 KORTIQ公司推出了一款Xilinx FPGA的CNN加速器IP——AIScale
KORTIQ公司推出了一款Xilinx FPGA的CNN加速器IP——AIScale
隨著人工智能(AI)的不斷發展,它已經從早期的人工特征工程進化到現在可以從海量數據中學習,機器視覺、語音識別以及自然語言處理等領域都取得了重大突破。CNN(Convolutional Neural Network,卷積神經網絡)在人工智能領域受到越來越多的青睞,它是深度學習技術中極具代表性的網絡結構之一,尤其在圖像處理領域取得了很大的成功。隨著網絡變得越來越大、越來越復雜,我們需要大量的計算資源來對其進行訓練,因此人們紛紛將注意力轉向FPGA(Field Programmable Gate Array,現場可編程門陣列)器件,FPGA不僅具有軟件的可編程性和靈活性,同時又有ASIC高吞吐和低延遲的特性,而且由于具有豐富的I/O接口,FPGA還非常適合用作協議和接口轉換的芯片。
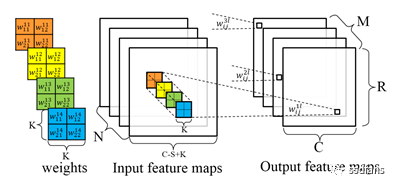
近日KORTIQ公司推出了一款Xilinx FPGA的CNN加速器IP——AIScale,它能夠利用實現訓練好的CNN網絡,比如行業標準的ResNet、AlexNet、Tiny Yolo和VGG-16等,并將它們進行壓縮輸出二進制描述文件,可以部署到Xilinx全系列可編程邏輯器件上。Zynq SoC和Zynq UltraScale+ MPSoC器件PS可以提供數據給AIScale CNN加速器(PL),經過分類處理將輸出數據給PS。壓縮后的CNN網絡占用資源相對小很多,可以部署在片上存儲器中,可以更快更靈活的切換CNN網絡。
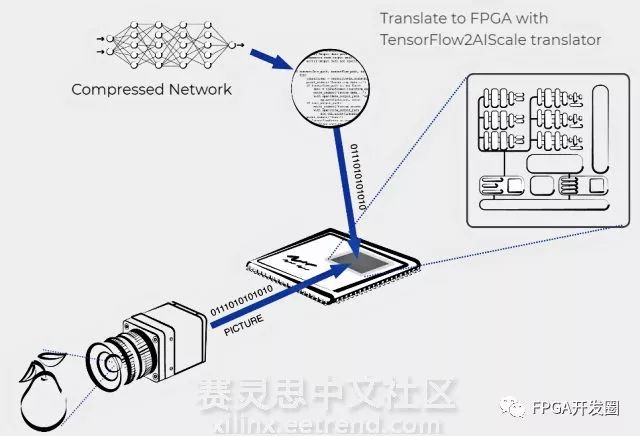
圖1:AIScale在計算機視覺應用案例示意圖
AIScale加速器的核心是AIScale RCC(Re-configurable Compute Core),用戶根據需求可以靈活自定義AIScale RCC模塊的數量,AIScale RCC支持卷積預處理、池化/采樣、加權和全連接層等處理。資源更豐富的Zynq SoC和UltraScale+ MPSoC可以集成更多的AIScale RCC模塊,這會給AIScale加速器帶來更大的性能提升。當然也可以根據成本、系統功耗、性能需求集成一定的AIScale RCC模塊,選擇合適的Xilinx FPGA器件。
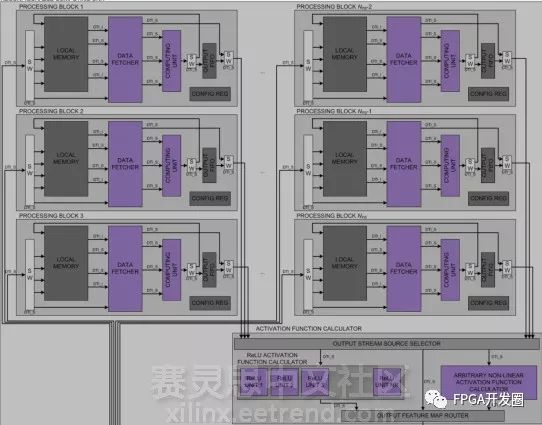
圖2:多個 AIScale RCC模塊級聯連接
KORTIQ公司目前專注于嵌入式和計算機視覺領域,設計工業4.0和物聯網(IoT)等,未來將會為AIScale CNN加速器提供更多更先進的特性,比如圖像分類、物體識別和追蹤、人臉和語音識別、自然語言處理等,將先進的人工智能網絡應用到自動化生產、控制等場景中,提高相關行業的生產力為用戶帶來更好的服務。
-
FPGA
+關注
關注
1643文章
21954瀏覽量
613901 -
Xilinx
+關注
關注
73文章
2181瀏覽量
124312 -
IP
+關注
關注
5文章
1779瀏覽量
151262 -
cnn
+關注
關注
3文章
354瀏覽量
22626
原文標題:介紹一款基于FPGA的CNN硬件加速器IP
文章出處:【微信號:FPGA-EETrend,微信公眾號:FPGA開發圈】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
數據中心加速器就看GRVI Phalanx FPGA加速器
機器學習實戰:GNN加速器的FPGA解決方案
一款低端14 MHz加速器Spitfire 500
使用AMD-Xilinx FPGA設計一個AI加速器通道
高級語言(HLL)標準擴展大大簡化基于FPGA加速器的應用程序的開發
基于FPGA的通用CNN加速設計

優化基于FPGA的深度卷積神經網絡的加速器設計
基于Xilinx 28nmFPGA的Dragen加速器板卡用于基因組分析算法的加速的解析
一款Xilinx FPGA的CNN加速器IP—AIScale
基于Xilinx FPGA的Memcached硬件加速器的介紹
Kortiq小巧高效的CNN加速器,支持所有類型
Achronix和BittWare推出采用FPGA芯片的加速卡
如何采用帶專用CNN加速器的AI微控制器實現CNN的硬件轉換
基于FPGA的深度學習CNN加速器設計方案





 工商網監
工商網監
評論