 MemryX 推出浮點運算 AI 芯片,引領精準運算新時代
MemryX 推出浮點運算 AI 芯片,引領精準運算新時代
一、概述
近年來,隨著半導體制程的進步,硬件計算能力和數據量都有了飛躍性的提升,使得 計算機視覺(Computer Vision) 領域迎來了全新的發展階段。過去,圖像處理大多依賴像素級別的逐一運算,而現在,通過 大數據(Big Data) 的支撐以及 深度學習(Deep Learning) 隨著AI模型的成熟,它能夠通過固定的學習模式從海量數據中快速創造出各種各樣的應用。
人工智能技術的普及與邊緣計算在工業與車輛應用中的雙向崛起
在人工智能(AI)技術迅速普及的浪潮中,邊緣計算(Edge Computing) 正成為工業與車輛應用的共同核心推動力。傳統云計算雖然擁有強大的集中處理能力,但在實時性、高數據吞吐量以及敏感數據保護的多場景需求下,逐漸暴露其短板。而邊緣計算的崛起,通過將計算能力分散至工廠現場、設備端及車輛內部,為此提供了解決方案。兩個領域提供了解決方案。
工業應用的價值
■ 降低延遲:就近處理來自傳感器與設備的數據,確保生產線與工業機器人等實時反應能力。
■ 減輕網絡負擔:在邊緣端完成大數據預處理,減少工廠內部和外部網絡的壓力,提升運營效率。
■ 保護隱私:在邊緣完成關鍵工業數據處理,避免敏感生產數據外流,確保企業機密和用戶隱私。
車輛應用的價值
■ 即時決策:車載邊緣設備實時處理攝像頭、LIDAR 和雷達數據,確保自動駕駛汽車的快速決策。
■ 本地運算優化:降低車輛對外部網絡的依賴,并確保在網絡中斷的情況下仍然可靠執行。
■ 數據隱私保障:本地化處理車輛內部數據(如駕駛行為與位置信息),減少對云端的依賴,保護駕駛者隱私。
隨著 2024 年生成式 AI 的爆發,創造出更多 AI 應用需求的多樣化發展,邊緣計算不僅僅是一項輔助技術,更成為現代 AI 應用的重要基石。
MemryX:邊緣計算與浮點計算的革新者
在邊緣計算浪潮中,MemryX 加速卡脫穎而出,憑借其強大的浮點運算能力和全面的軟件支持,成為邊緣 AI 應用的理想選擇。與傳統專注于整型運算的解決方案不同,浮點運算對于需要高度精確的 AI 推理場景至關重要。MemryX 解決方案在低功耗 ( 1W / 5 TFLOPS ) 的情況下提供 20 TFLOPS 的卓越性能,成為物體檢測、圖像識別、肢體識別、語義分割、深度估計和自然語言處理等應用的關鍵推動力。
