 智算加速卡是什么東西?它真能在AI戰場上干掉GPU和TPU!
智算加速卡是什么東西?它真能在AI戰場上干掉GPU和TPU!
隨著AI技術火得一塌糊涂,大家都在談"大模型"、"AI加速"、"智能計算",可真到了落地環節,算力才是硬通貨。你有沒有發現,現在越來越多的AI企業不光用GPU,也不怎么迷信TPU了?他們嘴里多了一個新詞兒——智算加速卡。
這篇文章,小頡就站在一個行業老兵的角度,用通俗易懂的內容給大家講清楚:智算加速卡是什么東西?它為什么有本事讓GPU和TPU靠邊站?又能在哪些實際場景里大顯身手?
一、智算加速卡到底是什么東西?
智算加速卡,聽著高大上,其實可以理解為為AI、機器學習、大模型推理訓練等場景量身打造的高性能計算加速硬件。它的“智”不是說它本身智能,而是說它為智能計算服務。
換句話說,智算加速卡就是專為AI這種吃算力的大戶量身定做的“專用加速器”,比起傳統的GPU或TPU,它更強調算力密度、并行處理、模型優化能力。
可能有些行業小白不是很明白智算加速卡、GPU與TPU是什么東西,下面小頡就簡單的給這三者進行釋義:
智算加速卡:智能計算專用加速硬件,用于AI訓練、推理、大數據處理等任務。
GPU:圖形處理器,原本為游戲、圖像而生,后被廣泛用于AI訓練。
TPU:谷歌推出的張量處理器,針對神經網絡做了專用優化。
二、GPU和TPU的優勢在哪?但也有短板
說句公道話,GPU和TPU也是AI發展的老功臣。
加速器 | 優勢 | 短板 |
| GPU | 通用性強,適配多種AI框架;成熟生態;高并行度 | 功耗高、成本貴、資源調度復雜 |
| TPU | 神經網絡優化更深,TensorFlow生態下效率高 | 封閉性強,僅限谷歌生態,通用性較弱 |
但如今AI大模型動輒千億參數,單靠GPU、TPU已經出現力不從心。尤其在企業部署AI時,越來越追求性價比、可定制能力、資源隔離、國產替代等,這時候智算加速卡就殺出來了。
三、那智算加速卡到底強在哪?
1. 定制化設計:不像GPU通用性太強、TPU又太偏科,智算加速卡往往針對特定AI場景(如NLP、CV、大模型推理)設計硬件架構,比如支持更高效的矩陣計算、低精度運算(INT8/BF16)。
2. 算力密度更高:有些智算卡在相同體積內提供更高的TOPS性能。例如某國產智算加速卡,單卡性能可達256TOPS,功耗控制在150W以內。
3. 更強兼容性:不少智算加速卡兼容主流AI框架(PyTorch、TensorFlow、ONNX),還支持國產操作系統和主板平臺。
4. 資源隔離能力:針對數據中心部署,支持多租戶、安全隔離、彈性擴展,是很多云廠商的新寵。
5. 國產化替代優勢:當前政策鼓勵自研,智算卡不少已實現從芯片到驅動全鏈自研,填補了不少空白。
四、真實應用場景有哪些?
1. 大模型推理中心:
像訊飛、百度、阿里等大廠都在部署大模型推理集群,智算加速卡憑借低功耗、高吞吐、兼容主流框架,成為節省能耗的關鍵組件。
2. 邊緣AI部署:
在智慧工廠、智能攝像頭、無人車等場景中,需要在邊緣設備上運行AI推理。智算加速卡因其體積小、功耗低,在這些場景中比傳統GPU更合適。
3. 金融風控+大數據分析:
數據中心利用智算卡加速結構化數據的處理、模型的實時預測,尤其在信貸風控、交易分析中,已經開始替代傳統計算架構。
五、對比實測:智算卡和GPU誰更強?
我們引用一家國內AI初創公司真實部署數據,做個簡單對比:
指標 | 主流GPU A100 | 國產智算卡X100 | 差異 |
| 單卡性能(FP16) | 312 TFLOPS | 240 TOPS | 智算卡略低,但滿足多數推理需求 |
| 功耗 | 400W | 150W | 智算卡節能明顯 |
| 成本 | ¥10萬+ | ¥3~4萬 | 成本大幅降低 |
| 系統集成 | 限定主板+電源需求高 | 可靈活搭配X86/ARM平臺 | 靈活性更高 |
結論很明確:智算加速卡雖不一定全面碾壓GPU,但在推理場景和部署性價比上,勝出一大截。
六、智算加速卡正在成為“新主力”
AI不是實驗室游戲,而是要在金融、制造、教育、政務、醫療等各行業落地。而落地的關鍵是可控、能用、成本低、能量產。
所以,從趨勢來看:在訓練場景,GPU仍占主力;在推理和部署場景,智算加速卡開始大范圍上位;在邊緣智能、國產替代、政企安全等領域,智算卡幾乎是唯一合理選擇。
相關問答FAQs:
Q1:智算加速卡和普通GPU最大的區別是什么?
