 大語言模型的解碼策略與關鍵優化總結
大語言模型的解碼策略與關鍵優化總結

本文系統性地闡述了大型語言模型(Large Language Models, LLMs)中的解碼策略技術原理及其實踐應用。通過深入分析各類解碼算法的工作機制、性能特征和優化方法,為研究者和工程師提供了全面的技術參考。主要涵蓋貪婪解碼、束搜索、采樣技術等核心解碼方法,以及溫度參數、懲罰機制等關鍵優化手段。
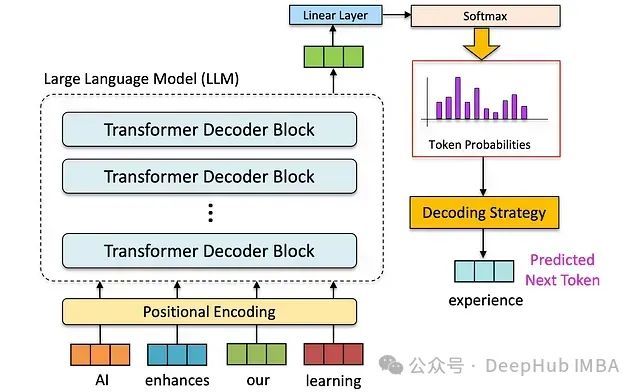
大型語言模型的技術基礎
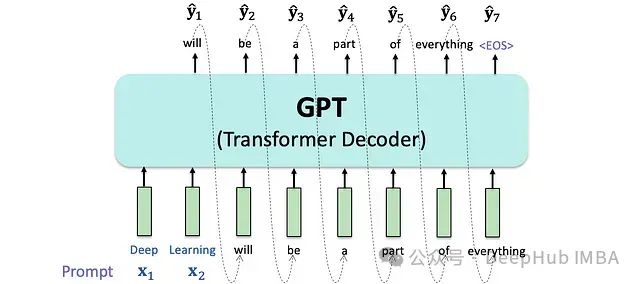
大型語言模型是當代自然語言處理技術的核心支柱,其基礎架構建立在自回歸語言建模的理論基礎之上。模型通過序列條件概率建模,實現對下一個可能token的精確預測。
大型語言模型的自回歸特性體現為基于已知序列進行逐token概率預測的過程。在每個時間步,模型基于已生成序列計算下一個token的條件概率分布。
從形式化角度,該過程可表述為條件概率的連乘形式:
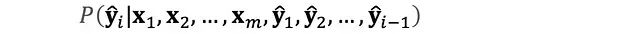
此自回歸機制確保了模型能夠保持上下文的語義連貫性,并在此基礎上構建完整的輸出序列。
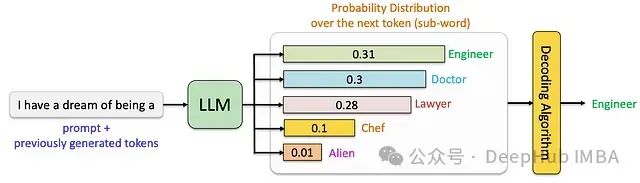
解碼策略是將模型輸出的概率分布轉化為具體文本序列的關鍵技術環節。不同解碼策略的選擇直接影響生成文本的多個質量維度,包括語義連貫性、表達多樣性和邏輯準確性。以下將詳細分析各類主流解碼策略的技術特點。
貪婪解碼策略分析
貪婪解碼采用確定性方法,在每個時間步選擇概率最高的候選token。
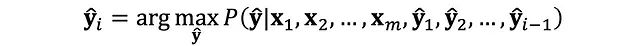

技術特性分析:
計算效率:實現簡單,計算開銷小,適用于對響應時間要求較高的場景
局限性:容易陷入局部最優解,生成文本存在重復性問題
實例:
輸入序列:"My favorite color is" 貪婪解碼輸出:"My favorite color is blue blue blue blue is blue and blue is my favorite color blue"
束搜索技術原理
束搜索通過并行維護多個候選序列來優化解碼過程。其中束寬度參數k決定了并行探索路徑的數量,直接影響輸出質量與計算資源的平衡。
