 基于DBFP與DB-Attn的算法硬件協同優化方案
基于DBFP與DB-Attn的算法硬件協同優化方案
本文討論了LLM推理過程對計算資源需求急劇攀升的背景下,現有量化和剪枝技術、新數據格式存在的不足,提出動態塊浮點數(DBFP)及其配套算法-硬件協同框架DB-Attn以解決這些問題。
序言
近年來,以LLaMA和Mistral為代表的大型語言模型(Large Language Models, LLMs)在自然語言理解、生成和多模態任務中展現了革命性的能力。然而,隨著模型規模的指數級增長,其推理過程對計算資源的需求急劇攀升,尤其體現在內存帶寬占用和算力消耗上。
量化和剪枝技術通過減少模型的大小和計算復雜度,在一定程度上緩解了資源壓力,但往往伴隨著模型精度的顯著下降,并且需要復雜的后訓練過程。新的數據格式,如 BF16 和 TF32,相較于標準的 FP32 在計算成本上有所降低,但對于大規模、低成本的推理任務而言,仍然不夠理想。
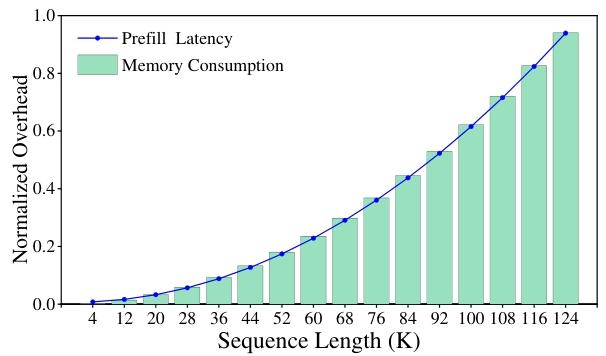
此外,大模型推理計算資源消耗的增幅與輸入序列長度同樣呈現顯著相關性——當處理長文本序列時,非線性運算模塊逐漸成為制約推理效率的關鍵瓶頸。具體而言,模型中廣泛采用的Softmax、LayerNorm和GELU等非線性操作仍嚴重依賴標準浮點計算范式,導致計算效率顯著低于線性運算模塊。Softmax 層的計算時間在 LLMs 總推理時間中占比超過 30%,且 Attention 層的計算復雜度與輸入長度呈二次方關系,導致隨著序列長度增加,計算負擔急劇加重。在 LLaMA3-8B 模型中,隨著序列長度增長,內存消耗和延遲呈現超線性增長,嚴重影響了模型的推理效率。
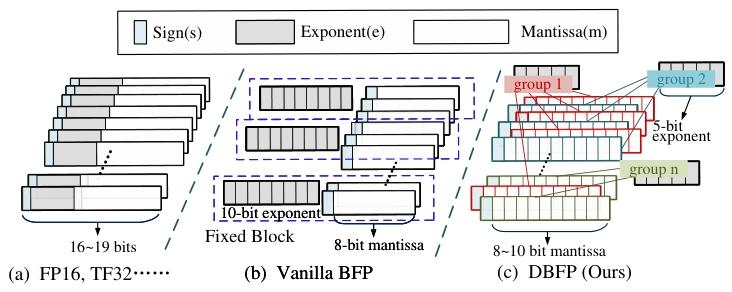
塊浮點(BFP)格式的出現為解決這些問題帶來了新的思路。BFP 通過讓一組定點數共享指數,將浮點運算轉換為定點運算,在為 DNNs 推理提供廣泛動態范圍的同時,有效降低了硬件開銷,在加速線性運算方面表現出顯著優勢。但目前 BFP 的研究主要集中在線性運算,在非線性運算領域的研究尚顯不足。
塊浮點數(Block Floating Point, BFP)作為一種高效數值表示格式,通過塊內共享指數將浮點運算轉換為定點運算,在GEMM(通用矩陣乘法)等線性操作中展現出顯著優勢。然而,現有BFP研究存在三大局限:
對齊策略僵化:傳統BFP以塊內最大值為對齊基準,導致小數值因過度右移而精度丟失,在Softmax中尤其致命;
分組機制固定:靜態分組無法適應數據分布的動態變化,異常值(Outliers)易破壞塊內數值對齊;
