 BFF層聚合查詢服務異步改造及治理實踐
BFF層聚合查詢服務異步改造及治理實踐

首先感謝王曉老師的[接口優化的常見方案實戰總結]一文總結,恰巧最近在對穩健理財BFF層聚合查詢服務優化治理,針對文章內的串行改并行章節進行展開,分享下實踐經驗,主要涉及原同步改異步的過程、全異步化后衍生的問題以及治理方面的思考與改進。 希望通過分享這些經驗,能夠對大家的工作有所啟發和幫助。如果有任何問題或建議,請隨時提出。 感謝大家的關注和支持!
一、問題背景
將不同理財產品(如基金、券商、保險、銀行理財等)針對不同投放渠道人群進行個性化商品推薦,每個渠道或人群看到的商品或特性數據又各不相同,為方便渠道快速對接,由BFF層統一對所有數據進行聚合下發,因此BFF層聚集依賴了大量底層原子服務,所以主要問題是在依賴大量上游接口的場景下保障TP99、以及可用率。
案例:
以其中比較典型的商品推薦接口為例,需要依賴本地商品池緩存、算法推薦服務、商品基礎信息服務、持倉查詢服務、人群標簽服務、券配置服務,可領用券服務、其他數據服務ServN……等等,其中大部分上游原子接口對單次批量查詢支持有限,所以極端情況,單個推品接口單次推薦1-n個推品,每個商品如果要綁定10個動態屬性,至少需要發起(1~n)*10次io調用。
改造前的流程和問題:
流程:
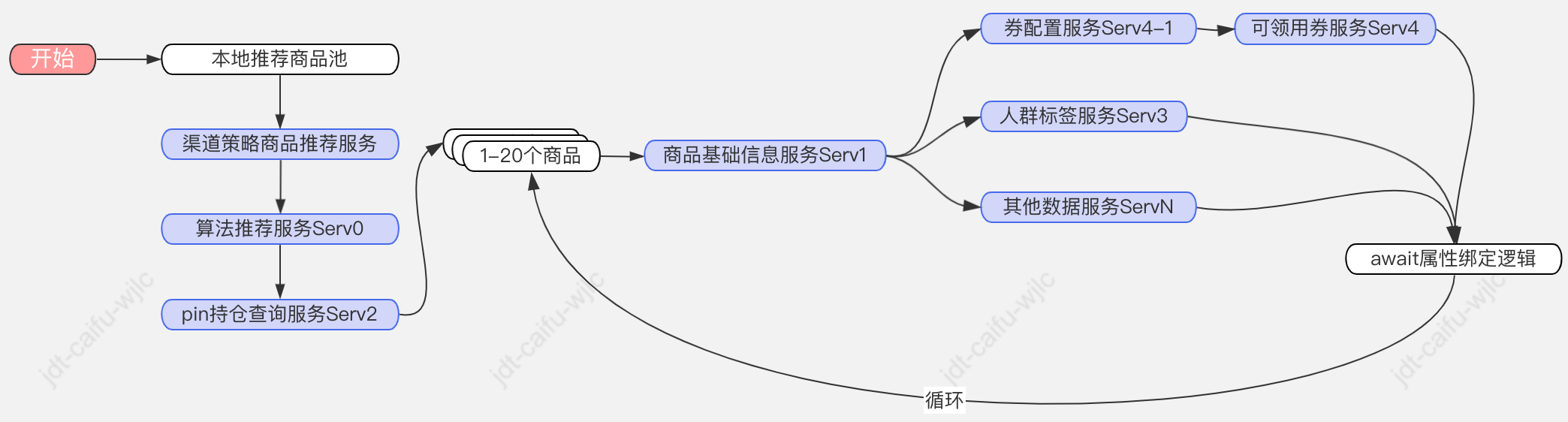
問題:
?一是邏輯流程強耦合,很多上下游服務強同步依賴;
?二是鏈路較長,其中某個上游服務不穩定時很容易造成整體鏈路失敗。
改造后的流程和實現的目標:
流程:
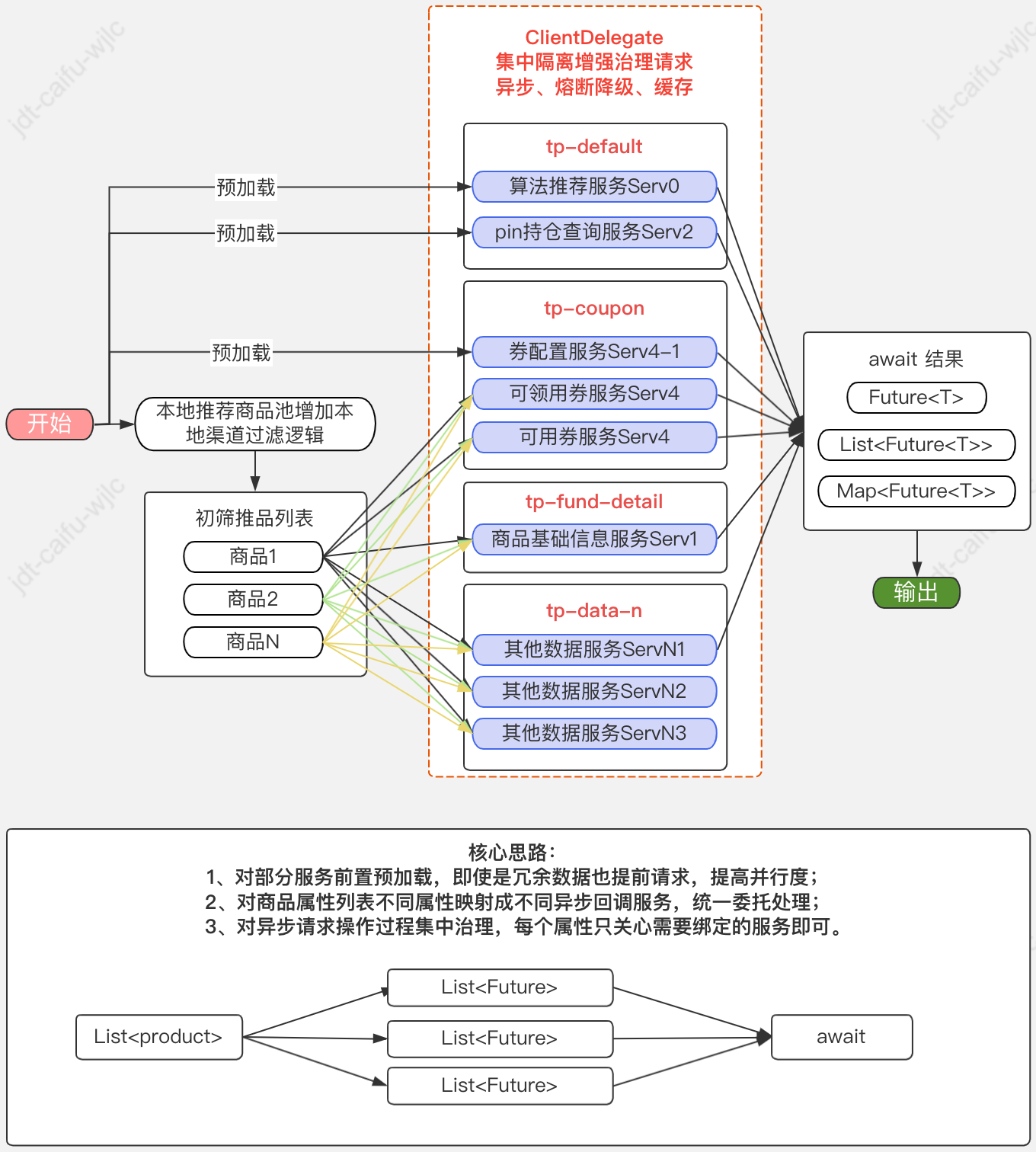
目標:
?改造目標也很明確,就是對現有邏輯改造,盡可能增加弱依賴比例,一是方便異步提前加載,二是弱依賴代表可摘除,為降級操作奠定基礎,減少因某個鏈路抖動影響整體鏈路失敗;
初步改造后的新問題【【重點解決】】:
?邏輯上解耦比較簡單,無非就是前置參數或冗余加載,本次不展開探討;
?技術上改造前期異步邏輯主要是采用@Async("tpXXX")標注,這也是最快捷實現的方式,但也存在以下幾個問題,主要是涉及治理方面:
