 首個Mamba系列模型量化方案MambaQuant解讀
首個Mamba系列模型量化方案MambaQuant解讀
MambaQuant在Mamba系列模型上實現了W8A8/W4A8量化的方法,精度逼近浮點,超過Quarot等SOTA方法。該工作已被人工智能頂會ICLR-2025接收。
Abstract
Mamba是一種高效的序列模型,可與Transformer相媲美,在各類任務中展現出作為基礎架構的巨大潛力。量化技術常用于神經網絡,以減小模型大小并降低計算延遲。然而,將量化應用于Mamba的研究尚少,現有的量化方法雖然在CNN和Transformer模型中效果顯著,但對Mamba模型卻不太適用(例如,即使在W8A8配置下,QuaRot在Vim-T模型上的準確率仍下降了21%)。我們率先對這一問題展開探索,并識別出幾個關鍵挑戰。
首先,在門投影、輸出投影和矩陣乘法中存在大量異常值。其次,Mamba獨特的并行掃描操作進一步放大了這些異常值,導致數據分布不均衡且呈現長尾現象。第三,即使應用了Hadamard變換,權重和激活值在通道間的方差仍然不一致。為此,我們提出了MambaQuant,這是一種訓練后量化(PTQ)框架,包含:1)基于Karhunen-Loève變換(KLT)的增強旋轉,使旋轉矩陣能適應不同的通道分布;2)平滑融合旋轉,用于均衡通道方差,并可將額外參數合并到模型權重中。
實驗表明,MambaQuant能夠將權重和激活值量化為8位,且基于Mamba的視覺和語言任務的準確率損失均小于1%。據我們所知,MambaQuant是首個針對Mamba系列模型的綜合性PTQ設計,為其進一步的應用發展奠定了基礎。
?論文鏈接:https://arxiv.org/abs/2501.13484
?單位:后摩智能、哈爾濱工業大學(深圳)、南京大學、東南大學
Introduction
為了建立一套針對Mamba模型的綜合量化方法,我們首先研究其中涉及的潛在限制和挑戰:
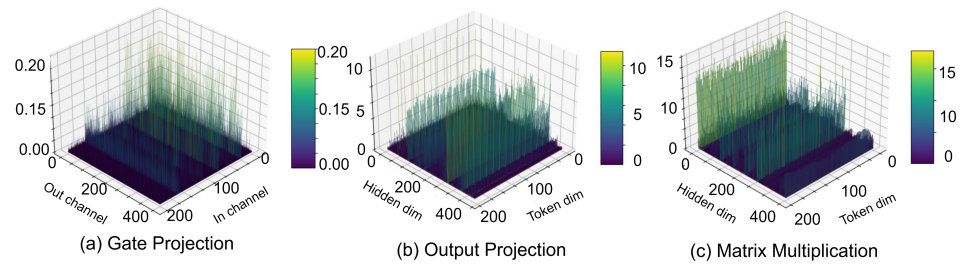
Mamba模型的權重和激活值中都存在顯著的異常值。我們觀察到,線性層的權重中存在異常值,尤其是在用于語言任務的 Mamba-LLM 的門投影層(圖1a)中。我們還發現,線性層的某些輸入在通道維度上表現出顯著的方差。這種情況在用于視覺任務的 Vim 的輸出投影層(圖1b)中尤為明顯。
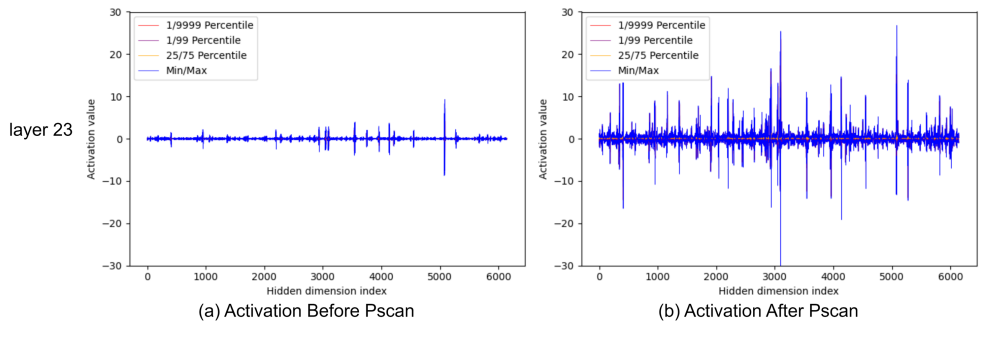
并行掃描(PScan)進一步放大了激活值的異常值。為了在每個時間戳獲得隱藏狀態,PScan算子(Smith等人,2022)會對一個固定的參數矩陣不斷進行自乘運算。在這種情況下,值較高的通道會被放大,而值相對較低的通道則會被削弱。這種通道間明顯的數值差異會直接擴展到激活值上(例如,如圖1(c)所示的矩陣乘法的輸入變量,以及圖2所示)。
