 從 Java 到 Go:面向對象的巨人與云原生的輕騎兵
從 Java 到 Go:面向對象的巨人與云原生的輕騎兵
Go 語言在 2009 年被 Google 推出,在創建之初便明確提出了“少即是多(Less is more)”的設計原則,強調“以工程效率為核心,用極簡規則解決復雜問題”。它與 Java 語言生態不同,Go 通過編譯為 單一靜態二進制文件實現快速啟動和低內存開銷,以25個關鍵字強制代碼簡潔性,用接口組合替代類繼承,以顯式返回error取代異常機制 和 輕量級并發模型(Goroutine/Channel) 在 云原生基礎設施領域 占據主導地位,它也是 Java 開發者探索云原生技術棧的關鍵補充。本文將對 Go 語言和 Java 語言在一些重要特性上進行對比,為 Java 開發者在閱讀和學習 Go 語言相關技術時提供參考。
代碼組織的基本單元
在 Java 中,我們會創建 .java 文件作為 類(類名與文件名相同),并在該類中定義相關的字段或方法等(OOP),如下定義 User 和 Address 相關的內容便需要聲明兩個 .java 文件(User.java, Address.java)定義類:
public class User {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
public class Address {
private String city;
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
}
而在 Go 語言中,它是通過 “包” 來組織代碼的:每個目錄下的所有 .go 文件共享同一個 包,在包內可以定義多個結構體、接口、函數或變量。它并不要求文件名與聲明的內容一致,比如創建 User “結構體”并不會要求 .go 文件也命名為 User.go,而是任何命名都可以(命名為 user.go 甚至 a.go 這種無意義的命名),而且同一個包下可以創建多個 .go 文件。如下為在 user 包下定義 User 和 Address 相關的內容,它們都被聲明在一個 user.go 文件中:
package user
type User struct {
name string
}
func (u *User) Name() string {
return u.name
}
func (u *User) SetName(name string) {
u.name = name
}
type Address struct {
city string
}
func (a *Address) City() string {
return a.city
}
func (a *Address) SetCity(city string) {
a.city = city
}
相比來說,Java 代碼組織的基本單元是類,作為面向對象的語言更側重對象定義,而 Go 代碼組織的基本單元是包,并更側重功能模塊的聚合。
可見性控制
在 Java 中通過 public/protected/private 關鍵字控制成員的可見性,而在 Go 語言中,通過 首字母大小寫 控制“包級別的導出”(大寫字母開頭為 public),包的導出成員對其他包可見。以 user 包下 User 類型的定義為例,在 main 包下測試可見性如下:
package main
import (
"fmt"
// user package 的全路徑
"learn-go/src/com/github/user"
// 不能導入未使用到的包
//"math"
)
func main() {
var u user.User
// 在這里是不能訪問未導出的字段 name
// fmt.Println(u.name)
fmt.Println(u.Name())
}
Go 語言不能導入未使用到的包,并且函數是基于包的一部分。比如 fmt.Println 函數,這個函數是在 fmt 包下的,調用時也是以包名為前綴。
變量的聲明
在 Java 語言中,對變量(靜態變量或局部變量)的聲明只有一種方式,“采用 = 運算符賦值”顯式聲明(在 Jdk 10+支持 var 變量聲明),如下:
public class Test {
public static void main(String[] args) {
int x = 100;
}
}
而在 Go 語言中,變量聲明有兩種主要方式:短聲明(:= 運算符) 和 長聲明(var 聲明),它們的適用場景和限制有所不同,以下是詳細區分:
短聲明(:=)
只能在函數(包括 main、自定義函數或方法、if/for 塊等)內部使用,不能在包級別(全局作用域)使用,并且 聲明的局部變量必須被使用,不被使用的局部變量不能被聲明:
package main
import "fmt"
func main() {
// 正確
x := 10
fmt.Println(x)
// 未被使用,不能被聲明
// y := 20
// 不賦值也不能被聲明
// z :=
}
// 錯誤:不能在包級別使用短聲明
// y := 20
這種短聲明直接根據右側值自動推斷變量類型,無需顯式指定類型,并且可以一次性聲明多個變量,但至少有一個變量是 新聲明的:
package main
import "fmt"
func main() {
// 同時聲明 a 和 b
a, b := 1, "abc"
// c 是新變量,b 被重新賦值
c, b := 2, "def"
// 無新變量無法再次對已聲明的變量再次聲明
//a, b := 4, "error"
fmt.Println(a, b, c)
}
長聲明(var 聲明)