束搜索實現機制
初始化階段:從概率最高的初始token序列開始
迭代拓展:為每個候選序列計算并附加top-k個最可能的后續token
評分篩選:基于累積概率為新序列評分,保留得分最高的k個序列
終止判斷:直至達到最大序列長度或生成結束標志
以生成"the cat sat on the mat"為例(k=2)進行技術分析:
初始候選序列:"the"和"a",基于每個候選計算下一步最可能的兩個token
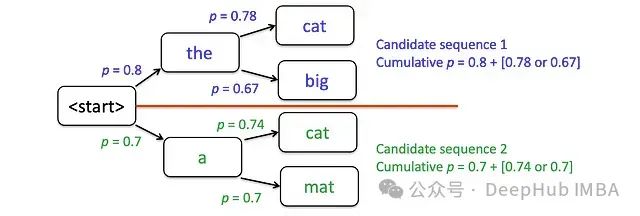
每輪迭代后保留兩個最優得分序列(例如保留"the cat"和"a cat",舍棄"the big"和"a mat")
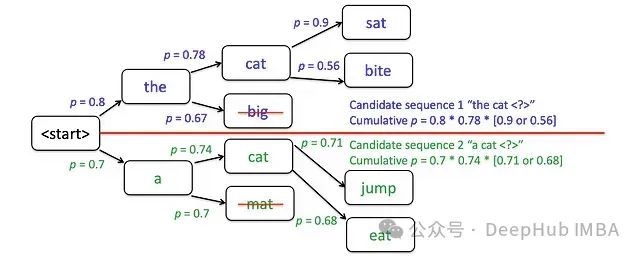
迭代過程中的概率優化選擇:"the cat"作為首選序列,"a cat"作為次優序列。頂部候選項的累積概率更高時,將作為后續迭代的基準序列。
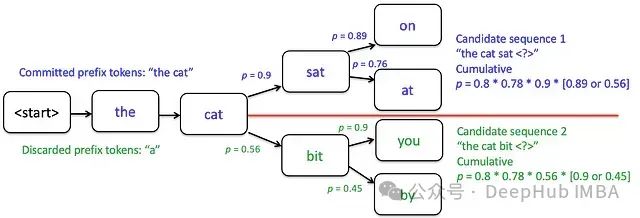
技術特性分析:
優勢:在探索與利用間實現平衡,相比貪婪解碼產生更多樣化且連貫的文本
局限:計算成本隨束寬k增加而顯著上升,且仍可能出現重復性問題
束搜索輸出示例(k=3):
輸入:"My favorite color is" 輸出序列1:"My favorite color is blue because blue is a great color" 輸出序列2:"My favorite color is blue, and I love blue clothes" 輸出序列3:"My favorite color is blue, blue is just the best"
基于采樣的解碼技術
隨機采樣基礎原理
自然語言具有內在的多樣性分布特征,這與傳統確定性解碼方法產生的單一輸出形成鮮明對比。基于采樣的解碼技術通過概率分布采樣來實現更貼近人類表達特征的文本生成。
隨機采樣是最基礎的采樣類解碼方法,其核心機制是直接從模型輸出的概率分布中進行隨機選擇。

這種簡單的隨機采樣存在明顯的技術缺陷:在概率分布的長尾區域(即大量低概率token的聚集區域),模型的預測質量普遍較低。這種現象會導致生成的文本出現語法錯誤或語義不連貫的問題。
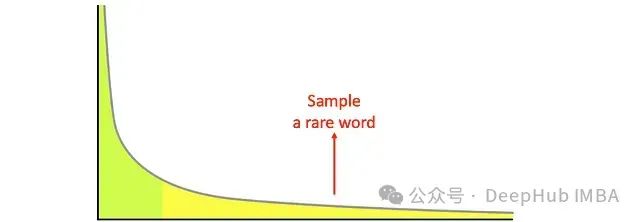
Top-k采樣技術實現