最近,基于 Hadamard 的方法因其能夠使最大值均勻化以及具有等價變換特性,在 Transformer-based LLMs (T-LLMs) 的量化中取得了顯著成功。例如,使用 QuaRot 將 LLAMA2-70B 量化為 4 位時,能保持 99% 的零樣本性能。然而,將這種方法直接應用于 Mamba 模型會導致準確率大幅下降(例如,即使在 8 位量化的情況下,在 Vim上平均準確率仍然下降超過 12%)。
為了解決上述問題,我們發表了MambaQuant這篇文章,(據我們所知)這是首個在Mamba系列模型上實現了高準確率W8A8/W4A8量化的工作,主要貢獻包括:
a. 在離線模式下,我們提出基于 Karhunen - Loève 變換(KLT)的增強旋轉。此技術將 Hadamard 矩陣與 KLT 矩陣相乘,使旋轉矩陣能夠適應不同的通道分布。
b. 在在線模式下,我們引入平滑融合旋轉。這種方法在 Hadamard 變換之前進行平滑處理。額外的平滑參數被靈活地整合到 Mamba 模塊的權重中,以避免額外的內存空間和推理步驟成本。
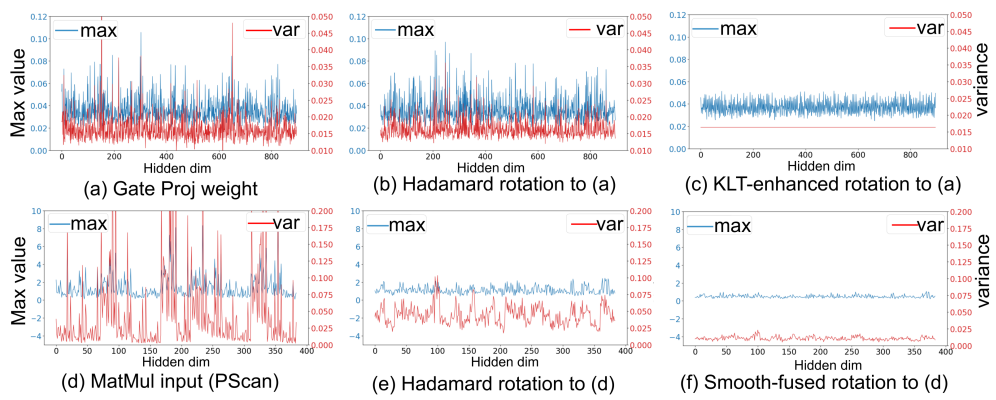
因此,量化數據的最大值和方差在通道維度上都得到了充分對齊,方法效果如圖3所示:
實驗表明,MambaQuant 能夠高效地將權重和激活值量化為8位,且在基于Mamba的視覺和語言任務上,準確率損失均小于1%。
Method
對Hadamard旋轉效果不佳的分析
我們發現,該方法無法對齊量化變量的通道方差,從而忽略了不同通道之間的分布一致性。詳細來說,給定一個中心化的數據矩陣(矩陣的列均值為零)X(權重或激活值),其維度為(n, m),以及維度為(m, m)的Hadamard變換矩陣H,變換后的矩陣XH的協方差矩陣可以表示為:
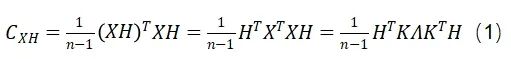
協方差矩陣的第l個對角元素可以表示為:
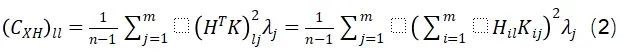
對于給定的l值,公式(2)表示第l個通道的方差。由于向量隨l變化,在大多數情況下無法證明通道方差在數值上接近。此外,考慮到H是一個固定矩陣,而K和λ都取決于輸入,在所有情況下,Hadamard變換都不可能統一調整通道方差。Hadamard變換的這一特性不可避免地為每個通道形成了不同的分布,從而導致次優的量化效果。
KLT增強旋轉
