 深度學習為圖片壓縮算法,可以節省55%帶寬
深度學習為圖片壓縮算法,可以節省55%帶寬
隨著互聯網的發展,人們對高清圖片的需求也在不斷增加,在保證圖像畫質的情況下最大程度降低圖像體積已成為行業發展趨勢。
目前比較出名的圖像壓縮格式是:WebP與HEIF。
WebP:谷歌旗下的一款可以同時提供有損壓縮和無損壓縮的圖片文件格式,其以VP8編碼為內核,在2011年11月開始可以支持無損和透明色功能。目前facebook等網站都已采用這種圖片格式。
BPG:知名程序員、ffmpeg和QEMU等項目作者Fabrice Bellard推出的圖像格式,它以HEVC編碼為內核,在相同體積下,BPG文件大小只有JPEG的一半。另外BPG還支持8位和16位通道等等。盡管BPG有很好的壓縮效果,但是HEVC的專利費很高,所以目前的市場使用比較少。
這兩大技術都各有優劣,為了最大程度的應對市場需求采用深度學習技術做圖片壓縮算法已受到業界越來越多的關注。
深度學習技術設計圖片壓縮算法
通過深度學習技術設計壓縮算法不僅能在不借助HEVC的情況下設計出更適合商用的更高壓縮比的圖片壓縮算法,還可以在保持圖片畫質同時,盡可能降低圖片體積。
在圖片壓縮領域主要用到的深度學習技術是卷積神經網絡(CNN)。卷積神經網絡就像搭積木一樣,一個卷積神經網絡由卷積、池化、非線性函數、歸一化層等模塊組成,最終的輸出根據應用而定;如在人臉識別領域,我們可以用它來提取一串特征表示一幅人臉圖片,然后通過比較特征的異同進行人臉識別。
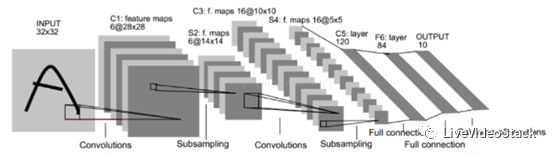
圖1:卷積神經網絡示意圖(來源http://blog.csdn.net/hjimce/article/details/47323463)
如何利用卷積神經網絡做壓縮?
如圖2所示,完整的框架包括CNN編碼器、量化、反量化、CNN解碼器、熵編碼、碼字估計和碼率-失真優化等幾個模塊。編碼器的作用是將圖片轉換為壓縮特征,解碼器就是從壓縮特征恢復出原始圖片。其中編碼網絡和解碼器,可以用卷積、池化、非線性等模塊進行設計和搭建。
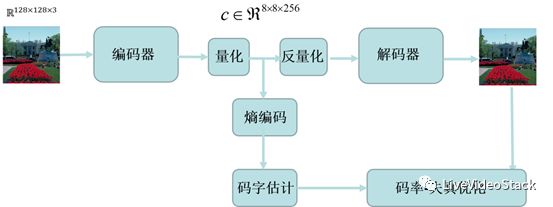
圖2:用深度學習進行圖片壓縮示意圖
如何評判壓縮算法?
目前評判一個壓縮算法的重要指標有三個:PSNR(Peak Signal to Noise Ratio)、BPP(bit per pixel)和MS-SSIM(multi-scaleSSIM index)。我們知道,任何數據在計算機內都是以比特形式存儲,所需比特數越多則占據的存儲空間越大。PSNR用來評估解碼后圖像恢復質量,BPP用于表示圖像中每個像素所占據的比特數,MS-SSIM值用來衡量圖片的主觀質量,簡單來說在同等的Rate/BPP下PSNR更高,壓縮效果更好,MSSIM更高,主觀感受更好。
下圖為圖鴨圖片格式Tiny Network Graphics (TNG) 與其他圖片格式在同一壓縮比下的PSNR值與MS-SSIM值對比:
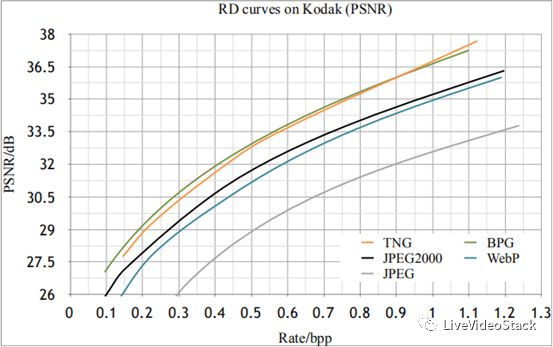
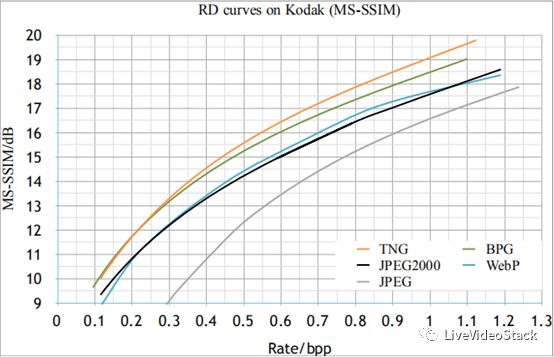
圖3:圖鴨TNG圖片格式與其他圖片格式在同一壓縮比下的PSNR值與MS-SSIM值對比
從上圖對比中可以看到,圖鴨的TNG在MS-SSIM值上一直處于領先狀態,其PSNR值也已超過WebP、JPEG2000等商用算法。
如何用深度學習做壓縮?
