 NVMe IP高速傳輸卻不依賴XDMA設計之三:系統架構
NVMe IP高速傳輸卻不依賴XDMA設計之三:系統架構

結合目前應用需求,以及前面基礎分析,確定IP應具有如下特色:
(1) 通用性
前端數據采集系統基于 FPGA 開發。 一方面, 設備類型多, 使用的 FPGA型號各不相同, 需要實現的設計能夠在多種類型 FPGA 上的工作; 另一方面, 為了降部署低成本, 需要實現脫離 CPU 的存儲控制。 綜合考慮以上兩方面因素,設計應采用純邏輯電路的方式實現。
(2) 高性能
前端采集的數據存在連續數據、 零散數據等多種數據量形式。 面臨大量零散數據存儲請求時, 需要增加 NVMe I/O 隊列的數量和深度來保證數據傳輸性能; 而面臨大量連續數據存儲請求時, 單隊列足以發揮性能。 在這種情況下, 需要盡可能降低功耗,減少運行中的 I/O 隊列數量。 因此, 需要實現動態的隊列管理功能, 在滿足高性能的同時適應不同的應用環境。 具體要求為使用 PCIe3.0 以上接口的高性能固態硬盤的順序讀寫數據吞吐量不低于2GB/s, 隨機寫IOPS不低于500000, 隨機寫延遲不高于1ms。
(3) 易集成、 易操作
實現的 NVMe 主機控制邏輯和 NVMe 固態硬盤作為存儲子系統, 應能夠方便的集成到應用環境中, 并提供簡易的操作方式實現數據的傳輸與存儲。 因此, 設計需要采用標準化接口, 實現盡可能低的資源占用率, 并具備 DMA 數據傳輸功能。
基于以上需求, 本IP擬基于 FPGA 的 NVMe over PCIe(NoP) 邏輯進行設計,它具有以下特點:
(1) 支持 NVMe 1.3d 協議、 支持 PCIe 3.0 協議。
(2) 基于 Xilinx PCIe Integration Block 硬核開發。 一方面, 該 PCIE 集成塊具有多種版本, 并且適用平臺多, 因此 NoP 邏輯加速引擎能夠部署在支持 PCIE 集成塊的FPGA 開發板上。 另一方面, 直接對接 PCIE 集成塊的結構設計具有更高的數據傳輸性能。
(3) 純邏輯電路開發。 設計基于純邏輯電路, 不需要 CPU 的介入, 獨立運行,可以節省 CPU 資源, 兼容 SoC 與純邏輯環境。
(4) 使用 AXI 總線接口。 設計使用標準化的 AXI 總線接口提供系統控制和數據傳輸功能, 在保證了傳輸性能的同時, 更容易集成到應用環境中。
(5) 多隊列并行管理與動態配置。 支持的最大 I/O 提交隊列數量為 16, 支持的最大單 I/O 提交隊列深度為 1024, 最大 I/O 提交隊列總深度為 1024, 支持運行過程中動態的創建或刪除隊列。