非線性支持不足:非線性操作需復雜函數計算(如指數、對數),但目前 BFP 的研究主要集中在線性運算,在非線性運算領域的研究尚顯不足,同時現有BFP硬件設計缺乏相關針對性優化。
本文提出動態塊浮點數(Dynamic-BFP, DBFP)及其配套算法-硬件協同框架DB-Attn,首次將BFP擴展至非線性操作領域。DBFP通過樞軸聚焦策略(Pivot-Focus Policy)和自適應分組策略(Adaptive Grouping Strategy)動態調整指數對齊方式,結合動態分層查找表(Dynamic Hierarchical LUT, DH-LUT)實現非線性函數的高效近似。硬件層面,設計基于RTL的DBFP引擎,支持FPGA與ASIC部署。實驗表明,DB-Attn在LLaMA-7B的Softmax計算中實現74%的GPU加速,ASIC設計較SOTA方案性能提升10倍,同時模型精度損失可忽略(零樣本任務平均下降<0.1%)。
相關工作
2.1面向LLM的數據格式優化
主流低精度格式可分為三類:
BF16 格式采用 16 位表示,其中 8 位用于指數,7 位用于尾數,在一定程度上減少了存儲和計算開銷,適用于一些對精度要求不是極高的深度學習任務。TF32 格式是 NVIDIA 在 A100 GPU 中引入的 19 位浮點格式,結合了 FP32 的動態范圍和 BF16 的計算效率,在深度學習計算中表現出較好的性能,但其硬件計算單元仍需浮點邏輯,功耗較高。
低比特定點數據類型,如 INT4,通過固定浮點比特數將運算轉換為整數運算,計算效率較高,但在處理大動態范圍數據時,由于精度有限,容易導致模型性能下降。
冪次量化格式通過將乘法運算替換為移位操作來簡化計算,在某些場景下提高了計算速度,但這種格式在處理復雜數值計算時存在局限性,無法靈活適應各種計算需求。
BFP通過塊內共享指數,在動態范圍與計算效率間取得平衡。然而,現有BFP方案存在兩大缺陷:其一,靜態分組策略對異常值敏感,導致塊內對齊誤差累積;其二,缺乏對非線性操作的適配,如Song等人設計的BFP加速器僅支持GEMM,Softmax仍需回退至FP32計算。
2.2非線性操作加速算法
非線性操作的硬件優化集中于兩類方法:
基于 LUT 的方法通過預先計算并存儲函數值,在計算時直接查找對應結果,具有較高的準確性。在 Softmax 運算中,可使用 LUT 存儲指數函數的計算結果,加快運算速度。然而,這種方法需要大量存儲空間來存儲查找表,當函數輸入范圍較大或精度要求較高時,存儲開銷會顯著增加。
近似算法通過對復雜函數進行近似計算來提高計算效率,使用多項式逼近或其他近似方法來計算非線性函數。隨著計算單元的增大,近似算法的準確性通常會有所提高,但計算復雜度也會相應增加,并且在某些情況下可能會引入較大的誤差。
