 硬件算法協同設計
硬件算法協同設計
本文翻譯整理自 A Survey on Efficient Training of Transformers
來自:無數據不只能
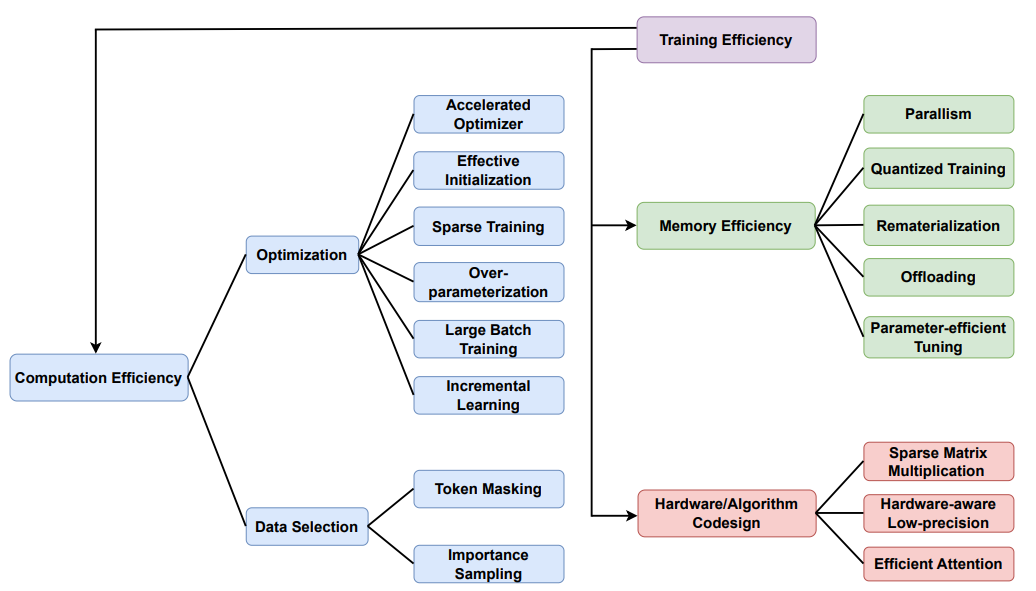
在本文中,將探討了transformer高效訓練方法,從存儲效率、硬件算法協同設計和計算效率三個角度進行了闡述。
在計算效率方面,介紹加速優化器、初始化、稀疏訓練、過參數化、大批次訓練和增量訓練等優化策略,以及token掩碼和重要性抽樣等數據選擇方法。
在內存效率方面,介紹并行化、量化訓練、再物化、卸載和參數效率微調等策略。
在硬件算法協同設計方面,介紹稀疏矩陣乘法、低精度硬件感知和高效注意力等方法。
計算效率
優化
加速優化器
AdamW是Adam的一個變體,其解耦了正則化2和權重衰減,是transformer中最常用的優化器之一。
Lion只使用一階梯度跟蹤動量,更新只考慮符號方向,對每個參數具有相同的量級,與AdamW等自適應優化器有很大不同。在實踐中,Lion一般收斂更快,在各種基準上訓練transformer時,Lion的內存效率和準確性都比AdamW更高。
初始化
好的初始化對于穩定訓練、加速收斂、提高學習率和泛化能力很重要。
Fixup重新縮放標準初始化以確保梯度范數適當,避免梯度爆炸或消失,從而可在不添加歸一化層的情況下使用非常深的網絡進行訓練。
ReZero和SkipInit只是將每個層初始化為執行恒等操作,其基礎是歸一化殘差塊計算出的函數接近于恒等函數。它們在每個殘差塊的輸出上添加一個可學習的縮放乘法器。T-Fixup分析表明,Adam優化器中二階動量的方差無界,導致部分優化難度。因此,T-Fixup采用一種類似于Fixup對殘差塊的初始化的縮放方案。以上所有方法都從所有塊中刪除批/層歸一化,并在沒有學習率warm up的情況下進行訓練。
在訓練深度視覺transformer(ViT)時,提出了通道級可學習的縮放因子,并根據經驗觀察到重新引入預熱和層歸一化技術可以使訓練更加穩定。
稀疏訓練
稀疏訓練的關鍵思想是在不犧牲精度的情況下,直接訓練稀疏子網絡而不是全網絡。可靠性首先由彩票假說(LTH)證明,一個密集的、隨機初始化的網絡包含子網絡,這些子網絡可以單獨訓練,以匹配原始網絡的精度。然而,LTH需要以交替訓練-剪枝-再訓練的方式識別中獎彩票,這使得大型模型和數據集的訓練成本極其昂貴,限制了實際效益。鑒于此,具有更高訓練效率的后續工作可以大致分為三類:
(i) 通過測量連接對損失的重要性,在初始化時一次性找到稀疏網絡,消除了對復雜迭代優化調節的需要;(ii) 通過低成本方案在非常早期的訓練階段識別transformer中的中獎彩票,然后僅僅訓練這些早期彩票,直到收斂;(iii) 在整個訓練過程中使用交替修剪和增長計劃來動態更新模型稀疏模式,適用于通用架構。
過參數化
實用的DNN是過于參數化的,其可學習的參數數量遠遠大于訓練樣本的數量。過參數化可以在一定程度上提高收斂性和泛化性,雖然不充分,但有理論支持。早期的研究證明在線性神經網絡中通過過參數化增加深度可以加速SGD的收斂。進一步探索了兩層非線性神經網絡,證明了SGD可以在多項式時間內收斂到DNNs的訓練目標上的全局最小值,假設訓練樣本不重復,并且參數數量是多項式級別的。在泛化方面,理論證明了充分過參數化的神經網絡可以泛化到種群風險,一個有趣的特性是,在SGD訓練軌跡上任意點的近鄰域內存在一個精確的網絡,具有高概率的隨機初始化。需要注意的是,與LTH有很深的關聯,因為它部分解釋了為什么LTH在稀疏訓練中表現良好,因為過度參數化會產生許多低風險的好子網絡。在transformer中應用這一理論,可以獲得更快的收斂速度和更好的性能。
大批次訓練