(6) DMA 功能。 通過配置 DMA 寄存器直接請求數據傳輸, 數據傳輸通過 AXI4總線接口對接用戶邏輯, 使用突發傳輸提高數據傳輸性能。
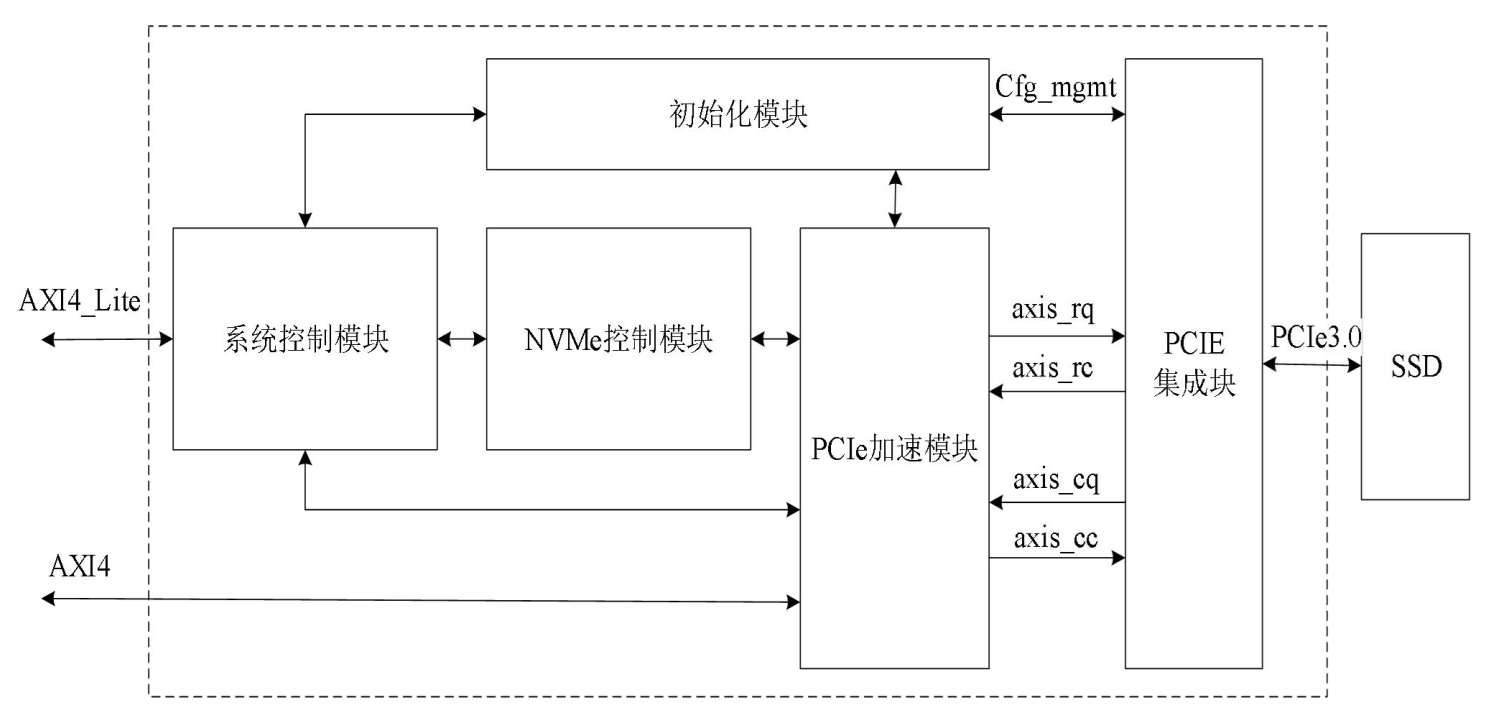
圖1 Nvme邏 輯加速IP系統架構圖
新系統中,Nvme邏輯加速IP通過 PCIe 3.0x4 接口連接 NVMe
固態硬盤, 并提供 AXI4-Lite 接口用于系統控制, 以及 AXI4 接口用于數據傳輸。 在該IP內部, 根據功能劃分為系統控制模塊、 初始化模塊、 NVMe 控制模塊、 PCIe 加速模塊、 PCIE 集成塊。 以下為各功能模塊的定義:
系統控制模塊是實現NVMe over PCIe關鍵組件。 NoP 邏輯加速引擎內部集成了各種功能, 包括初始化、 NVMe 隊列管理以及 DMA 等多種功能, 統由系統控制模塊進行管理。 為了有效管理這些功能, 系統控制模塊設計了對應的功能控制單元, 并提供了 AXI4-Lite 從機接口, 使得 NoP 邏輯加速引擎能夠輕松地與用戶環境集成。 通過 AXI4-Lite 接口, 用戶可以方便地訪問各個功能控制單元, 實現對系統功能的控制。 這種設計使得用戶能夠直接與 NoP 邏輯加速引擎進行交互, 靈活地配置和管理系統的各項功能, 從而更好地滿足特定的應用需求。
初始化模塊負責控制系統的初始化流程, 其中包括 PCIe 初始化和 NVMe 初始化兩個主要步驟。 在系統上電復位后, 首先由 PCIE 集成塊執行物理層的鏈路訓練和速度協商, 建立有效的 PCIe 通信鏈路。 隨后, 由初始化模塊進行 PCIe 設備的枚舉與配置, 并執行 NVMe 的初始化流程。 初始化過程是確保系統能夠在正確狀態下運行的前提條件, 也為后續操作提供了必要的支持。
NVMe 控制模塊是實現 NVMe 的命令提交和完成機制的核心模塊。 首先, 該模塊負責將來自系統控制模塊的功能請求轉換為 NVMe 命令請求, 并執行 NVMe 指令提交與完成機制。 其次, 該模塊實現 NVMe 隊列管理功能, 除了基本的隊列存儲、門鈴控制、 請求仲裁、 條目解析等, 還包括了動態創建和刪除隊列功能。 最后, 該模塊還負責實現 PRP 尋址機制, 根據指令管理和計算 PRP 偏移, 實現數據的尋址并降低 PRP 讀取延遲。
