 Facebook發布高性能AI代碼
Facebook發布高性能AI代碼

Facebook今天宣布發布Tensor Comprehensions,能夠自動將數學符號快速轉換成高性能機器學習代碼,將原本幾天乃至幾周的過程縮短為幾分鐘,大幅提高生產力。
Facebook AI Research(FAIR)今天宣布發布Tensor Comprehensions,這是一個C++庫和數學語言,旨在幫助彌合研究人員和工程師在從事機器學習任務時,在溝通上的差距;研究人員習慣使用數學運算,而工程師則專注在不同的硬件后端運行大規模ML模型的實際需求。
相比其他庫,Tensor Comprehensions 的主要不同是對Just-In-Time編譯有獨特的研究,能夠自動按需生成機器學習社區需要的高性能代碼。
只需幾分鐘生成高性能CPU/GPU代碼,生產力實現數量級提高
要創建新的高性能機器學習(ML)層,典型的工作流程一般包含兩個階段,時間往往需要好幾天乃至數周:
1、首先,一位研究人員在numpy級別的抽象中編寫了一個新的層,并將其與像PyTorch這樣的深度學習庫鏈接起來,然后在小規模實驗中對其進行測試。想法得到驗證后,相關的代碼,性能需要加快一個數量級才能運行大規模實驗。
2、接下來,一位工程師為GPU和CPU編寫高效代碼,而這又需要:
這名工程師需要是高性能計算的專家,這方面人才數量有限
這名工程師需要獲取上下文,制定策略,編寫和調試代碼
將代碼移到后端需要進行一些枯燥但必須完成的任務,例如反復進行參數檢查和添加Boilerplate集成代碼
因此,在過去的幾年中,深度學習社區在很大程度上都依靠CuBLAS,MKL和CuDNN等高性能庫來獲得GPU和CPU上的高性能代碼。不使用這些庫提供的原語來進行試驗,需要極高的工程水平,這對不少研究人員都構成了很大的挑戰。
如果有套件能夠將上述過程從幾周縮短為幾分鐘,我們預期,將這樣一個套件開源將具有重大實用價值。有了Tensor Comprehensions,我們的愿景是讓研究人員用數學符號寫出他們的想法,這個符號自動被我們的系統編譯和調整,結果就是具有良好性能的專用代碼。
在這次發布的版本中,我們將提供:
表達一系列不同機器學習概念的數學符號
用于這一數學符號的基于Halide IR的C++前端
基于Integer Set Library(ISL)的多面體Just-in-Time(JIT)編譯器
基于進化搜索的多線程、多GPU自動調節器
使用高級語法編寫網絡層,無需明確如何運行
最近在高性能圖像處理領域很受歡迎的一門語言是Halide。Halide使用類似的高級函數語法來描述圖像處理流水線,然后在單獨的代碼塊中,明確將其調度(schedule)到硬件上,詳細指定運算如何平鋪、矢量化、并行和融合。這對于擁有架構專業知識的人來說,是一種非常高效的語言,但對于大多數機器學習從業者卻很難使用。目前有很多研究積極關注Halide的自動調度(Automatic scheduling),但對于在GPU上運行的ML代碼,還沒有很好的解決方案。
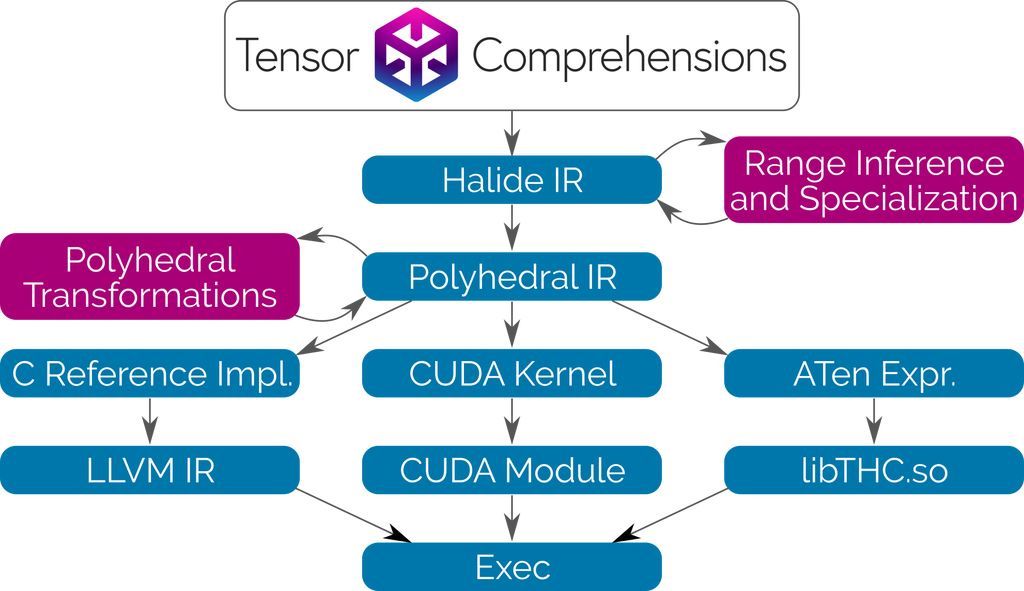
Tensor Comprehensions使用Halide編譯器作為庫。在Halide的中間表示(IR)和分析工具的基礎上,將其與多面體編譯技術相結合,使用者可以用類似的高級語法編寫網絡層,而無需明確它將如何運行。我們還成功使語言更加簡潔,無需指定減法(reduction)的循環邊界。

