") 基于英特爾至強(qiáng)可擴(kuò)展處理器的浪潮信息服務(wù)器AI訓(xùn)推一體化方案
基于英特爾至強(qiáng)可擴(kuò)展處理器的浪潮信息服務(wù)器AI訓(xùn)推一體化方案

概 述
大模型已經(jīng)成為新一輪數(shù)字化轉(zhuǎn)型的重要驅(qū)動力,為了降低對算力與語料資源的要求,加快大模型在實際應(yīng)用的部署,目前企業(yè)普遍在開源/商用大模型中,加入少量語料對模型進(jìn)行預(yù)訓(xùn)練,以構(gòu)建面向具體場景的微調(diào)版大模型,并在實際業(yè)務(wù)中進(jìn)行模型推理,這種方式在經(jīng)濟(jì)性與靈活性方面通常更具優(yōu)勢。對于輕量級的人工智能 (AI) 場景而言,找到一個既經(jīng)濟(jì)又靈活的AI微調(diào)和推理解決方案顯得尤為重要。
浪潮信息和英特爾緊密合作,結(jié)合在硬件和軟件開發(fā)方面的技術(shù)優(yōu)勢,推出了基于英特爾至強(qiáng)可擴(kuò)展處理器的浪潮信息服務(wù)器AI訓(xùn)推一體化方案。該AI訓(xùn)推一體化方案支持計算機(jī)視覺模型的推理工作,同時還支持大語言模型 (LLM) 的微調(diào)和推理工作,并可以用于支持其他通用業(yè)務(wù)。這一方案具備高性能、高性價比、高靈活性等優(yōu)勢,可以充分滿足用戶構(gòu)建輕量級AI微調(diào)與推理系統(tǒng)的需求。
挑戰(zhàn)
在AI模型尤其是大模型微調(diào)及推理過程中,用戶普遍面臨著以下性能挑戰(zhàn):
如何滿足AI微調(diào)及推理對于算力的要求
在AI模型微調(diào)和推理過程中,特別是在大語言模型微調(diào)中,對算力的需求尤其突出。這既包括硬件提供的算力支持,也包括向量化指令集和矩陣計算指令集的支持。
如何滿足模型微調(diào)對于內(nèi)存規(guī)模的需求
在模型訓(xùn)練和微調(diào)中,需要存儲中間激活值、梯度信息,以及用于優(yōu)化器(如Adam、AdamW等)參數(shù)更新的信息,這就需要龐大的內(nèi)存作為支撐。模型微調(diào)實踐表明,Batch size設(shè)定不能太小(通常需要大于16),避免Batch size過小造成不穩(wěn)定的優(yōu)化器梯度下降。同時,訓(xùn)練過程中會產(chǎn)生大量的中間激活值,所需的內(nèi)存遠(yuǎn)遠(yuǎn)超過模型本身的大小。但是,傳統(tǒng)訓(xùn)練方案(雙路服務(wù)器,一機(jī)兩卡/一機(jī)四卡/一機(jī)八卡)由于顯存數(shù)量有限,難以滿足模型微調(diào)的顯存需求。
如何提供充足的內(nèi)存帶寬
AI推理任務(wù)對內(nèi)存帶寬有著高度需求,因此,AI訓(xùn)推服務(wù)器需要提供足夠大的內(nèi)存帶寬與內(nèi)存訪問速度,傳統(tǒng)的雙路服務(wù)器在內(nèi)存帶寬與訪問速度方面難以支撐模型的高效推理。