PCIe 加速模塊負責處理 PCIe TLP, 將 PCIe 事務與 NVMe 緊密結合。 一方面,該模塊將來自初始化模塊或 NVMe 控制模塊的事務請求轉換為 PCIe TLP 請求, 然后發送到 PCIE 集成塊, 同時接收 PCIE 集成塊的 TLP 響應包, 將其轉換為內部事務響應發送到對應內部模塊。 另一方面, 該模塊負責處理來自 NVMe 存儲設備的 TLP 請求, 根據請求內容將請求轉發到 NVMe 控制模塊或轉換為 AXI4 總線事務, 同時將來自 NVMe 控制模塊和 AXI4 總的響應組裝為 CplD, 經由 PCIE 集成塊發送給 NVMe存儲設備。
PCIE 集成塊實現 PCIe 的數據鏈路層和物理層。 PCIE 集成塊是 Xilinx 提供的用于 PCIe 的高帶寬、 可擴展和靈活的通用 I/O 核, 在 NoP 邏輯加速引擎中使用 PCIE集成塊的 RC 模式實現 Root Complex 的數據鏈路層與物理層。 PCIE 集成塊提供了四組 AXI stream 接口用于傳遞 PCIe TLP, 通過這些接口實現 TLP 與 PCIe 鏈路信號的相互轉換, 此外還包含一組配置接口用于訪問 PCIE 集成塊的配置空間。
想進一步了解相關視頻,請搜索B站用戶:專注與守望
鏈接:https://space.bilibili.com/585132944/dynamic?spm_id_from=333.1365.list.card_title.click
更多博文見:https://blog.csdn.net/tiantianuser/article/details/148994728
-
FPGA
+關注
關注
1644文章
22009瀏覽量
616591 -
可編程邏輯
+關注
關注
7文章
526瀏覽量
44661 -
高速存儲
+關注
關注
0文章
9瀏覽量
5995 -
nvme
+關注
關注
0文章
246瀏覽量
23176
發布評論請先 登錄
NVMe IP之AXI4總線分析
NVMe IP高速傳輸卻不依賴便利的XDMA設計之三:系統架構
NVMe IP高速傳輸擺脫XDMA設計之四:系統控制模塊設計
PCIE高速傳輸解決方案FPGA技術XILINX官方XDMA驅動
據調查64%的人表示:日常生活中不依賴物聯網設備
PHP簡單實現不依賴于Unix系統Cron的定時任務程序資料說明

以色列成立新研究中心,開發不依賴GPS的導航系統
智行者發布國內首款不依賴高精地圖的高級別自動駕駛解決方案
一個種不依賴昂貴檢測設備的偏置電流測試方法
原生鴻蒙系統正式發布,余承東宣布不依賴國外核心技術
NVMe IP over PCIe 4.0:擺脫XDMA,實現超高速!