另一種加速訓練的流行方法是使用大批量,減少每個epoch的迭代次數,提高計算資源利用率。從統計學的角度來看,大批量訓練降低了隨機梯度估計的方差,因此需要調整可靠的步長以獲得更好的收斂。在卷積神經網絡時代,利用學習率的線性縮放,在ImageNet上以8192的批次大小在1小時內訓練ResNet-50。隨后提出了更先進的步長估計方法。廣泛使用的方法是SGD的LARS和Adam的LAMB,它們建議分別對ResNet和Transformers使用分層自適應學習率。
它配備了一個歸一化項,對梯度爆炸和平臺提供魯棒性,縮放項確保更新的參數與參數的范數相同階次,促進更快的收斂。最近,根據經驗,針對大批量訓練定制的更強大的優化方法表現良好。例如,表明,將一定數量的最新檢查點的權重進行平均,可以促進更快的訓練。DeepMind在中訓練了400多個具有不同規模的模型大小和訓練token的Transformer語言模型,達到了一個實用的假設,即模型大小和訓練token的數量應該被均勻縮放以進行計算最優的LLM訓練。
增量訓練
增量學習的高級概念是將原來具有挑戰性的優化問題放松為一系列易于優化的子問題,其中一個子問題的解可以作為后續子問題的良好初始化,以規避訓練難度,類似于退火。一些工作提出通過逐步堆疊層來加速BERT預訓練,從一個較小的模型適當地初始化一個較大的模型。以相反的方向通過層丟棄來訓練具有隨機深度的transformer,其中它沿著時間維度和深度維度逐步增加丟棄率。為ViT定制,AutoProg建議在使用神經架構搜索的漸進式學習過程中自動決定模型是否增長、在哪里增長以及應該增長多少。一個關鍵的觀察結果是,逐步增加輸入圖像的分辨率(減少patch大小)可以顯著加快ViT訓練,這與眾所周知的訓練動態一致,即在早期集中于低頻結構,在后期集中于高頻語義。
數據選擇
除了模型效率,數據效率也是高效訓練的關鍵因素。
token掩碼
Toke n m asking 是自監督預訓練任務中的一種主要方法,例如掩碼語言建模和掩碼圖像建模。標記掩碼的精神是隨機掩碼一些輸入標記,并訓練模型用可見標記中的上下文信息來預測缺失的內容,例如詞匯表ID或像素。由于壓縮序列長度以二次方式降低了計算和存儲復雜度,跳過處理掩碼token為MLM和MIM帶來了可觀的訓練效率增益。對于MLM,提出聯合預訓練語言生成任務的編碼器和解碼器,同時刪除解碼器中的掩碼標記,以節省內存和計算成本。對于MIM,代表性工作表明,在視覺中,在編碼器之前移除掩碼圖像塊顯示出更強的性能,并且比保留掩碼token的整體預訓練時間和內存消耗低3倍或更多。在中也發現了類似的現象,對于語言-圖像預訓練,隨機掩碼并去除掩碼圖像塊顯示了比原始剪輯快3.7倍的整體預訓練時間。
重要性抽樣
在數據上采樣的重要性,也稱為數據剪枝,理論上可以通過優先考慮信息量大的訓練樣本來加速監督學習的隨機梯度算法,主要受益于方差縮減。對于DNNs來說,估計每個樣本重要性的一種主要方法是使用梯度范數,并且使用不同的近似使計算這些規范變得容易進一步加快類似于early-bird LTH的采樣過程,但在數據域,在幾個權重初始化上的簡單平均梯度范數或誤差2范數可以用于在訓練的非常早期階段識別重要的示例。最近,展示了一個令人興奮的分析理論,即測試誤差與數據集大小的縮放可以突破冪次縮放定律,如果配備了優越的數據修剪度量,則可以減少到至少指數縮放,并且它采用了使用k-means聚類的自監督度量。它展示了一個有希望的方向,即基于數據重要性采樣的更有效的神經縮放定律。
內存效率
除了計算負擔之外,大型Transformer模型不斷增長的模型大小,例如從BERT 345M參數模型到1.75萬億參數的GPT-3,是訓練的一個關鍵瓶頸,因為它們不適合單個設備的內存。我們首先分析了現有模型訓練框架的內存消耗,這些內存消耗由模型狀態,包括優化器狀態、梯度和參數;以及激活。我們在表1中總結了內存有效的訓練方法。在下文中,我們將討論優化內存使用的主要解決方案。