Tensor Comprehensions使用Halide和Polyhedral Compilation 技術,自動合成CUDA內核。這種轉換會為通用算子融合、快速本地內存、快速減法和JIT類型特化進行優化。由于沒有或者沒有去優化內存管理,我們的流程可以輕松高效地集成到任何ML框架和任何允許調用C++函數的語言中。
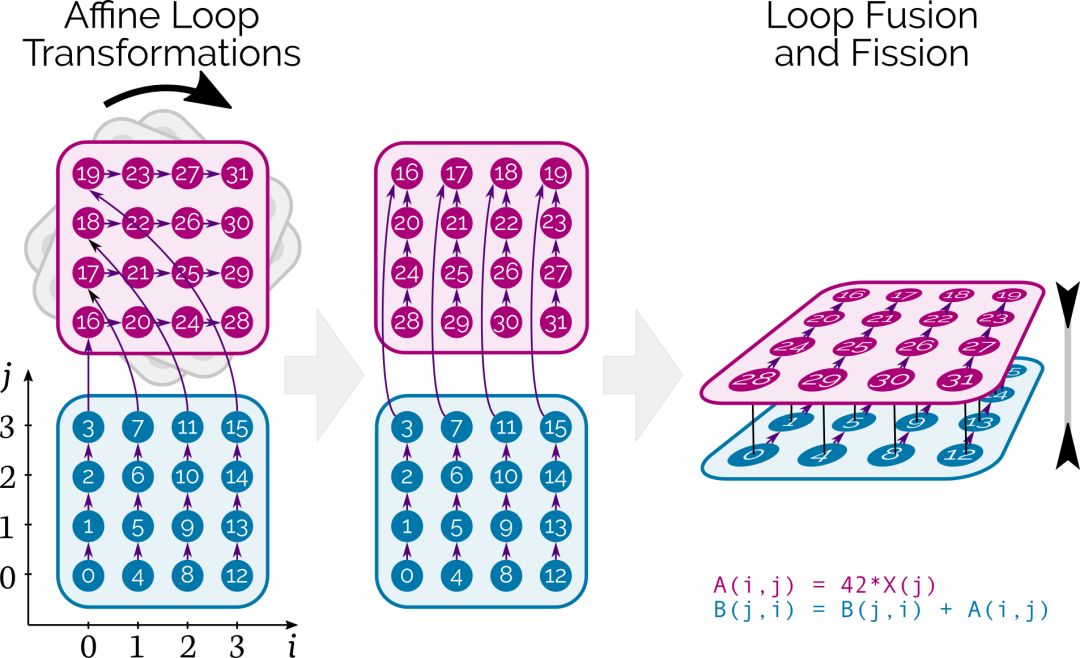
與傳統的編譯器技術和庫的方法相反,多面編譯(Polyhedral Compilation)讓Tensor Comprehensions為每個新網絡按需調度單個張量元素的計算。
在CUDA層面,Tensor Comprehensions結合了affine loop transformations,fusion/fission和自動并行處理,同時確保數據在存儲器層次結構中正確移動。
圖中的數字表示最初計算張量元素的順序,箭頭表示它們之間的依賴關系。在這個例子中,數字旋轉對應loop interchange,深度算子融合就發生在這個過程中。
性能媲美乃至超越Caffe2+cuBLAS
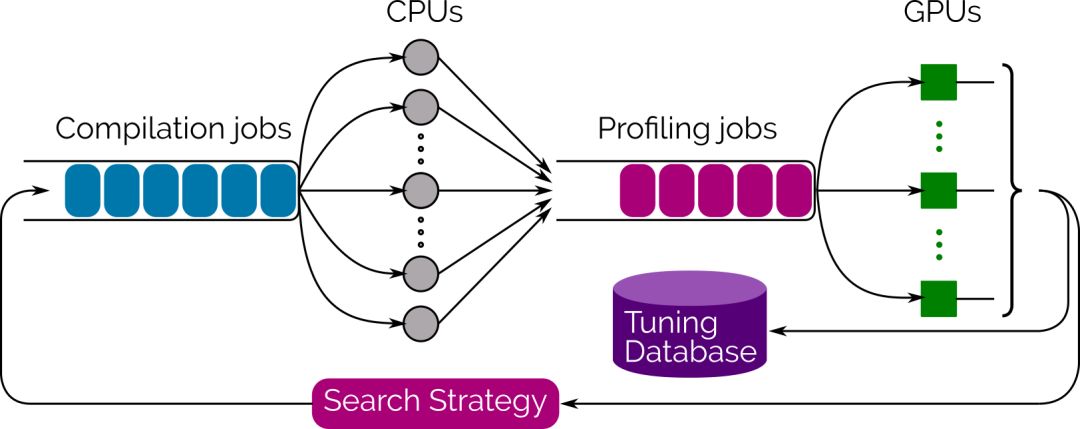
為了推動搜索過程,我們還提供了一個集成的多線程、多GPU自動調諧庫(autotuning library),它使用Evolutionary Search來生成和評估數千種實現方案,并從中選擇性能最佳的方案。只需調用Tensor Comprehension的tune函數,你就能實時地看著性能提高,到你滿意時停止即可。最好的策略是通過protobuf序列化,立即就可重用,或在離線情況下。
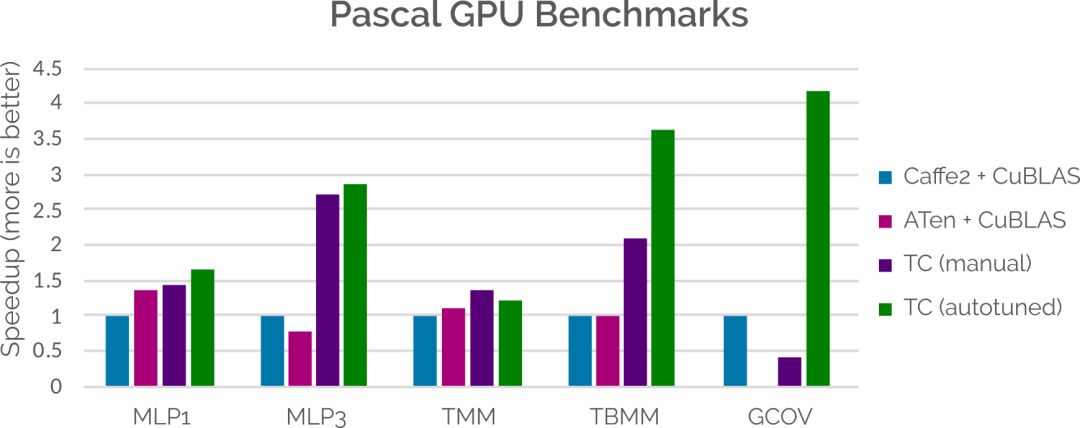
在性能方面,盡管我們還有很多需要改進的地方,但在某些情況下,Tensor Comprehensions 已經可以媲美甚至超越當前整合了手動調整庫的ML框架。這主要通過將代碼生成策略適應特定問題大小的能力來實現的。下面的條形圖展示了將Tensor Comprehensions自動生成的內核與Caffe2和ATen(使用CuDNN)相比較時的結果。更多信息,請參閱論文(見文末鏈接)。
