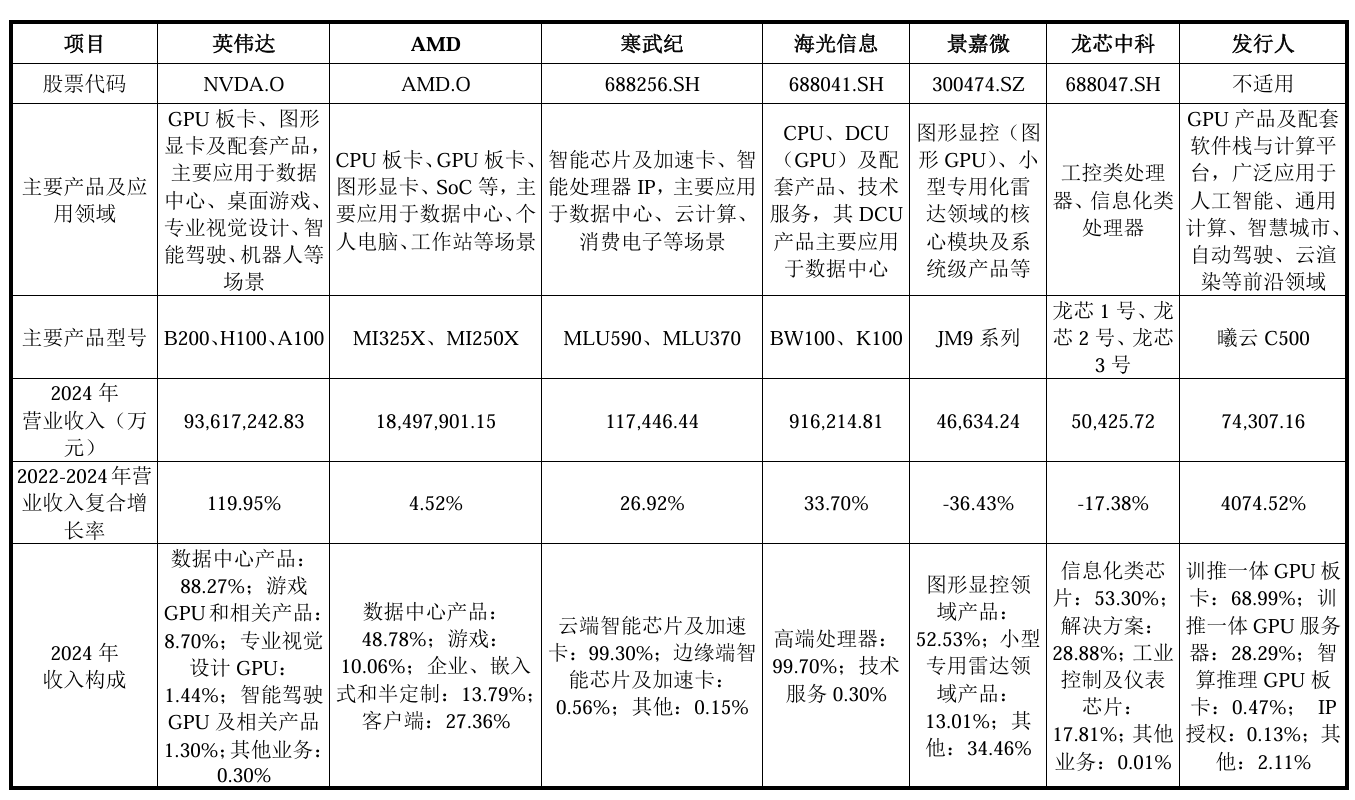
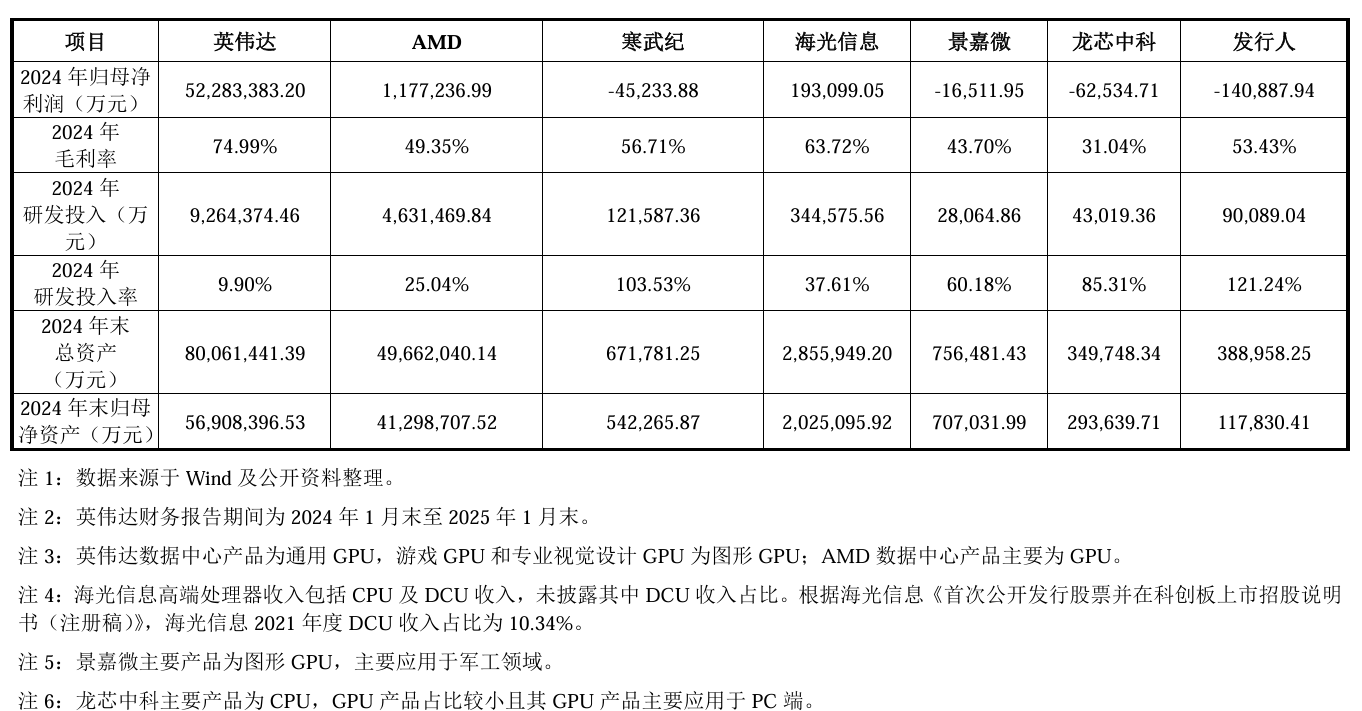
來源:沐曦招股書
摩爾線程表示,與國際龍頭公司英偉達、AMD等企業(yè)相比,公司在技術積累、產品性能等方面仍需持續(xù)提升。英偉達在GPU領域擁有深厚的技術底蘊和豐富的行業(yè)經驗,其產品在性能、兼容性以及超大規(guī)模GPU集群建設等方面具有較為明顯的技術優(yōu)勢和成本優(yōu)勢。公司產品在部分性能指標上已經接近或達到國際先進水平,實現了對部分“卡脖子”領域核心產品的突破。
例如,公司MTT S80顯卡的單精度浮點算力性能接近英偉達RTX 3060;基于公司MTT S5000 產品構建的千卡 GPU智算集群效率超過同等規(guī)模國外同代系GPU集群計算效率。公司在國內GPU領域具有一定的技術優(yōu)勢,基于自主研發(fā)的MUSA架構,公司率先實現了在單芯片架構上同時支持AI計算加速、圖形渲染、物理仿真以 及超高清視頻處理所需計算能力的突破,推動了我國GPU產業(yè)的自主可控進程。
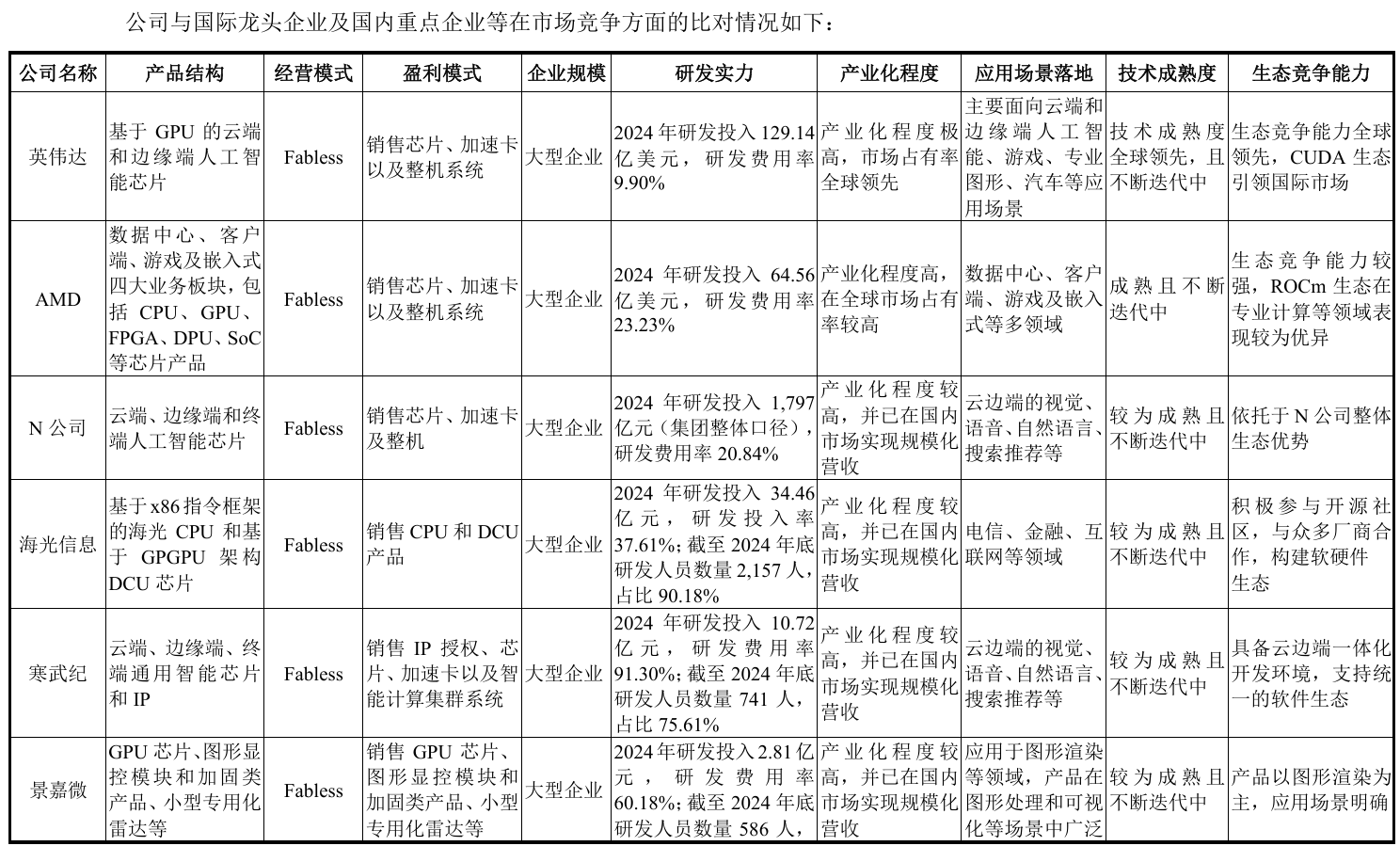

來源:摩爾線程招股書
產品技術