基于 LUT 的方法通過預先計算并存儲函數值,在計算時直接查找對應結果,具有較高的準確性。在 Softmax 運算中,可使用 LUT 存儲指數函數的計算結果,加快運算速度。然而,這種方法需要大量存儲空間來存儲查找表,當函數輸入范圍較大或精度要求較高時,存儲開銷會顯著增加。
近似算法通過對復雜函數進行近似計算來提高計算效率,使用多項式逼近或其他近似方法來計算非線性函數。隨著計算單元的增大,近似算法的準確性通常會有所提高,但計算復雜度也會相應增加,并且在某些情況下可能會引入較大的誤差。
當前方案在精度與效率間難以兼顧:LUT需要高容量SRAM存儲,而多項式近似在非線性區域誤差顯著。DB-Attn通過DH-LUT實現動態非均勻分區,結合DBFP的共享指數特性,顯著降低存儲需求。
本文工作
3.1動態塊浮點數(Dynamic Block Floating-Point, DBFP)
DBFP的核心目標是優化傳統BFP在非線性操作中的局限性。傳統BFP將一組數據共享一個指數e8,通過將各元素的指數對齊至塊內最大值emax,將浮點運算轉換為定點運算。然而,這種對齊方式導致小數值的尾數因過度右移而精度丟失,公式化表示為:
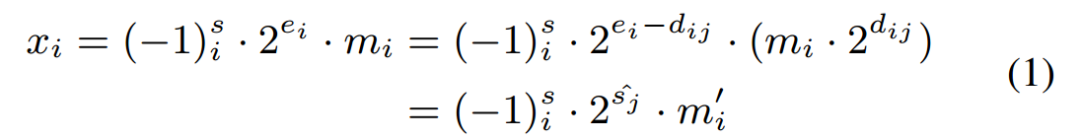
其中,dij= ei ? 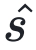 j?表??xi?的指數與第?j?個共享指數之間的差值。由于尾數與 2dij?相乘(移位?dij?位)時的有限精度,這種對??式會引?誤差。該誤差取決于距離?dij,??dij?由輸?指數?ei?決定。當 ei = emax?時,?數值的?dij?較?,尾數有效位被截斷,誤差顯著。
j?表??xi?的指數與第?j?個共享指數之間的差值。由于尾數與 2dij?相乘(移位?dij?位)時的有限精度,這種對??式會引?誤差。該誤差取決于距離?dij,??dij?由輸?指數?ei?決定。當 ei = emax?時,?數值的?dij?較?,尾數有效位被截斷,誤差顯著。
在 BFP 的基礎上,DBFP 對其進?了進?步的優化。BFP 將?組數據表?為共享指數和私有尾數的形式,? DBFP 則更加靈活地確定共享指數和分組?式。通過對數據分布的分析,DBFP 選擇更具代表性的值,如中位數,作為對?樞軸,?不是像傳統 BFP 那樣使?最?值。這種樞軸聚焦策略能夠更好地平衡數據的準確性,減少因異常值導致的精度損失。在 Softmax 運算的實驗中,傳統 BFP 以最?值為對??向導致的損失?以中位數為對??向?出 9.6 倍。
