 聲學技術如何重構人機交互生態
聲學技術如何重構人機交互生態

當你的智能音箱能在嘈雜的客廳“聽懂”指令、AI 耳機能在地鐵的轟鳴聲中精準捕捉你的語音、AI硬件能辨識自然界中的各類聲音事件、機器人能通過聲紋與笑聲識別情緒時,一場“聲音智能”的革命正悄然重塑人機交互的底層邏輯。隨著非線性聲學計算與強化學習的深度融合,聲音交互正從“聽得見”邁向“聽得懂”,并逐漸成為 AI 時代的重要接口。
語音Agent:全球行業風向指向何方?
近期,a16z兩位合伙人Olivia Moore和 Anish Acharya在播客訪談中再次重申了a16z在其語音 AI 行業的分析報告中表達的“聲音交互將成為AI應用公司最強大的突破口之一”的觀點,即面向消費者時,聲音交互將成為人們接觸AI的首要方式——甚至可能演變為最主要的交互方式。
Olivia Moore表示,在過去三四個月中,人機交互在降低延遲、提高人性化程度和增強情感表達三個方面上有了飛速的發展。
Anish Acharya也強調了情感表達在人機交互中的重要性:“對于Alexa和Siri來說,即使它們沒有在智能和功能上投入更多,而是在情感表達上加大投入,也能在很大程度上提升消費者體驗。但我感覺這些公司都沒有從這個角度去思考。”
a16z的兩位合伙人表示:“如果建立關系太容易,如果它們總是對你唯命是從,不給你坦誠的反饋,很快就會讓人覺得乏味。作為消費者,一直有個‘應聲蟲’跟著你并沒有什么價值。所以,我們對那些在構建語音Agent時,賦予其獨特角色和個性,讓用戶與之建立情感聯系的創業者非常感興趣。”
如今,多家企業,包括 OpenAI 在內,正嘗試在語音 Agent 中引入“情緒識別”功能,主張機器能夠精準識別對話人的情緒并作出相應反饋。然而,目前面市的語音 Agent 大多仍停留在文本層面的情緒識別,對于嘆氣、笑聲等更為復雜的聲學特征,特別是嬰兒哭聲、貓狗叫聲等聲學事件的敏感度有限。如何在嘈雜、多變的真實環境下,讓機器既能“精準聽見”,又能“深度理解”,成為聲音交互下一階段的關鍵挑戰。
聲智的最新研究表明,非線性聲學計算與強化學習的深度融合,正突破傳統聲學技術在復雜環境中的瓶頸,讓機器不僅能 “聽見” 聲音,更能 “理解” 聲音背后的場景與需求,為人機交互打開 “神經級” 感知的新維度。
“精密耳朵”與“自適應大腦”:
聲音交互的另類創新路線
想象一下,當你在裝修噪音轟鳴的房間試圖喚醒智能音箱,或在高強度混響的地鐵車廂中戴著耳機通話,傳統基于線性模型的聲學技術往往無法做到“既快又準”。波束成形、回聲消除等常規算法很難兼顧實時性和高精度,要么耗時太長、響應延遲,要么簡化模型、識別失真。
而近年來,基于 Westervelt 方程、KZK 方程等物理模型的非線性聲學計算,正在為復雜環境下的精準識音提供全新的思路。聲波在傳播中會因為介質的彈性變化或衍射而產生二次諧波、波形畸變等非線性效應,這些細節過去常被線性模型忽略,卻恰恰是“破解復雜環境下聲音失真密碼”的關鍵。
如果說非線性聲學是機器的“精密耳朵”,那么強化學習則賦予其“自適應大腦”。通過與外界環境持續交互,系統能實時調整降噪參數、優化聲源定位策略,從而在嘈雜、多變的場景中依舊保持高精度捕捉目標聲音。這種“物理模型 + 學習算法”的復合技術框架,不僅彌補了傳統線性聲學對多路徑、混響等問題的局限,更讓整套交互系統實現“聽得清、反應快、適應強”的三重突破。
