 采用OpenACC框架的FVCOM模型實現超百倍計算加速
采用OpenACC框架的FVCOM模型實現超百倍計算加速

華東師范大學河口海岸學國家重點實驗室葛建忠教授團隊作為國際先進海洋數值模型 FVCOM 開發團隊核心成員,隨著 FVCOM 的發展和應用越來越廣泛,以及行業不斷提升的對預報精度與時效性要求,算力需求劇增,借助 NVIDIA GPU 加速計算技術,不僅實現了傳統動力學數值模型的百倍計算加速,造福了海洋預報、水利工程等具體應用領域,也為海洋模型系統向人工智能模型轉型以及人工智能海洋學的發展提供了關鍵的基礎數據生成工具和方法,是人工智能技術進一步應用于海洋領域的重要基石。
海洋預報數值模型計算負載劇增
隨著自然災害越來越頻發,為災害過程防御提供技術支撐的數值預報系統對“精確、及時、高效、穩定”有著越來越高的需求,特別是隨著集合預報模型的研發和應用帶來了數值模型計算量的急劇上升(比如在集合預報中計算量與集合樣本數量成正比,是單個模型計算的數十倍),超大的計算負載給預報業務單位和超算中心帶來了極大的壓力,而預報系統又具有“高時效”的特點,要盡可能地控制計算量,從而提高預報時效。與此同時,河口生態、生物地球化學過程模型具有變量多、過程復雜的特點,其計算量一般是動力模型的 10 倍以上。潮灘濕地植被斑塊及潮溝系統、近海工程、海上風電場等模型一般都要求小于 5 米的空間分辨率,這也造成了模型計算量顯著增大。
面對計算量劇增的挑戰,實驗室目前的計算架構主要采取基于 CPU 的多核計算節點擴展方案為主,以增加核數、節點來應對,這對高性能集群的建設和運維提出了更高的要求,也進一步提高了數值模型應用和拓展的門檻。
采用 OpenACC 框架加速 FVCOM 模型
為了解決數值模型計算負載劇增這一難點問題,華東師范大學河口海岸學國家重點實驗室葛建忠教授團隊調研分析了目前的主要 GPU 加速計算技術,包括 CUDA、OpenACC、stdpar、Kokkos、OpenCL 等,并與 NVIDIA 技術團隊進行了詳細討論和分析,結合 FVCOM 模型代碼的復雜度,選擇了 OpenACC 為主的技術路線,并于 2023 年初開始相關代碼遷移工作,并在 2023 年 8 月參加了 NVIDIA 舉辦的武漢大學 GPU Hackthon 活動,得到了專業的技術支持,解決了多個關鍵技術難點,于 2023 年底完成了主要代碼的遷移、測試和驗證工作。
為降低大規模數值模型的使用門檻,模型代碼的遷移和測試都在一臺搭載 NVIDIA GeForce RTX 40 系列 GPU 的臺式電腦上完成,并在 2023 年初完成部署的超算中心計算節點上采用 CPU 進行對比,該計算節點為 Intel Xeon Gold CPU,遷移后的模型支持正壓、斜壓、泥沙、植被等關鍵模型,并支持全部外部驅動包括風場、熱通量、降雨、離線流場、嵌套文件的高效傳輸,也可進行單精度、雙精度計算的自由切換。遷移后模型相關的輸入、輸出和控制文件未發生任何變化,可以適用于原有 FVCOM 的相關應用。