全球龍頭企業(yè)在技術、市場和生態(tài)方面具有顯著優(yōu)勢。在架構、計算能力、存儲能力、集群能力和軟件生態(tài)方面,國內外均存在差異。英偉達和AMD均采用通用型架構,并進行數次迭代,如英偉達常見的GPU架構包含Ampere架構、Hopper架構、Blackwell架構。AMD常見的有 RDNA 架構、CDNA架構等。英偉達及AMD先進的計算架構決定了其領先的GPU計算性能。而國內企業(yè)根據自身技術特色沿用了不同的技術路徑,包括通用型架構(GPU)和專用型架構(如ASIC),不同公司的架構設計各有差異。
在計算能力方面,英偉達和AMD支持多種混合精度(FP64、FP32、FP16、BF16、FP8、FP4、INT8)等。算力指標上,英偉達主要產品的FP16/BF16在300-2000TFLOPS左右,AMD主要產品的FP16/BF16在300-1,300 TFLOPS左右。
國內企業(yè)支持部分混合精度,大多不支持FP64且對矩陣計算的支持程度較低。采用專用型架構的企業(yè)通常以支持 FP16、BF16、INT8 為主。算力指標上,國內多數頭部企業(yè)主流在售產品的FP16/BF16在100-300 TFLOPS 左右。
在存儲能力上,緩存方面,英偉達和AMD 均使用了復雜的多級高速緩存架構,以提升數據訪問效率,減少延遲。顯存方面,英偉達和AMD采用高帶寬顯存HBM2e、HBM3及HBM3e,顯存帶寬在2-7TB/s 左右。