為了克服上述限制,我們引入了KLT來均衡通道方差。KLT識別數據中的主成分,并將數據投影到這些成分上,通過關注方差最大的方向來保留每個通道的最關鍵信息。在實際應用中,Mamba權重和激活值的均值通常接近于零,滿足KLT的適用條件。具體而言,我們對由校準數據得到的中心化矩陣X的協方差矩陣進行特征值分解來應用KLT:
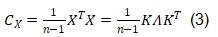
接下來,如公式(4)所示,通過將KLT應用于Hadamard矩陣H,可以得到KLT增強旋轉矩陣:
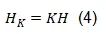
在公式(4)基礎上,公式(1)可因此轉化為公式(5):
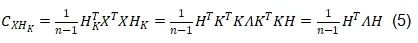
而公式(2)可變為公式(6):
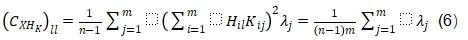
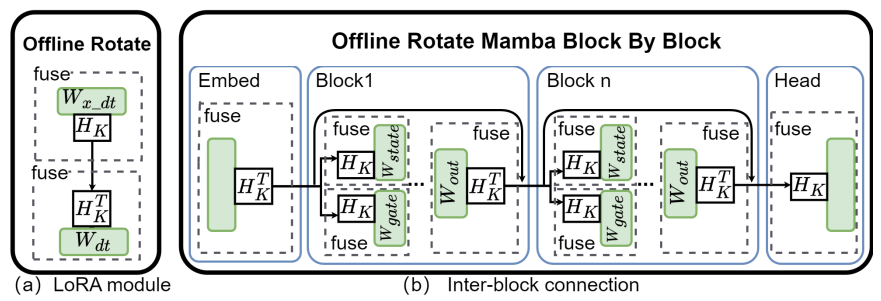
這樣,每個通道的方差變得相同,使得量化變得容易得多。這種變換具有雙重目的:它不僅均衡了不同通道之間的方差,還體現了KLT矩陣與Hadamard矩陣的獨特屬性,后者能夠平衡最大值。在實踐中,KLT是離線執行的,以避免額外的計算成本。為了將這種KLT增強的旋轉矩陣應用于Mamba結構,我們修改了QuaRot中的離線變換。如圖5所示,我們將此策略應用于LoRA模塊和層間連接(其中輸出投影、門投影和狀態投影被變換)。
Smooth對齊旋轉
為了在在線旋轉中實現通道方差對齊,我們在執行在線Hadamard旋轉之前引入了平滑(smooth)技術。采用這種方法的動機是通過一個平滑向量來使通道方差均勻化。通常,平滑因子可以被吸收到量化層的相鄰層中例如SmoothQuant, OmniQuant。這種操作有效地避免了因引入額外參數而產生的額外內存分配和計算開銷需求。然而,這種方法在Mamba模塊中并不完全適用,這是由于非逐元素的SiLU操作以及PScan的復雜循環結構。為此,我們分別針對輸出投影和矩陣乘法提出了兩種不同的設計。
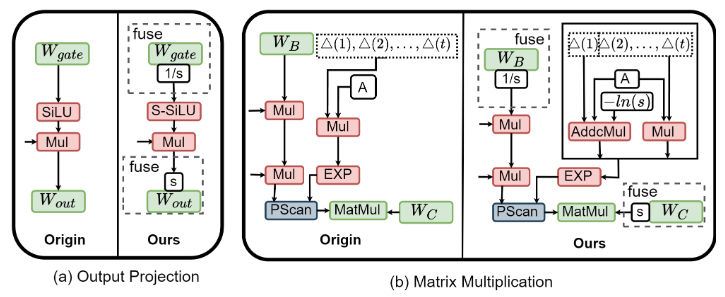
對于輸出投影層:我們提出S - SiLU,改進了傳統的SiLU激活函數,以滿足平滑融合量化的需求:
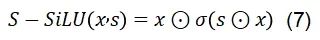
如圖6(a)所示,S - SiLU函數在門投影上的應用可以表示為如下公式:
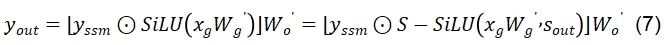
