") 自動駕駛中常提的VLA是個啥?
自動駕駛中常提的VLA是個啥?
[首發(fā)于智駕最前沿微信公眾號]隨著自動駕駛技術(shù)落地,很多新技術(shù)或在其他領(lǐng)域被使用的技術(shù)也在自動駕駛行業(yè)中得到了實踐,VLA就是其中一項,尤其是隨著端到端大模型的提出,VLA在自動駕駛中的使用更加普遍。那VLA到底是個啥?它對于自動駕駛行業(yè)來說有何作用?
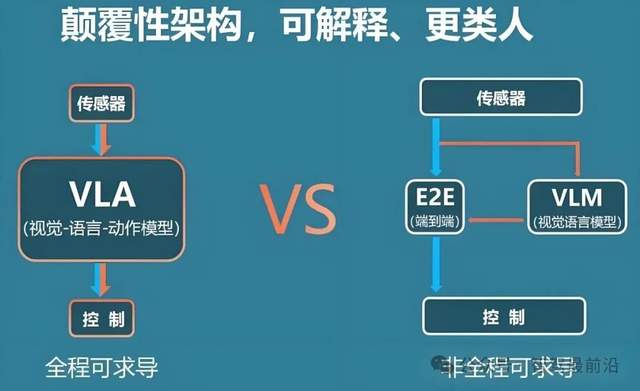
VLA全稱為“Vision-Language-Action”,即視覺-語言-動作模型,其核心思想是將視覺感知、語言理解與動作決策端到端融合,在一個統(tǒng)一的大模型中完成從環(huán)境觀察到控制指令輸出的全過程。與傳統(tǒng)自動駕駛系統(tǒng)中感知、規(guī)劃、控制模塊化分工的思路不同,VLA模型通過大規(guī)模數(shù)據(jù)驅(qū)動,實現(xiàn)了“圖像輸入、指令輸出”的閉環(huán)映射,有望大幅提高系統(tǒng)的泛化能力與場景適應(yīng)性。
VLA最早由GoogleDeepMind于2023年在機(jī)器人領(lǐng)域提出,旨在解決“視覺-語言-動作”三者協(xié)同的智能體控制問題。DeepMind的首個VLA模型通過將視覺編碼器與語言編碼器與動作解碼器結(jié)合,實現(xiàn)了從攝像頭圖像和文本指令到物理動作的直接映射。這一技術(shù)不僅在機(jī)器人操作上取得了突破,也為智能駕駛場景引入了全新的端到端思路。
在自動駕駛領(lǐng)域,感知技術(shù)通常由雷達(dá)、激光雷達(dá)、攝像頭等多種傳感器負(fù)責(zé)感知,感知結(jié)果經(jīng)過目標(biāo)檢測、語義分割、軌跡預(yù)測、行為規(guī)劃等一系列模塊處理,最后由控制器下發(fā)方向盤和油門等動作指令。整個流程雖條理清晰,卻存在模塊間誤差累積、規(guī)則設(shè)計復(fù)雜且難以覆蓋所有極端場景的短板。VLA模型正是在此背景下應(yīng)運(yùn)而生,它舍棄了中間的手工設(shè)計算法,直接用統(tǒng)一的神經(jīng)網(wǎng)絡(luò)從多模態(tài)輸入中學(xué)習(xí)最優(yōu)控制策略,從而簡化了系統(tǒng)架構(gòu),提高了數(shù)據(jù)利用效率。
VLA模型通常由四個關(guān)鍵模塊構(gòu)成。第一是視覺編碼器,用于對攝像頭或激光雷達(dá)等傳感器采集的圖像和點云數(shù)據(jù)進(jìn)行特征提取;第二是語言編碼器,通過大規(guī)模預(yù)訓(xùn)練的語言模型,理解導(dǎo)航指令、交通規(guī)則或高層策略;第三是跨模態(tài)融合層,將視覺和語言特征進(jìn)行對齊和融合,構(gòu)建統(tǒng)一的環(huán)境理解;第四是動作解碼器或策略模塊,基于融合后的多模態(tài)表示生成具體的控制指令,如轉(zhuǎn)向角度、加減速命令等。
在視覺編碼器部分,VLA模型一般采用卷積神經(jīng)網(wǎng)絡(luò)或視覺大模型(VisionTransformer)對原始像素進(jìn)行深度特征抽取;同時,為了增強(qiáng)對三維場景的理解,部分研究引入三維空間編碼器,將多視角圖像或點云映射到統(tǒng)一的三維特征空間中。這些技術(shù)使VLA在處理復(fù)雜道路環(huán)境、行人辨識和物體追蹤上擁有較傳統(tǒng)方法更強(qiáng)的表現(xiàn)力。
語言編碼器則是VLA與傳統(tǒng)端到端駕駛模型的最大差異所在。通過接入大規(guī)模預(yù)訓(xùn)練語言模型,VLA能夠理解自然語言形式的導(dǎo)航指令(如“前方在第二個紅綠燈右轉(zhuǎn)”)或高層安全策略(如“當(dāng)檢測到行人時務(wù)必減速至5公里/小時以下”),并將這些理解融入決策過程。這種跨模態(tài)理解能力不僅提升了系統(tǒng)的靈活性,也為人車交互提供了新的可能。
跨模態(tài)融合層在VLA中承擔(dān)著“粘合劑”作用,它需要設(shè)計高效的對齊算法,使視覺與語言特征在同一語義空間內(nèi)進(jìn)行交互。一些方案利用自注意力機(jī)制(Self-Attention)實現(xiàn)特征間的深度融合,另一些方案則結(jié)合圖神經(jīng)網(wǎng)絡(luò)或Transformer結(jié)構(gòu)進(jìn)行多模態(tài)對齊。這些方法的目標(biāo)都是構(gòu)建一個統(tǒng)一表征,以支持后續(xù)更準(zhǔn)確的動作生成。