據聲智最新研究顯示,通過結合非線性聲學與強化學習,聲音交互在底層感知能力上獲得重大提升。面對復雜噪聲環境,語音識別準確率、情緒識別精度和實時性均得到顯著提高,為智能設備真正“聽懂”用戶情緒和環境提供了可能。
也就是說,聲智對應a16z合伙人提出的投資方關注的聲音交互的幾個核心方面,聲智通過將非線性聲學計算與強化學習的深度融合,實現了聲音交互在聲學底層能力上的突破,這也就意味著,語音Agent將通過全場景聲音感知,更好地識別說話人的情緒與環境,并將更加靈活地適應環境與情緒的變化。
聲學重構人機交互生態:
從 “設備” 到 “場景” 的全域滲透
非線性聲學與強化學習的融合框架不僅將成為聲音交互領域具有突破性的底層技術,更重要的是它還將在 AI 硬件、機器聽覺、人工聽覺、腦機接口等領域具有廣闊的應用前景。
AI 耳機不再僅是播放工具,而是通過耳道聲波動態建模與環境噪聲實時分析,自動調節音質與降噪模式;智能音箱借助情感識別技術,根據用戶情緒切換語音反饋 —— 當檢測到焦慮情緒時,會主動降低語速并播放舒緩音樂。這些變革的背后,是聲學技術從 “功能模塊” 到 “核心交互引擎” 的升級。
AI 助聽器通過融合非線性聲學模型與深度學習,能在咖啡館等復雜場景中精準分離人聲與噪聲,將語音清晰度提升 58%;腦機接口技術更實現 “神經信號 - 語音” 的實時轉換,為失語患者提供溝通新途徑,解碼延遲控制在 30ms 以下,接近人類自然交互速度。
當聲音與視覺、觸覺數據深度融合,人機交互進入“立體感知” 時代。智能汽車通過車載麥克風陣列分析駕駛員語氣與環境噪聲,實時判斷疲勞狀態并觸發提醒;服務機器人結合聲紋與唇動信息,在嘈雜展廳中準確理解多語種指令,識別準確率突破 98%。
聲音,正在重新連接人與世界
從人機對話到醫療輔助,從AI硬件到腦機接口,聲學技術正以 “看不見的方式” 重構人機交互的每一個細節。當非線性聲學計算遇見強化學習,當物理模型融合智能算法,聲音不再是簡單的信號,而是承載場景理解、用戶意圖、情感溫度的 “智能紐帶”。
在這個 “萬物互聯” 的時代,聲學技術的突破不僅是一次技術迭代,更是對 “人機關系” 的重新定義 —— 它讓機器真正 “聽懂” 人類的需求。
通過聲學算法與大模型的結合,在全場景感知聲音環境的基礎之上,AI能夠聽懂你的每一聲嘆息和每一份笑容,與你共歡樂、同憂傷,讓《黑鏡》中有關人機交互的終極構想成真,讓交互超越語言的邊界,讓智能設備成為理解環境、適應場景、服務用戶的 “生態伙伴”。
聲智目前致力于“物理模型 + 學習算法” 的復合創新,正在拓展遠場感知、噪聲抑制、情感交互的技術邊界。當聲音的智能滲透到每一個角落,我們迎來的不僅是更便捷的生活,更是一個 “聲臨其境” 的智能時代。
正如 a16z 合伙人所言,只有那些賦予語音 Agent 獨特角色和個性的公司,才能在未來贏得用戶的心。而這背后,恰恰是聲學技術不斷突破所帶來的無限可能。
-
人機交互
+關注
關注
12文章
1242瀏覽量
56317 -
AI
+關注
關注
88文章
34780瀏覽量
277096 -
Agent
+關注
關注
0文章
130瀏覽量
27697
原文標題:聲學計算遇上強化學習:聲音如何成為下一次人機交互的變革引擎
文章出處:【微信號:聲智科技,微信公眾號:聲智科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
中山大學:用于呼吸識別和非接觸式人機交互的均勻快速響應濕度場傳感陣列的可擴展制備