對于矩陣乘法層:如圖6(b)所示,平滑參數s可以被自然的吸收到權重B和權重C中,然而A矩陣會在推理時執行多次的自乘運算,因此我們引入了計算友好的addcmul算子,僅對第一個時間步的A矩陣的運算做s參數的吸收融合,如公式(8)所示:
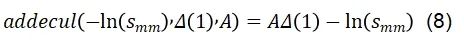
經過平滑處理后,輸出投影和矩陣乘法的激活值的通道方差變得相對均勻。隨后,我們針對Mamba結構修改并應用了在線Hadamard旋轉,如圖7所示。Hadamard矩陣H被動態地應用于輸出投影和矩陣乘法的輸入激活值,而轉置后的H^T可以被吸收到相應的權重中。
Experiments
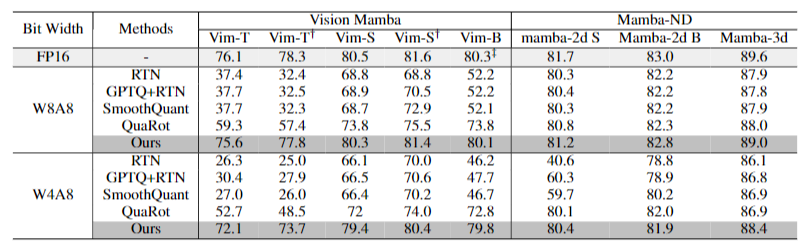
實驗結果表明,MambaQuant 在 Mamba 系列模型上都取得了驚人的效果,表現超過Quarot,并遠超其他的量化方案。例如其W8A8的精度在多種視覺語言的評估任務上都表現出小于1%的精度損失,其W4A8的量化也是實現了SOTA的效果。
值得一提的是,我們的通道方差對齊方法對精度有很明顯的提升,該提升的可視化效果也十分顯著,比如KLT:
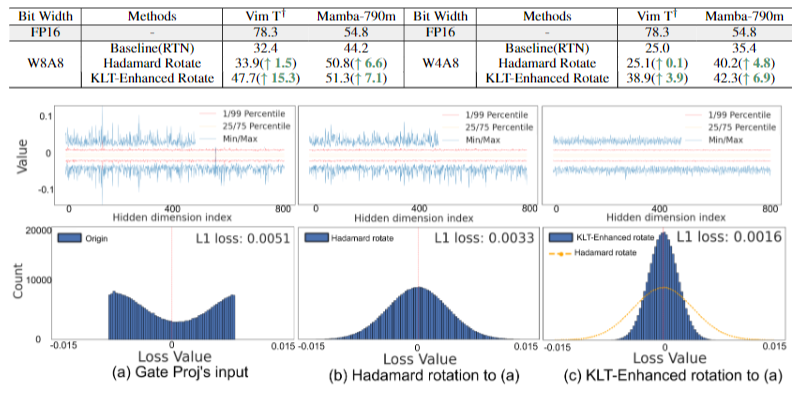
這項工作首次在Mamba模型上實現了高精度量化,為Mamba模型的高效部署和推理開辟了新的途徑,尤其是邊緣設備上。
-
神經網絡
+關注
關注
42文章
4807瀏覽量
102792 -
人工智能
+關注
關注
1804文章
48717瀏覽量
246536 -
模型
+關注
關注
1文章
3487瀏覽量
49995 -
后摩智能
+關注
關注
0文章
33瀏覽量
1329
原文標題:后摩前沿 | MambaQuant:首個Mamba系列模型量化方案,精度近乎無損
文章出處:【微信號:后摩智能,微信公眾號:后摩智能】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
解讀大模型FP量化的解決方案

為什么量化caffe模型完,模型的input_shape被output_shape替換了?
INT8量化常見問題的解決方案
可以使用已有的量化表作為輸入來完成BModel模型的量化嗎?
【KV260視覺入門套件試用體驗】Vitis AI 進行模型校準和來量化
TensorFlow模型優化:模型量化
談談MNN的模型量化(一)數學模型


Yolo系列模型的部署、精度對齊與int8量化加速
Transformer迎來強勁競爭者 新架構Mamba引爆AI圈!

幻方量化發布了國內首個開源MoE大模型—DeepSeekMoE

理解LLM中的模型量化

Mamba入局圖像復原,達成新SOTA





 工商網監
工商網監
評論