國內部分企業(yè)以采用相對簡單的緩存架構為主。國內企業(yè)結合自身產品特點,分別選擇HBM2e、HBM2、GDDR等顯存類型,顯存帶寬在0.5-2TB/s 左右。
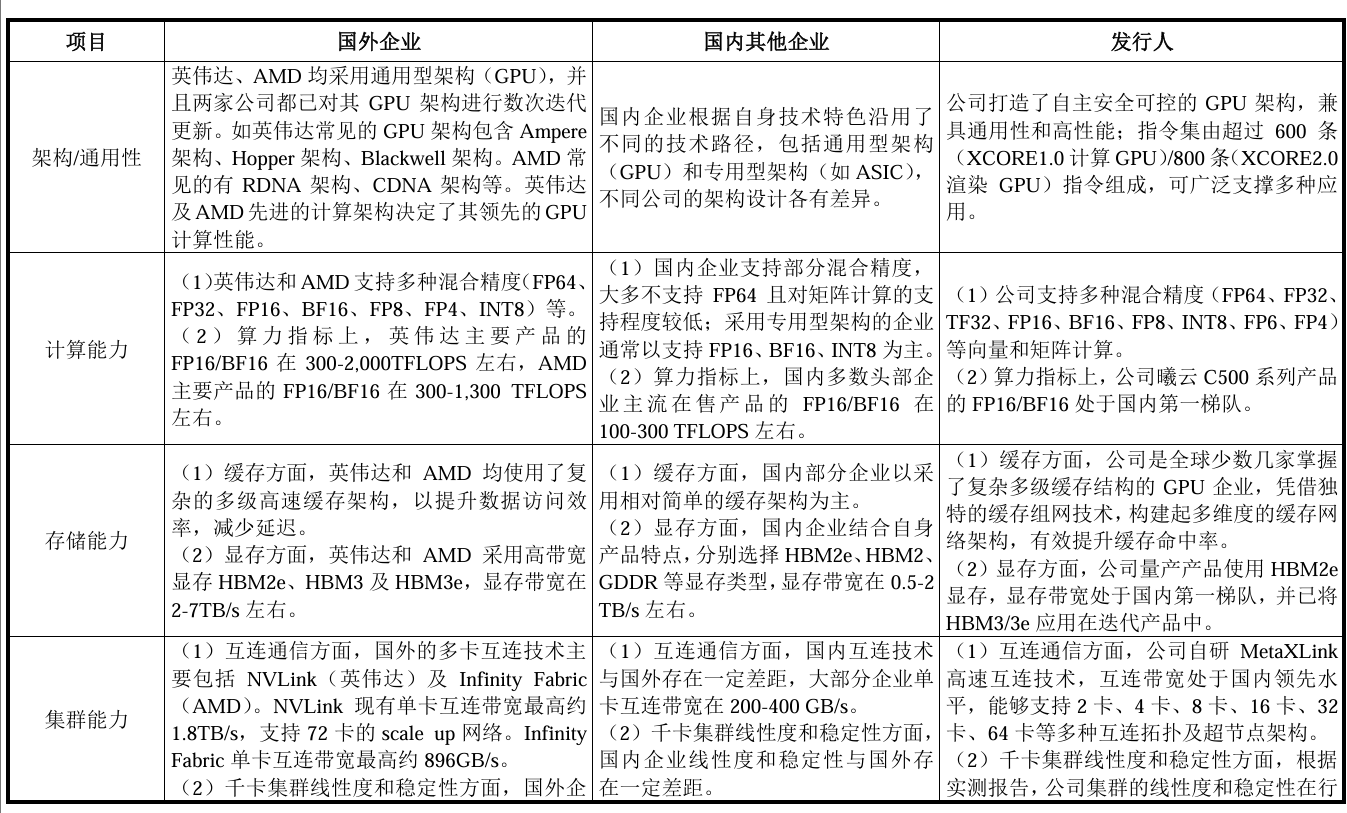
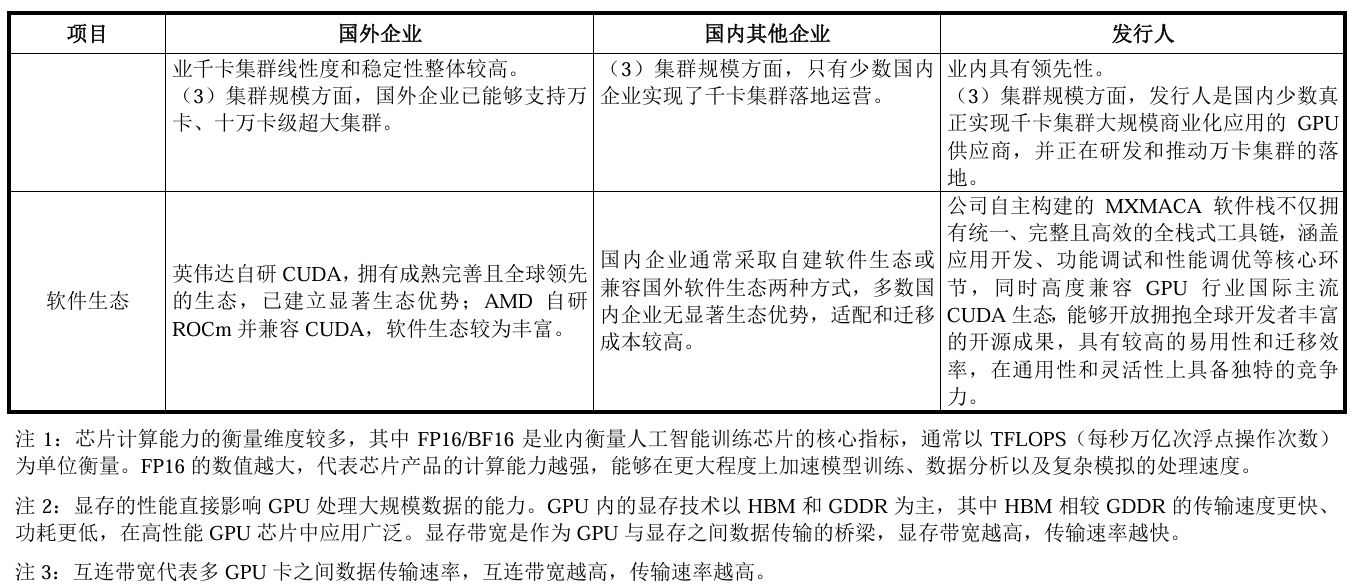
來源:沐曦招股書
軟件生態(tài)方面,英偉達自研 CUDA,擁有成熟完善且全球領先的生態(tài),已建立顯著生態(tài)優(yōu)勢:AMD自研ROCm 并兼容CUDA,軟件生態(tài)較為豐富。國內企業(yè)通常采取自建軟件生態(tài)或應用開發(fā)、功能調試和性能調優(yōu)等核心環(huán)節(jié),多數國內企業(yè)無顯著生態(tài)優(yōu)勢,適配和遷移成本較高。
沐曦是國內少數幾家系統(tǒng)掌握了先進制程 GPU芯片及其基礎系統(tǒng)軟件研發(fā)、設計和量產技術的企業(yè)之一,深度積累了GPU IP(包括指令集、 微架構等)、GPU SoC、高速互連、GPU軟件等核心技術,打造了自主開放、高度兼容國際主流GPU 生態(tài)(CUDA)的軟件生態(tài)體系,能夠為客戶構建軟硬件一體的全面生態(tài)解決方案,在底層技術上擺脫對國外算力資產的依賴,為推進新質生產力發(fā)展提供動力引擎。