具身智能工業機器人人機交互設計:重新定義人機協作新體驗
愛普生XV7021BB陀螺儀傳感器在人機交互中的應用

為什么開關柜人機交互裝置集成一鍵順控,可以替代開關柜操顯裝置

清華牽頭深開鴻參與:混合智能人機交互系統獲批立項
漢陽大學:研發自供電、原材料基傳感器,開啟人機交互新篇章
啟英泰倫新推出多意圖自然說,重塑離線人機交互新標準!

上海交大團隊發表MEMS視觸覺融合多模態人機交互新進展

芯海科技ForceTouch3.0:重塑人機交互新境界

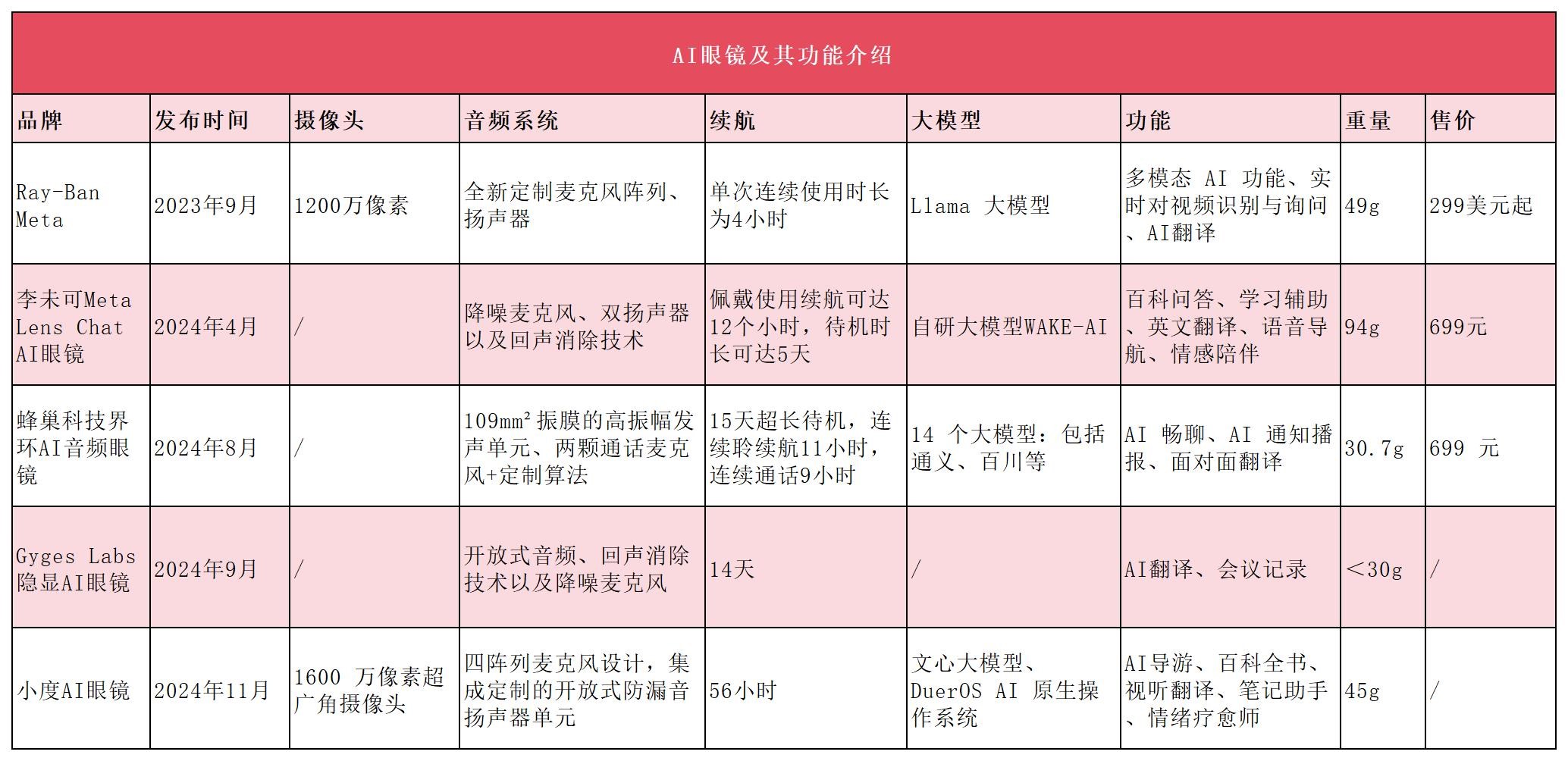
新的人機交互入口?大模型加持、AI眼鏡賽道開啟百鏡大戰





 工商網監
工商網監
評論