 PIMCHIP-S300 獲評中國電子報2024年AI芯片創新優秀產品
PIMCHIP-S300 獲評中國電子報2024年AI芯片創新優秀產品
無論是市場動力、技術創新還是熱點趨勢,2024年的半導體產業都繞不開“AI”這個關鍵詞。從算力芯片,到芯片互聯、異構聚合等AI基礎設施,再到軟件平臺、開發者社區與生態合作組織等平臺生態建設,以及算力集群等大規模應用——半導體產業鏈的每一個節點,都在跟隨AI的腳步創新發展。
1月22日,“中國電子報編輯選擇——2024年AI芯片創新產品及生態應用”正式出爐。本次編輯選擇結合行業關注、市場熱點和企業動態,通過考察技術領先性、市場競爭力、產品應用性、生態構建能力等指標,推選出10個創新產品及生態應用,涵蓋優秀產品、創新技術、生態貢獻和卓越應用等,以期為行業發展樹立典范,為業界人士提供參考,為產業合作提供契機。
第6代TPU Trillium
谷歌公司
優秀產品
Trillium(TPU v6e)是谷歌第 6 代 TPU。相比上一代產品TPU v5e,Trillium訓練性能提升超 4 倍,推理吞吐量提升3 倍;單顆芯片峰值計算能力(Int8)提升4.7倍,達到1836TOPs;HBM容量及帶寬各提升1倍,分別達到32GB和1640GBps;芯片間互聯帶寬提高一倍,達到3584Gbps;能源效率提升67%。Trillium支持最多256個v6e芯片訓練,以及最多8個芯片的單主機推理。在擴展能力方面,使用由3072個v6e芯片組成的12個計算模塊進行部署時,Trillium實現了99%的擴展效率。即便在跨數據中心網絡環境下,使用由6144個芯片組成的24個計算模塊對gpt3-175b進行預訓練,Trillium也展現出94%的擴展效率。
擁有45TOPS NPU的PC平臺驍龍X Elite
高通公司
優秀產品
驍龍X Elite是高通專為Windows 11 AI+ PC打造的PC平臺,擁有45TOPS NPU算力。該平臺采用定制的集成高通Oryon CPU,擁有12個高性能內核,主頻達3.8GHz,雙核增強技術可將兩個高性能內核提升到4.3GHz,是首個主頻達到4GHz以上的ARM架構CPU核心;集成Adreno GPU能夠實現每秒4.6萬億次浮點運算的圖形性能。驍龍X Elite采用了全新異構高通AI引擎,擁有45TOPS算力NPU。此外,該平臺支持10Gbps 5G下載速度,以及高通FastConnect7800支持的Wi-Fi 7等通信技術。除驍龍X Elite外,驍龍X系列還包括驍龍X Plus、驍龍X Plus(8核)以及驍龍X平臺。目前,來自眾多領先OEM廠商的超過60款PC設計已經量產或正在開發中,包括華碩、宏基、戴爾、HP和聯想等。
多模態智慧感知決策AI芯片PIMCHIP-S300
北京蘋芯科技有限公司
優秀產品
PIMCHIP-S300是一款基于存算一體技術的多模態智慧感知決策AI芯片。該芯片搭載的SRAM存算一體技術能夠使計算直接在存儲器內部發生,有效減少了傳統架構中數據搬運帶來的能耗和延遲問題,核心能效比達27TOPS/W,同時能夠實現低功耗運行。該芯片支持音頻、視頻多模態融合感知,具備超低功耗喚醒、VAD(聲音活動檢測)、語音識別、運動監測和視覺識別功能,可適用于智能穿戴、智慧家居、無人機等多個新興行業,為合作伙伴帶來高能效、低成本的解決方案,推動其產品的智能化轉型。
異構GPU協同訓練方案HGCT
上海壁仞科技股份有限公司