如何實現(xiàn)便捷擴(kuò)展
為了提升服務(wù)器的算力、內(nèi)存規(guī)模和帶寬,模型訓(xùn)練和推理通常需要將多個 CPU socket高效鏈接起來。而采用以太網(wǎng)作為連接方式將面臨速度慢、不穩(wěn)定、多顆CPU socket的擴(kuò)展性能差等問題。 除了性能挑戰(zhàn)之外,用戶還希望能夠盡可能地降低模型微調(diào)、推理平臺的構(gòu)建與運(yùn)營成本,提升平臺的靈活性,從而進(jìn)一步推動AI任務(wù)的普及和發(fā)展。
基于英特爾至強(qiáng)可擴(kuò)展處理器的浪潮信息服務(wù)器AI訓(xùn)推一體化方案
浪潮信息服務(wù)器AI訓(xùn)推一體化方案的硬件基礎(chǔ)是基于第四代英特爾至強(qiáng)可擴(kuò)展處理器的浪潮信息四路服務(wù)器。該服務(wù)器能夠充分發(fā)揮第四代英特爾至強(qiáng)可擴(kuò)展處理器強(qiáng)大的計算性能,并借助英特爾高級矩陣擴(kuò)展(英特爾AMX)和 IntelExtension for PyTorch (IPEX) 進(jìn)一步加速大模型微調(diào)和推理任務(wù),幫助用戶攻克AI應(yīng)用中的各項挑戰(zhàn)。

圖1. 浪潮信息服務(wù)器AI訓(xùn)推一體化方案架構(gòu)
浪潮信息四路服務(wù)器
為了支持在單臺浪潮信息四路服務(wù)器上,實現(xiàn)復(fù)雜的計算機(jī)視覺模型和大語言模型的微調(diào)及推理任務(wù),浪潮信息服務(wù)器AI訓(xùn)推一體化方案推薦采用英特爾至強(qiáng)金牌處理器或以上的型號。這不僅可以為高負(fù)荷情況下的任務(wù)提供額外的性能提升,還能支持在多線程處理能力上取得優(yōu)秀表現(xiàn)。 該方案推薦搭配DDR5內(nèi)存。DDR5內(nèi)存提供了比前代更高的帶寬,特別適合處理內(nèi)存密集型的應(yīng)用任務(wù)。當(dāng)處理大規(guī)模數(shù)據(jù)和復(fù)雜的計算任務(wù)時,DDR5能確保系統(tǒng)運(yùn)行的流暢性。同時,方案建議按照每個內(nèi)存通道1個DIMM (1DPC) 的配置,將內(nèi)存擴(kuò)展至2TB以上,以滿足同時對高帶寬和高內(nèi)存容量的需求。這一配置不僅可以優(yōu)化系統(tǒng)的運(yùn)行效率,還能在處理大型數(shù)據(jù)集時,提供足夠的內(nèi)存支持,從而確保微調(diào)任務(wù)以及推理任務(wù)的順暢執(zhí)行。

圖2-1. NF8260M7(2U4路)服務(wù)器

圖2-2. NF8480M7(4U4路)服務(wù)器
第四代英特爾至強(qiáng)可擴(kuò)展處理器提供強(qiáng)大AI算力支持