沐曦自主構建的MXMACA軟件棧不僅擁有統(tǒng)一、完整且高效的全棧式工具鏈,涵蓋應用開發(fā)、功能調試和性能調優(yōu)等核心環(huán)節(jié),同時高度兼容GPU行業(yè)國際主流CUDA生態(tài),能夠擁抱全球開發(fā)者豐富的開源成果,具有較高的易用性和遷移效率,在通用性和靈活性上具備獨特的競爭力。
摩爾線程構建的AI+圖形融合的GPU統(tǒng)一驅動架構,實現跨操作系統(tǒng)與異構硬件的無縫兼容。憑借自主研發(fā)的MUSA Unified Driver核心模塊,驅動層同時支持Windows、麒麟、統(tǒng)信、OpenEuler、龍蜥等操作系統(tǒng)及Intel/AMD/鯤鵬/海光/飛騰等CPU平臺,在統(tǒng)一代碼庫中整合AI張量計算與圖形渲染管線,使DirectX、 Vulkan 圖形API與MUSA AI計算框架共享底層硬件資源調度。
編譯器技術通過多層次中間表示,實現生態(tài)兼容與性能優(yōu)化雙重突破。基于 LLVM 的前端支持PyTorch Eager 模式腳本、CUDA內核代碼與標準SPIR-V著 色器語言混合編譯,后端生成自主指令集的二進制碼。