創新技術
壁仞科技自主原創的異構GPU協同訓練方案HGCT,是業界首次實現統一異構通信庫支持多種不同廠商、不同型號的GPU進行GDR高速通信,也是業界首次實現四種異構GPU混合訓練同一個大模型,將異構算力有效聚合,端到端混訓效率達到95-98%,突破了大模型異構算力孤島難題,有望實現萬卡、十萬卡異構集群混訓。該方案具備普適性、易用性、兼容性,使多種國產GPU和英偉達GPU算力的異構聚合成為可能,從而有助于加快國產GPU的落地遷移,有助于應用方最大化異構GPU集群利用效率,助力國產大模型落地。壁仞科技已聯合中國移動發布“芯合”異構混合并行訓練系統,聯合中國電信、中興通訊等發布“智算異構四芯混訓解決方案”。
實現光學I/O芯粒的完全集成
英特爾公司

創新技術
面向大模型和生成式AI的部署需求,數據中心需要指數級提升的I/O帶寬和更長的傳輸距離,以支持更大規模的處理器集群和更加高效的架構。在2024年光纖通信大會上,英特爾展示了完全集成的OCI(光學計算互連)芯粒。基于已實際驗證的硅光子技術,英特爾在OCI芯粒中集成了包含片上激光器的硅光子集成電路(PIC)、光放大器和電子集成電路。英特爾現場展示的OCI芯粒與自家CPU封裝在一起,但它也能與下一代CPU、GPU、IPU等SOC集成。該OCI芯粒可在最長100米的光纖上,單向支持64個32Gbps通道,以滿足AI基礎設施日益增長的對更高帶寬、更低功耗和更長傳輸距離的需求。同時有助于實現可擴展的CPU和GPU集群連接,和包括一致性內存擴展及資源解聚的新型計算架構。
用于AI XPU的3.5D面對面(F2F)封裝技術
博通公司
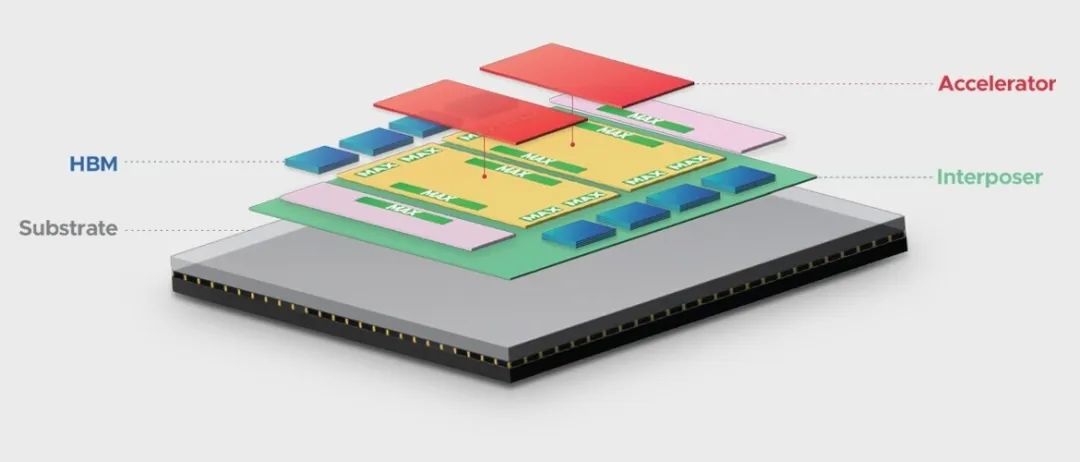
創新技術
2024年12月,博通公司推出3.5D系統級封裝平臺技術XDSiP,助力消費級人工智能領域企業開發下一代定制加速器(XPU)。該3.5D技術結合了3D硅片堆疊與2.5D封裝,能在單個封裝器件中集成超6000平方毫米的硅片以及多達12個HBM堆棧。基于創新的面對面(F2F)堆疊方式,3.5D XDSiP直接連接上下層芯片的頂部金屬層,從而提供了密集且可靠的連接,同時將電氣干擾降至最低,并具備出色的機械強度。相比傳統的面對背(F2B)封裝,3.5D XDSiP技術將堆疊芯片之間的信號密度提升7倍,芯片間接口的功耗降低10倍,降低了3D堆疊內計算、內存和輸入/輸出組件之間的延遲,且能夠實現更小的中介層和封裝尺寸。
開源軟件平臺ROCm
超威半導體產品(中國)有限公司
生態貢獻
ROCm(Radeon Open Compute Platform)是一個開源的軟件平臺,通過支持異構硬件、優化平臺工具、提升開發者友好程度以及拓展合作伙伴等方式,助力AI產業生態建設。ROCm既支持AMD的多種GPU架構,還推出了適用于中國本土需求的定制化解決方案;提供了諸多優化的庫和工具鏈,如MIOpen(深度學習庫)、rocBLAS(線性代數庫)和rocFFT(快速傅里葉變換庫)等,為開發者提供了強大的開發基礎,加速了算法的實現和優化。該平臺同時提供了編譯器工具鏈、性能分析工具、調試工具等多種類型的平臺工具,通過提供詳盡文檔和教程等方式給予開發者支持。
海光產業生態合作組織
海光信息技術股份有限公司