為了減少異常值對指數共享的影響,DBFP 引?了?適應分組策略。通過對數據的分析,將具有相似數量級分布的元素劃分為?組,使得同?組內元素的指數差異較?,從?減少了因指數對??產?的?特移位,降低了計算誤差。在處理包含異常值的數據時,?適應分組策略能夠將異常值單獨處理,避免其對其他數據的指數共享產?過?影響。
DBFP數學優化?標定義為:
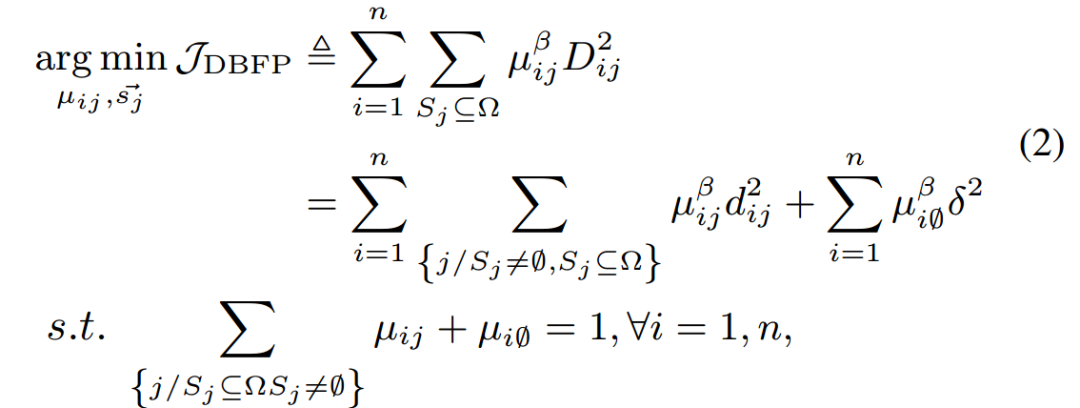
其中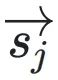 表?向量空間中從原點到點
表?向量空間中從原點到點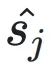 的?向和??的向量。移位向量
的?向和??的向量。移位向量
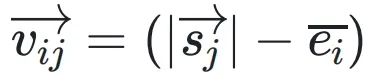
決定了每個xi相對于共享指數的移位量。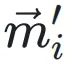 和
和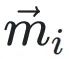 分別表?轉換前后尾數的投影,它們的歐??得距離為
分別表?轉換前后尾數的投影,它們的歐??得距離為
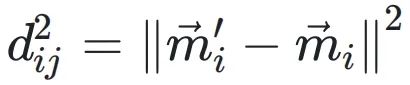
。μij表?xi落在由定義的區間內的置信度。
在公式2中,超參數β(默認值為2)?于調節μij的重要程度。為了減輕異常值對選擇的影響,引?了?個空集來處理這些異常值,μi0表?異常值屬于該空集的置信度。異常值與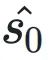 之間的距離記為δ2,D2ij與所有Sj的距離總和相關,其定義為:
之間的距離記為δ2,D2ij與所有Sj的距離總和相關,其定義為:
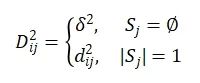
通過交替固定變量并求解約束最小化問題,得到了最優的共享指數集合,從而實現了自適應分組策略和樞軸聚焦策略的優化。
3.2DB-Attn算法設計
DB-Attn是基于DBFP的軟硬件協同優化框架,旨在提高Attention層的計算效率。該框架通過優化Softmax運算和矩陣運算,充分利用DBFP的特性,減少了浮點運算的需求,提高了計算吞吐量。
3.2.1DH-LUT
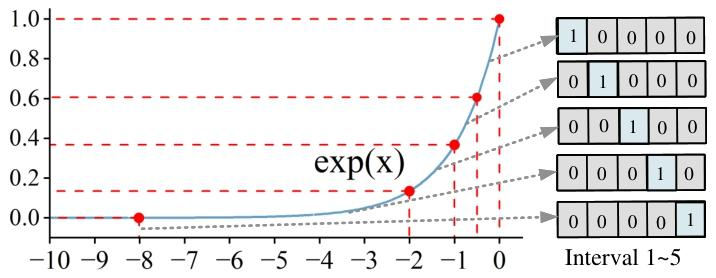
為了優化Softmax運算,DB-Attn提出了動態分層查找表(DH-LUT)算法。DH-LUT是一種緊湊、輕量級的LUT,它根據DBFP數據的共享指數動態加載子LUT,并利用尾數的高k位進行查找。