為營造低門檻開發(fā)環(huán)境,公司推出MUSA統(tǒng)一編程模型,語法上兼容CUDA C++核心語義和 Triton 語言,內置架構抽象層能自動適配主流 GPU生態(tài),在保持90%以上硬件利用率的前提下,將跨平臺代碼移植工作量削減90%。軟件開發(fā)生態(tài)通過模塊化SDK體系覆蓋核心技術需求,MUSA SDK提供超 3,000 個從設備級內存管理到分布式訓練通信的API接口,封裝muDNN、muBlast、 muFFT、MCCL等主流加速庫的優(yōu)化實現,并集成自動化性能分析工具鏈。
為深度融入現有AI生態(tài),公司構建了AI Framework Bridge雙向接口體系,支持PyTorch、DeepSpeed、MegaTron-LM、vLLM、SGLang 等通用AI 框架,助力開發(fā)者平滑遷移。 公司專注于自主知識產權的MUSA架構研發(fā),通過開放API和SDK工具集, 助力開發(fā)者和合作伙伴快速集成GPU解決方案。
公司生態(tài)團隊建立了“摩爾學院”,為開發(fā)者提供系統(tǒng)化的學習路徑,覆蓋企業(yè)開發(fā)者、科研機構及在校學生,提升開發(fā)者對公司產品的認知度和使用能力。 