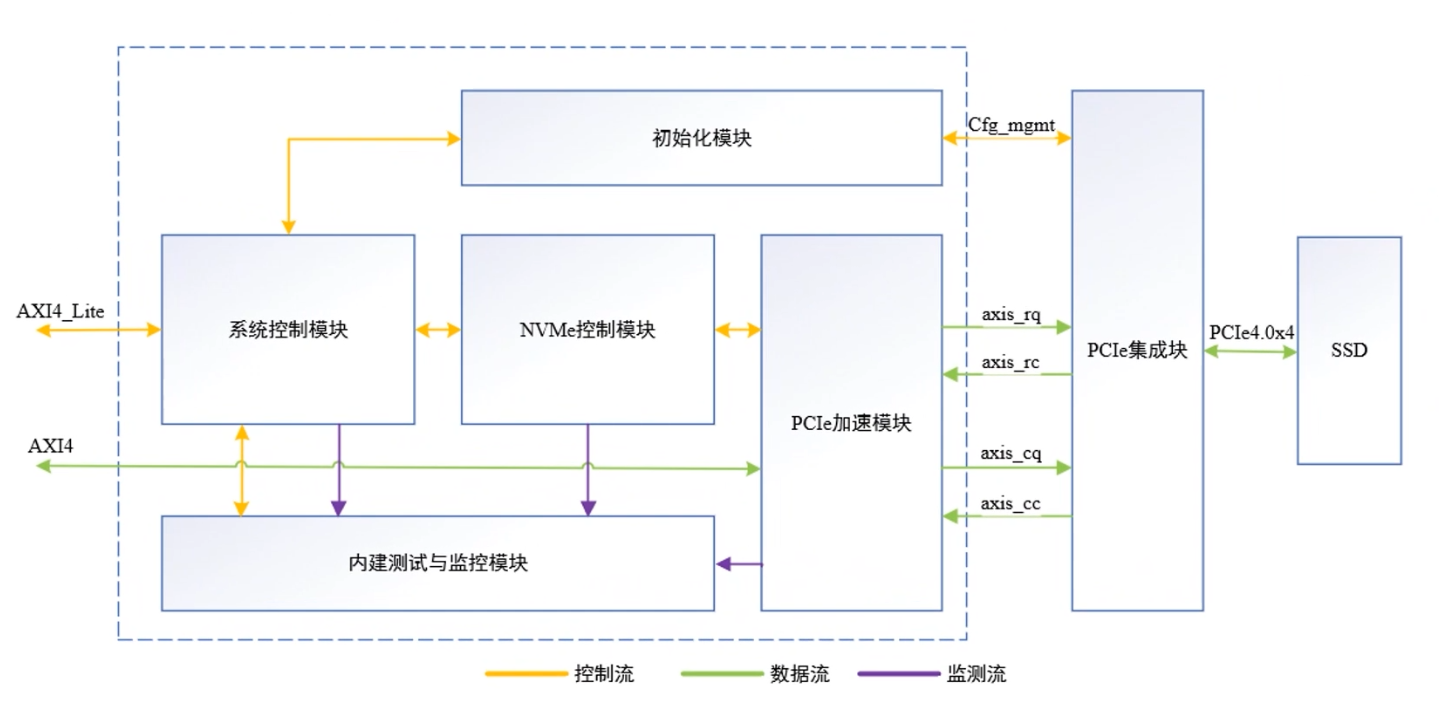
NVMe IP高速傳輸卻不依賴XDMA設計之二:PCIe讀寫邏輯





 工商網監
工商網監
評論