全面的軟件支持:助力開發者快速部署
MemryX 不僅硬件性能卓越,還提供豐富的軟件生態,包括模塊評估工具、API 接口、驅動程序與開發工具,幫助開發者快速整合并優化 AI 模型運行。其軟件支持涵蓋:
■ 芯片模擬性能(Simulator)
■ 權重精度調整(Weight Precision)
■ 模型裁剪(Model Cropping)工具
■ AI DEMO GitHub 資源
■ 模型庫資源
■ 模型探索器資源
卓越的AI性能
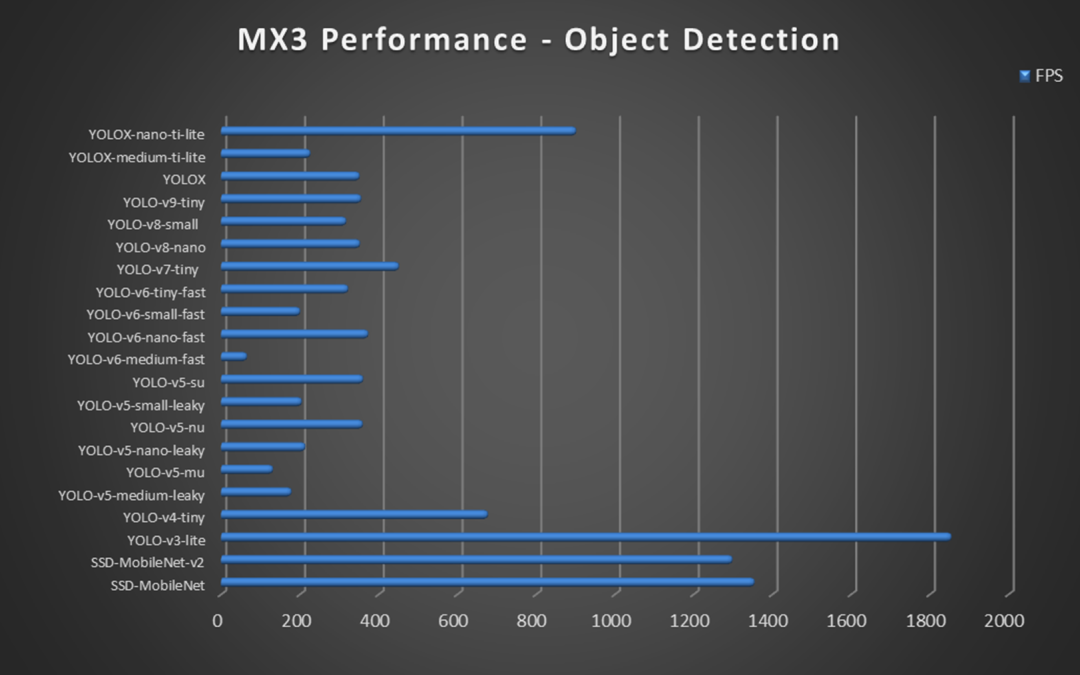
利用 MemryX MX3 芯片運行當前最熱門的 YOLOv8-Nano 目標檢測算法,可輕松達到每秒約 350 張。
二、MemryX:邊緣運算與浮點計算的革新者
MemryX 于2019年由現任密歇根大學電機系的盧偉博士與張正亞博士共同創立,目前由前高通(Qualcomm)副總裁 Keith Kressin 擔任首席執行官。其設計理念主打輕便、小巧、省電、高精度(浮點運算)、可迭代算力、不占用主平臺資源等特點,榮獲2022 EE Awards 亞洲金選獎- 最具潛力產品(Most Promising Product)。同時,活躍于各大社交媒體,趕快加入吧!領英 官方賬號!!即時發布最新的 MemryX 信息。
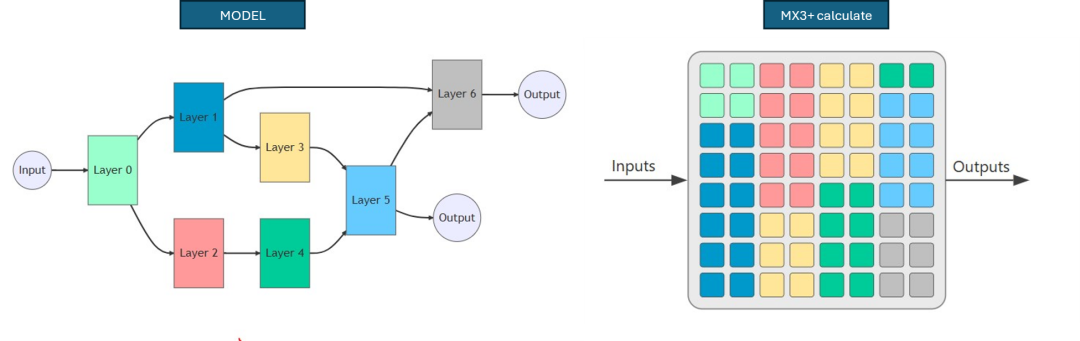
MemryX 最新的 MX3 芯片,具有低功耗、高計算能力 ( 1W / 5 TFLOPS )、高跨平臺整合性等等優勢,其中以 16 位浮點運算 (BF16) 為主,可以確保模型的準確度,并提供豐富的模塊資源與整合套件,能讓用戶體驗更完善的 AI 資源整合,如下圖所示。其中 AI 芯片內部亦有高頻的內存配置,用以消除高運算時所帶來的內存瓶頸。因此需要衡量所使用的模塊大小,一顆芯片大約能夠處理 10 M 參數數據量。舉例來說,A 模塊為 40 M 參數量,則需要搭配 4 顆 MX3 芯片才能使用。
規格

優勢介紹