此外,公司搭建了開放生態(tài)合作平臺,向開發(fā)者和合作伙伴開放申請通道,提供定制化的技術支持、資源共享及聯合開發(fā)機會,強化生態(tài)系統(tǒng)的持續(xù)優(yōu)化和價值創(chuàng)造理念。
通過構建完善的生態(tài)系統(tǒng),公司實現了從產品研發(fā)到市場的全鏈條閉環(huán),增 強了市場競爭力。未來,公司將秉持“技術驅動、生態(tài)賦能、全場景兼容”理念, 發(fā)揮GPU技術潛力,推動產業(yè)數字化轉型與智能化升級。
增長可期
根據沙利文數據,隨著AI和大數據應用的不斷深入,中國算力規(guī)模呈現出快速增長態(tài)勢,整體規(guī)模從2020年的136.20 EFLOPs增長至2024年的617.00 EFLOPs,期間年復合增長率為45.9%,預計到2029年中國算力總規(guī)模將達到3,442.89 EFLOPs,年復合增長率達40.0%。GPU作為實現算力的基礎硬件之一,在數據中心建設和部署過程中具有廣泛的配套需求。
根據弗若斯特沙利文預測,全球GPU市場規(guī)模預計在2029年將達到36,119.74億元,其中,中國GPU市場規(guī)模在2029年將達到13,635.78億元,在全球市場中的市場占比預計將從2024年的30.8%提升至2029年的37.8%。