生態貢獻
海光產業生態合作組織(簡稱:光合組織)是海光信息打造的貫通“芯片設計與制造—整機系統—軟件生態—應用服務”各個環節的開放創新鏈和產業鏈,凝聚了超過4000家上下游合作伙伴。該組織通過共同開展技術攻關、方案優化、應用創新及市場開拓,為千行百業提供了高質量的產品及解決方案。海光信息C86-3G、C86-4G等CPU系列產品,深算一號、深算二號等DCU系列產品,完全兼容x86指令集以及國際主流操作系統和應用軟件,為該組織的應用拓展提供了產品基礎。
慶陽“東數西算”智能算力樞紐示范工程
上海燧原科技股份有限公司

卓越應用
2024年6月19日,由燧原科技支持建設的全國算力樞紐(甘肅·慶陽)首批萬P算力上線,首個國產萬卡算力集群啟動。該算力集群搭建燧原科技新一代人工智能推理加速卡“燧原S60”。在項目建設過程中,燧原科技致力于打造智算中心的新范式,解決誰來建設、如何運營、用戶在哪三大核心問題,整合貫通智算產業生態鏈條,實現了智算中心“建”、“運”、“用”的商業閉環與可持續發展,助力慶陽充分發揮大模型算力資源優勢,發展人工智能技術應用,實現當地產業集聚和人才匯聚。
NVIDIA以太網加速xAI構建全球最大AI超級計算機
英偉達公司
卓越應用
2024年10月,英偉達宣布人工智能初創企業xAI的 Colossus 超級計算機集群達到了10萬顆 NVIDIA Hopper GPU規模。該集群使用了英偉達第一款專為 AI打造的以太網網絡平臺 NVIDIA Spectrum-X,是專為多租戶、超大規模的 AI 工廠設計的 RDMA(遠程直接內存訪問)網絡。Colossus 是世界上最大的 AI 超級計算機之一,被用于訓練 xAI 的Grok系列大語言模型,以及為訂閱用戶提供的聊天機器人功能。xAI和英偉達用了122天就建成了所有配套設施和Colossus超級計算機,從第一個機架落地到開始訓練任務,只用了19天。而建造這種規模的系統通常需要數月乃至數年的時間。
-
半導體
+關注
關注
335文章
28563瀏覽量
232255 -
gpu
+關注
關注
28文章
4909瀏覽量
130628 -
AI芯片
+關注
關注
17文章
1968瀏覽量
35688
發布評論請先 登錄
PIMCHIP S300 全球首款28nm節點實現存算一體產品化AI芯片
砥礪創新 芯耀未來——武漢芯源半導體榮膺21ic電子網2024年度“創新驅動獎”
通信市場新突破,維諦技術(Vertiv)獲評中國電信集團級戰略供應商

存算于芯 · 智啟未來 — 2024蘋芯科技產品發布會盛大召開

中國電信連續14年獲評《機構投資者》“最受尊崇企業”
江波龍自研eMMC主控芯片榮獲 “中國芯”優秀技術創新產品獎

再次問鼎“中國芯”大獎!“港華芯”榮獲優秀市場表現產品獎

2024“中國芯”出爐!賽昉科技昉·驚鴻-7110榮膺優秀技術創新產品獎

度亙核芯獲評“三年光電子領域優秀創新成果”!

后摩智能首款存算一體智駕芯片獲評突出創新產品獎
蘋芯科技引領存算一體技術革新 PIMCHIP系列芯片重塑AI計算新格局






 工商網監
工商網監
評論