在全局作用域聲明變量必須使用 var;在需要延遲初始化時也需要采用長聲明;顯示指定類型也需要使用長聲明
package main
import "fmt"
var global int = 42
func main() {
// a = 0
var a int
// s = ""
var s string
// 未被初始化值會默認為“零”值,a 為 0,s 為空字符串
fmt.Println(a, s)
}
函數內部的局部變量,尤其是需要類型推斷和簡潔代碼時優先用短聲明;在包級別聲明變量,需要顯式指定類型或聲明變量但不立即賦值(零值初始化)時,使用長聲明。
在 Go 語言中還有一點需要注意:聲明變量時,應確保它與任何現有的函數、包、類型或其他變量的名稱不同。如果在封閉范圍內存在同名的東西,變量將對它進行覆蓋,也就是說,優先于它,如下所示:
package main
import "fmt"
func main() {
// 這個變量會把導入的 fmt 包覆蓋掉
fmt := 1
println(fmt)
}
那么我們導入的 fmt 包在被局部變量覆蓋后便不能再被使用了。
常量的聲明
Go 語言中對常量的聲明采用 const 關鍵字,并且在聲明時便需要被賦值,如下所示:
package main
import "fmt"
// DaysInWeek const 變量名 類型 = 具體的值
const DaysInWeek int = 7
func main() {
const name = "abc"
fmt.Println(name, DaysInWeek)
}
在 Java 語言中對常量的聲明會使用 static final 引用:
public class Constants {
public static final int DAYS_IN_WEEK = 7;
// ...
}
方法/函數的聲明
在 Go 語言中,方法的聲明遵循 func (接收器) 方法名(入參) 返回值 的格式,無返回值可以不寫(無需 void 聲明),通過 接收器(Receiver) 將方法綁定到結構體上,如下為 User 結構體方法的聲明:
package user
type User struct {
name string
}
// Name (u *User) 即為接收器,表示該方法綁定在了 User 類型上
func (u *User) Name() string {
return u.name
}
func (u *User) SetName(name string) {
u.name = name
}
而“函數”的聲明不需要定義接收器,遵循的是 func 方法名(入參) 返回值 的格式。Go 語言中的函數類似于 Java 語言中的靜態方法,以下是聲明將整數擴大兩倍的函數:
package main
func double(a *int) {
*a *= 2
}
并且,在 Go 語言中,方法/函數支持多返回值(常用于錯誤處理),并且如果并不需要全部的返回值,可以用 _ 對返回值進行忽略,因為Go語言不允許定義未使用的局部變量,如下所示:
package main
import "fmt"
func main() {
// 忽略掉了第三個返回值
s1, s2, _, e := multiReturn()
if e == nil {
fmt.Println(s1, s2)
}
}
func multiReturn() (string, string, string, error) {
return "1", "2", "2", nil
}
此外,接收器參數和函數的形參支持傳入指針,用 * 符號表示。在 Go 語言中有指針的概念,我們在這里說明一下:Go 語言是 “值傳遞” 語言,方法/函數的形參(或接收器)如果不標記指針的話,接收的實際上都是 實參的副本,那么 在方法/函數中的操作并不會對原對象有影響。如果想對原對象進行操作,便需要通過指針獲取到原對象才行(因為值傳遞會對原對象和形參對象都劃分空間,所以針對較大的對象都推薦使用指針以節省內存空間)。在如下示例中,如果我們將上文中 double 方法的形參修改為值傳遞,這樣是不能將變量 a 擴大為兩倍的,因為它操作的是 a 變量的副本:
package main
import "fmt"
func main() {
a := 5
double(a)
// 想要獲取 10,但打印 5
fmt.Println(a)
}
func double(a int) {
a *= 2
}
想要實現對原對象 a 的操作,便需要使用指針操作,將方法的聲明中傳入指針變量 *int:
package main
import "fmt"
func main() {
a := 5
// & 為取址運算符
double(&a)
// 想要獲取 10,實際獲取 10
fmt.Println(a)
}
// *int 表示形參 a 傳入的是指針
func double(a *int) {
// *a 表示從地址中獲取變量 a 的值
*a *= 2
}
再回到 User 類型的聲明中,如果我們將接收器修改成 User,那么 SetName 方法是不會對原變量進行修改的,它的修改實際上只針對的是 User 的副本:
package user
type User struct {
name string
}
// SetName 指定為值接收器
func (u User) SetName(name string) {
u.name = name
}
這樣 SetName 方法便不會修改原對象,SetName 的操作也僅僅對副本生效了:
package main
import (
"fmt"