1. 隨著項目和人員不斷迭代,造成@Async注解滿天飛;
2. 不同人員在不熟悉其他模塊的情況下,無法界定不同線程池的是否可公用,大多都會采用聲明新的線程池,造成線程池資源泛濫;
3. 部分調用場景不合理造成@Async嵌套過多或注解失效問題;
4. 降級機制重復代碼太多,需要頻繁手動聲明各種降級開關;
5. 缺少統一的請求級別的緩存機制,雖然jsf已經提供了一定程度的支持;
6. 線程池上下文傳遞問題;
7. 缺少線程池狀態的統一監控報警,無法觀測實際運行過程中的每個線程池狀態,可能每次都是拍腦袋覺設置線程池參數。
二、整體改造路徑
切入點:
鑒于大部分項目都會封裝單獨的io調用層,比如 com.xx.package.xxx.client,所以以此為切入點進行重點改造治理。
最終目標:
實現、應用簡單,對老代碼改造友好,盡可能降低改造成本;
1. 抽象io調用模板,統一io調用層封裝規范,標準化io調用需要的增強屬性聲明并提供默認配置,如所屬線程池分配、超時、緩存、熔斷、降級等;
2. 優化@Async調用,所有io異步操作統一收縮至io調用層,在模板層實現回調機制,老代碼僅繼承模板即可實現異步回調;
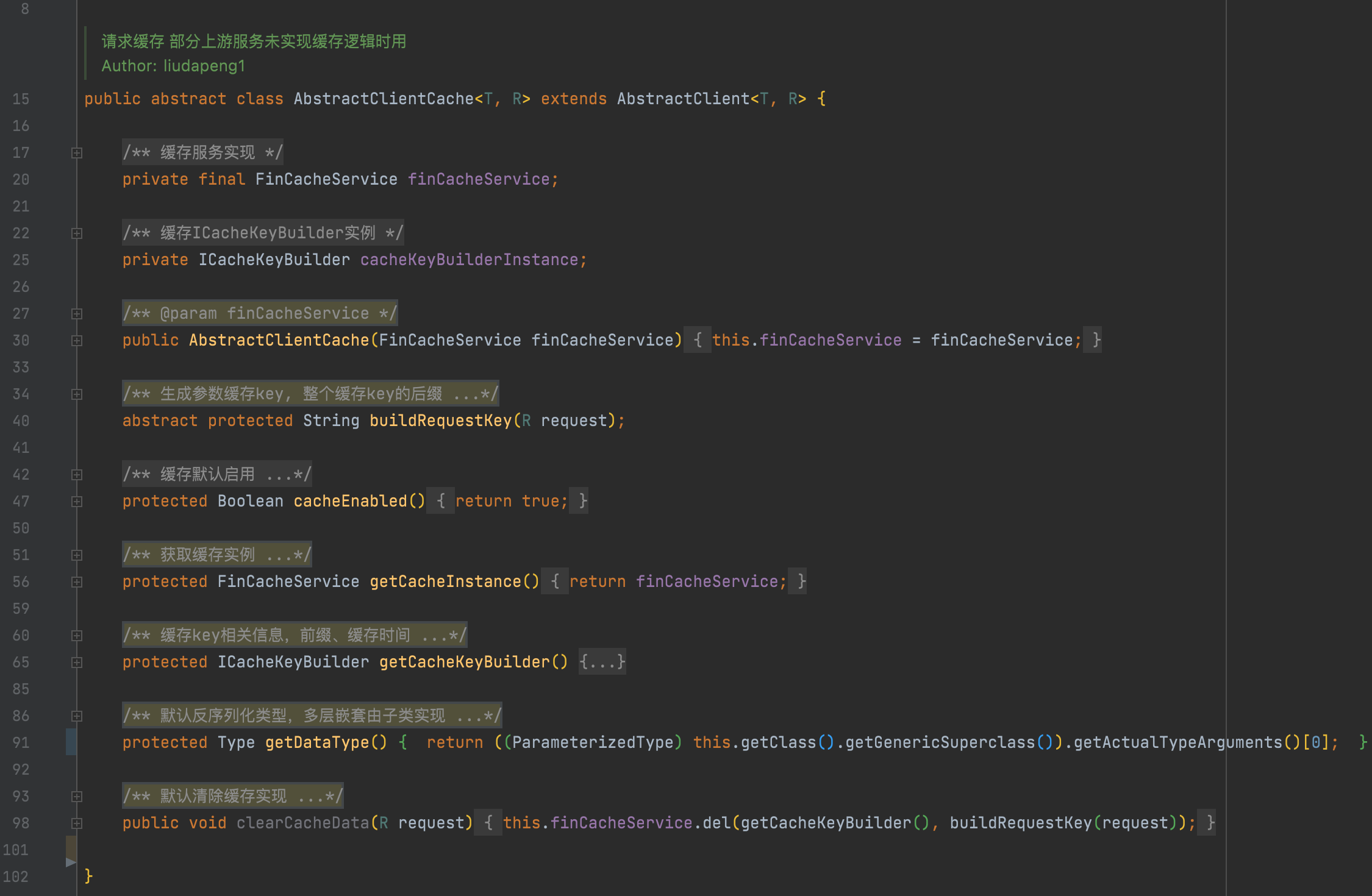
3. 請求級別的緩存實現,默認支持r2m;
4. 請求級別的熔斷降級支持,在上游故障時使服務實現一定程度的自治理;
5. 線程池集中管理,對上下文自動傳遞MDC參數提供支持;
6. 線程池狀態自動可視化監控、報警實現;
7. 支持配置中心動態設置。
具體實現:
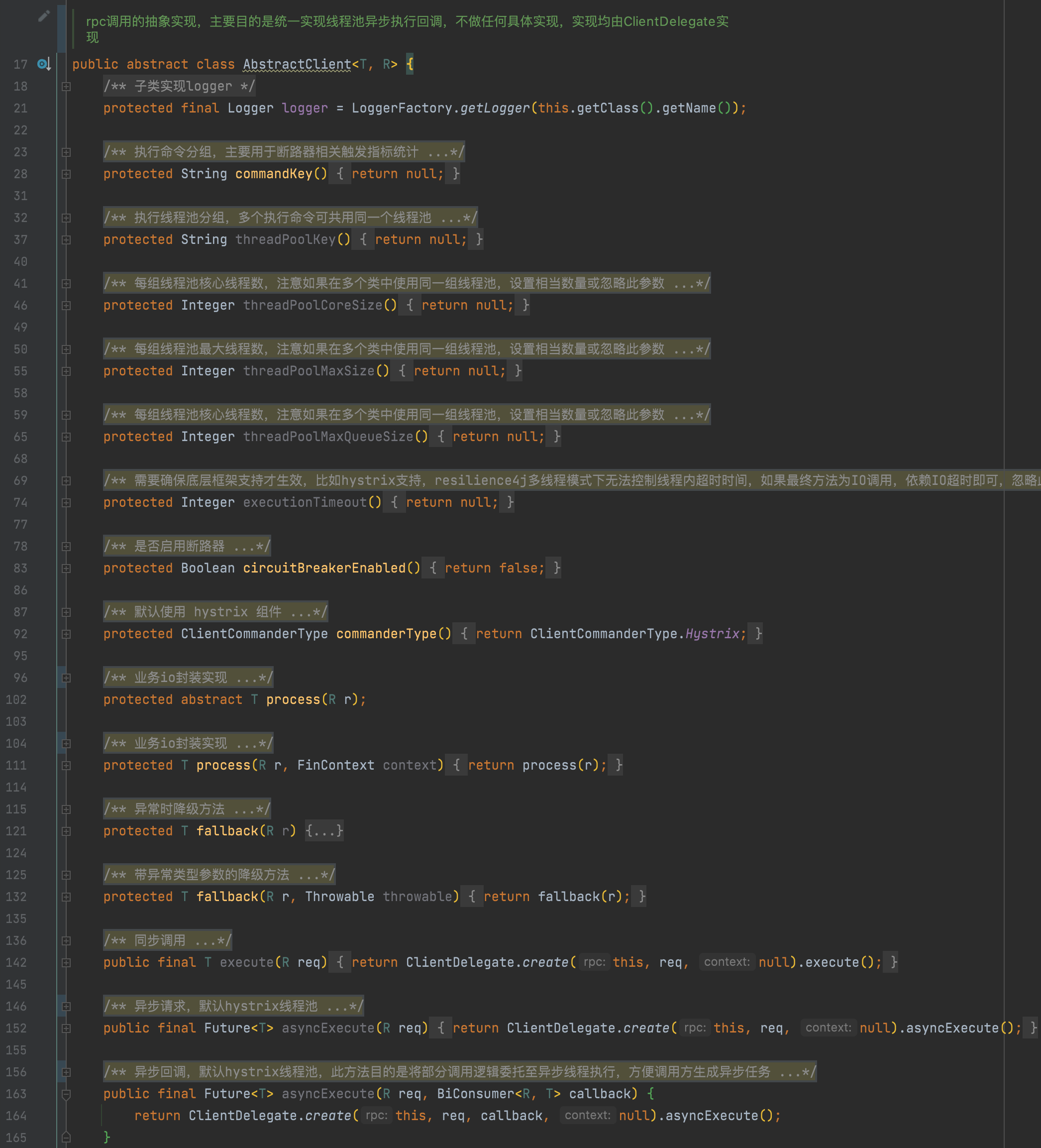
1. io調用抽象模板
模板主要作用是進行規范和增強,目前提供兩種模板,默認模板、緩存模板,核心思想就是對io操作涉及的大部分行為進行聲明,比如當前服務所屬線程池分組、請求分組等,由委托組件按照聲明的屬性進行增強實現,示例如下:
主要是提供代碼級別的默認聲明,從日常實踐看大部分采用開發時的代碼級別的配置即可。
?.