第四代英特爾至強(qiáng)可擴(kuò)展處理器通過創(chuàng)新架構(gòu)增加了每個時鐘周期的指令,每個插槽多達(dá)60個核心,支持8通道DDR5內(nèi)存,有效提升了內(nèi)存帶寬與速度,并通過PCIe 5.0(80個通道)實現(xiàn)了更高的PCIe帶寬提升。第四代英特爾至強(qiáng)可擴(kuò)展處理器提供了出色性能和安全性,可根據(jù)用戶的業(yè)務(wù)需求進(jìn)行擴(kuò)展。借助內(nèi)置的加速器,用戶可以在AI、分析、云和微服務(wù)、網(wǎng)絡(luò)、數(shù)據(jù)庫、存儲等類型的工作負(fù)載中獲得優(yōu)化的性能。通過與強(qiáng)大的生態(tài)系統(tǒng)相結(jié)合,第四代英特爾至強(qiáng)可擴(kuò)展處理器能夠幫助用戶構(gòu)建更加高效、安全的基礎(chǔ)設(shè)施。
第四代英特爾至強(qiáng)可擴(kuò)展處理器內(nèi)置了創(chuàng)新的英特爾AMX加速引擎。英特爾AMX針對廣泛的硬件和軟件優(yōu)化,通過提供矩陣類型的運(yùn)算,顯著增加了人工智能應(yīng)用程序的每時鐘指令數(shù) (IPC),可為AI工作負(fù)載中的訓(xùn)練和推理上提供顯著的性能提升。在實際AI推理負(fù)載中,英特爾AMX能夠加速模型微調(diào)、提升模型的首包推理速度并降低延遲。英特爾AVX-512指令集能夠加速在KV Cache模式下的第二個及以上的token推理。
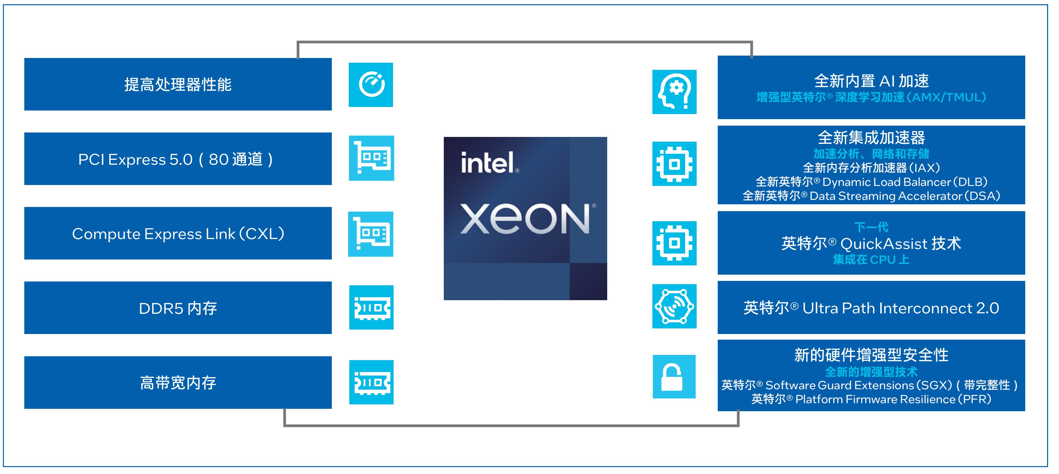
圖3. 英特爾至強(qiáng)可擴(kuò)展處理器為數(shù)據(jù)中心提供多種優(yōu)勢
英特爾豐富軟件生態(tài)助力加速AI部署,釋放算力潛能
除了在硬件領(lǐng)域取得顯著進(jìn)展之外,英特爾在人工智能領(lǐng)域亦構(gòu)建了一個強(qiáng)大且全面的軟件生態(tài)系統(tǒng),提供了包含 IntelExtension for PyToch和英特爾oneDNN在內(nèi)的豐富軟件,能夠幫助用戶充分利用英特爾硬件的強(qiáng)大性能,提高計算效率和運(yùn)行速度。
IntelExtension for PyTorch是一種開源擴(kuò)展,可優(yōu)化英特爾處理器上的深度學(xué)習(xí)性能。許多優(yōu)化最終將包含在未來的PyTorch主線版本中,但該擴(kuò)展允許PyTorch用戶更快地獲得最新功能和優(yōu)化。IntelExtension for Pytorch充分利用了英特爾AVX- 512、矢量神經(jīng)網(wǎng)絡(luò)指令 (VNNI) 和英特爾AMX,將最新的性能優(yōu)化應(yīng)用于英特爾硬件平臺。這些優(yōu)化既包括對PyTorch操作符、Graph和Runtime的改進(jìn),也包括特定于使用場景的自定義操作符和優(yōu)化器的添加。用戶可以通過簡易的Python API,只需對原始代碼做出微小更改即可在英特爾硬件平臺應(yīng)用最新性能優(yōu)化。
