 極速部署!GpuGeek提供AI開發者的云端GPU最優解
極速部署!GpuGeek提供AI開發者的云端GPU最優解
在AI開發領域,算力部署的效率和資源調度的靈活性直接影響研發進程與創新速度。隨著模型復雜度的提升和全球化協作需求的增長,開發者對GPU云服務的核心訴求已從單純追求硬件性能,轉向對部署效率、跨區域協作支持及全流程開發體驗的綜合考量。GpuGeek作為專注于AI基礎設施的平臺,憑借其“極速部署”能力與深度優化的服務體系,正成為開發者的云端首選。
一、秒級啟動:從注冊到運行,30秒開啟使用
傳統GPU云服務常因繁瑣的環境配置、復雜的計費模式拖慢開發節奏,而GpuGeek通過多項創新技術實現“零等待”體驗,讓用戶跳過環境部署“深水區”,直擊核心開發任務,實現效率提升。
極簡流程:注冊賬號、選擇預置鏡像(支持TensorFlow/PyTorch等主流框架)、創建GPU實例三步操作,最快30秒即可進入使用界面。
動態算力伸縮:GpuGeek支持8卡并行計算(平臺從消費級的RTX 4090到專業級的A5000/A800,再到最新的H100集群,全系列GPU資源應有盡有),用戶可根據任務需求一鍵調整算力規模,無需重復配置環境。
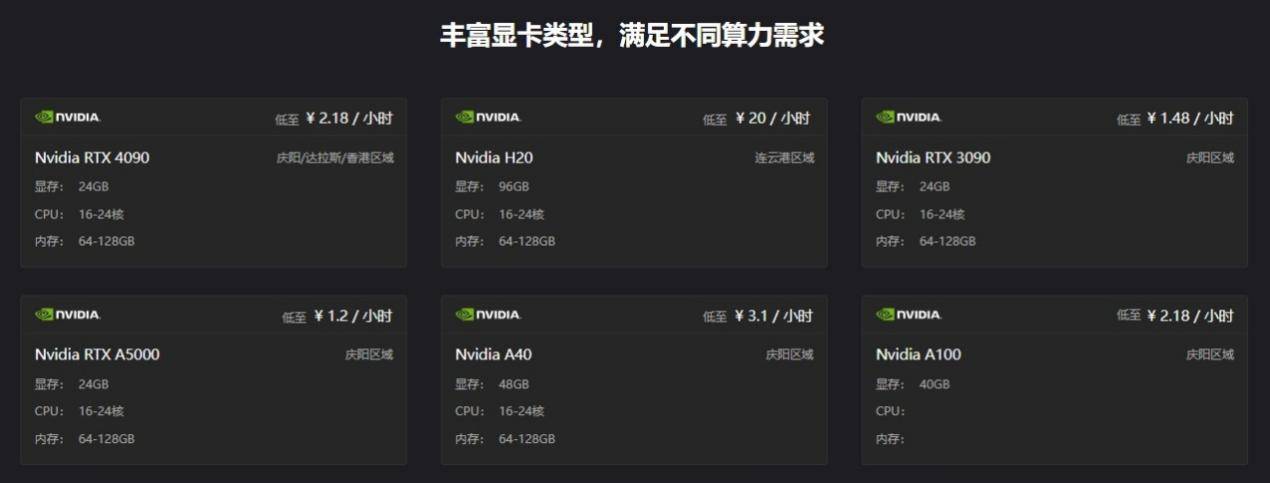
按需計費:GpuGeek秒級計費模式精準匹配開發周期,避免資源閑置浪費,尤其適合間歇性訓練或臨時性算力需求場景。
二、全球節點覆蓋:破解跨國部署三大痛點
全球化AI協作面臨鏡像加載慢、推理延遲高、數據合規難等挑戰。GpuGeek通過“全球鏡像庫+智能節點調度”提供一站式解決方案,無論是歐洲團隊訓練模型,還是亞太團隊通過本地節點實時調用API,其數據同步延遲都能壓縮至毫秒級。
跨國加速:GpuGeek在香港、達拉斯等海外節點實現模型鏡像秒級下載,推理延遲低至0.5秒,滿足歐洲、亞太等地區的實時響應需求。
數據合規保障:一鍵完成數據存儲與傳輸的本地化合規操作,規避跨境法律風險。
三、鏡像生態與存儲優化:加速模型全生命周期
從模型微調到大規模訓練,GpuGeek通過軟硬協同設計縮短數據讀寫與部署周期,引入kata虛擬化技術強化容器隔離性,兼顧安全與性能,保障多租戶場景穩定性。
預置鏡像池:GpuGeek提供100+預加載模型鏡像(如OpenManus、阿里千問QwQ-32B等),覆蓋CV、NLP、多模態領域,支持一鍵調用。
NVMe本地緩存:模型文件直接預載至本地硬盤,讀取速度較傳統云盤提升3-5倍,大幅減少等待時間。
開放生態共建:開發者可發布自定義鏡像賺取積分,或通過GpuGeek社區互助快速獲取稀缺框架配置,形成“開發-共享-復用”的正向循環。
四、開發者友好:從資源到社區的全鏈路激勵
GpuGeek主張讓開發者專注創新,通過活動與社區構建降低使用門檻:
成本優化:GpuGeek3月限時活動中,A5000 24G GPU低至0.98元/時,中小團隊亦可負擔專業級算力。
激勵體系:用戶參與“云大使”推廣、鏡像創作、技術內容征集等活動,可兌換現金、代金券或免費算力,實現“以技養研”。
開放社區:開發者可交流調優技巧、共享數據集,GpuGeek鼓勵用戶在社區中積極交流創作靈感、分享實踐經驗,共同推動技術生態的繁榮發展。
快,是AI時代的核心競爭力。在AI技術迭代速率以月為單位的今天,GpuGeek通過極速部署能力、全球化資源布局、開放鏡像生態及開發者優先理念,重新定義了GPU云服務的效率標準。無論是個人開發者的快速實驗,還是企業級模型的跨國協同,其“30秒啟動、全球無感切換、數據-訓練-部署全鏈路加速”的特性,均能為用戶贏得寶貴的創新時間窗口。選擇GpuGeek,本質是選擇一種更敏捷、更自由的AI開發方式——在這里,算力不再是瓶頸,創造力才是唯一邊界。
審核編輯 黃宇
-
gpu
+關注
關注
28文章
4909瀏覽量
130646 -
AI
+關注
關注
87文章
34155瀏覽量
275326
發布評論請先 登錄
《AI Agent 應用與項目實戰》閱讀心得3——RAG架構與部署本地知識庫
添越智創基于 RK3588 開發板部署測試 DeepSeek 模型全攻略
NVIDIA Jetson Orin Nano開發者套件的新功能

云端AI開發者工具怎么用
Arm推出GitHub平臺AI工具,簡化開發者AI應用開發部署流程
摩爾線程成立摩爾學院,賦能GPU開發者
NVIDIA RTX AI套件簡化AI驅動的應用開發
NVIDIA將全球數百萬開發者轉變為生成式 AI 開發者
NVIDIA NIM 革命性地改變模型部署,將全球數百萬開發者轉變為生成式 AI 開發者






 工商網監
工商網監
評論