"learn-go/src/com/github/user"
)
func main() {
u := user.User{}
u.SetName("abc")
// 實際輸出為 {},并沒有對原對象的 name 字段完成賦值
fmt.Println(u)
}
在 Java 中并沒有指針的概念,Java 中除了基本數據類型是值傳遞外,其他類型在方法間傳遞的都是“引用”,對引用對象的修改也是對原對象的修改。
接口
Go 語言也支持接口的聲明,不過相比于 Java 語言它更追求 “靈活與簡潔”。Go 的接口實現是“隱式地”,只要類型實現了接口的所有方法,就自動滿足該接口,無需顯式聲明。如下:
package writer
type Writer interface {
Write([]byte) (int, error)
}
// File 無需聲明實現 Writer,實現了接口所有的方法便自動實現了該接口
type File struct{}
func (f *File) Write(data []byte) (int, error) {
return len(data), nil
}
Java 語言則必須通過 implements 關鍵字聲明類對接口的實現:
public interface Writer {
int write(byte[] data);
}
public class File implements Writer { // 必須顯式聲明
@Override
public int write(byte[] data) {
return data.length;
}
}
它們對類型的判斷也是不同的,在 Go 語言中采用如下語法:
package writer
func typeTransfer() {
var w Writer = File{}
// 判斷是否為 File 類型,如果是的話 ok 為 true
f, ok := w.(File)
if ok {
f.Write(data)
}
}
而在 Java 語言中則采用 instanceof 和強制類型轉換:
private void typeTransfer() {
Writer w = new File();
if (w instanceof File) {
File f = (File) w;
f.write(data);
}
}
Go 語言還采用空接口 interface{} 來表示任意類型,作為方法入參時則支持任意類型方法的傳入,類似 Java 中的 Object 類型:
package writer func ProcessData(data interface{}) { // ... }
除此之外,Go 語言在 1.18+ 版本引入了泛型,采用 [T any] 方括號語法定義類型約束,any 表示任意類型,如果采用具體類型限制則如下所示:
package writer
// Stringer 定義約束:要求類型支持 String() 方法
type Stringer interface {
String() string
}
func ToString[T Stringer](v T) string {
return v.String()
}
通過類型的限制便能使用類型安全替代空接口 interface{},避免運行時類型斷言:
// 舊方案:空接口 + 類型斷言 func OldMax(a, b interface{}) interface{} { // 需要手動斷言類型,易出錯 } // 新方案:泛型 func NewMax[T Ordered](a, b T) T { /* 直接比較 */ }
泛型還在通用數據結構上有廣泛的應用:
type Stack[T any] struct { items []T } func (s *Stack[T]) Push(item T) { s.items = append(s.items, item) }
基本數據類型
Go 的基本數據類型分為 4 大類,相比于 Java 更簡潔且明確:
| 類別 | 具體類型 | 說明 |
|---|---|---|
| 數值型 | int, int8, int16, int32, int64 | Go 的 int 長度由平臺決定(32 位系統為 4 字節,64 位為 8 字節),有符號整數(位數明確,如 int8 占 1 字節) |
| uint, uint8, uint16, uint32, uint64, uintptr | 無符號整數(uintptr 用于指針運算) | |
| float32, float64 | 浮點數(默認 float64) | |
| complex64, complex128 | 復數(實部和虛部分別為 float32 或 float64,Java 無此類型) | |
| 布爾型 | bool | 僅 true/false(不可用 0/1 替代) |
| 字符串 | string | 不可變的 UTF-8 字符序列 |
| 派生型 | byte(=uint8) | 1 字節數據 |
| rune(=int32) | Go 語言的字符(rune)使用 Unicode 來存儲,而并不是字符本身,如果把 rune 傳遞給 fmt.Println 方法,會在控制臺看到數字。雖然 Java 語言同樣以 Unicode 保存字符(char),不過它會在控制臺打印字符信息 |
Go 和 Java 同樣都是 靜態類型語言,要求在 編譯期 確定所有變量的類型,且類型不可在運行時動態改變。Go 不允許任何隱式類型轉換(如 int32 到 int64),但是在 Java 中允許基本類型隱式轉換(如 int → long),除此之外,Go 語言會嚴格區分類型別名(如 int 與 int32 不兼容)。在 Go 語言中如果需要將不同類型的變量進行計算,需要進行類型轉換:
package main
import "fmt"
func main() {
a := 1
b := 2.2
// 如果不類型轉換則不能通過編譯
fmt.Println(float64(a) * b)
}
“引用類型”
在 Go 語言中,嚴格來說并沒有“引用類型”這一官方術語,但在 Go 語言社區中通常將 Slice(切片)、Map(映射)、Channel(通道) 稱為“引用語義類型”(或簡稱引用類型),因為它們的行為與傳統的引用類型相似,在未被初始化時為 nil,并無特定的“零值”。除了這三種類型之外,Go 的其他類型(如結構體、數組、基本類型等)都是 值類型。
Slice
Go 的 Slice 本質上是動態數組的抽象,基于底層數組實現自動擴容。它類似于 Java 中的 ArrayList,采用 var s []int 或 s := make([]int, 5) 聲明,如下:
package main
import "fmt"
func slice() {
// 初始化到小為 0 的切片
s := make([]int, 0)
// 動態追加元素
s = append(s, 1, 2, 3, 4, 5)
fmt.Println(s)
// 子切片,左閉右開區間 sub = {2, 3}
sub := s[1:3]
fmt.Println(sub)
// 修改子切片值會影響到 s 原數組
sub[0] = 99
fmt.Println(s)
}
切片的底層數組并不能增長大小。如果數組沒有足夠的空間來保存新的元素,所有的元素會被拷貝至一個新的更大的數組,并且切片會被更新為引用這個新的數組。但是由于這些場景都發生在 append 函數內部,所發知道返回的切片和傳入 append 函數的切片是否為相同的底層數組,所以如果保留了兩個切片,那么這一點需要注意。
Map
Go 的 Map 本質上是無序鍵值對集合,基于哈希表實現。它的鍵必須支持 == 操作(如基本類型、結構體、指針),聲明方式為 m := make(map[string]int) 或 m := map[string]int{"a": 1},它與 Java 中的 HashMap 類似,如下所示:
package main
import "fmt"
func learnMap() {
m := make(map[string]int)
m["a"] = 1
// 安全的讀取
value, ok := m["a"]
if ok {
fmt.Println(value)
}
delete(m, "a")
}
Channel
Go 的 Channel 是用于 協程(goroutine,Go 語言中的并發任務類似 Java 中的線程)間通信 的管道,支持同步或異步數據傳輸。無緩沖區通道會阻塞發送/接收操作,直到另一端就緒。它的聲明方式為 channel := make(chan string)(無緩沖)或 channel := make(chan string, 3)(有緩沖,緩沖區大小為 3),創建無緩存區的 channel 示例如下:
package main
import "fmt"
// 創建沒有緩沖區的 channel,如果向其中寫入值后而沒有其他協程從中取值,
// 再向其寫入值的操作則會被阻塞,也就是說“發送操作會阻塞發送 goroutine,直到另一個 goroutine 在同一 channel 上執行了接收操作”
// 反之亦然
func channel() {
channel1 := make(chan string)
channel2 := make(chan string)
// 啟動一個協程很簡單,即 go 關鍵字和要調用的函數
go abc(channel1)
go def(channel2)
//
如果創建有緩沖的 channel,在我們的例子中,那么就可以實現寫入協程不必等待 main 協程的接收操作了:
package main
import "fmt"
func channelNoBlocked() {
// 表示創建緩沖區大小為 3 的 channel,并且 channel 傳遞的類型為 string
channel1 := make(chan string, 3)
channel2 := make(chan string, 3)
go abc(channel1)
go def(channel2)
// 輸出一直都會是 adbecf
fmt.Print(
在 Go 中創建上述三種引用類型的對象時,都使用了 make 函數,它是專門用于初始化這三種引用類型的,如果不使用該函數,直接聲明(如var m map[string]int)會得到 nil 值,而無法直接操作。它與 Java 中的 new 關鍵字操作有很大的區別,new 關鍵字會為對象分配內存 并調用構造函數(初始化邏輯在構造函數中),而在 Go 的設計中是沒有構造函數的,Go 語言除了這三種引用類型,均為值類型,直接聲明即可,聲明時便會直接分配內存并初始化為零值。
從失敗中恢復
在 Go 語言中 沒有傳統“異常”概念,它不依賴 try/catch,而是通過 顯式返回錯誤值 和 panic/recover 機制處理。它的錯誤(error)也是普通的數據,能夠作為值傳遞。在多數方法中能看到如下類似的實現:
package main
func main() {
data, err := ReadFile("file.txt")
// 處理錯誤
if err != nil {
log.Fatal(err)
}
// ...