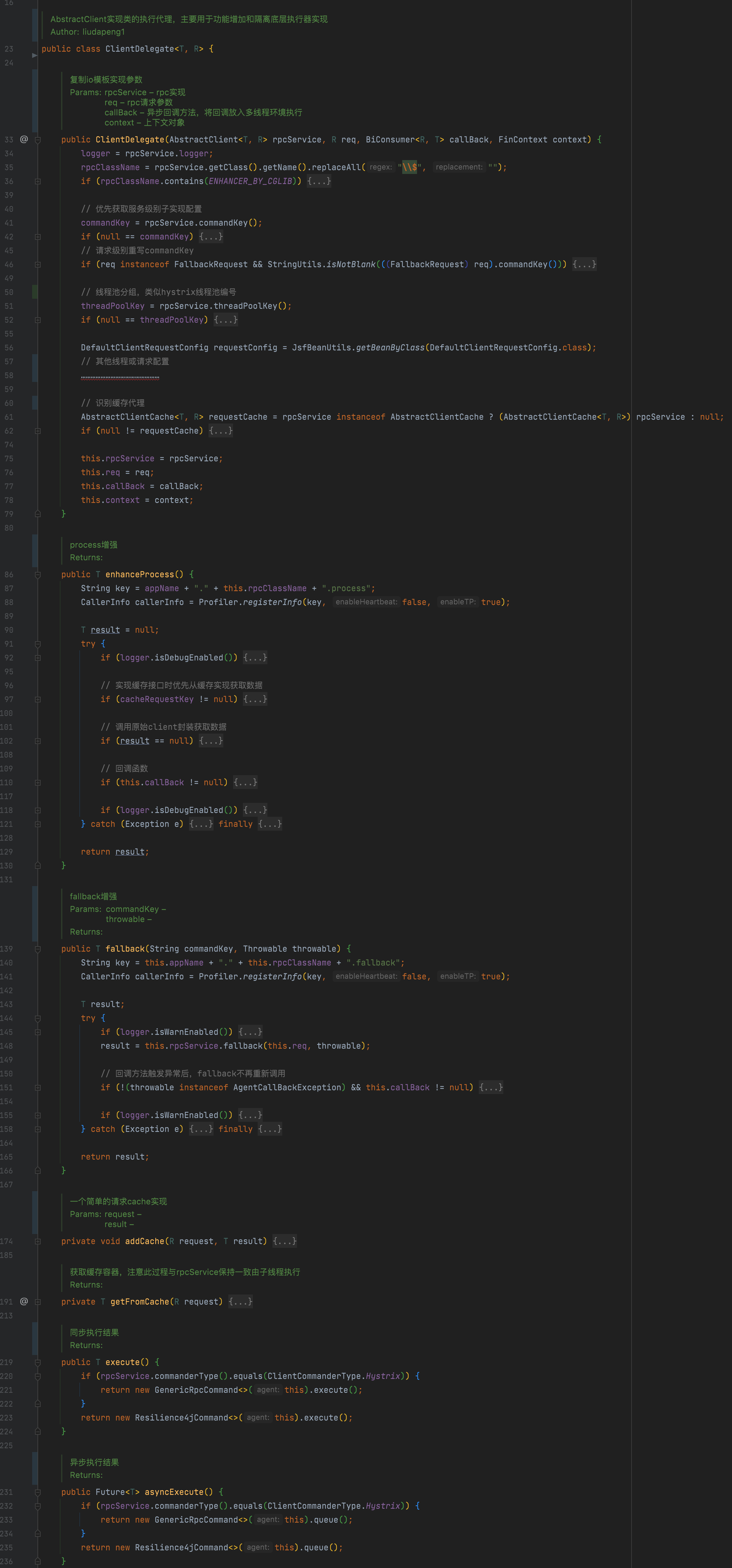
2. 委托代理
此委托屬于整個執行過程的橋接實現,io封裝實現繼承抽象模板后,由模板創建委托代理實例,主要用于對io封裝進行增強實現,比如調用前、調用后、以及調用失敗自動調用聲明的降級方法等處理。
可以理解為:模板專注請求行為,委托關注對象行為進行組合增強。
3. 執行器選型
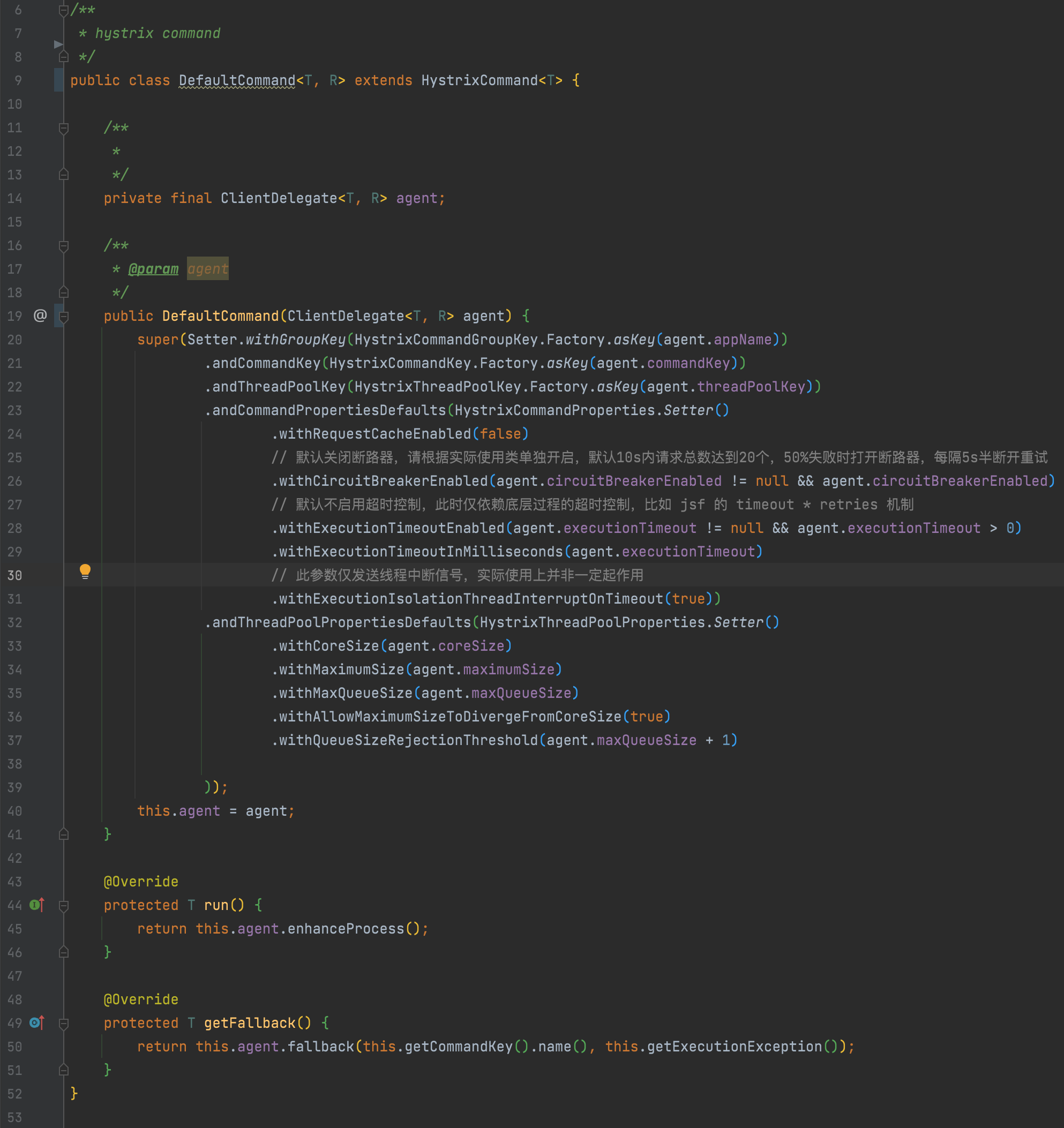
基于前面的實現目標,減少自研成本,調研目前已有框架,如 hystrix、sentinel、resilience4j,由于主要目的是期望支持線程池級別的壁艙模式實現,且hystrix集成度要優于resilience4j,最終選型默認集成hystrix,備選resilience4j, 以此實現線程池的動態創建管理、熔斷降級、半連接重試等機制,HystrixCommander實現如下:
4. hystrix 適配 concrete 動態配置
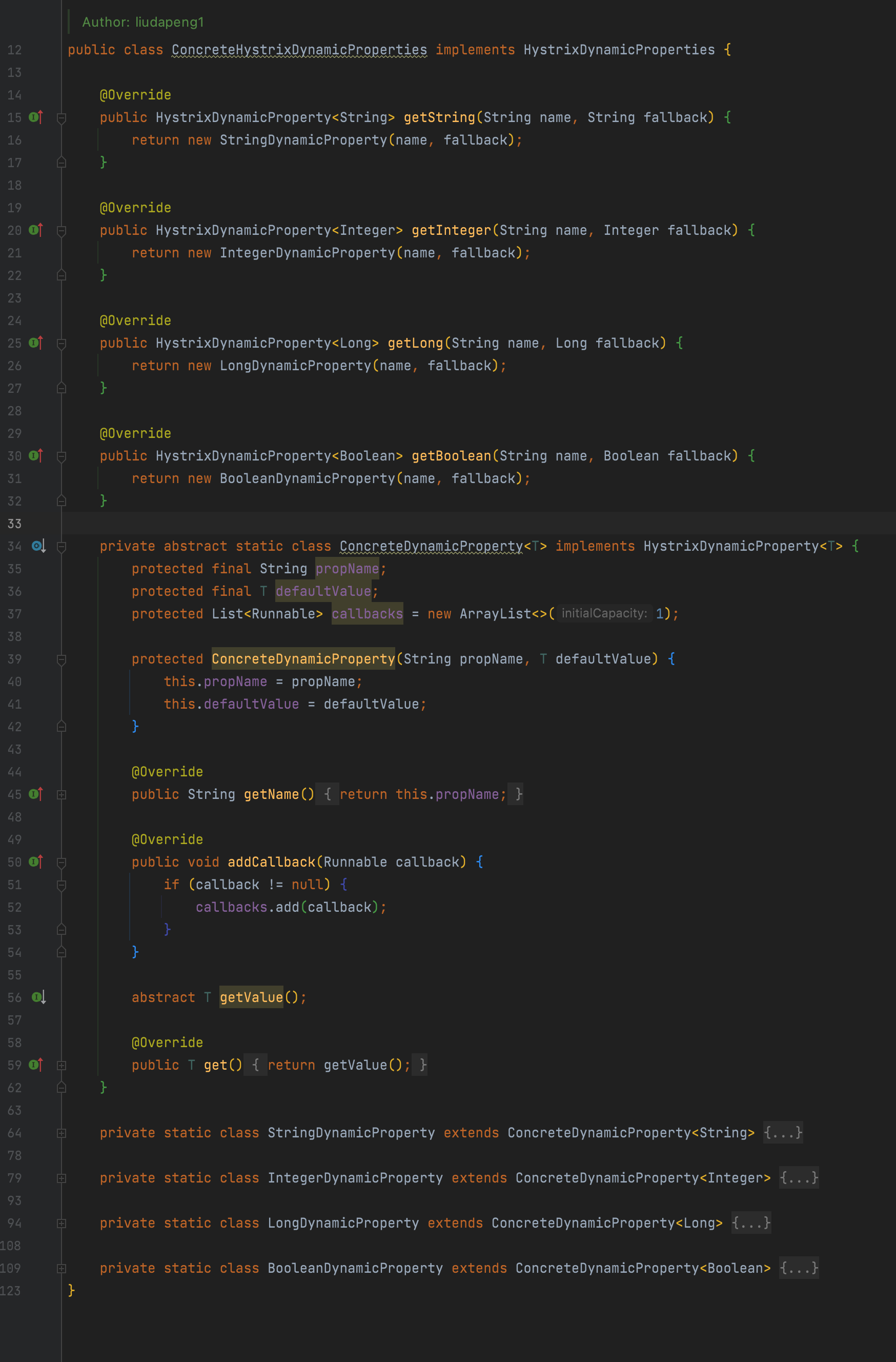
1、繼承concrete.PropertiesNotifier, 注冊HystrixPropertiesNotifier監聽器,緩存配置中心所有以hystrix起始的key配置;