并行化
跨設備并行訓練大型DNN是滿足內存需求的常見做法。基本上有兩種范式:數據并行(DP),它在不同的設備上分配一個小批量的數據,模型并行(MP),它在多個worker上分配一個模型的子圖。對于DP來說,隨著可用worker的增加,批處理大小接近線性縮放。第2節中討論的大批量培訓就是針對這種情況開發的。然而,很明顯,DP具有較高的通信/計算效率,但內存效率較差。當模型變得很大時,單個設備無法存儲模型副本,并且針對梯度的同步通信會阻礙DP的可擴展性。因此,DP本身只適合訓練小到中等規模的模型。為了提高DP的可擴展性,Transformer的一種解決方案是參數共享 ,即Albert,但它限制了表征能力。最近,ZeRO將均勻劃分策略與DP結合在一起,其中每個數據并行過程僅處理模型狀態的一個劃分,在混合精度制度下工作。為了處理非常大的DNN,人們總是需要利用模型并行性,以“垂直”的方式在多個加速器上分配不同的層。雖然MP具有良好的存儲效率,但由于跨設備的大量數據傳輸和較差的PE利用率,其通信和計算效率較低。幸運的是,在an中有兩種策略可以進一步提高MP的效率
正交的“水平”維度,包括張量并行(TP)和流水線并行(PP)。TP跨worker將張量操作劃分在一個層中,以實現更快的計算和更多的內存節省。根據基于transformer的模型定制,Megatron-LM跨GPU對MSA和FFN進行切片,并且在前向和后向傳遞中只需要一些額外的All-Reduce操作,使他們能夠使用512個GPU訓練模型多達83億個參數。在PP方面,它最初是在GPipe中提出的,它將輸入的mini-batch分割為多個較小的micro-batch,使不同的加速器(在加速器上劃分順序層)同時在不同的micro-batch上工作,然后對整個mini-batch應用單一的同步梯度更新。然而,它仍然受到管道氣泡(加速器空閑時間)的影響,這會降低效率。特別是,PyTorch實現了torchgpipe,它使用檢查點執行微批次PP,允許擴展到大量的微批次,以最小化氣泡開銷。請注意,DP和MP是正交的,因此可以同時使用兩者來訓練具有更高計算和內存容量的更大模型。例如,Megatron-LM和DeepSpeed組成了張量、管道和數據并行,以將訓練擴展到數千個GPU。
量化訓練
訓練神經網絡的標準程序采用全精度(即FP32)。相比之下,量化訓練通過將激活值/權重/梯度壓縮為低比特值(例如FP16或INT8),以降低的精度從頭開始訓練神經網絡。在之前的工作中已經表明,降低精度的訓練可以加速神經網絡的訓練,并具有良好的性能。對于Transformer來說,采用最廣泛的方法是自動混合精度(AMP)訓練。具體來說,AMP以全精度存儲權重的主副本用于更新,而激活值、梯度和權重則存儲在FP16中用于算術。與全精度訓練相比,AMP能夠實現更快的訓練/推理速度,并減少網絡訓練期間的內存消耗。例如,基于64的批量大小和224×224的圖像分辨率,在AMP下的RTX3090上訓練DeiT-B比全精度訓練快2倍(305張圖像vs124張圖像/s),同時消耗22%的峰值GPU內存(7.9GBvs10.2GB)。雖然人們普遍認為,至少需要16位才能訓練網絡而不影響模型精度,但最近在NVIDIA H100上對FP8訓練的支持在Transformer訓練上顯示出了可喜的結果,在FP8下訓練DeiT-S和GPT可以與16位訓練相媲美。除了同時量化激活/權重/梯度的精度降低訓練外,激活壓縮訓練(ACT)在精確計算前向傳遞的同時存儲低精度的激活近似副本,這有助于減少訓練期間的整體內存消耗。然后將保存的激活解量化為向后傳遞中的原始精度,以計算梯度。最近的工作進一步建議自定義ACT以支持內存高效的Transformer訓練。
