") 特征空間在端側的作用
特征空間在端側的作用
作者:蘇勇Andrew
作為一家國際知名半導體公司的人工智能技術專家,我在向客戶介紹瑞薩的AI硬件和AI工具時,總會收到我關于機器學習算法的詢問,例如:卷積神經網絡、K均值算法或其他什么算法。但事實是,在構建人工智能解決方案的過程中,算法并不是最重要的因素(雖然是必要的),尤其是對于端側應用。數(shù)據才是關鍵,一旦有了數(shù)據,真正起決定作用的,其實是隱藏在其中的“特征”(Feature)。
在機器學習的術語中,特征是作為算法輸入的特定變量。特征可以是直接來自于輸入數(shù)據中的原始值,也可以是對這些數(shù)據進行處理(預處理)后間接得到的值。有了合適的特征,幾乎任何機器學習算法都能找到你要找的東西。如果沒有好的特征,任何算法都無濟于事。對于現(xiàn)實世界中的問題來說尤其如此,因為現(xiàn)實世界中的數(shù)據往往帶有大量的固有噪聲和差異,干擾和迷惑我們,妨礙我們直接通過數(shù)據看到真相。
我的同事Jeff(瑞薩AI COE部門的技術總監(jiān),前Reality AI獨立公司的聯(lián)合創(chuàng)始人)喜歡用這樣一個例子跟同事們解釋機器學習中關于特征的概念:
“假設我試圖用人工智能模型檢測我妻子何時回家,我會準備一組傳感器,將其對準門口并收集數(shù)據。為了將這些數(shù)據應用于機器學習,我需要確定一組特征,這些特征能幫助模型將妻子與傳感器可能檢測到的其他任何事物區(qū)分開來。那么,最好用的特征會是什么呢?是能表明“她在那兒!”的那個特征。那將是完美的——一個具有完全預測能力的特征。這樣一來,機器學習的任務就變得輕而易舉了。”
誠然,如果能預知直接從底層數(shù)據中計算出完美特征的算法就最好了,實際上,深度學習通過多層卷積神經網絡踐行了這個思路,但這會帶來大量的計算開銷,并且需要大量的數(shù)據樣本做支撐。正如在前文《深度學習的困局》中所闡述的那樣。不過,還有其他方法,比如,使用Reality AI提供的工具集。
瑞薩的Reality AI工具基于連續(xù)采樣的信號輸入(如加速度、振動、聲音、電信號等等)來創(chuàng)建分類器和探測器,而這些輸入通常帶有大量噪聲和固有的信號波動。我們的價值在于,能夠探索到那些以最低計算開銷實現(xiàn)最強推測能力(關聯(lián)度最高)的特征。Reality AI工具會遵循一套數(shù)學流程,先從數(shù)據中發(fā)現(xiàn)經過優(yōu)化的特征,然后才會考慮使用這些特征來做出決策的算法(SVM或者NN)細節(jié)。Reality AI工具探索到越接近完美的特征,最終得到的推測結果就越好,需要參與訓練和推理過程的數(shù)據更少,訓練時間更少,結果更準確,并且所需的處理能力也更低。經過驗證,行之有效。
這里舉個例子說明有效的特征對后續(xù)判決起到顯著作用。當以比較高的采樣率(50 Hz及以上)對客觀上世界的信號數(shù)據進行分析,比如,從振動或聲音轉化成的電信號進行采樣得到的數(shù)據中發(fā)現(xiàn)某些規(guī)律或模式。在信號處理領域,工程師們通常采用頻率分析方法提取信號特征。對于這類數(shù)據,機器學習的常見做法是,也是對輸入數(shù)據流進行快速傅里葉變換(FFT),然后將這些頻率系數(shù)中的峰值作為神經網絡或其他某種算法的輸入。
為什么采用這種方法呢?
一方面,是因為它很方便,畢竟數(shù)據工程師使用的所有數(shù)據處理工具都支持FFT,例如:MATLAB、Numpy、Scipy。
另一方面,也是因為他們理解這種方法,因為在學校里,每個人都會學習FFT。
同時,也是因為這種方法易于解釋,因為其結果很容易與底層物理原理聯(lián)系起來。
但是,F(xiàn)FT并不是總會提供最優(yōu)的特征,它常會模糊掉重要的時間信息,而這些時間信息對于底層時序信號的分類或檢測可能極為有用。
例如
在一項測試中,將Reality AI優(yōu)化后的特征與FFT在一組中等復雜程度且?guī)в性肼暤男盘柹线M行了比較。在圖1中,展示了針對這一特定信號輸入進行FFT處理后的時頻圖(或稱為頻譜圖)。縱軸是頻率,橫軸是時間,在流信號上的滑動窗口中每次計算FFT。圖中的顏色是熱圖,顏色越暖表示在該特定頻率范圍內的能量越高。
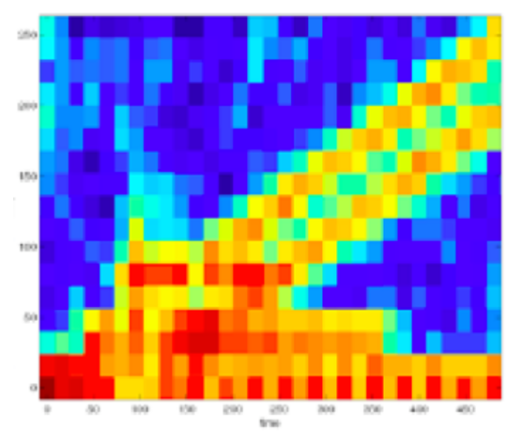
圖1 測試信號的頻譜圖
把現(xiàn)在看到的這張圖,同另一張圖做個對比,見圖2。圖2是對當前這個分類問題,用Reality AI探索到的方法做出來的,它展示的是經過優(yōu)化的特征。在圖2中,細節(jié)展現(xiàn)得更豐富,之前模糊的地方現(xiàn)在都能分辨出來,而且降低了描述的復雜度(不需要使用不同的顏色在第三個維度上表達能量的分布情況)。如此,理解圖中的內容也容易多了。