2、實現HystrixDynamicProperties,注冊ConcreteHystrixDynamicProperties替換默認實現,最終支持所有的hystrix配置項,具體用法參考hystrix文檔。
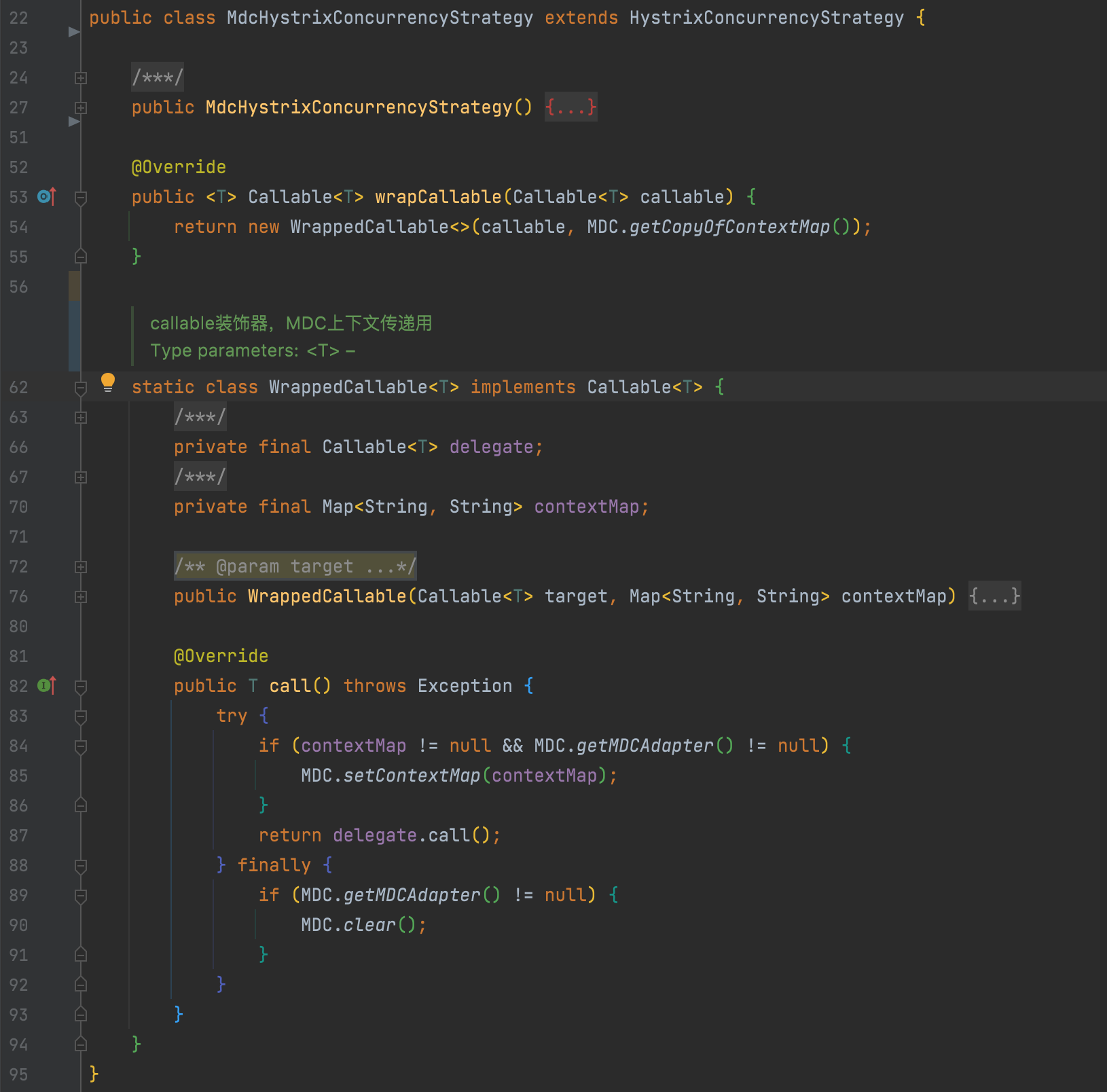
5. hystrix 線程池上下文傳遞改造
hystrix已經提供了改造點,主要是對HystrixConcurrencyStrategy#wrapCallable方法重寫實現即可,在submit任務前暫存主線程上下文進行傳遞。
6. hystrix、jsf、spring注冊線程池狀態多維可視化監控、報警
主要依賴以下三個自定義組件,注冊一個狀態監控處理器,單獨啟動一個線程,定期(每秒)收集所有實現數據上報模板的實例,通過指定的通道實現狀態數據推送,目前默認使用PFinder上報:
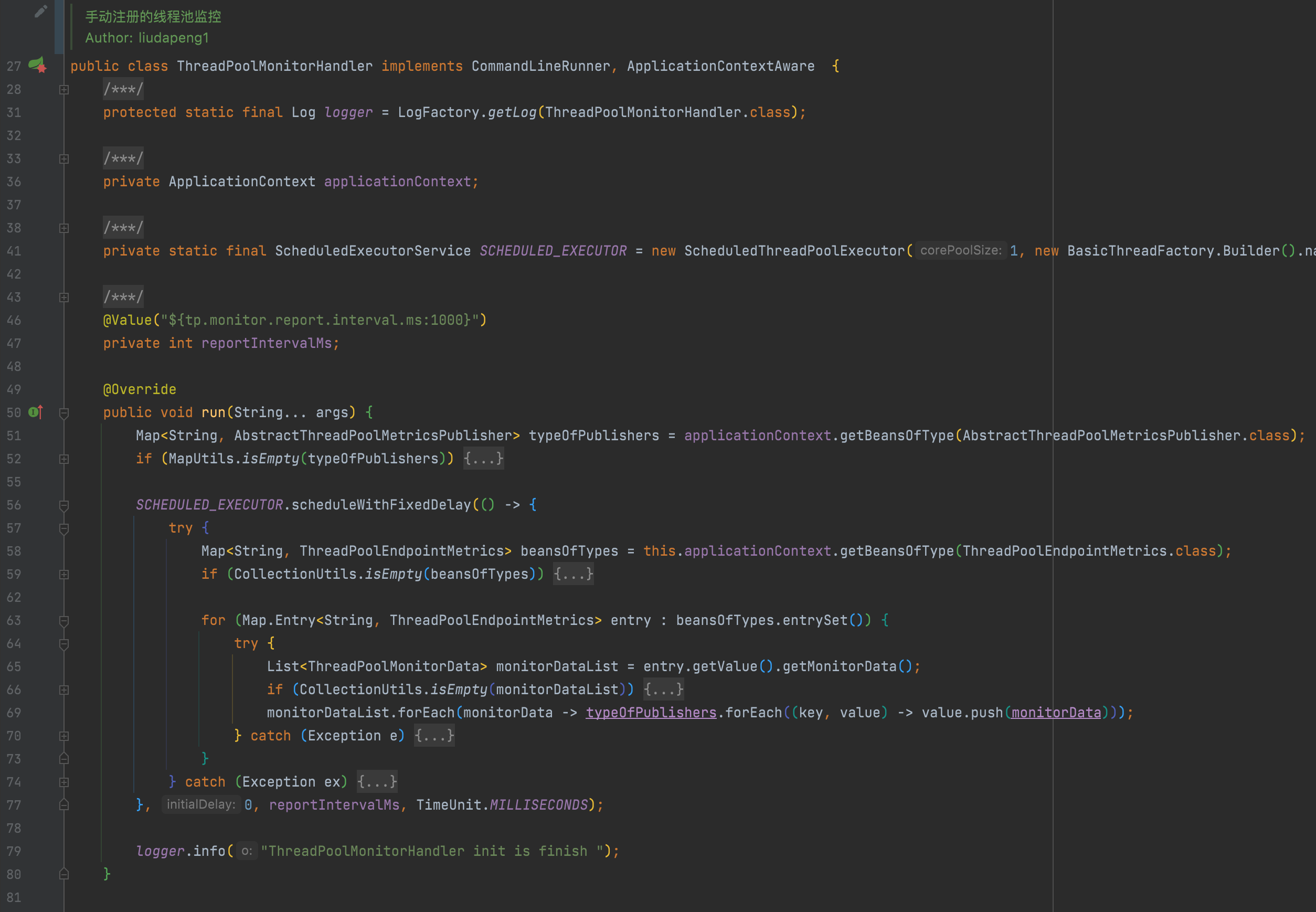
?ThreadPoolMonitorHandler 定義一個線程狀態監控處理器,定期執行上報過程;
