") 神經(jīng)網(wǎng)絡(luò)瘦身:關(guān)于SqueezeNet的創(chuàng)新點(diǎn)、網(wǎng)絡(luò)結(jié)構(gòu)
神經(jīng)網(wǎng)絡(luò)瘦身:關(guān)于SqueezeNet的創(chuàng)新點(diǎn)、網(wǎng)絡(luò)結(jié)構(gòu)
今年二月份,UC Berkeley和Stanford一幫人在arXiv貼了一篇文章:
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and<0.5MB model size(https://arxiv.org/abs/1602.07360)
這篇文章做成了許多人夢寐以求的事——壓縮神經(jīng)網(wǎng)絡(luò)參數(shù)。但和以往不同,原作不是在前人網(wǎng)絡(luò)基礎(chǔ)上修修補(bǔ)補(bǔ)(例如Deep Compression),而是自己設(shè)計(jì)了一個(gè)全新的網(wǎng)絡(luò),它用了比AlexNet少50倍的參數(shù),達(dá)到了AlexNet相同的精度!
關(guān)于SqueezeNet的創(chuàng)新點(diǎn)、網(wǎng)絡(luò)結(jié)構(gòu),國內(nèi)已經(jīng)有若干愛好者發(fā)布了相關(guān)的簡介,如這篇(http://blog.csdn.net/xbinworld/article/details/50897870)、這篇(http://blog.csdn.net/shenxiaolu1984/article/details/51444525),國外的文獻(xiàn)沒有查,相信肯定也有很多。
本文關(guān)注的重點(diǎn)在SqueezeNet為什么能實(shí)現(xiàn)網(wǎng)絡(luò)瘦身?難道網(wǎng)絡(luò)參數(shù)的冗余性就那么強(qiáng)嗎?或者說很多參數(shù)都是浪費(fèi)的、無意義的?
為了更好的解釋以上問題,先給出AlexNet和SqueezeNet結(jié)構(gòu)圖示:
AlexNet
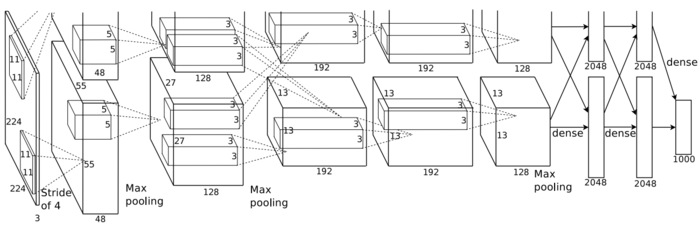
圖1 AlexNet示意圖
圖2 AlexNet網(wǎng)絡(luò)結(jié)構(gòu)
SqueezeNet
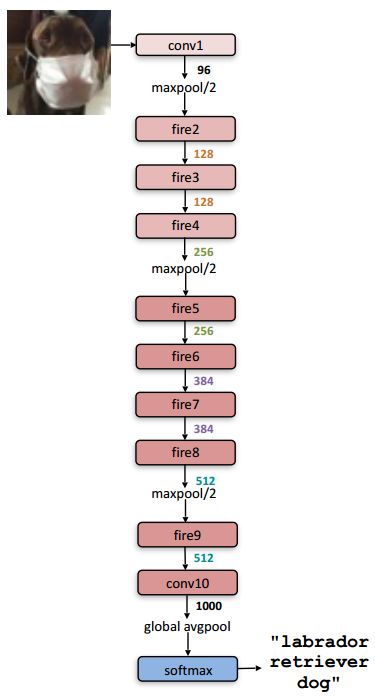
圖3 SqueezeNet示意圖
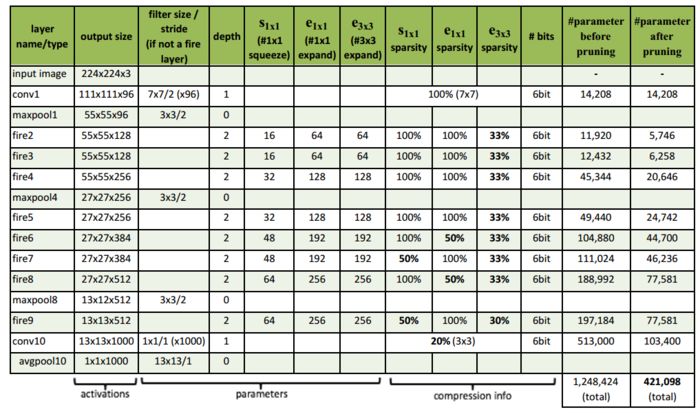
圖4 SqueezeNet網(wǎng)絡(luò)結(jié)構(gòu)
為什么SqueezeNet能夠以更少的參數(shù)實(shí)現(xiàn)AlexNet相同的精度?