為了克服純隨機采樣的局限性,Top-k采樣通過限定采樣空間來優化生成質量。在每個時間步t,系統僅從概率最高的k個token中進行隨機采樣。
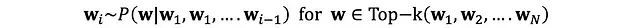
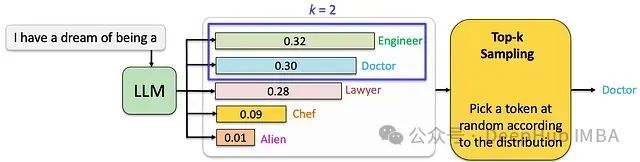
技術特性分析:
優化效果:通過引入受控隨機性,在保持文本多樣性的同時提升生成質量
參數敏感性:k值的選擇對生成效果有顯著影響,需要根據具體應用場景進行優化調整
計算效率:相比束搜索,具有較好的效率和資源利用率
核采樣技術
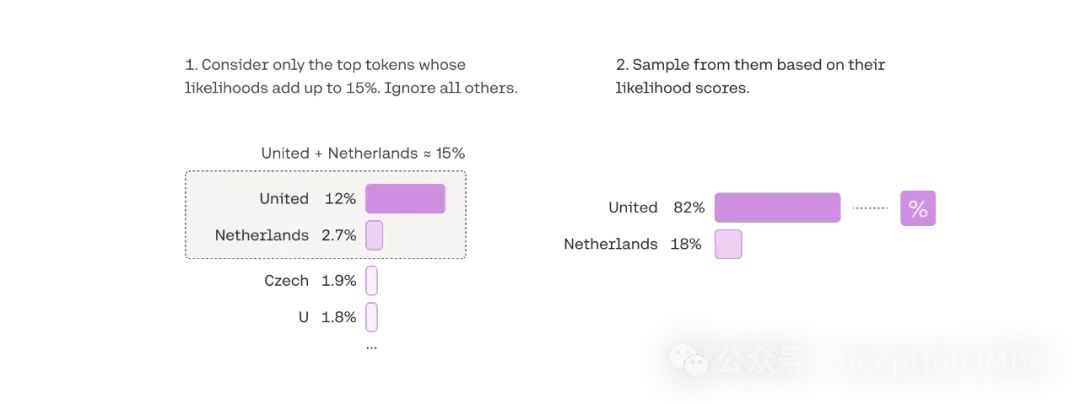
核采樣(Nucleus Sampling,又稱Top-p采樣)是一種動態調整采樣空間的高級解碼技術。其核心思想是僅從累積概率達到閾值p的最小token集合中進行采樣,從而實現采樣空間的自適應調整。
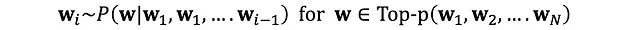

核采樣技術優勢
動態采樣空間:根據概率分布特征自適應調整候選token數量
平衡性能:在文本流暢性和創造性之間達到較好的平衡
自適應特性:能夠根據不同語境自動調整生成策略
參數配置分析
核采樣的效果高度依賴于閾值p的選擇:
p = 0.9:采樣空間收窄,生成文本傾向于保守,適合需要高準確性的場景
p = 0.5:采樣空間適中,在創造性和準確性之間取得平衡
p = 1.0:等同于完全隨機采樣,適用于需要最大創造性的場景
技術局限性:核采樣在計算資源需求上可能高于Top-k采樣,且參數調優需要較多經驗積累。
溫度參數原理
溫度參數(T)是一個核心的概率分布調節機制,通過調整logits的分布來影響token的選擇概率。其數學表達式為:
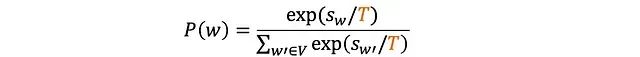
溫度參數
T = 1.0:保持原始概率分布特征
T > 1.0:增加分布的熵,提升采樣多樣性
0 < T < 1.0:降低分布的熵,增強確定性
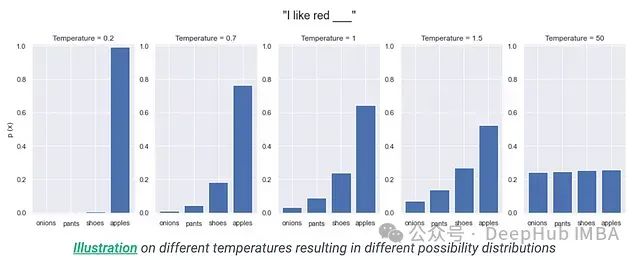
溫度參數可與各類解碼策略結合使用,通過調節概率分布的"陡峭程度"來實現對生成文本特征的精細控制。需要注意的是這是一種預處理機制,而非獨立的解碼算法。
ChatGPT解碼策略實踐分析
ChatGPT的解碼機制集成了多種先進技術,通過參數組合實現靈活的文本生成控制。