?ThreadPoolEndpointMetrics 定義要上報的數據模板,包括應用實例、線程類型(spring、jsf、hystrix……)、類型線程分組、以及線程池的幾個核心參數;
?AbstractThreadPoolMetricsPublisher 定義監控處理器執行上報時依賴的通道(Micrometer、PFinder、UMP……)。
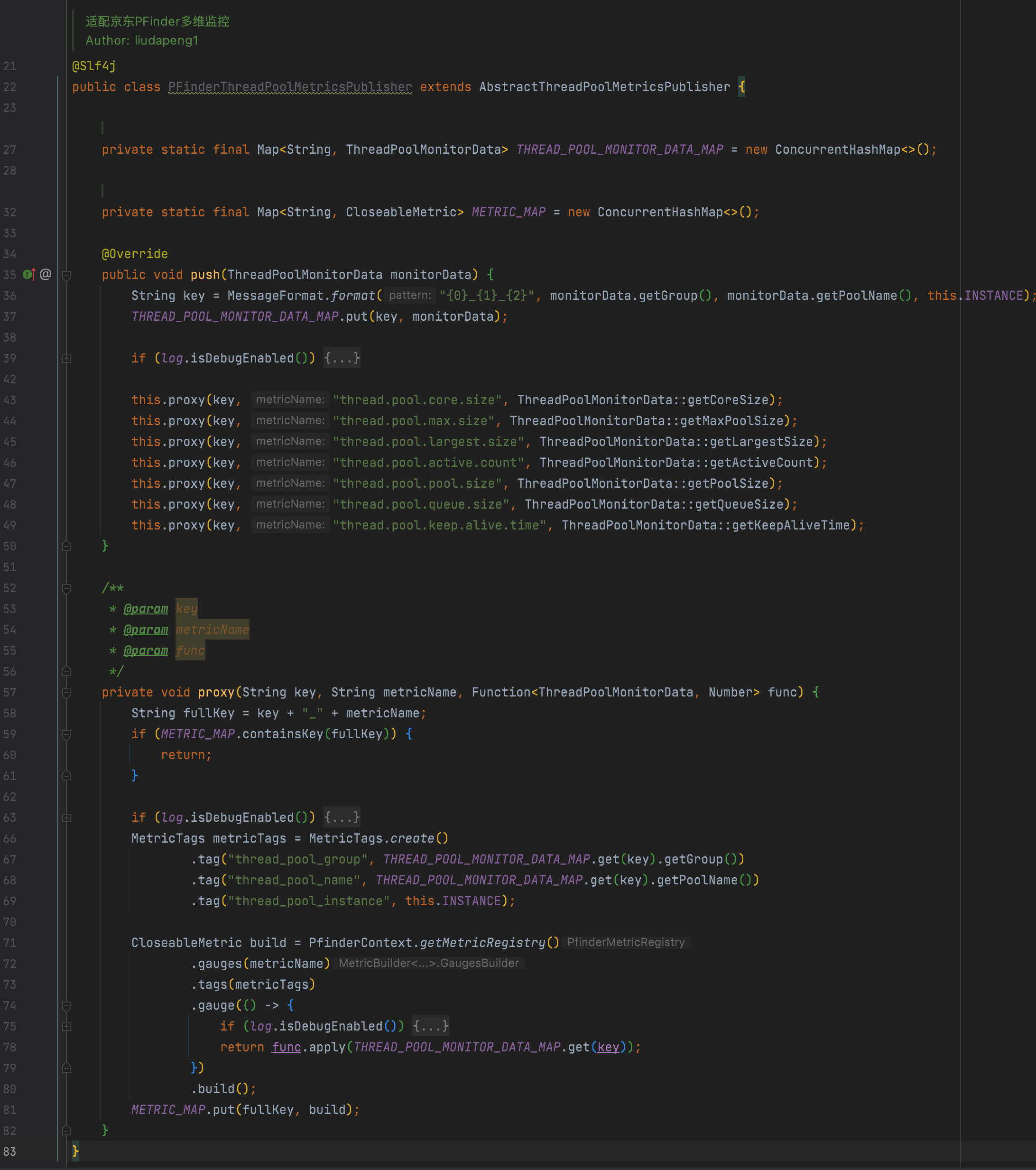
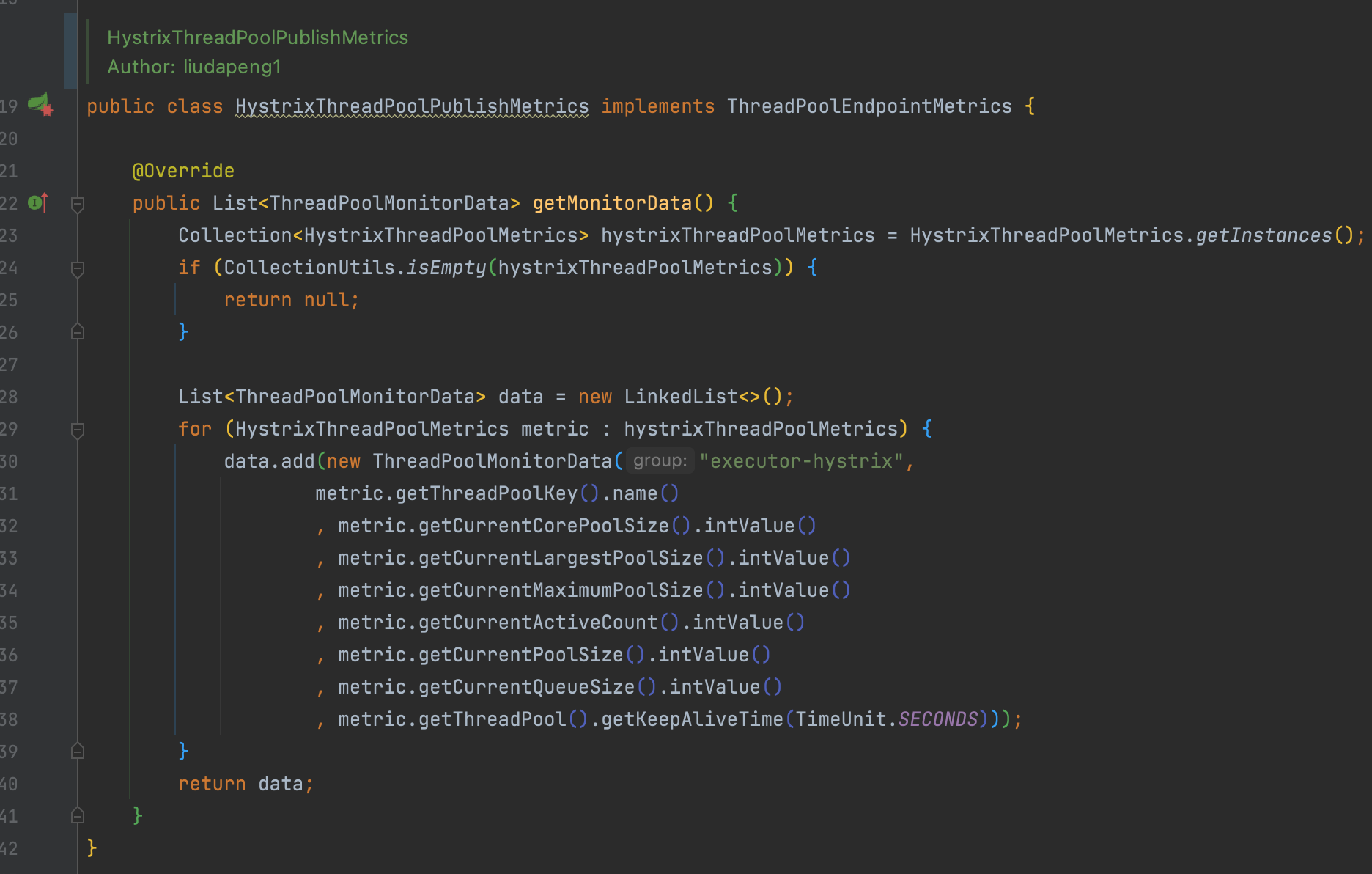
例如以下是hystrix的狀態收集實現,最終可實現基于機房、分組、實例、線程池類型、名稱等不同維度的狀態監控:
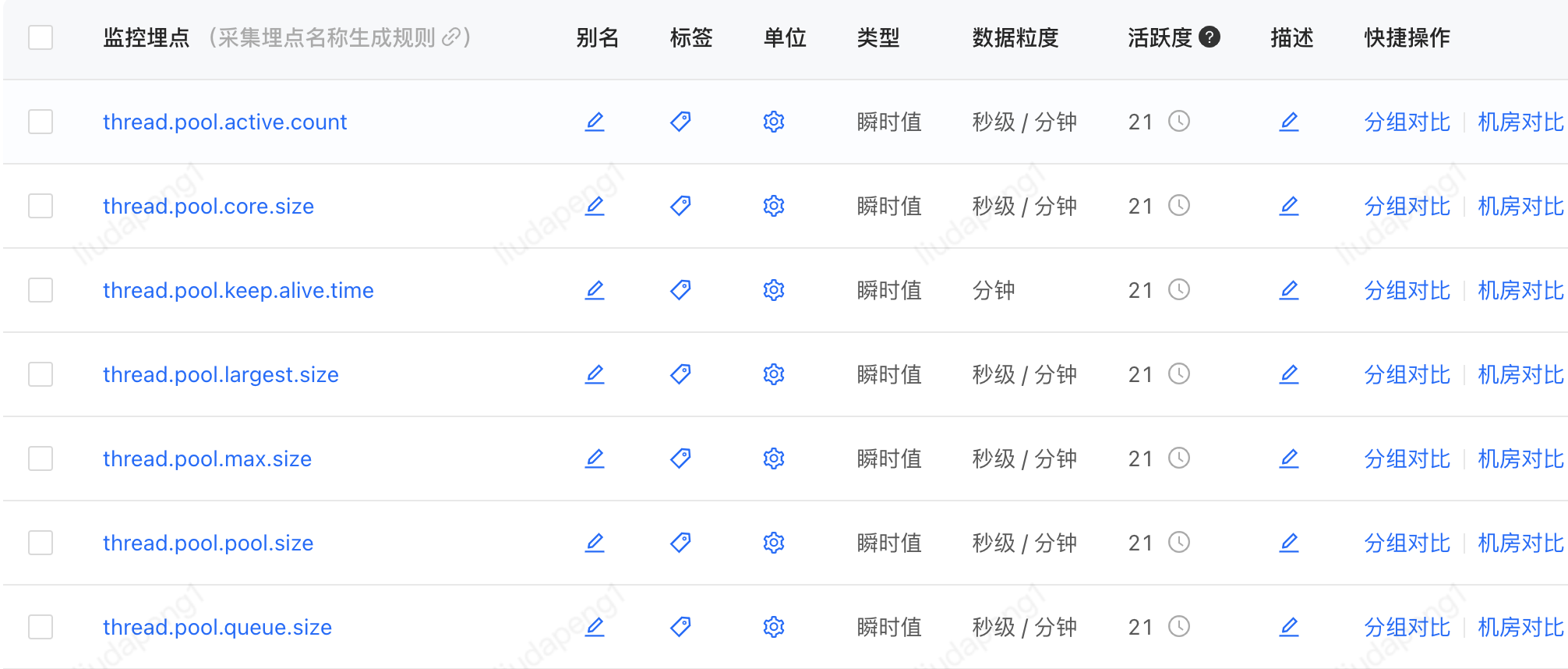
PFinder實際效果:支持不同維度組合查看及報警
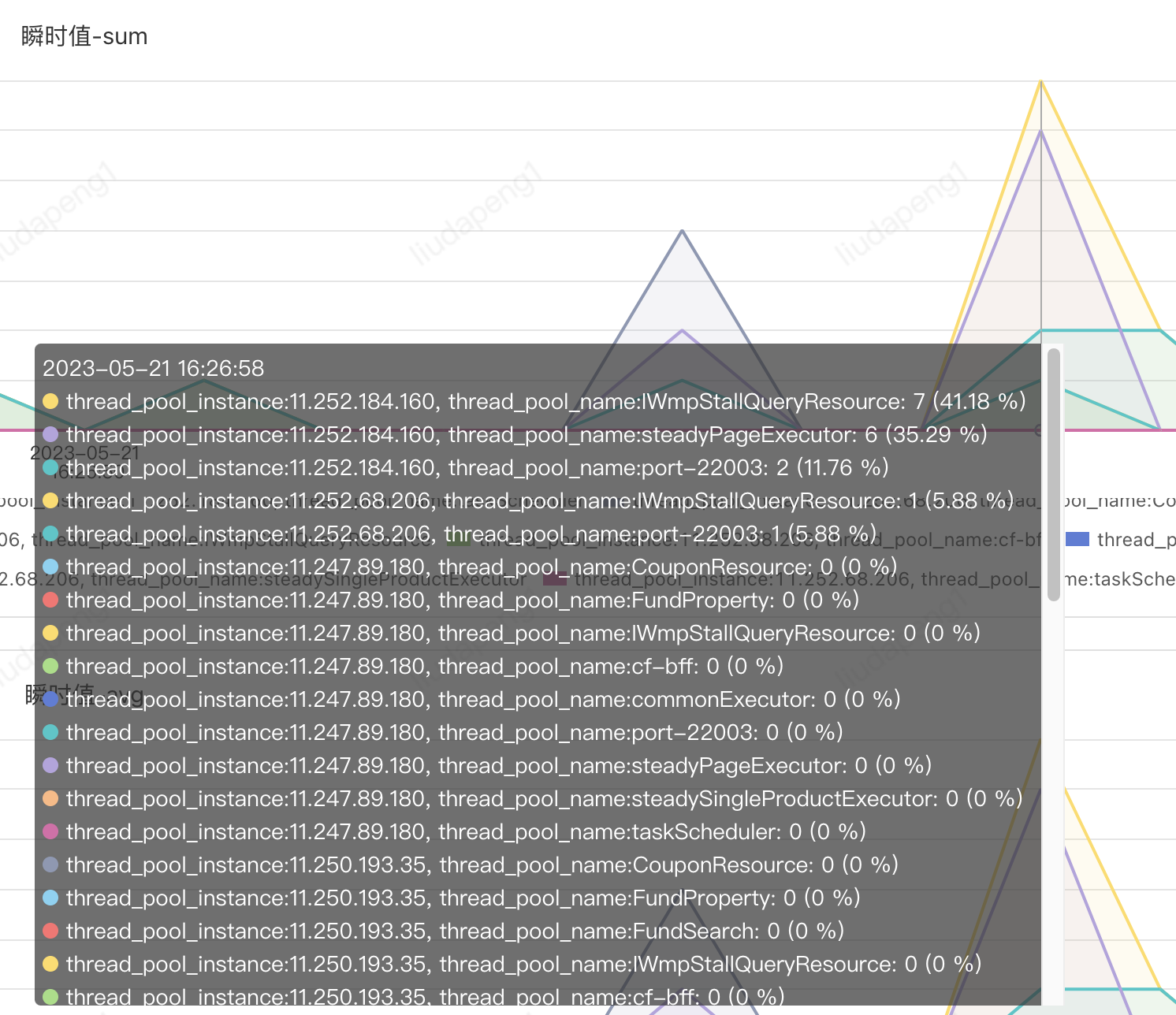
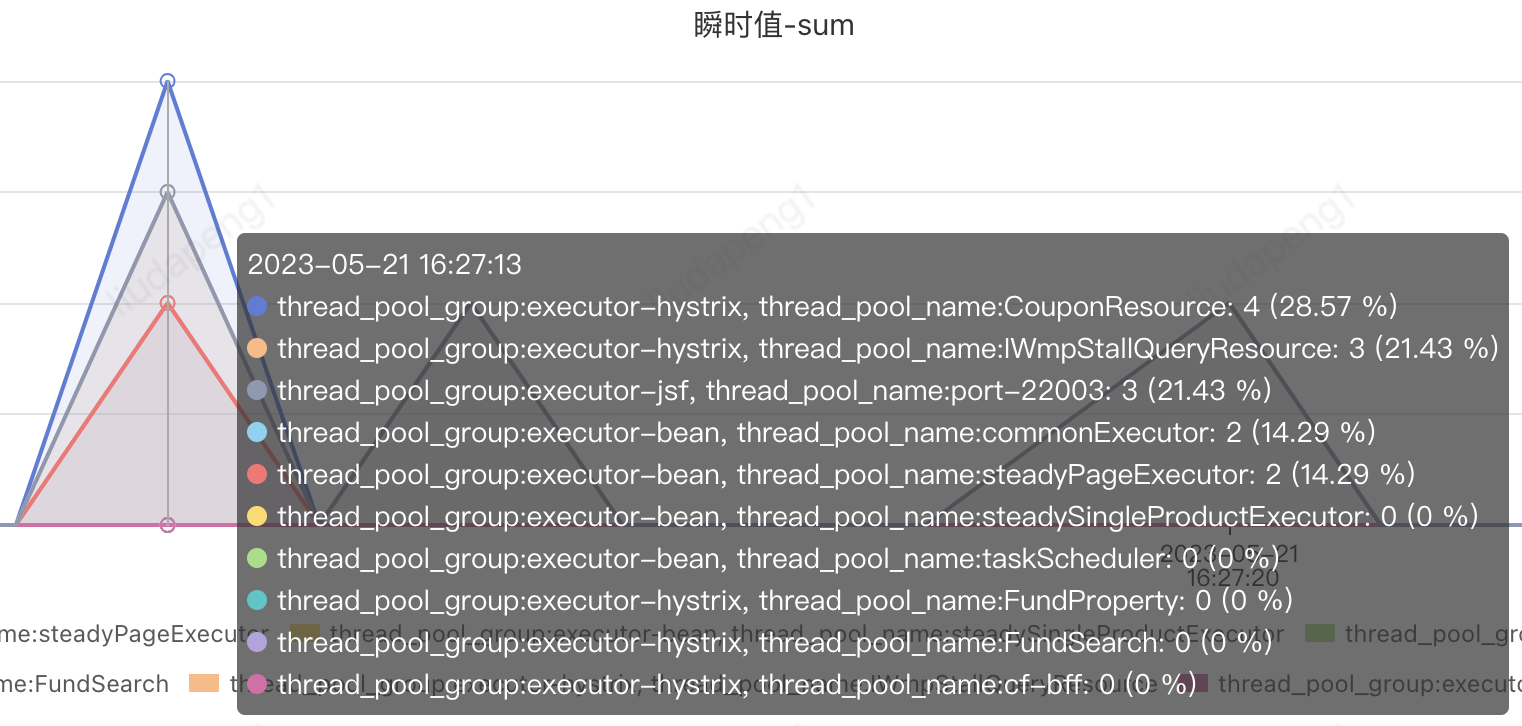
7. 提供統一await future工具類
由于大部分調用是基于列表形式的異步結果List>、Map>,并且hystrix目前暫不支持返回CompletableFuture,方便統一await,提供工具類:
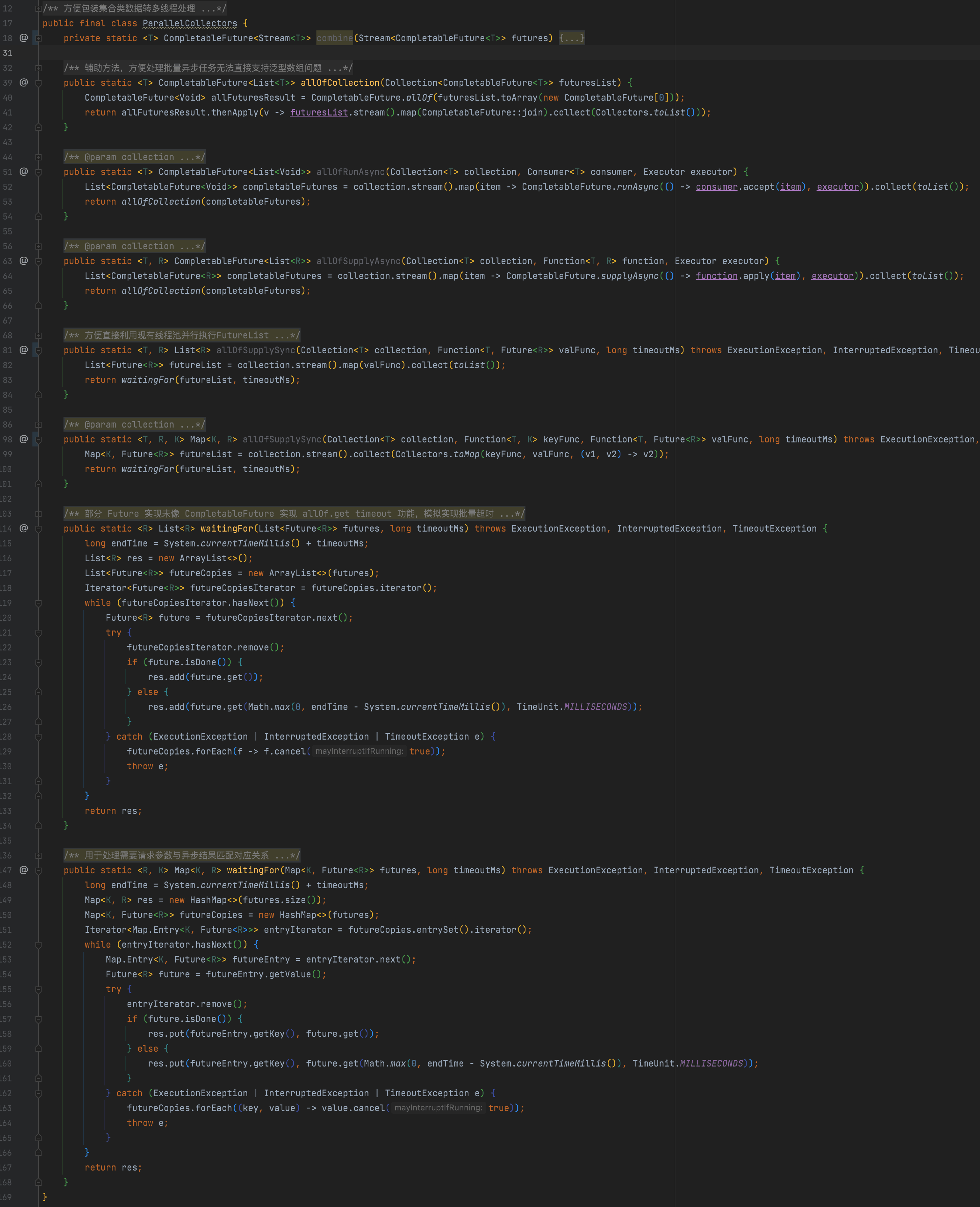
8. 其他小功能
1、除了sgm traceId支持,同時內置自定義的traceId實現,主要是處理sgm在子線程內打印traceId需要在控制臺手動添加監控方法的問題以及提供對部分無sgm環境的鏈路Id支持,方便日志跟蹤;
2、比如針對jsf調用,基于jsf過濾器實現跨應用級別的前后請求id傳遞支持;
3、默認增加jsf過濾器實現日志打印,同時支持provider、consume的動態日志打印開關,方便線上隨時開關jsf日志,不再需要在client層重復logger.isDebugerEnabled();
4、代理層自動上報io調用方法、fallback等信息至ump,方便監控報警。
日常使用示例:
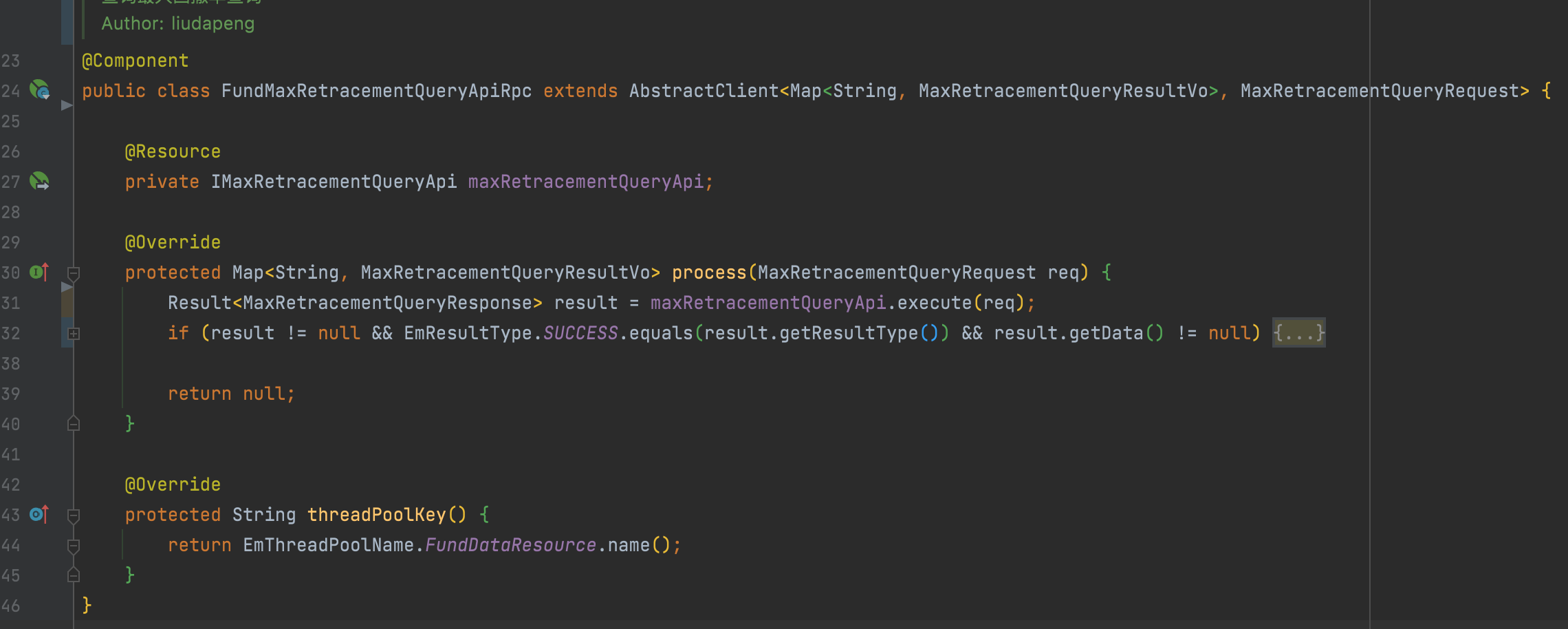
1. 一個最簡單的io調用封裝
僅增加繼承即可支持異步回調,不重寫線程池分組時使用默認分組。
2. 一個支持請求級別熔斷的io調用封裝
默認支持的熔斷級別是服務級別,老服務僅需要繼承原請求參數,實現FallbackRequest接口即可,可防止因為某一個特殊參數引起的整體接口熔斷。