}
func ReadFile(path string) ([]byte, error) {
// 成功返回 data, nil
// 失敗返回 nil, error
}
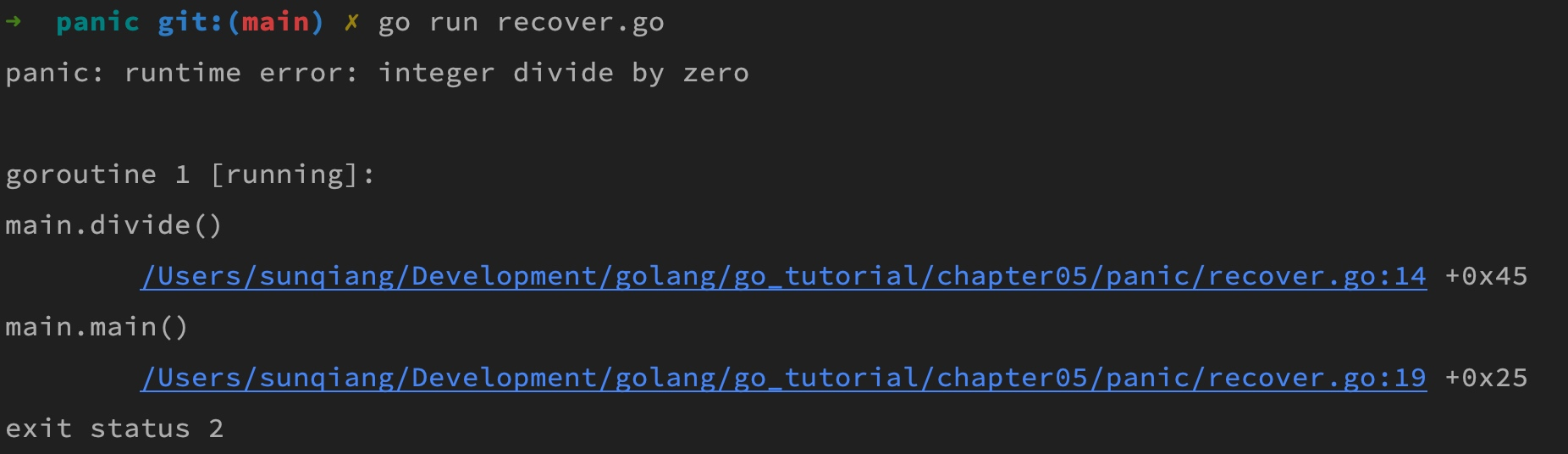
Go 語言使用 panic 來處理不可恢復的或程序無法繼續運行的錯誤(如數組越界、空指針),這類似于 Java 語言中的 throw 異常,它會中斷方法或函數的執行,向上拋出直到遇到 defer 和 recover() 函數的聲明捕獲或者程序崩潰:
// 初始化失敗時觸發 panic
func initDatabase() {
if !checkDatabaseConnection() {
panic("Database connection failed!")
}
}
// 通過 recover 捕獲 panic
func main() {
// 延遲函數的執行
defer func() {
// 使用 recover() 函數嘗試捕獲異常
if r := recover(); r != nil {
fmt.Println("Recovered from panic:", r)
}
}()
initDatabase()
// 正常邏輯...