隨著我們擴大至更多硬件后端,Tensor Comprehensions將補充硬件制造商(如NVIDIA和Intel)編寫的速度很快的庫,并將與CUDNN,MKL或NNPack等庫一起使用。
未來計劃
這次發布的版本將讓研究人員和程序員用與他們在論文中使用的數學語言來編寫網絡層,并簡明地傳達他們程序的意圖。同時,研究人員還能在幾分鐘之內將他們的數學符號轉化成能夠快速實施的代碼。隨著工具鏈的不斷增長,我們預計可用性和性能將會增加,并使整個社區受益。
我們將在稍后發布PyTorch的Tensor Comprehensions集成。
我們感謝與框架團隊的頻繁交流和反饋,并期待著將這一令人興奮的新技術帶入你最喜愛的ML框架。
FAIR致力于開放科學并與機器學習社區合作,進一步推動AI研究。Tensor Comprehensions(已經在Apache 2.0協議下發布)已經是Facebook,Inria,蘇黎世聯邦理工學院和麻省理工學院的合作項目。目前工作還處于早期階段,我們很高興能夠盡早分享,并期望通過社區的反饋來改進它。
-
機器人
+關注
關注
213文章
29728瀏覽量
212820 -
AI
+關注
關注
88文章
35099瀏覽量
279539 -
代碼
+關注
關注
30文章
4900瀏覽量
70704
原文標題:【AI大紅包】Facebook發布張量理解庫,幾分鐘自動生成ML代碼
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
高性能計算集群在AI領域的應用前景

芯原可擴展的高性能GPGPU-AI計算IP賦能汽車與邊緣服務器AI解決方案
開售RK3576 高性能人工智能主板
Synaptics發布高性能AI MCU,推動邊緣計算新突破

Banana Pi 發布 BPI-AI2N & BPI-AI2N Carrier,助力 AI 計算與嵌入式開發
Banana Pi 發布 BPI-AI2N & BPI-AI2N Carrier,助力 AI 計算與嵌入式開發

MediaTek發布全新高性能邊緣AI物聯網芯片
賽昉聯合國芯推出高性能AI MCU芯片,實現RISC-V+AI新應用






 工商網監
工商網監
評論