(1) 采用浮點數 (BF16) 進行計算,確保模塊準確度。
(2) 不占用系統內存
(3) 可擴展性 (最多可連接 16 個芯片)
(4) 最佳數據流優化,能夠最大限度地減少數據移動
(5) 模塊具有最佳可操作性,能夠配合其他硬件加速器進行二次優化
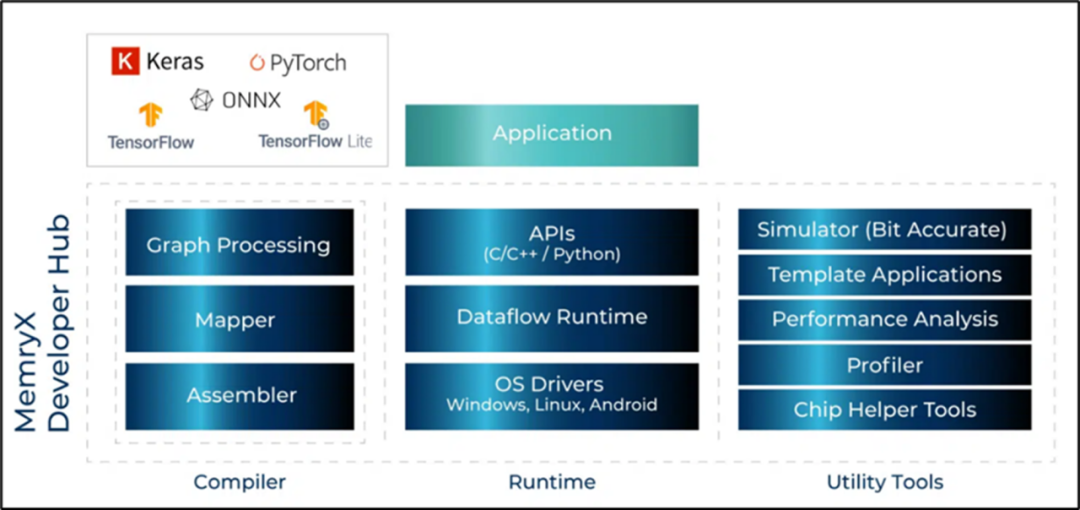
軟件框架 (Software Framework)
MemryX開發者中心包含編譯器(Compiler)、運行時(Runtime)、公用工具(Utility Tools)來驅動旗下的MemryX AI SoCs系列。如下圖所示:
▼ 編譯器(Compiler)
神經編譯器提供多種功能,例如多模型整合(Multi-Model)、模型剪枝(Model Cropping)、多路流輸入單一應用(Multiple Input Streams)、單路流輸入多個應用(Shared Input Stream)、混合精度權重(Mixed-Precision Weights)、模塊資源使用情況顯示(Resources Utilization)。通過簡單的命令行指令,能夠幫助開發者。快速轉換模塊將 Pytorch、Keras、Tensorflow、Tensorflow Lite、ONNX 等模型轉換為 MemryX DFP 模組格式。
▼ 運行器(Runtime)
提供優化的用戶體驗,利用 Benchmark 搭配模型庫能夠幫助開發者快速評估其硬件性能與準確度,并且提供多種開源示例 DEMO ( MemryX Example ) 與簡潔有力的 API 能夠幫助開發者快速實現與部署AI應用。
加速器 API(Python,C/C++)
▼ 公用工具(Utility Tools)
模擬器 (Simulator) : 為 MemryX 提供的軟件,幫助沒有 MX3 芯片的開發者完成性能評估。
可視化工具(Viewer ) : 為 MemryX 提供的 GUI 界面,包括上述編譯器、模擬器、加速器。
檢查器(DFP Inspect): 為 MemryX 提供的一套檢查 DFP 文件的工具。
▼ DEMO 示例
MemryX 原廠提供許多 AI 示例,一步步教導開發者如何實現 AI 應用!