談到如何用深度學習做壓縮,我們以圖片來舉例。將一張大小 768 * 512 的三通道圖片送入編碼網絡,進行前向處理后,會得到占據 96 * 64 * 192 個數據單元的壓縮特征。有計算機基礎的讀者可能會想到,這個數據單元中可放一個浮點數,整形數,或者是二進制數。那到底應該放入什么類型的數據呢?
從圖像恢復角度和神經網絡原理來講,如果壓縮特征數據都是浮點數,恢復圖像質量是最高的。但一個浮點數占據32個比特位,圖片的計算公式為( 96 * 64 * 192 * 32)/(768*512)=96,壓縮后反而每個像素占據比特從24變到96!圖片大小非但沒有壓縮,反而增加了,這是一個糟糕的結果,很顯然浮點數不是好的選擇。
所以為了設計靠譜的算法,可以使用一種稱為量化的技術,它的目的是將浮點數轉換為整數或二進制數,最簡單的操作是去掉浮點數后面的小數,浮點數變成整數后只占據8比特,則表示每個像素要占據24個比特位。與之對應,在解碼端,可以使用反量化技術將變換后的特征數據恢復成浮點數,如給整數加上一個隨機小數,這樣可以一定程度上降低量化對神經網絡精度的影響,從而提高恢復圖像的質量。
即使壓縮特征中每個數據占據1個比特位,可是壓縮還是有可進步的空間。那如何進一步優化算法?再看下BPP的計算公式。
假設每個壓縮特征數據單元占據1個比特,則公式可寫成:(96*64*192*1)/(768*512)=3,計算結果是3 bit/pixel,從壓縮的目的來看,BPP越小越好。在這個公式中,分母由圖像決定,我們進行調整的只有分子:96、64、192,這三個數字與網絡結構相關。所以,如果我們設計出更優的網絡結構,這三個數字也會變小。
那1與哪些模塊相關?1表示每個壓縮特征數據單元平均占據1個比特位,量化會影響這個數字,但它不是唯一的影響因素,它還與碼率控制和熵編碼有關。碼率控制的目的是在保證圖像恢復質量的前提下,讓壓縮特征數據單元中的數據分布盡可能集中、出現數值范圍盡可能小,這樣我們就可以通過熵編碼技術來進一步降低1這個數值,圖像壓縮率會進一步提升。
總結
總體而言,借助于深度學習設計視頻和圖像壓縮算法是一項非常具有前景,但同時也非常有挑戰性的技術。
最后,大家可以點擊閱讀原文獲取TNG測試鏈接(建議在PC端測試)。
-
帶寬
+關注
關注
3文章
991瀏覽量
41743 -
圖片壓縮
+關注
關注
0文章
6瀏覽量
5604
原文標題:深度學習為圖片壓縮算法賦能:節省55%帶寬
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
華為云深度學習服務,讓企業智能從此不求人
啃論文俱樂部 | 壓縮算法團隊:我們是如何開展對壓縮算法的學習
電腦上的圖片怎么批量壓縮
深度學習模型壓縮與加速綜述

基于MobileNet的多目標跟蹤深度學習算法





 工商網監
工商網監
評論