加速對比測試選擇 10 萬、35 萬、100 萬、150 萬、200 萬水平方向網格等模型,所有模型都在 RTX GPU 上進行單精度模式計算,并采用計算節點進行單線程運行相同模型。相對于 CPU 單線程計算速度,采用 OpenACC 技術的 FVCOM 模型分別達到了 88、181、194、195、198 倍的加速比(圖 1)。在此基礎上采用編譯器控制選項可以在同一套代碼上靈活切換 CPU 或者 GPU 模式,且經檢驗,CPU 和 GPU 加速模型都得到一致的模擬結果。在單精度 FVCOM 的前提下,一個 RTX GPU 的計算能力在不考慮網絡交換的情況下相當于超算集群的 3.5 個 64 核計算節點,在考慮節點間網絡交換延遲時可相當于 5 個節點。
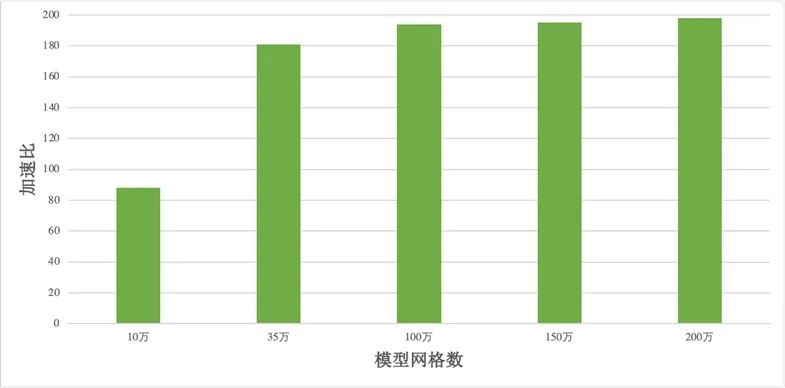
圖 1:單精度 GPU-FVCOM 加速實驗結果
該模型可在 NVIDIA 加速計算框架體系內高效擴展,將 10 萬、35 萬、100 萬、150 萬網格模型再調整為雙精度模式,采用單個 NVIDIA Ampere Tensor Core GPU 進行加速計算,分別達到了 48、77、139 和 135 的加速比,顯示了對雙精度模式也有良好的加速效果。在多個 GPU 計算節點的情況下,也可采用 MPI+OpenACC 方式支持多 GPU 并行計算。
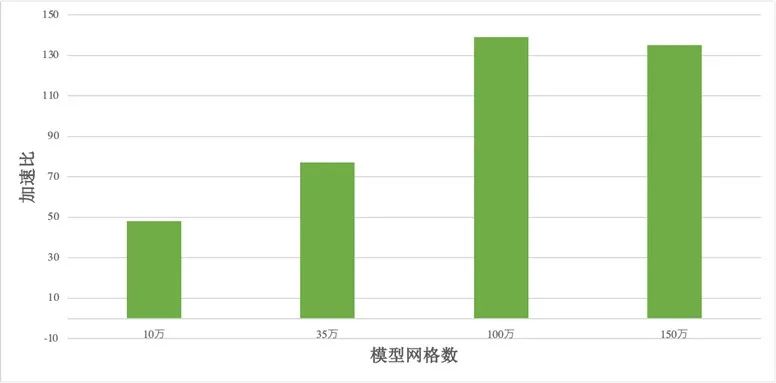
圖 2:雙精度 GPU-FVCOM 加速實驗結果
超百倍計算加速造福海洋預報
目前,FVCOM 模型在海洋預報、海洋工程與作業等領域應用極為廣泛。以國內外近海海洋預報業務為例,FVCOM 已經成為我國沿海省、市、區各級海洋預警預報部門開展業務化預報工作的主要模型選擇。海洋預報業務的發展趨勢是不斷提升對預報精度與時效的要求,二者都意味著巨大的算力需求,而將 FVCOM 模型實現 GPU 加速是解決實際應用中劇增的算力需求的有效途徑。
采用 GPU 加速的預報模型可以將預報時效從小時級別降低到分鐘級,甚至秒級。顯著的效率提升也釋放了模型進一步采用更高網格分辨率從而提高模擬精度的潛力。
另一方面,業務部門對于臺風風暴潮等事件的集合預報愈發重視。集合預報是指針對不同的初始條件或驅動要素(例如臺風演化過程)的擾動,計算出多個可能的未來情形,以考慮預報中的不確定性。這就對模型的計算速度提出了更大的挑戰,而 GPU 加速能夠很好地加以應對。
在水利工程領域,FVCOM 模型也已廣泛用于工程可行性分析與評估。尤其是在工程前期研究階段,需要借助數值模型對多種施工建設方案的效果進行模擬評估,多工況計算對傳統模型也造成了極大挑戰。實現 GPU 加速從而更快地給出論證結果,則可以切實地提高工程推進效率,節省工期。
此外,本項目所實現的案例具有較高的啟示意義與推廣價值,例如 OpenACC 技術方案還可以應用在其他近海和海洋數值模型系統。在采用結構化網格的模型中(如ROMS、ECOM、POM 等),該方案甚至可能實現更好的加速效果。本次實踐也證明,GPU 加速能夠極大地降低河口、海岸、海洋研究和工程應用領域進行數值模擬所需的硬件門檻,為學科發展、業務應用都提供了巨大幫助。