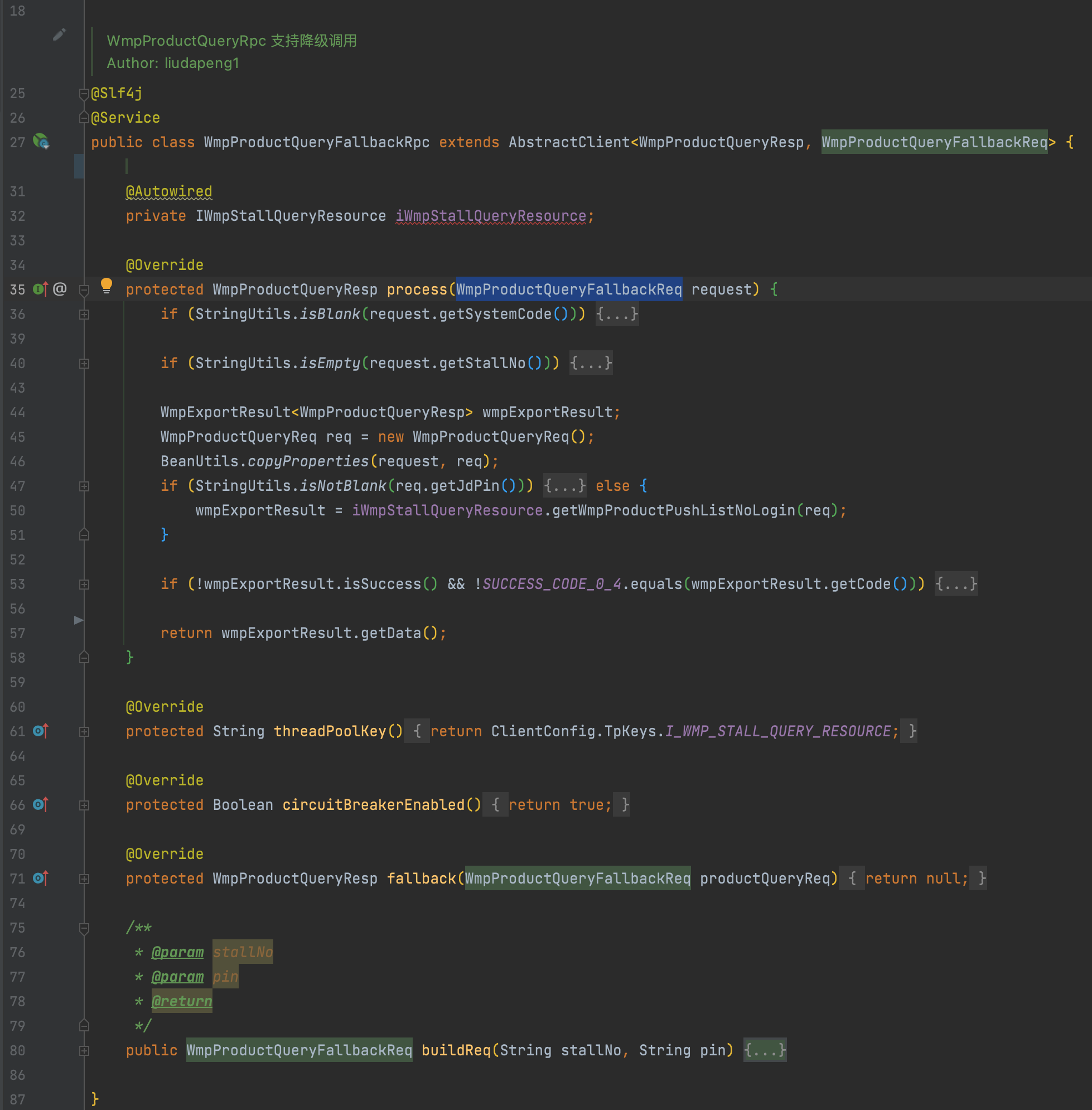
3. 一個支持請求級別緩存、接口級別熔斷降級、獨立線程池的io調用封裝
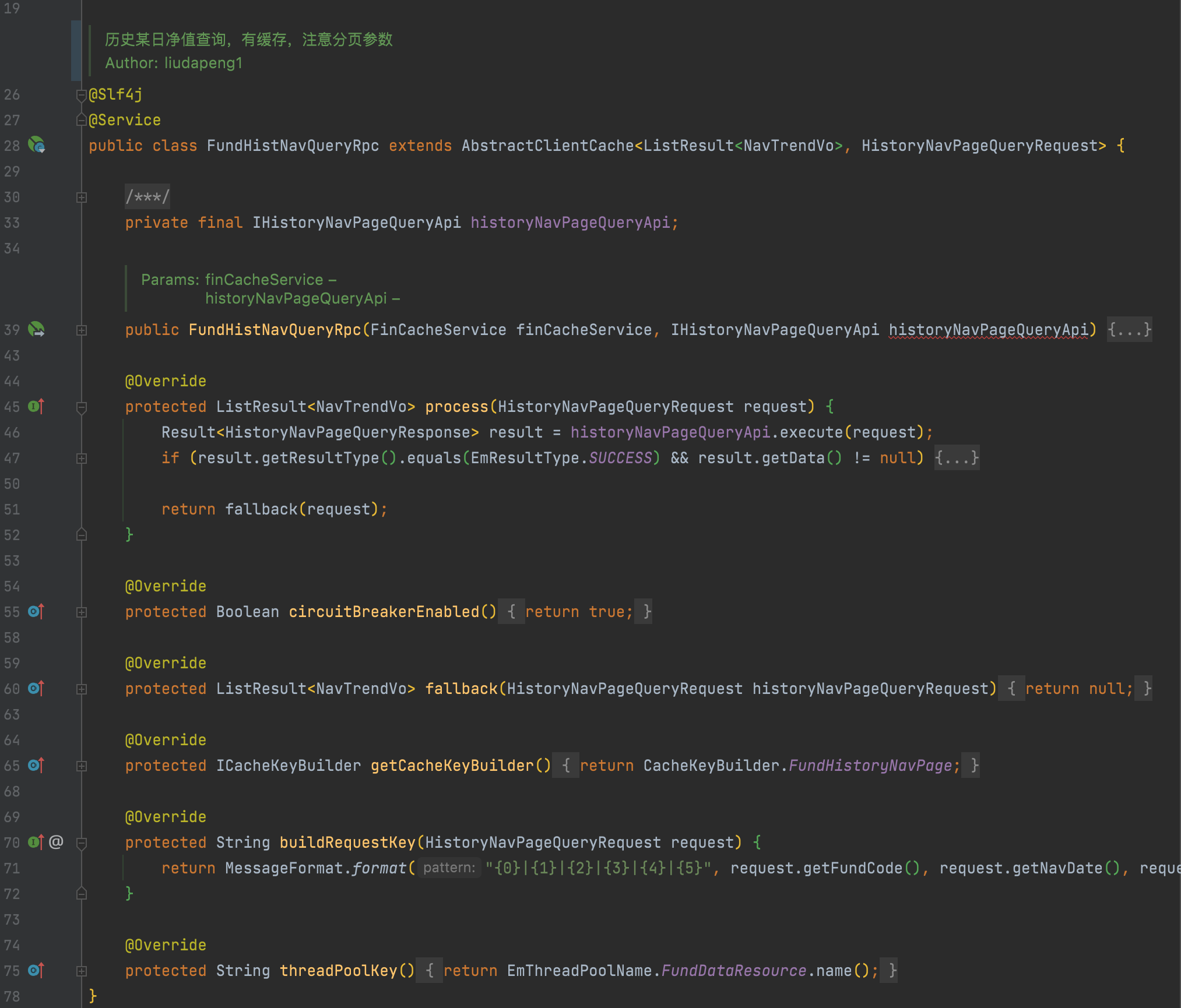
4. 上層調用,實際效果
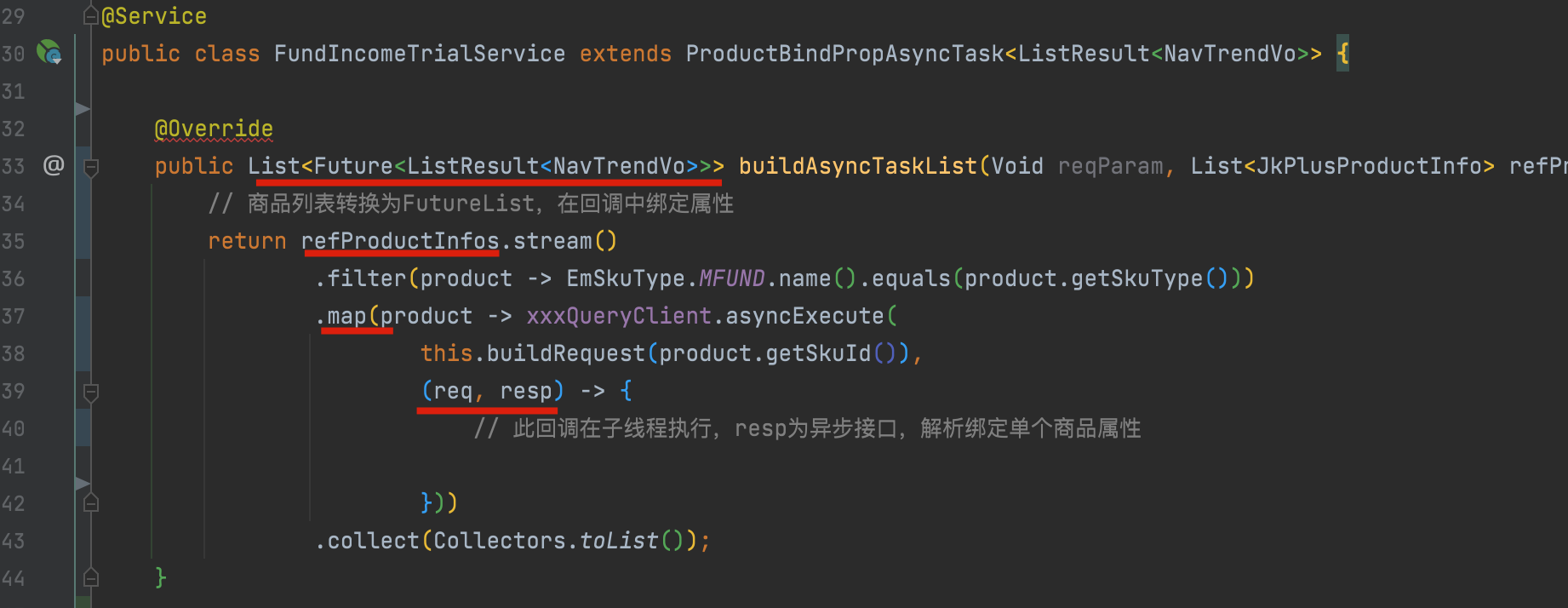
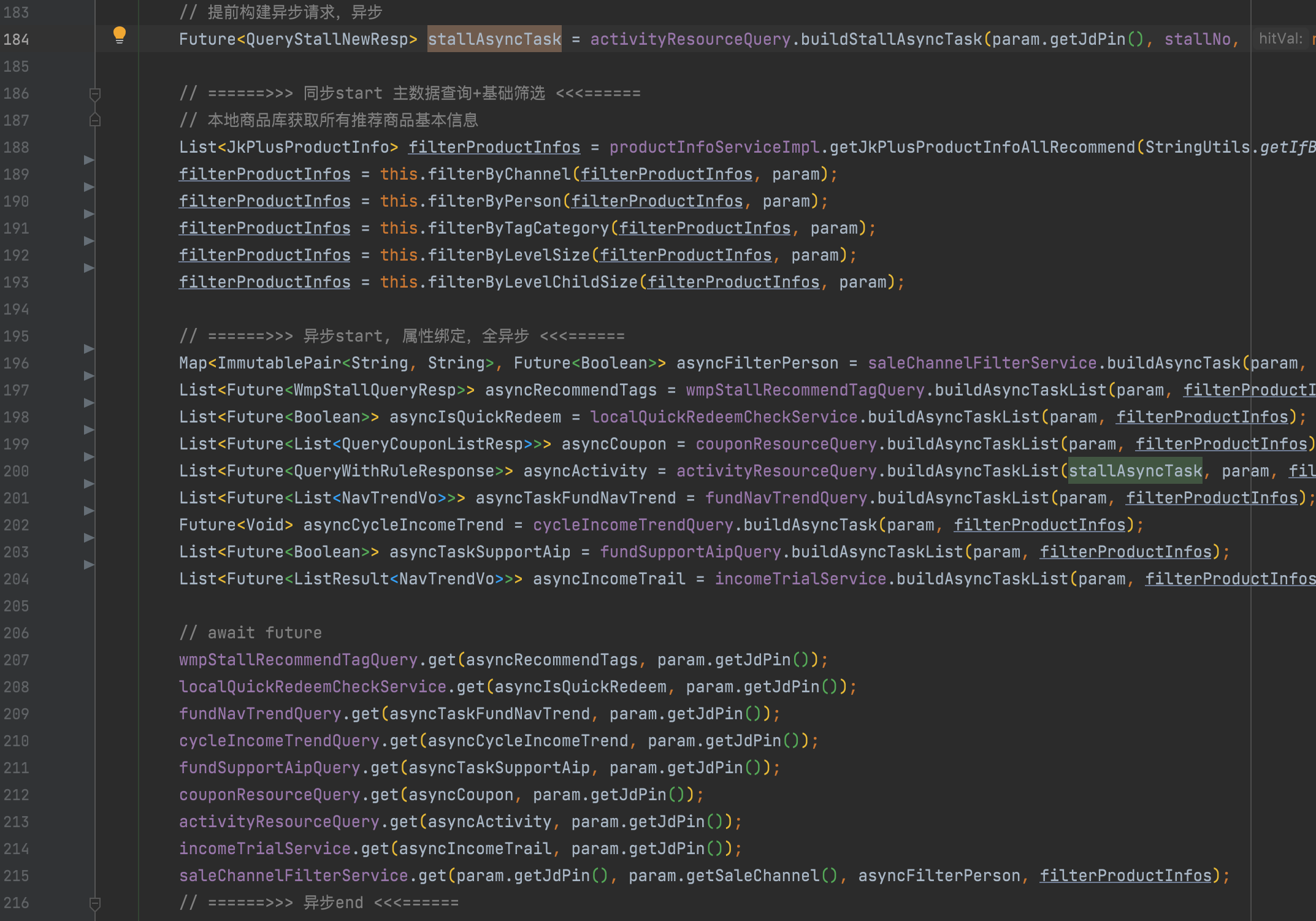
1、直接將一個商品列表轉換成一個異步屬性綁定任務;
2、利用工具類await List>;
3、在上層無感知的狀態下,實現線程池的管理、熔斷、降級、或緩存邏輯的增強,且可根據pfinder監控的可視化線程池狀態,通過concrete實時調整線程池及超時或熔斷參數;
4、舉例:比如某接口頻繁500ms超時,可通過配置直接打開短路返回降級結果,或者調低超時為100ms,快速觸發熔斷,默認10s內請求總數達到20個,50%失敗時打開斷路器,每隔5s半鏈接重試。
三、最后
本篇主要是思考如何依賴現有框架、環境的能力,從代碼層面系統化的實現相關治理規范。
最后仍引用王曉老師文章結尾來結束