英特爾oneAPI Deep Neural Network Library (oneDNN) 是英特爾在軟件優(yōu)化領(lǐng)域的又一亮點(diǎn)。英特爾oneDNN是一個開源性能庫,專為深度學(xué)習(xí)應(yīng)用設(shè)計,支持廣泛的深度學(xué)習(xí)框架和應(yīng)用。該庫提供了高級性能優(yōu)化的深度學(xué)習(xí)原語,專門優(yōu)化了用于英特爾架構(gòu)的深度學(xué)習(xí)操作,包括英特爾至強(qiáng)處理器和 英特爾集成顯卡。通過oneDNN,開發(fā)者可以輕松地在英特爾硬件上實現(xiàn)高效的深度學(xué)習(xí)模型推理和訓(xùn)練,而無需深入了解底層硬件細(xì)節(jié)。英特爾oneDNN已經(jīng)被融合到多個開源平臺中,包括PyTorch和TensorFlow等。
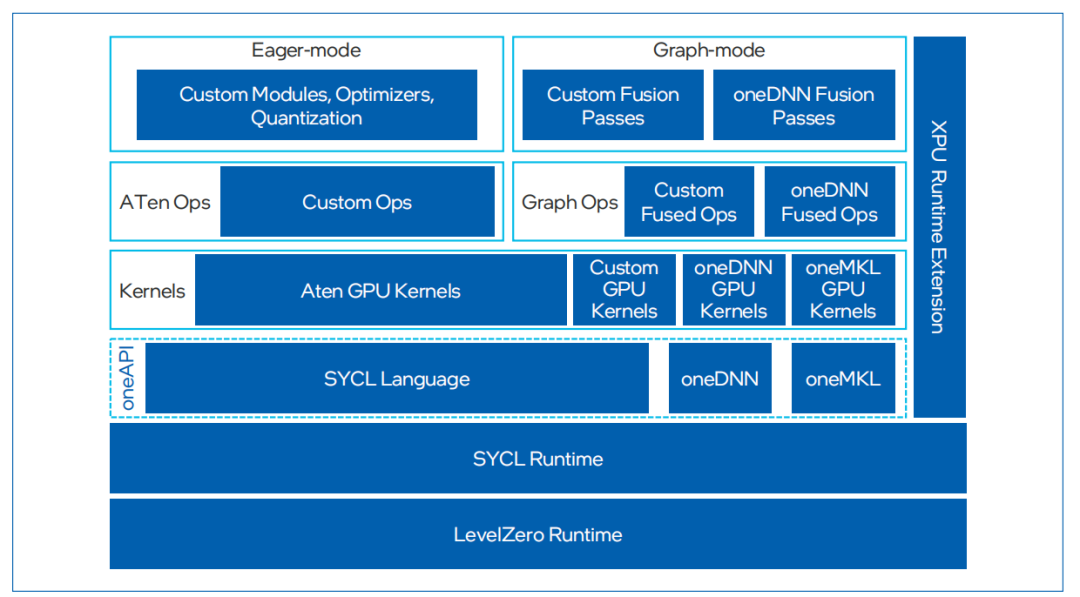
圖4. IntelExtension for PyTorch框架 
測 試 驗 證
在上述軟硬件基礎(chǔ)上,浪潮信息與英特爾合作,從多個方面入手,優(yōu)化了AI模型微調(diào)及推理性能。
采用英特爾AMX加速器和IntelExtension for PyTorch加速模型微調(diào)
得益于對IntelExtension for PyTorch的支持,以及強(qiáng)大的運(yùn)算能力和超大內(nèi)存,浪潮信息四路服務(wù)器在微調(diào)方面表現(xiàn)出強(qiáng)大的性能。浪潮信息四路服務(wù)器采用分布式數(shù)據(jù)并行 + LoRA (Low-Rank Adaptation) 微調(diào)以減少通信開銷,其具備的大內(nèi)存有利于支持更大的batch size,從而提高訓(xùn)練的收斂效果,改善模型質(zhì)量。目前,單臺浪潮信息四路服務(wù)器能夠支持高達(dá)30B模型的微調(diào)。
模型微調(diào)的測試數(shù)據(jù)如圖5顯示,當(dāng)采用alpaca數(shù)據(jù)集(6.5M tokens,數(shù)據(jù)集大小24.2MB)時,單臺四路服務(wù)器可以在72分鐘的時間內(nèi)完成Llama-2-7B微調(diào) (batch size = 16);可以在362分鐘的時間內(nèi)完成Llama-30B模型的微調(diào) (batch size = 16),穩(wěn)定支持非梯度累積模式下高達(dá)64的batch size1。
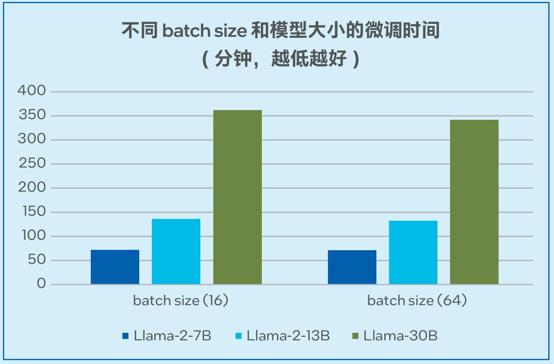
圖5. Llama-2-7B/13B/30B模型的微調(diào)時間
采用英特爾AMX加速器和張量并行加速大語言模型推理