A1:最大區別在于用途和設計理念。GPU是通用的圖形和計算芯片,智算加速卡是專門針對AI推理和智能計算定制優化的卡片,功耗更低,適配更精準。
Q2:我做AI開發,是不是還得買GPU,不能只用智算卡?
A2:要看你做的是什么。如果是大模型訓練,GPU目前還是主力;但如果你做模型推理部署、邊緣計算、嵌入式AI等,智算加速卡性價比更高。
Q3:國產智算加速卡支持哪些主流AI框架?
A3:目前很多國產卡已支持TensorFlow、PyTorch、ONNX、MindSpore等主流框架,也在不斷完善生態和開發工具包,兼容性不再是瓶頸。
-
智能卡
+關注
關注
0文章
153瀏覽量
25141 -
加速卡
+關注
關注
1文章
63瀏覽量
11141 -
AI加速器
+關注
關注
1文章
70瀏覽量
9002
發布評論請先 登錄
萬卡集群解決大模型訓算力需求,建設面臨哪些挑戰

大模型向邊端側部署,AI加速卡朝高算力、小體積發展
MLU220-M.2邊緣端智能加速卡支持相關資料介紹
LCD轉VGA視頻加速卡
東京論壇2018活動:富士通展示了深度學習芯片DLU和加速卡
AI加速卡電源定時系統
GPU加速卡對PCB性能的作用是什么?
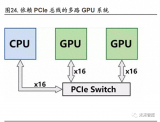
瞬變對AI加速卡供電的影響
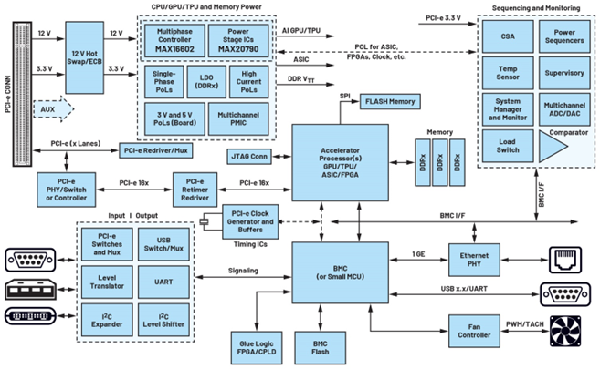
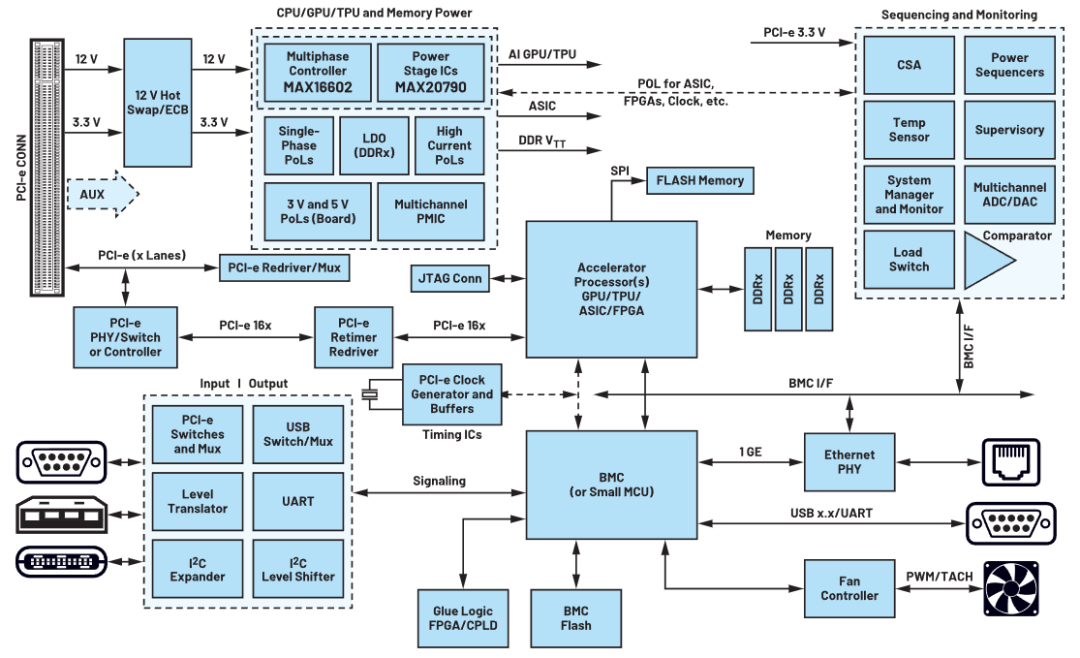
瞬變對AI加速卡供電的影響
研華發布EAI-3100邊沿AI加速卡,搭載英特爾銳炫A370M移動GPU
英偉達發布超強AI加速卡,性能大幅提升,可支持1.8萬億參數模的訓練
英偉達發布最強AI加速卡Blackwell GB200
寒武紀基于思元370芯片的MLU370-X8 智能加速卡產品手冊詳解






 工商網監
工商網監
評論