再物化和卸載
再物化 (R e materialization),也被稱為檢查點,是一種廣泛使用的時空權衡技術。在正向傳遞時只存儲一部分激活/權重,在反向傳遞時重新計算其余部分。提供了一個在PyTorch3中實現的簡單的周期性調度,但它僅適用于同構的順序網絡。更先進的方法,如實現了異構網絡4的最優檢查點。在卸載方面,它是一種利用CPU內存等外部內存作為GPU內存的擴展,通過GPU和CPU之間的通信,在訓練過程中增加內存容量的技術。模型狀態和激活,都可以卸載到CPU,但最優選擇需要最小化通信成本(即數據移動)到GPU,減少CPU計算和最大化GPU內存節省。一個代表性的工作是ZERO-Offload,它提供了使用Adam優化器定制的混合精度訓練的最優卸載策略。它在CPU內存上卸載所有fp32模型狀態和fp16梯度,并在CPU上計算fp32參數更新。fp16參數保存在GPU上,前向和后向計算在GPU上。為了兩全兼顧,建議聯合優化激活卸載和再物化。
參數效率微調
以 HuggingFace 為代表的公共模型動物園包含豐富的預訓練模型,可以隨時下載和執行,正在為降低訓練成本做出顯著貢獻。對這些現成的模型進行有效調優,正成為一種大幅削減訓練成本的流行方式。作為香草全微調的強大替代方案,
參數高效調優(PET)在凍結預訓練模型的同時只更新少量額外參數,以顯著減少存儲負擔。它可以隨動態部署場景擴展,而不需要為每種情況存儲單獨的模型實例。一般的PET方法可以分為基于添加的方法和基于重新參數化的方法。前者將額外的可訓練參數附加到預訓練模型上,并且只調整這些參數。例如,在輸入空間中添加可訓練參數,在MSA和FFN之后在每個Transformer塊中添加兩次適配器模塊。然而,額外的參數會在推理過程中引入額外的計算和內存開銷。為了應對這一挑戰,后者建議調整模型中固有的參數或可以重新參數化到模中的新參數,從而不會對推理效率產生犧牲。受觀察到大型語言預訓練模型具有較低的內在維度的啟發,代表性工作LoRA將自注意力權重的更新近似為兩個低秩矩陣,可以在推理過程中將其合并到預訓練權重中。值得注意的是,在實現LLM民主化方面最受認可的工作之一是Stanford Alpaca,它使用從Chat GPT生成的52K指令遵循數據從開源的LLaMA模型中進行微調。為了廉價有效地對其進行微調,其變體Alpaca-LoRA5進一步采用低秩LoRA來實現在客戶硬件上對羊駝進行指令微調,表明可以在單個RTX 4090上在數小時內完成訓練。
開源框架
有幾個被廣泛采用的原型用于大規模訓練大型Transformer模型,其中微軟DeepSpeed、HPC-AI Tech ColossalAI和Nvidia Megatron是先驅。具體來說,DeepSpeed主要基于和ZERO系列作品實現,Colossal-AI基于構建,Megatron-LM實現。所有這些都支持混合精度的數據和模型并行,以及其他通用實踐,如卸載和再物化。更多用于高效分布式訓練的庫包括但不限于HuggingFace Transformers,MosaicML Composer,百度PaddlePaddle,Bytedance Lightspeed,EleutherAI GPT-NeoX等。
硬件算法協同設計
除了計算和內存負擔,設計高效的硬件加速器可以使DNNs更快地訓練和推理。具體來說,與中央處理單元(CPU)相比,圖形處理單元(GPU)由于高度并行性,在執行矩陣乘法時更加強大。對于專注于特定計算任務的應用,專用集成電路(ASIC)具有低功耗、高訓練/推理速度的優勢。例如,谷歌設計的張量處理單元(TPU)比當代CPU和GPU提供了30~80倍的性能/瓦特。然而,ASIC不容易重新編程或適應新任務。相比之下,現場可編程門陣列(FPGA)被設計成可以根據需要重新編程以執行不同的功能,在最終確定設計之前也可以作為ASIC的原型。為了進一步優化DNNs特別是Transformer的訓練效率,硬件-算法協同設計在設計算法時考慮了硬件的約束和能力,這將在以下小節中介紹。