浪潮信息四路服務(wù)器采用了英特爾UPI全拓?fù)溥B接方式, 張量并行推理方案下等同于有效地擴(kuò)展了內(nèi)存帶寬。這一優(yōu)勢與英特爾AMX加速器一起,使得服務(wù)器最終在推理7/13B參數(shù)級別的模型時表現(xiàn)出高度的可擴(kuò)展性。
測試數(shù)據(jù)如圖6-1和圖6-2所示,在7B和13B規(guī)模的模型中,模型推理的延遲可以低至20毫秒左右2,能夠滿足實際業(yè)務(wù)對于推理性能的要求。
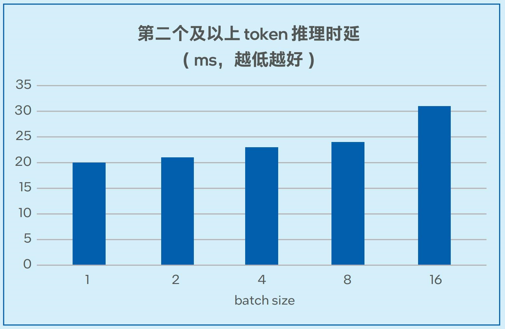
圖6-1. 不同batch size下Llama-2-7B推理延遲測試
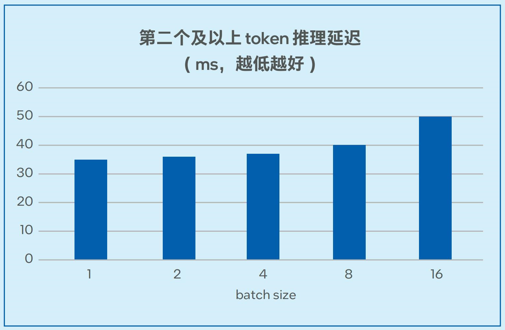
圖6-2. 不同batch size下Llama-2-13B推理延遲測試
采用英特爾AMX加速器和IntelExtension for PyTorch提升視覺模型推理性能
在非大語言模型的通用AI負(fù)載中,一般矩陣乘法(General Matrix Multiplication, GEMM) 往往消耗最多時間,推理訓(xùn)練都受算力限制。浪潮信息四路服務(wù)器在為基于CNN的視覺模型推理帶來更強(qiáng)算力的同時,利用英特爾高級矩陣擴(kuò)展(AMX) 加速矩陣乘法運(yùn)算。如圖7所示,對于經(jīng)典的視覺模型ResNet50,在推理階段,單顆處理器吞吐量最高可以達(dá)到2942.57FPS。同時,該解決方案可以支持高并發(fā),在單臺四路配置時可以達(dá)到11322.08 FPS的吞吐量3。
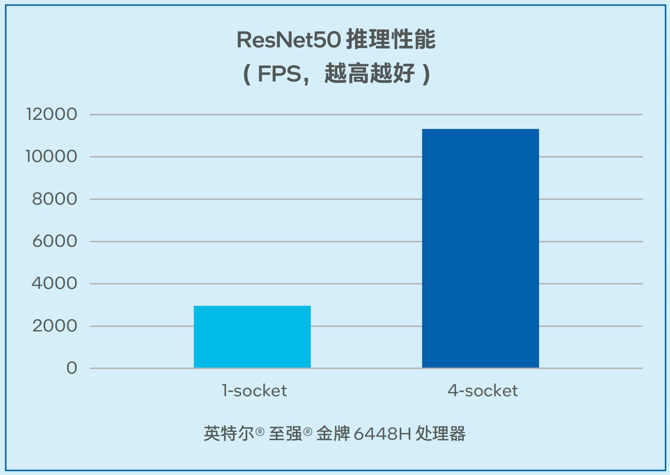
圖7. 浪潮信息四路服務(wù)器 ResNet50推理性能
收 益
基于英特爾至強(qiáng)可擴(kuò)展處理器的浪潮信息服務(wù)器AI訓(xùn)推一體化方案能夠為用戶AI任務(wù)帶來以下收益:
滿足中小規(guī)模的模型對于微調(diào)及推理的算力需求:通過硬件構(gòu)建與軟件優(yōu)化,該AI訓(xùn)推一體化方案提供了強(qiáng)大的模型微調(diào)與推理算力支持,在7B和13B規(guī)模的模型中,模型推理的延遲可以低至20毫秒左右,在基于CNN的視覺模型推理中,單臺四路服務(wù)器上可以達(dá)到11322.08FPS的吞吐量4。
更高的適用性、擴(kuò)展性:該AI訓(xùn)推一體化方案可以靈活地支持計算機(jī)視覺模型推理、大語言模型的微調(diào)和推理,以及其它通用業(yè)務(wù),并實現(xiàn)更高的擴(kuò)展性。
更高的性價比與投資回報:對比專用的AI服務(wù)器方案,該AI訓(xùn)推一體化方案具備高性價比、高可及性等優(yōu)勢,可助力用戶獲得更高的投資回報。
展 望
在智能化成為業(yè)務(wù)關(guān)鍵驅(qū)動力的今天,用戶急切希望搭建自己的AI訓(xùn)練與推理計算平臺,以便能夠躋身人工智能熱潮之中,探索和擴(kuò)展他們的AI業(yè)務(wù)領(lǐng)域。以英特爾至強(qiáng)可擴(kuò)展處理器為基礎(chǔ)的浪潮信息服務(wù)器AI訓(xùn)推一體化方案憑借在性價比與靈活性等方面的優(yōu)勢,有望成為推動AI微調(diào)與推理的關(guān)鍵基礎(chǔ)設(shè)施。