對于Softmax中的指數函數,DH-LUT僅對[-∞, 0]范圍進行擬合,因為在Softmax的計算中,通過對指數進行降尺度變換(如 ex?xmax),數據主要集中在該范圍內。DH-LUT支持非均勻擬合,通過在樞軸聚焦策略下對齊指數,能夠更好地保留較小的值,并聚焦于函數的非線性顯著部分。為了進一步優化DH-LUT的準確性和內存使用,設計了一種非均勻分層分配方法,根據目標擬合函數自適應地確定最優分區點,將更多的表項分配給非線性區域,以實現更精確的逼近。
基于DH-LUT的Softmax計算選擇以中位數指數為對齊方式,能夠在保證準確性的同時,平衡計算效率。由于DH-LUT中存儲的數據均為DBFP格式,其共享指數的特性使得計算不僅可以在浮點域進行,還可以在計算資源有限的設備上進行整數運算,從而提高了Softmax算法在不同平臺上的適用性和計算速度。
3.2.2級聯矩陣乘法優化
將DBFP應用于Attention中的矩陣運算,能夠顯著提高計算效率。在DBFP格式下,向量可以表示為共享系數和整數向量的乘積,向量點積和矩陣乘法可以通過整數乘法單元和整數加法器實現,避免了復雜的浮點運算。兩個DBFP格式的向量
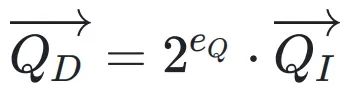
和
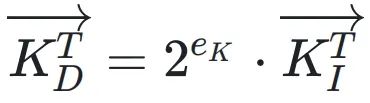
進行點積運算時,結果為

,可以通過整數運算高效實現。
這種特性使得DBFP矩陣乘法具有級聯效應,即兩個DBFP矩陣相乘的結果仍然是DBFP矩陣,可以無縫地連接進行后續的矩陣乘法運算,而無需額外的處理。對于細粒度塊的DBFP矩陣,在級聯運算中可以通過硬件移位操作高效地進行重新對齊,進一步提高了計算效率。
3.3算法驅動的硬件架構
為了支持DB-Attn算法,我們設計并實現了一種基于RTL級的DBFP引擎,該引擎適用于FPGA和ASIC,能夠有效提高Softmax運算的硬件性能。
該加速器的架構分為四個流水線階段:
Max階段:定位輸入向量中的最大值xmax,為后續指數對齊提供基準;
SE階段(Shared Exponent):
?根據樞軸策略計算共享指數es,并對齊尾數;
?觸發DMA預加載DH-LUT中對應區間的數據;
Exp階段:
?并行查表計算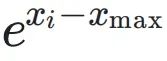 ;
;
?使用加法樹累加分母和;
Div階段:將分子與分母和相除,完成歸一化。