稀疏矩陣乘法
為了降低 Transformer 的計算開銷,涉及將稀疏矩陣與稠密矩陣相乘的稀疏通用矩陣乘法(SpGEMM),利用注意力矩陣的稀疏性來減少計算次數。目前有幾個流行的稀疏矩陣計算庫,如Intel Math Kernel library CPU和cuSPARSE15、CUSP16和24 GPU上的結構化稀疏性。然而,由于不規則的稀疏性,SpGEMM往往對CPU、GPU等通用處理器的硬件不友好。為了解決這個問題,需要專門的硬件加速器,如FPGA和ASIC,來處理糟糕的數據局部性問題。例如,OuterSPACE 將矩陣乘法轉換為外積過程,并通過將乘法與累加解耦來消除冗余內存訪問。為了在不引入顯著開銷的情況下充分利用這一減少,OuterSPACE構建了一個具有可重構存儲層次的自定義加速器,相對于運行英特爾數學內核庫的CPU實現了7.9倍的平均加速,相對于運行CUSP的GPU實現了14.0倍的平均加速。此外,為了緩解高稀疏性造成的數據移動瓶頸,ViTCoD使用可學習的自編碼器將稀疏注意力壓縮為更緊湊的表示,并設計編碼器和解碼器引擎以提高硬件利用率。
低精度硬件感知
降低計算精度會減少內存和計算量,這可以用硬件友好的定點或整數表示來實現,而不是浮點表示。因此,我們可以使用精度較低的乘法器、加法器和內存塊,從而在功耗和加速比方面得到顯著改善。此外,低精度的算法可以與其他技術相結合,如剪枝和低秩近似,以實現進一步的加速。例如,Sanger使用4位查詢和鍵來計算稀疏注意力矩陣的量化預測。然后,稀疏注意力掩碼被重新排列成結構化的塊,并由可重構硬件處理。以下工作DOTA使用低秩變換和低精度計算識別注意力中的不重要連接。通過結合token級并行和亂序執行,DOTA實現了GPU上152.6倍的加速。
高效注意力
除了稀疏的矩陣乘法和低精度的計算,幾項開創性的工作都專注于在硬件上實現高效和輕量級的注意力。具體來說,一個3只選擇那些可能與給定查詢具有高相似性的鍵,以減少注意力的計算量。ELSA根據哈希相似度過濾掉與特定查詢無關的鍵,以節省計算量。借助高效的硬件加速器,ELSA實現了58.1倍的加速,與配備16GB內存的Nvidia V100 GPU相比,在能效方面有三個數量級的提升。值得注意的是,Flash Attention提出利用tiling來減少GPU高帶寬內存(HBM)和片上SRAM之間的I/O通信,這正在成為一個默認的快速和內存高效的注意力模塊來加速。
審核編輯:湯梓紅
-
cpu
+關注
關注
68文章
11031瀏覽量
215955 -
算法
+關注
關注
23文章
4697瀏覽量
94715 -
內存
+關注
關注
8文章
3108瀏覽量
74981 -
硬件
+關注
關注
11文章
3459瀏覽量
67181 -
協同設計
+關注
關注
0文章
14瀏覽量
7982
原文標題:硬件算法協同設計
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
SOC設計領域的核心技術-軟/硬件協同設計
基于SoPC的狀態監測裝置的嵌入式軟硬件協同設計
基于Altera FPGA的軟硬件協同仿真方法介紹
智能控制的系統辨識協同算法
面向HDTV應用的音頻解碼軟硬件協同設計
一種改進的協同優化算法
基于巴氏系數的協同過濾算法
基于加權的Slope One協同過濾算法
基于標簽主題的協同過濾推薦算法研究
一種協同過濾推薦算法
基于顯式反饋的改進協同過濾算法研究

基于函數逼近協同更新的DQN算法
基于DBFP與DB-Attn的算法硬件協同優化方案





 工商網監
工商網監
評論