圖2 測試信號在Reality AI探索到特征空間中的分布
仔細看這個圖,就可以試著解釋這段信號的模式:
最基礎的信號其實是一種低沉的(初始頻率分布在較低的頻段)、帶著好幾種音調(能量分布在多個頻點)的嗡嗡聲
同時還伴隨著一陣一陣逐漸變響的啁啾聲(有效頻率分布的范圍隨著時間的推移在逐步升高)
另外還有一些突然出現(xiàn)又消失的其他信號(隨著時間的推移,在某些頻點出現(xiàn)能量后又消失)。
哈哈,你可能猜到了,這是一種獨特的鳥在傳遞某種信息時發(fā)出的鳴叫聲。
因為用了Reality AI探索出的方法,圖中的信息不再模糊不清,那些干擾的噪聲也被去掉了。所以,即使不是專業(yè)搞信號處理的人,也能一下子能看明白。現(xiàn)在,無論使用什么分類方法,要檢測這些信號可比以前簡單太多了。
一開始就對特征進行優(yōu)化還有另一個關鍵的好處,可以提升最終分類器的計算效率。對于嵌入式解決方案而言,內存空間和計算負載都是最寶貴的資源,如果沒有選對合適的特征,可能會導致最終可用模型的尺寸和計算復雜度急劇攀升,從而導致選型的芯片成本增加。
如前文《深度學習的困局》所述,深度學習也能夠發(fā)現(xiàn)特征,不過效率不高。盡管如此,深度學習方法在處理某些使用信號數(shù)據的問題時非常成功,包括圖像中的物體識別以及聲音中的語音識別。對于廣泛的各類問題,它都是一種可行的方法,但深度學習需要大量的訓練數(shù)據,計算效率不是很高,而且對于非專業(yè)人士來說使用起來可能有難度。分類器的準確性往往對大量的配置參數(shù)有著敏感的依賴,這使得許多使用深度學習的開發(fā)者把大量精力放在調整預訓練的模型上,而不是專注于為每個新問題找到最佳特征。
我的同事Jeff(同時作為數(shù)學家的他)也解釋說,深度學習的本質上是“一種廣義的非線性函數(shù)映射 ——數(shù)學原理很精妙,但與幾乎任何其他方法相比,其收斂速度慢得離譜”。而Reality AI的方法則是針對信號進行了優(yōu)化調整,通過探索和提取有效特征的方法,能夠在使用較少數(shù)據的情況下實現(xiàn)更快的收斂。對于資源有限的端側AI的應用場景,這種方法的效率將比深度學習高出好幾個數(shù)量級。
雖然,深度學習在目前主流的AI產品中取得了顯著的成功,這使得相關領域的人們將更多的關注放到了算法方面。在深度學習及其周邊領域,機器學習算法已經有了大量令人興奮的創(chuàng)新成果。但是,不要忘記一些基本的要義:
歸根結底,一切都來自于數(shù)據,與特征有關。
-
瑞薩
+關注
關注
36文章
22361瀏覽量
87644 -
AI
+關注
關注
87文章
33789瀏覽量
274615 -
機器學習
+關注
關注
66文章
8482瀏覽量
133949
原文標題:嵌入式AI技術漫談 | 特征空間在端側的用武之地
文章出處:【微信號:瑞薩MCU小百科,微信公眾號:瑞薩MCU小百科】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
端側AI浪潮已來!炬芯科技發(fā)布新一代端側AI音頻芯片,能效比和AI算力大幅度提升

基于回路神經網絡的特征子空間估值算法
新的空間關系特征的圖像檢索方法
如何進行雙側空間窗的異常檢測詳細方法概述

MindSpore在LiteOS端側AI技術實踐及探索
基于空間特征的遙感圖像場景分類方法
端側softmax推理的數(shù)學等價優(yōu)化

時擎科技與Sensory聯(lián)合發(fā)布端側多語種語音交互和識別方案

榮耀引領端側AI新時代

創(chuàng)星未來訪談|時擎科技:端側智能芯片領域的新銳力量
【一文看懂】什么是端側算力?

華邦電子創(chuàng)新存儲賦能端側智能端側






 工商網監(jiān)
工商網監(jiān)
評論