動作解碼器或策略模塊通常基于強(qiáng)化學(xué)習(xí)或監(jiān)督學(xué)習(xí)框架訓(xùn)練。VLA利用融合后的多模態(tài)特征,直接預(yù)測如轉(zhuǎn)向角度、加速度和制動壓力等連續(xù)控制信號。這一過程省去了傳統(tǒng)方案中復(fù)雜的規(guī)則引擎和多階段優(yōu)化,使整個系統(tǒng)在端到端訓(xùn)練中獲得了更優(yōu)的全局性能。但同時也帶來了可解釋性不足、安全驗證難度增大等挑戰(zhàn)。
VLA模型的最大優(yōu)勢在于其強(qiáng)大的場景泛化能力與上下文推理能力。由于模型在大規(guī)模真實或仿真數(shù)據(jù)上學(xué)習(xí)了豐富的多模態(tài)關(guān)聯(lián),它能在復(fù)雜交叉路口、弱光環(huán)境或突發(fā)障礙物出現(xiàn)時,更迅速地做出合理決策。此外,融入語言理解后,VLA可以根據(jù)指令靈活調(diào)整駕駛策略,實現(xiàn)更自然的人機(jī)協(xié)同駕駛體驗。
國內(nèi)外多家企業(yè)已開始將VLA思想應(yīng)用于智能駕駛研發(fā)。DeepMind的RT-2模型在機(jī)器人控制上展示了端到端視覺-語言-動作融合的潛力,而元戎啟行公開提出的VLA模型,被其定義為“端到端2.0版本”,元戎啟行CEO周光表示“這套系統(tǒng)上來以后城區(qū)智駕才能真正達(dá)到好用的狀態(tài)”。智平方在機(jī)器人領(lǐng)域推出的GOVLA模型,也展示了全身協(xié)同與長程推理的先進(jìn)能力,為未來智能駕駛提供了新的參考。
VLA雖然給自動駕駛行業(yè)提出了新的可能,但實際應(yīng)用依舊面臨很多挑戰(zhàn)。首先是模型可解釋性不足,作為“黑盒子”系統(tǒng),很難逐步排查在邊緣場景下的決策失誤,給安全驗證帶來難度。其次,端到端訓(xùn)練對數(shù)據(jù)質(zhì)量和數(shù)量要求極高,還需構(gòu)建覆蓋多種交通場景的高保真仿真環(huán)境。另外,計算資源消耗大、實時性優(yōu)化難度高,也是VLA商用化必須克服的技術(shù)壁壘。
為了解決上述問題,也正在探索多種技術(shù)路徑。如有通過引入可解釋性模塊或后驗可視化工具,對決策過程進(jìn)行透明化;還有利用Diffusion模型對軌跡生成進(jìn)行優(yōu)化,確保控制指令的平滑性與穩(wěn)定性。同時,將VLA與傳統(tǒng)規(guī)則引擎或模型預(yù)測控制(MPC)結(jié)合,以混合架構(gòu)提高安全冗余和系統(tǒng)魯棒性也成為熱門方向。
未來,隨著大模型技術(shù)、邊緣計算和車載硬件的持續(xù)進(jìn)步,VLA有望在自動駕駛領(lǐng)域扮演更加核心的角色。它不僅能為城市復(fù)雜道路提供更智能的駕駛方案,還可擴(kuò)展至車隊協(xié)同、遠(yuǎn)程遙控及人機(jī)交互等多種應(yīng)用場景。智駕最前沿以為,“視覺-語言-動作”一體化將成為自動駕駛技術(shù)的主流方向,推動智能出行進(jìn)入新的“端到端2.0”時代。
VLA作為一種端到端多模態(tài)融合方案,通過將視覺、語言和動作三大要素集成到同一模型中,為自動駕駛系統(tǒng)帶來了更強(qiáng)的泛化能力和更高的交互靈活性。盡管仍需解決可解釋性、安全驗證與算力優(yōu)化等挑戰(zhàn),但其革命性的技術(shù)框架無疑為未來智能駕駛的發(fā)展指明了方向。隨著業(yè)界不斷積累實踐經(jīng)驗、優(yōu)化算法與完善安全體系,VLA有望成為自動駕駛領(lǐng)域的“下一代技術(shù)基石”。
審核編輯 黃宇
-
Vla
+關(guān)注
關(guān)注
0文章
7瀏覽量
5755 -
自動駕駛
+關(guān)注
關(guān)注
788文章
14240瀏覽量
169874
發(fā)布評論請先 登錄
自動駕駛中常提的魯棒性是個啥?
FPGA在自動駕駛領(lǐng)域有哪些應(yīng)用?
【話題】特斯拉首起自動駕駛致命車禍,自動駕駛的冬天來了?
自動駕駛真的會來嗎?
自動駕駛的到來
AI/自動駕駛領(lǐng)域的巔峰會議—國際AI自動駕駛高峰論壇
如何讓自動駕駛更加安全?
自動駕駛汽車的處理能力怎么樣?
自動駕駛系統(tǒng)設(shè)計及應(yīng)用的相關(guān)資料分享
自動駕駛技術(shù)的實現(xiàn)
自動駕駛中常提的SLAM到底是個啥?
自動駕駛大模型中常提的Token是個啥?對自動駕駛有何影響?
自動駕駛中常提的“NOA”是個啥?
自動駕駛行業(yè)常提的高階智駕是個啥?
自動駕駛中常提的“點云”是個啥?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論