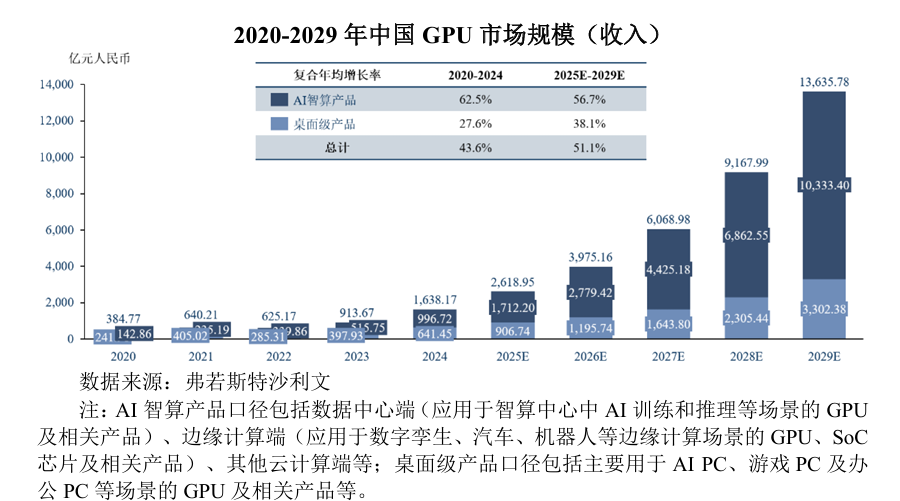
過去五年,中國GPU產業(yè)呈現快速增長態(tài)勢,市場規(guī)模從2020年的384.77億元快速增長到2024 年的1,638.17 億元。未來,隨著AI的應用不斷開發(fā),對于GPU等算力基礎設施的需求預計將會出現爆發(fā)增長。
-
gpu
+關注
關注
28文章
4937瀏覽量
131183 -
摩爾線程
+關注
關注
2文章
234瀏覽量
5347 -
沐曦
+關注
關注
0文章
34瀏覽量
1427
發(fā)布評論請先 登錄
英偉達殺瘋了!Blackwell橫掃市場,AMD、英特爾加入降本浪潮
荷蘭與英偉達、AMD商討共建人工智能設施
黃仁勛宣布:豐田與英偉達攜手打造下一代自動駕駛汽車

英偉達計劃2025年推出基于Arm架構的消費級CPU,挑戰(zhàn)英特爾和AMD
軟銀升級人工智能計算平臺,安裝4000顆英偉達Hopper GPU
英偉達下一代GPU或將改用全新連接器
英偉達Blackwell GPU未來一年訂單爆滿
英偉達年度研發(fā)支出超120億美元,為AMD的兩倍之多
英偉達或明年將革新AI GPU設計,采用插槽設計
英偉達Blackwell GPU量產加速,Q4營收沖刺百億美元大關






 工商網監(jiān)
工商網監(jiān)
評論