采用動態分層非均勻LUT策略,通過從向量元素中提取 n 位創建一個 2n項的表,在保證準確性的同時,有效控制了表的大小。該設計使用兩個表:一個值表用于存儲近似的指數值,一個命中位圖表用于記錄尾數的出現情況。輸入向量可以并行地在這兩個表中進行查找,每個指數索引對應一個DH-LUT區間,并設置相應的位圖位。通過加法樹結構對兩個表的值進行相乘和求和,實現了并行查找結果,且無需額外的硬件資源。
DBFP能夠將浮點運算轉換為整數運算,這是其在硬件計算中的關鍵優勢。在神經網絡的向量加法運算中,傳統的浮點加法需要對每對數字進行指數對齊,而DB-Attn通過在組內預對齊指數,將運算簡化為指數乘法和尾數加法。在加法樹結構中,通過一次初始的指數對齊,就可以直接進行尾數計算,實驗證明,在4級加法樹中,使用DBFP可以將延遲降低42%。
在非線性運算中,除法操作通常是并行計算的瓶頸,如在Softmax和Layernorm中。DBFP的共享指數特性使得可以通過整數近似高效地進行除法運算。傳統的FP16串行除法器資源消耗大,10位尾數計算需要11個周期的移位操作,占用了超過90%的面積和功耗。而基于DBFP的除法器策略借鑒了相關的研究成果,使用LUT和移位加法操作,將11個周期的操作壓縮為1個周期,大大提高了計算速度。在Softmax應用中,當除數固定且DBFP指數相同時,每64次除法僅需進行一次指數減法和查找操作,顯著降低了資源利用率和延遲,實驗證明,該除法單元能夠將延遲降低83%。通過這些優化,DBFP使得FP16運算可以僅使用10位整數運算實現,有效降低了計算開銷,特別有利于對比特寬度敏感的乘法和除法運算。

評估
4.1 DB-Attn 的準確性結果
4.1.1 LLM任務
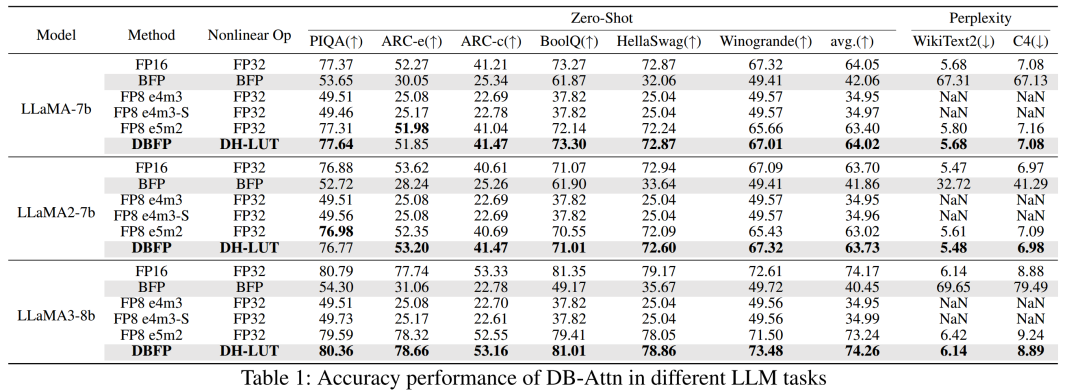
在語言生成任務和六個零樣本任務中,對 DB-Attn 的準確性進行了評估,并與傳統的 BFP 和 FP8 格式進行了比較。以 LLaMA 系列模型為例,直接將傳統 BFP 格式應用于 Softmax 操作會導致顯著的準確性下降,如 LLaMA3 在零樣本任務上的平均準確率下降了 33.81%。FP8 e4m3 格式由于無法表示無窮大,在 Attention 計算中表現不佳。而 DB-Attn 在所有評估任務中均優于傳統 BFP 和 FP8 格式,能夠保持與浮點運算幾乎相同的準確性。在不同的數據集上,如 PIQA、ARC 等,DB-Attn 的零樣本困惑度與浮點運算結果相近,證明了其在保持模型性能的同時,能夠有效降低計算開銷的優勢。
4.1.2 視覺任務