展望AI技術(shù)的未來發(fā)展,其不僅將創(chuàng)造更多的業(yè)務(wù)形態(tài),而且為企業(yè)創(chuàng)造了巨大的商業(yè)潛力和發(fā)展機(jī)遇。浪潮和英特爾雙方將在技術(shù)探索、產(chǎn)品升級、應(yīng)用推廣等多個層面深度協(xié)作,推動AI在更多應(yīng)用場景的創(chuàng)新以及普及,助力AI的應(yīng)用與發(fā)展。
審核編輯:劉清
-
處理器
+關(guān)注
關(guān)注
68文章
19852瀏覽量
234191 -
以太網(wǎng)
+關(guān)注
關(guān)注
40文章
5610瀏覽量
175357 -
DDR5
+關(guān)注
關(guān)注
1文章
444瀏覽量
24797 -
pytorch
+關(guān)注
關(guān)注
2文章
809瀏覽量
13868 -
AI大模型
+關(guān)注
關(guān)注
0文章
370瀏覽量
546
原文標(biāo)題:浪潮信息基于至強(qiáng)? 可擴(kuò)展處理器推出 AI 服務(wù)器訓(xùn)推一體化方案
文章出處:【微信號:英特爾中國,微信公眾號:英特爾中國】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
主控CPU全能選手,英特爾至強(qiáng)6助力AI系統(tǒng)高效運(yùn)轉(zhuǎn)

英特爾發(fā)布邊緣AI控制器與邊緣智算一體機(jī),創(chuàng)造“AI新視界”

部署成本顯著降低!英特爾助陣高效AI算力一體機(jī)方案

英特爾至強(qiáng)6處理器助力數(shù)據(jù)中心整合升級
英特爾至強(qiáng)6再推新品!打造最強(qiáng)AI“機(jī)頭引擎”
英特爾展示基于至強(qiáng)6處理器的基礎(chǔ)網(wǎng)絡(luò)設(shè)施
MWC 2025:英特爾展示基于至強(qiáng)6處理器的基礎(chǔ)網(wǎng)絡(luò)設(shè)施

HPE攜手英特爾至強(qiáng)6,打造新一代服務(wù)器性能巔峰
英特爾發(fā)布全新企業(yè)AI一體化解決方案
浪潮信息發(fā)布元腦企智一體機(jī)
英特爾發(fā)布至強(qiáng)6性能核處理器
英特爾?至強(qiáng)?可擴(kuò)展處理器助力智慧醫(yī)療的數(shù)字化轉(zhuǎn)型

英特爾發(fā)布至強(qiáng)6處理器產(chǎn)品
開箱即用,AISBench測試展示英特爾至強(qiáng)處理器的卓越推理性能






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論