https://github.com/memryx/MemryX_eXamples/tree/release
注意:必須注意以下示例均為開源模型,不能用于商業用途!謝謝。


三、結語
如下列原廠發布的新聞稿提到,MemryX 是如何通過 AI 芯片來改變邊緣人工智能應用的客戶體驗
1. 高幀率 (High FPS)
MemryX 的數據流與內存計算架構適合流水線操作。一張低功耗的 MemryX M.2 卡可以同時處理 10 個攝像頭流,運行一個或多個 AI 模型,特別適合如視頻管理系統等對實時性要求高的應用場景。
2. 高模型精度與自動化編譯
MemryX 提供只需一鍵即可完成高精度 AI 模型編譯的工具。MX3 支持浮點運算 (BF16),能確保模型的準確性與完整性,無需重新訓練模型或進行額外調整。相比于目前主流的整數模塊 (INT),MemryX 能夠讓客戶快速部署高效且準確的 AI 應用。
3. 保持原始模型的完整性
不同于其他解決方案需要改動模型來適配硬件,MemryX 支持直接在 MX3 上編譯與運行原始模型,并提供可選的模型剪枝與壓縮功能以實現設計優化。
4. 自動前/后處理
MemryX 自動識別并打包 AI 模型中的前處理與后處理代碼,幫助開發者快速整合,減少手動調整的復雜度,提升部署效率。
5. 卓越的可擴展性
MX3 可以單芯片使用,也可以多芯片結合為邏輯單元,支持從單臺智能攝像機到 16 芯片邊緣服務器的應用,所有配置共享相同的軟件和接口,無需增加 PCIe 交換器等額外硬件。
6. 低功耗設計
每個 MX3 芯片僅消耗 0.5-2.0 W,而整個 4 芯片 M.2 模組的功耗不到主流 GPU 的十分之一,同時提供更高效的邊緣 AI 性能。
7. 廣泛的軟件與硬件支持
MemryX 支持多種操作系統及 x86、ARM 和 RISC-V 平臺,適配廣泛的硬件環境,為開發者提供靈活性。
因此,MemryX 憑借其創新的 MX3 解決方案,正在重新定義邊緣人工智能的應用范疇從高效的浮點運算能力到豐富的軟件支持,再到可擴展性和低功耗設計,MemryX 正在為邊緣計算的未來奠定堅實的基礎。其核心技術不僅解決了當前市場的諸多痛點,更為開發者和企業用戶提供了靈活、快速且可靠的 AI 部署方案。此外,MemryX 提供多種核心平臺的硬件加速解決方案將 MX3 芯片與周邊硬件整合,更能充分發揮 1+1 大于 2 的平臺性能。
隨著人工智能在零售、汽車、工業、農業和機器人等行業中的廣泛應用,MemryX 正站在邊緣計算技術的前沿,為客戶提供卓越的性能和更高的價值。在未來,MemryX 將繼續推動技術創新,成為 AI 邊緣計算領域中不可或缺的合作伙伴通過上述原廠提供的工具與示例,AI 不再是遙不可及的夢想,只需一步步按照示例步驟操作,就可以快速實現任何智能應用。若想試用或購買 MemryX 產品的新伙伴,請直接聯系伊布小編(email: [email protected])!謝謝!
四、參考文件
[1] MemryX 官方網站
[2] MemryX 開發者中心技術網站
[3] EE Awards 2022 亞洲金選獎
[4] MemryX - LinkedIn 官方賬號
[5] MemryX_示例
[6] PR Newswire - MemryX宣布MX3邊緣AI加速器正式投產
歡迎關注大大通博主:ATU 伊布小編 (一部)
了解MPU技術整合、深度學習、電腦視覺技術與人工智能(AI)的發展等更多相關內容
-
深度學習
+關注
關注
73文章
5554瀏覽量
122484 -
NPU
+關注
關注
2文章
321瀏覽量
19516 -
AI芯片
+關注
關注
17文章
1968瀏覽量
35692
發布評論請先 登錄
Nordic nRF54 系列芯片:開啟 AI 與物聯網新時代?
英偉達GTC25亮點:NVIDIA Blackwell Ultra 開啟 AI 推理新時代
驅動 AI 邊緣計算新時代!高性能 i.MX 95 應用平臺引領未來

邊緣AI新突破:MemryX AI加速卡與RK3588打造高效多路物體檢測方案
舵機精度大揭秘:微米級控制,引領精準定位新時代
【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+內容簡介
FPGA中的浮點四則運算是什么
FPGA中浮點四則運算的實現過程





 工商網監
工商網監
評論