在目標檢測和圖像分類任務中,評估了 DB-Attn 的性能。使用流行的 ViT 和 Swin 骨干網絡在 ImageNet 數據集上進行圖像分類實驗,以及利用 Detr 在 COCO 數據集上進行目標檢測實驗。結果表明,DB-Attn 的性能與在 LLMs 任務中的表現相似,能夠無損地集成到現有的 Transformer 模型中,展示了其在不同任務和數據分布上的泛化性和通用性。在不同模型和數據集上,DB-Attn 的準確率與浮點運算相當,證明了其在視覺任務中的有效性。

4.1.3 DH-LUT 比特精度 - 準確率帕累托前沿
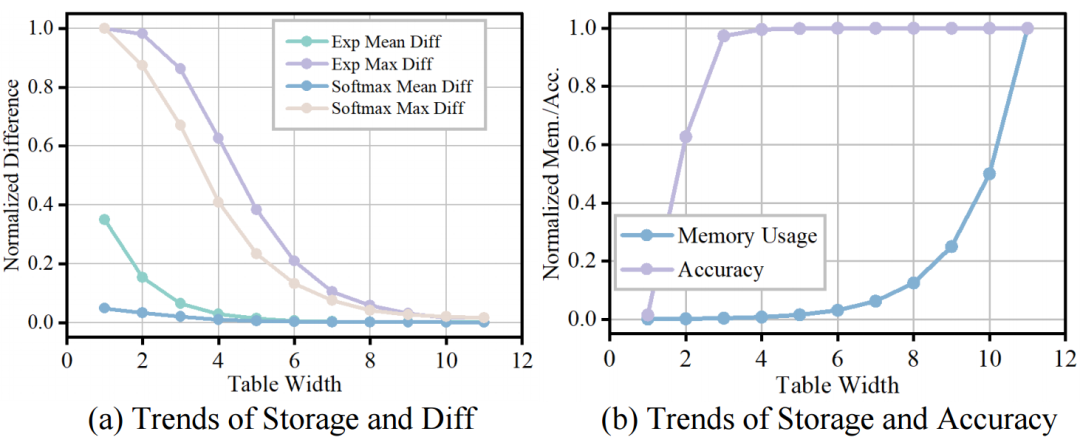
通過測試 DB-Attn 中 Softmax 在不同 LUT 比特寬度下的計算誤差、LUT 內存使用和實際模型準確性,尋找 LUT 比特寬度配置的帕累托前沿。實驗結果表明,當 LUT 比特寬度在 5 - 7 之間時,能夠在計算誤差、內存使用和準確性之間實現較好的平衡。在這個范圍內,隨著 LUT 比特寬度的增加,計算誤差逐漸減小,模型準確性逐漸提高,但內存使用也會相應增加。通過合理選擇 LUT 比特寬度,可以在保證模型性能的前提下,優化計算資源的使用。
4.2 硬件實現評估
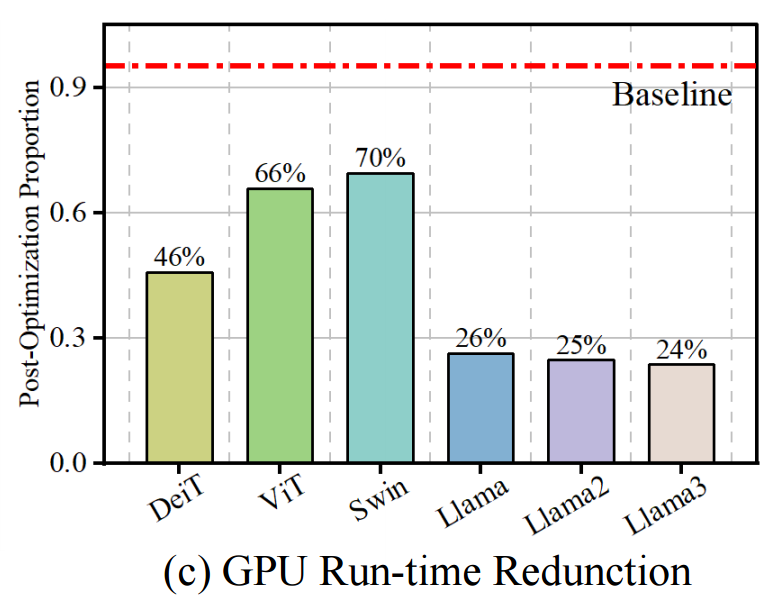
在NVIDIA A800 GPU上實現了自定義的CUDA Softmax算子來模擬DBFP格式,并在多種模型(如LLaMA和ViT)上進行推理。結果顯示,基于DBFP的Softmax在不同模型架構上均實現了至少30%的速度提升,在LLaMA系列模型上平均延遲降低了74%。這表明DBFP能夠有效加速Softmax運算,提高模型的推理效率。
在FPGA上對設計進行了評估,并與當前最先進的設計進行了比較。評估指標包括Softmax操作的處理延遲、FPGA資源利用率(以LUT和觸發器FF為指標)、最大可實現的工作頻率以及綜合性能指標FOM(定義為
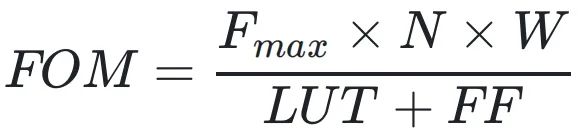
,其中W和N分別表示輸入的精度和數量,FOM值越高表示性能越好)。與現有Softmax加速器相比,本文設計能夠適應更大的輸入帶寬,在輸入序列長度為1024(現代LLMs常用的設置)的情況下,使用的資源比Xilinx FP少54.21%,處理延遲降低了62.5%,計算帶寬提高了128倍,FOM值提高了至少10倍,充分展示了DBFP在FPGA硬件實現上的優勢。
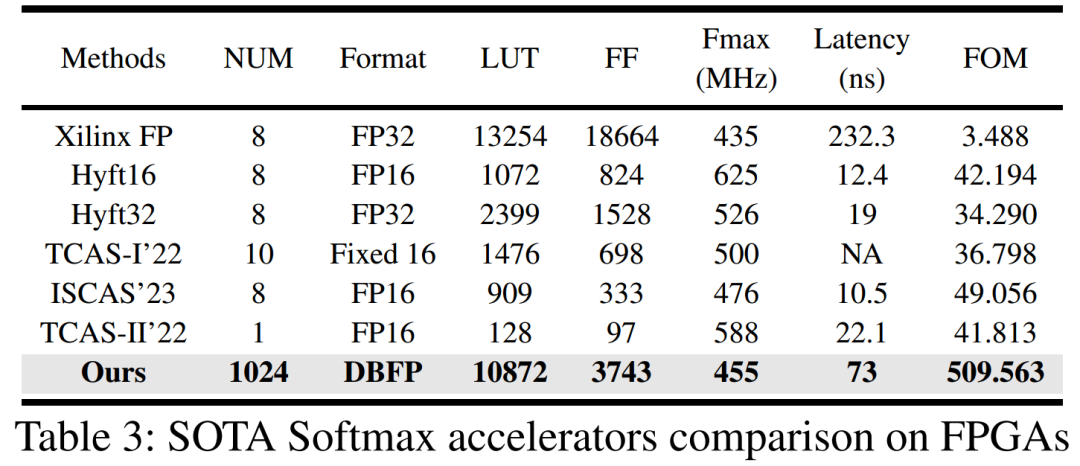