}
defer 關鍵字 必須修飾的函數或方法,而且被這個關鍵字修飾的函數或方法 一旦注冊 無論如何都會被執行(類似于 Java 中的 finally),但如果 defer 聲明在函數尾部,但函數在運行到該 defer 語句之前就退出(例如中途 return 或 panic),則 defer 不會注冊,也不會執行。所以該關鍵字在資源被初始化之后應該立即使用,而非像 Java 一樣聲明在方法的尾部。而且 defer 支持聲明多個,但執行的順序是逆序的。
revocer() 函數與 defer 關鍵字搭配使用,它會返回函數執行過程中拋出的 panic(未發生 panic 時會為 nil),可以幫助開發者恢復或提供有用的異常信息。
以下是在文件讀取場景 Go 和 Java 語言在語法上的不同:
Go
func readFile() {
file, err := os.Open("file.txt")
if err != nil {
log.Fatal(err)
}
defer file.Close()
// 處理文件內容
}
Java
public void readFile() {
// try-with-resources
try (FileReader file = new FileReader("file.txt")) {
// 處理文件內容
} catch (IOException e) {
System.err.println("Error: " + e.getMessage());
}
}
問:我看到其他編程語言有 exception。panic 和 recover 函數似乎以類似的方式工作。我可以把它們當作 exception 來使用嗎?
答:Go語言維護者強烈建議不要這樣做。甚至可以說,語言本身的設計不鼓勵使用 panic和 recover。在 2012 年的一次主題會議上,RobPike(Go的創始人之一)把 panic 和 recover 描述為“故意笨拙”。這意味著,在設計 Go 時,創作者們沒有試圖使 panic 和 recover 被容易或愉快地使用,因此它們會很少使用。這是 Go 設計者對 exception 的一個主要弱點的回應:它們可以使程序流程更加復雜。相反,Go 開發人員被鼓勵以處理程序其他部分的方式處理錯誤:使用 if 和 return 語句,以及 error 值。當然,直接在函數中處理錯誤會使函數的代碼變長,但這比根本不處理錯誤要好得多。(Go的創始人發現,許多使用 exception 的開發人員只是拋出一個 exception,之后并沒有正確地處理它。)直接處理錯誤也使錯誤的處理方式一目了然,你不必查找程序的其他部分來查看錯誤處理代碼。所以不要在 Go 中尋找等同于 exception 的東西。這個特性被故意省略了。對于習慣了使用 exception 的開發人員來說,可能需要一段時間的調整,但 Go 的維護者相信,這最終會使軟件變得更好。
for 和 if
for
Go 語言的循環語法只有 for,沒有 while 或 do-while,但可實現所有循環模式:
// 1. 經典三段式(類似 Java 的 for 循環)
for i := 0; i < 5; i++ {
fmt.Println(i)
}
// 2. 類似 while 循環(條件在前)
sum := 0
for sum < 10 {
sum += 2
}
// 3. 無限循環(省略條件)
for {
fmt.Println("Infinite loop")
break // 需手動退出
}
// 4. 遍歷集合,采用 range 關鍵字,index 和 value 分別表示索引和值
arr := []int{1, 2, 3}
for index, value := range arr {
fmt.Printf("Index: %d, Value: %dn", index, value)
}
if
Go 語言的 if 語法相比于 Java 支持聲明 + 條件的形式,并且強制要求大括號(即使是單行語句也必須使用 {}):
// 支持簡短聲明(聲明 + 條件)
if num := 10; num > 5 {
fmt.Println("num is greater than 5")
}
// 簡單判斷
if num > 5 {
fmt.Println("num is greater than 5")
}
巨人的肩膀
《Head First Go 語言程序設計》
審核編輯 黃宇
-
JAVA
+關注
關注
20文章
2984瀏覽量
106788 -
Go
+關注
關注
0文章
45瀏覽量
12350
發布評論請先 登錄
云原生在汽車行業的優勢
云原生AI服務怎么樣
云原生LLMOps平臺作用
如何選擇云原生機器學習平臺
什么是云原生MLOps平臺
梯度科技入選2024云原生企業TOP50榜單
云原生和數據庫哪個好一些?
k8s微服務架構就是云原生嗎?兩者是什么關系
開源分析和落地方案—Sentinel篇
云原生和非云原生哪個好?六大區別詳細對比
三十分鐘入門基礎Go Java小子版
京東云原生安全產品重磅發布
從積木式到裝配式云原生安全
基于DPU與SmartNic的云原生SDN解決方案





 工商網監
工商網監
評論