目前,海洋數值模型正經歷其發展歷程中的最大轉型,即從基于動力學機制與方程的傳統海洋數值模型轉型為基于機器學習(深度學習)等方法的人工智能模型。而人工智能模型對數據的需求與依賴巨大,其訓練通常離不開海量的、可靠的數據。然而,海洋系統中的實測數據,相較于海洋巨大的空間尺度以及所關切問題的具體時間范圍,總是稀缺的。數值模型則可以為人工智能模型提供大量的基礎訓練數據,也是當下保障數據范圍與質量最有效的途徑之一。例如,葛建忠教授團隊已經用實現 GPU 加速的 FVCOM 模型系統計算了中國近海 1960 – 2023 年海洋流場和生態動力過程,用該三維高分辨率模型生成了超 20TB 容量的同化數據產品。隨后,通過利用 NVIDIA 開發的基于 AFNO 架構的 FourCastNet 模型對該數據集開展訓練,他們實現了對河口及近海動力學過程的快速推演與分析。此外,他們還采用實現 GPU 加速的 FVCOM 模型高效快速地計算了超過 1000 個臺風風暴潮過程樣本,用于訓練一個基于深度學習方法的風暴潮預報模型。這兩個數據集的構建,若采用傳統的、未經加速的數值模型,所耗費的時間成本將高出百倍以上。
綜上,采用 OpenACC 框架的 FVCOM 為傳統動力學數值模型提供了超過百倍的計算加速。這樣的效率提升不僅直接造福了海洋預報、水利工程等具體應用領域,也為海洋模型系統向人工智能模型轉型以及人工智能海洋學的發展提供了關鍵的基礎數據生成工具和方法,是人工智能技術進一步應用于海洋領域的重要基石。
團隊介紹
華東師范大學河口海岸學國家重點實驗室葛建忠教授團隊長期致力于海洋數值模型的研發與應用,是國際先進海洋數值模型 FVCOM 開發團隊核心成員,主持開發了其中導堤-丁壩、細顆粒粘性泥沙、浮泥、河流閘門、植被、藻類漂移生長等 FVCOM 核心模塊,并參與開發了波流共同作用、FVCOM-ERSEM 生物地球化學等模塊。此外,該團隊也建立了中國海-長江口多空間尺度物理-生物地球化學耦合數值模擬系統。
葛建忠教授團隊基于 FVCOM 框架,主要聚焦高濃度泥沙、物理-生物地球化學耦合過程、臺風風暴潮等方面的研究,并針對長江河口、黃海、浙閩沿海、珠江口和北部灣等國內典型河口海岸區域進行了應用研究。在德國的易北河口、漢堡港、越南的峴港等區域,該團隊也開展了相關合作和應用研究,其相關成果也為國家海洋與水利等部門的黃海滸苔防治、風暴潮預報、咸潮入侵防御等方面提供了多項技術支撐。
審核編輯:劉清
-
NVIDIA
+關注
關注
14文章
5309瀏覽量
106348 -
人工智能
+關注
關注
1806文章
49008瀏覽量
249322 -
機器學習
+關注
關注
66文章
8501瀏覽量
134583 -
深度學習
+關注
關注
73文章
5561瀏覽量
122789 -
GPU芯片
+關注
關注
1文章
305瀏覽量
6197
原文標題:造福海洋預報!采用 OpenACC 框架的 FVCOM 模型實現超百倍計算加速
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
大模型推理顯存和計算量估計方法研究
百度飛槳框架3.0正式版發布

華為星河AI網絡加速行業智能化轉型
利用NVIDIA DPF引領DPU加速云計算的未來
中國電提出大模型推理加速新范式Falcon






 工商網監
工商網監
評論