下面的表格直觀的展示了SqueezeNet的參數(shù)量,僅為AlexNet的1/48。
| 網(wǎng)絡(luò) | 參數(shù)量 |
|---|---|
| AlexNet | 60M |
| SqueezeNet | 1.25M |
乍一看,感覺非常不科學(xué),怎么可能相差如此懸殊的參數(shù)量實(shí)現(xiàn)了相同的識(shí)別精度?
我們先考慮一個(gè)非常簡單的例子,這個(gè)例子可以說是SqueezeNet和AlexNet的縮影:
1、一層卷積,卷積核大小為5×5
2、兩層卷積,卷積核大小為3×3
以上兩種卷積方式除了卷積核大小不同,其它變量均相同,為了方便后文計(jì)算,定義輸入通道數(shù)1,輸出通道數(shù)為C(兩層卷積為C'),輸出尺寸N×N。
按照目前的理論,神經(jīng)網(wǎng)絡(luò)應(yīng)該盡可能的采用多層小卷積,以減少參數(shù)量,增加網(wǎng)絡(luò)的非線性。但隨著參數(shù)的減少,計(jì)算量卻增加了!根據(jù)上面的例子,大致算一下,為了簡便,只考慮乘法的計(jì)算量:
5×5一層卷積計(jì)算量是25×C×N×N
3×3兩層卷積的計(jì)算量是9×C×(1+C')×N×N
很明顯25C<9C(1+C')。
這說明了什么?說明了“多層小卷積核”的確增大了計(jì)算量!
我們再回過頭考慮SqueezeNet和AlexNet,兩個(gè)網(wǎng)絡(luò)的架構(gòu)如上面4幅圖所示,可以看出SqueezeNet比AlexNet深不少,SqueezeNet的卷積核也更小一些,這就導(dǎo)致了SqueezeNet計(jì)算量遠(yuǎn)遠(yuǎn)高于AlexNet(有待商榷,需要進(jìn)一步確認(rèn),由于Fire module中的squeeze layer從某種程度上減少了計(jì)算量,SqueezeNet的計(jì)算量可能并不大)。
可是論文原文過度關(guān)注參數(shù)個(gè)數(shù),忽略計(jì)算量,這樣的對比方式貌似不太妥當(dāng)。事實(shí)上,目前最新的深層神經(jīng)網(wǎng)絡(luò)都是通過增加計(jì)算量換來更少的參數(shù),可是為什么這樣做效果會(huì)很好?
因?yàn)閮?nèi)存讀取耗時(shí)要遠(yuǎn)大于計(jì)算耗時(shí)!
如此一來,問題就簡單了,不考慮網(wǎng)絡(luò)本身架構(gòu)的優(yōu)劣性,深層網(wǎng)絡(luò)之所以如此成功,就是因?yàn)榘褏?shù)讀取的代價(jià)轉(zhuǎn)移到計(jì)算量上了,考慮的目前人類計(jì)算機(jī)的發(fā)展水平,計(jì)算耗時(shí)還是要遠(yuǎn)遠(yuǎn)小于數(shù)據(jù)存取耗時(shí)的,這也是“多層小卷積核”策略成功的根源。
關(guān)于Dense-Sparse-Dense(DSD)訓(xùn)練法
不得不說一下原作的這個(gè)小發(fā)現(xiàn),使用裁剪之后的模型為初始值,再次進(jìn)行訓(xùn)練調(diào)優(yōu)所有參數(shù),正確率能夠提升4.3%。 稀疏相當(dāng)于一種正則化,有機(jī)會(huì)把解從局部極小中解放出來。這種方法稱為DSD (Dense→Sparse→Dense)。
這個(gè)和我們?nèi)祟悓W(xué)習(xí)知識(shí)的過程是多么相似!人類每隔一段時(shí)間重新溫習(xí)一下學(xué)過的知識(shí),會(huì)增加對所學(xué)知識(shí)的印象。我們可以把“隔一段時(shí)間”理解為“裁剪”,即忘卻那些不怎么重要的參數(shù),“再學(xué)習(xí)”理解為從新訓(xùn)練,即強(qiáng)化之前的參數(shù),使其識(shí)別精度更高!
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4806瀏覽量
102688
原文標(biāo)題:神經(jīng)網(wǎng)絡(luò)瘦身:SqueezeNet
文章出處:【微信號(hào):CAAI-1981,微信公眾號(hào):中國人工智能學(xué)會(huì)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
【案例分享】ART神經(jīng)網(wǎng)絡(luò)與SOM神經(jīng)網(wǎng)絡(luò)
神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)搜索有什么優(yōu)勢?
卷積神經(jīng)網(wǎng)絡(luò)(CNN)是如何定義的?
卷積神經(jīng)網(wǎng)絡(luò)模型發(fā)展及應(yīng)用
神經(jīng)網(wǎng)絡(luò)分類

基于自適應(yīng)果蠅算法的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)訓(xùn)練
基于神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)在命名實(shí)體識(shí)別中應(yīng)用的分析與總結(jié)

一種新型神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu):膠囊網(wǎng)絡(luò)
一種改進(jìn)的深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)搜索方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論