在ASIC上進行了實現,以獲得更準確的功耗、最大時鐘頻率和可擴展性數據。使用面積 - 延遲積(ADP)、能量 - 延遲積(EDP)、整體效率和吞吐量(Freq × Bandwidth)等指標對設計進行評估。在輸入序列長度為1024的統一場景下,將實驗結果歸一化到28nm工藝。與最先進的設計相比,本文設計雖然面積增加了約10%,但在能耗和吞吐量方面有顯著提升,超過10倍。這表明在實際應用中,雖然需要額外的面積,但可以通過性能和效率的大幅提升來彌補,這種權衡是可接受的。
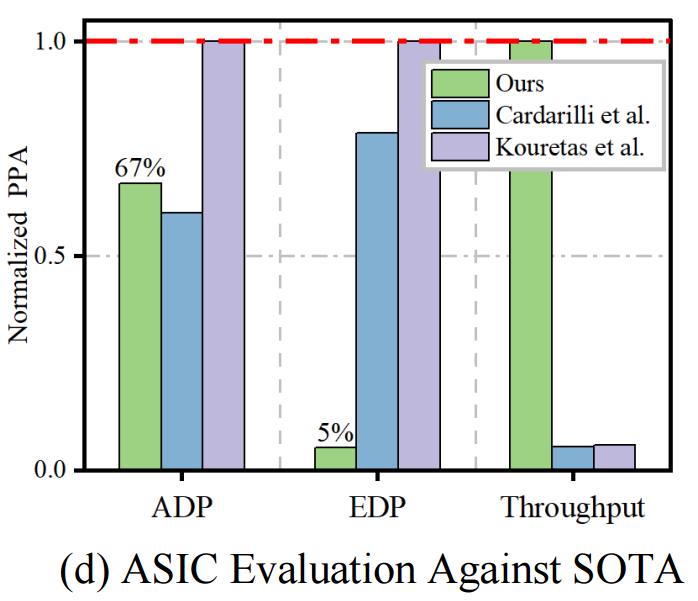
通過對輸入大小從8到4096元素的調優測試,驗證了設計的可擴展性。隨著輸入數據點數量的增加,總計算時間呈指數增長,這是由于輸入長度與處理矩陣大小的二次關系。在輸入大小增加的過程中,各個流水線階段的時間消耗比例增長平衡,沒有出現某個部分延遲增長過快的情況,證明了設計在處理大規模數據時的并行性和可擴展性,能夠適應不同規模的應用需求。
總結
本文提出了 DBFP,一種先進的 BFP 變體,通過自適應分組和樞軸聚焦策略,有效解決了非線性運算中準確性和效率的挑戰。在此基礎上,構建了 DB-Attn 框架,通過算法和硬件的協同設計,實現了高效的 Attention 計算。實驗結果表明,DB-Attn 在 GPU 上實現了 74% 的加速,且精度損失可忽略不計,基于 RTL 級的 DBFP 引擎比現有最先進的設計性能提升了 10 倍。
本文的研究成果為 BFP 在窄精度 LLM 推理中的應用開辟了新的道路,證明了軟硬件協同設計在優化非線性運算方面的巨大潛力。未來的研究可以進一步探索 DB-Attn 在其他復雜神經網絡結構和任務中的應用,以及如何進一步優化硬件架構,以降低成本和提高能效,推動 LLMs 在更廣泛領域的高效應用。
-
算法
+關注
關注
23文章
4690瀏覽量
94501 -
模型
+關注
關注
1文章
3474瀏覽量
49893 -
LLM
+關注
關注
1文章
318瀏覽量
659
原文標題:后摩前沿 | 低精度LLM推理加速:基于 DBFP 與 DB-Attn 的算法硬件協同優化方案
文章出處:【微信號:后摩智能,微信公眾號:后摩智能】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
FPGA芯片用于神經網絡算法優化的設計實現方案
汽車領域多學科優化設計解決方案--Optimus
如何優化控制算法的代碼
軟硬件協同優化,平頭哥玄鐵斬獲MLPerf四項第一
Camellia加密算法基于硬件實現的優化
基于AES算法硬件優化及IP核應用
基于聚類協同過濾推薦算法優化

求解大規模問題的協同進化動態粒子群優化算法
優化的協同過濾推薦算法
基于多策略協同作用的粒子群優化MSPSO算法
基于SVDPP算法的新型協同過濾推薦算法






 工商網監
工商網監
評論