核心參數配置
溫度調節機制
- 低溫度配置(T≈0.2):用于需要確定性強的場景
高溫度配置(T≈0.8):適用于創意生成任務
核采樣實現
動態調整采樣空間
自適應平衡生成質量
懲罰機制
- 頻率懲罰:抑制詞語重復使用
存在懲罰:促進詞匯多樣性
技術優化策略
參數協同調優
- 場景適應性配置
實時性能監控
總結
解碼策略在利用 LLM 的力量來生成高質量、連貫和多樣化的文本方面發揮著關鍵作用。從貪婪解碼的簡單性到 核采樣的復雜性,各種解碼算法在連貫性和多樣性之間提供了微妙的平衡。每種算法都有其優點和缺點,理解它們的細微差別對于優化 LLM 在各種應用中的性能至關重要。
貪婪解碼:一種直接的方法,它在每個步驟選擇最可能的詞,通常導致連貫但多樣性較差的文本。
束搜索:貪婪解碼的擴展,它考慮了多個可能的序列,從而產生更多樣化和連貫的文本。
Top-k:此參數控制模型生成的輸出的多樣性。Top-K 的值為 5 意味著僅考慮最可能的 5 個詞,這可以提高生成的文本的流暢性并減少重復。
Top-p (Nucleus 采樣):此參數控制模型生成的輸出的多樣性。值為 0.8 意味著僅考慮最可能的詞的 top 80%,這可以提高生成的文本的流暢性并減少重復。
溫度:此超參數控制 LLM 輸出的隨機性。較低的溫度(例如 0.7)有利于更確定和較少多樣化的輸出,而較高的溫度(例如 1.05)可能導致更多樣化的輸出,但也可能引入更多錯誤。
頻率懲罰:這種技術通過對生成文本中頻繁使用的詞施加懲罰來阻止重復,從而減少冗余并鼓勵使用更廣泛的詞。它有助于防止模型生成重復文本或陷入循環。
重復懲罰:一個參數,用于控制生成文本中重復的可能性,確保更多樣化和引人入勝的響應。
理解和選擇適當的解碼算法對于優化 LLM 在各種應用中的性能至關重要。隨著該領域的研究不斷發展,可能會出現新的解碼技術,從而進一步增強 LLM 在生成類人文本方面的能力。通過利用高級解碼算法,像 ChatGPT 這樣的平臺可以產生連貫、引人入勝和多樣化的響應,使與 AI 的交互更加自然和有效。
作者:LM Po
本文來源:DeepHub IMBA
-
語言模型
+關注
關注
0文章
561瀏覽量
10733 -
解碼技術
+關注
關注
0文章
8瀏覽量
10353 -
LLM
+關注
關注
1文章
323瀏覽量
768
發布評論請先 登錄





 工商網監
工商網監
評論