接口性能問題形成的原因思考我相信很多接口的效率問題不是一朝一夕形成的,在需求迭代的過程中,為了需求快速上線,采取直接累加代碼的方式去實現功能,這樣會造成以上這些接口性能問題。 變換思路,更高一級思考問題,站在接口設計者的角度去開發需求,會避免很多這樣的問題,也是降本增效的一種行之有效的方式。 以上,共勉!
審核編輯 黃宇
-
接口
+關注
關注
33文章
8993瀏覽量
153688 -
代碼
+關注
關注
30文章
4900瀏覽量
70670
發布評論請先 登錄
ArkUI-X跨平臺應用改造指南
電壓暫降(晃電)危害解析與末端治理實踐:安科瑞ARD系列抗晃電裝置解決方案
HarmonyOS5云服務技術分享--云數據庫使用指南
中軟國際RAI治理能力獲權威認可

IP地址查詢技術

晶科能源入選2024年度Wind中國上市公司ESG最佳實踐100強榜單
架構與設計 常見微服務分層架構的區別和落地實踐
云容器引擎屬于saas層服務嗎?二者是什么關系
常見的IP地址查詢技術

服務網格DPU卸載解決方案
Proxyless的多活流量和微服務治理
如何利用python和API查詢IP地址?
中國高速服務區加油站應用觸摸屏查詢一體機智慧便民






 工商網監
工商網監
評論