") 簡單三步使用OpenVINO?搞定ChatGLM3的本地部署
簡單三步使用OpenVINO?搞定ChatGLM3的本地部署
工具介紹
英特爾OpenVINO 工具套件是一款開源AI推理優(yōu)化部署的工具套件,可幫助開發(fā)人員和企業(yè)加速生成式人工智能 (AIGC)、大語言模型、計算機(jī)視覺和自然語言處理等 AI 工作負(fù)載,簡化深度學(xué)習(xí)推理的開發(fā)和部署,便于實現(xiàn)從邊緣到云的跨英特爾 平臺的異構(gòu)執(zhí)行。
ChatGLM3是智譜AI和清華大學(xué)KEG實驗室聯(lián)合發(fā)布的對話預(yù)訓(xùn)練模型。ChatGLM3-6B是ChatGLM3系列中的開源模型,在保留了前兩代模型對話流暢、部署門檻低等眾多優(yōu)秀特性的基礎(chǔ)上,ChatGLM3-6B引入了以下新特性:
1
更強(qiáng)大的基礎(chǔ)模型:
ChatGLM3-6B的基礎(chǔ)模型ChatGLM3-6B-Base采用了更多樣的訓(xùn)練數(shù)據(jù)、更充分的訓(xùn)練步數(shù)和更合理的訓(xùn)練策略。在語義、數(shù)學(xué)、推理、代碼、知識等不同角度的數(shù)據(jù)集上測評顯示,ChatGLM3-6B-Base具有在10B以下的預(yù)訓(xùn)練模型中領(lǐng)先的性能。
2
更完整的功能支持:
ChatGLM3-6B采用了全新設(shè)計的Prompt格式,除正常的多輪對話外,同時原生支持工具調(diào)用 (Function Call)、代碼執(zhí)行 (Code Interpreter) 和Agent任務(wù)等復(fù)雜場景。
3
更全面的開源序列:
除了對話模型ChatGLM3-6B外,還開源了基礎(chǔ)模型ChatGLM-6B-Base、長文本對話模型ChatGLM3-6B-32K。以上所有權(quán)重對學(xué)術(shù)研究完全開放,在填寫問卷進(jìn)行登記后亦允許免費商業(yè)使用。

圖:基于Optimum-intel與OpenVINO部署生成式AI模型流程
英特爾為開發(fā)者提供了快速部署ChatGLM3-6B的方案支持。開發(fā)者只需要在GitHub上克隆示例倉庫,進(jìn)行環(huán)境配置,并將Hugging Face模型轉(zhuǎn)換為OpenVINO IR模型,即可進(jìn)行模型推理。由于大部分步驟都可以自動完成,因此開發(fā)者只需要簡單的工作便能完成部署,目前該倉庫也被收錄在GhatGLM3的官方倉庫和魔搭社區(qū)Model Card中,接下來讓我們一起看下具體的步驟和方法:
示例倉庫:
https://github.com/OpenVINO-dev-contest/chatglm3.openvino
官方倉庫:
https://github.com/THUDM/ChatGLM3?tab=readme-ov-file#openvino-demo
Model Card:
https://www.modelscope.cn/models/ZhipuAI/chatglm3-6b/summary#
1
模型轉(zhuǎn)換
當(dāng)你按倉庫中的README文檔完成集成環(huán)境配置后,可以直接通過以下命令運(yùn)行模型轉(zhuǎn)換腳本:
python3 convert.py --model_id THUDM/chatglm3-6b –output {your_path}/chatglm3-6b-ov
該腳本首先會利用Transformers庫從Hugging Face的model hub中下載并加載原始模型的PyTorch對象,如果開發(fā)者在這個過程中無法訪問Hugging Face的model hub,也可以通過配置環(huán)境變量的方式,將模型下載地址更換為鏡像網(wǎng)站,并將convert.py腳本的model_id參數(shù)配置為本地路徑,具體方法如下:
$env:HF_ENDPOINT = https://hf-mirror.com
huggingface-cli download --resume-download --local-dir-use-symlinks False THUDM/chatglm3-6b --local-dir {your_path}/chatglm3-6b
python3 convert.py --model_id {your_path}/chatglm3-6b --output {your_path}/chatglm3-6b-ov
當(dāng)獲取PyTorch的模型對象后,該腳本會利用OpenVINO的PyTorch frontend進(jìn)行模型格式的轉(zhuǎn)換,執(zhí)行完畢后,你將獲取一個由.xml和.bin文件所構(gòu)成的OpenVINO IR模型文件,該模型默認(rèn)以FP16精度保存。
2
權(quán)重量化
該步驟為可選項,開發(fā)者可以通過以下腳本,將生成的OpenVINO模型通過權(quán)重量化策略,進(jìn)一步地壓縮為4-bits或者是8-bits的精度,以獲取更低的推理延時及系統(tǒng)資源占用。
python3 quantize.py --model_path {your_path}/chatglm3-6b-ov --precision int4 --output {your_path}/chatglm3-6b-ov-int4
執(zhí)行完畢后,你將獲得經(jīng)過壓縮后的IR模型文件,以INT4對稱量化為例,該壓縮后的模型文件的整體容量大約為4GB左右。
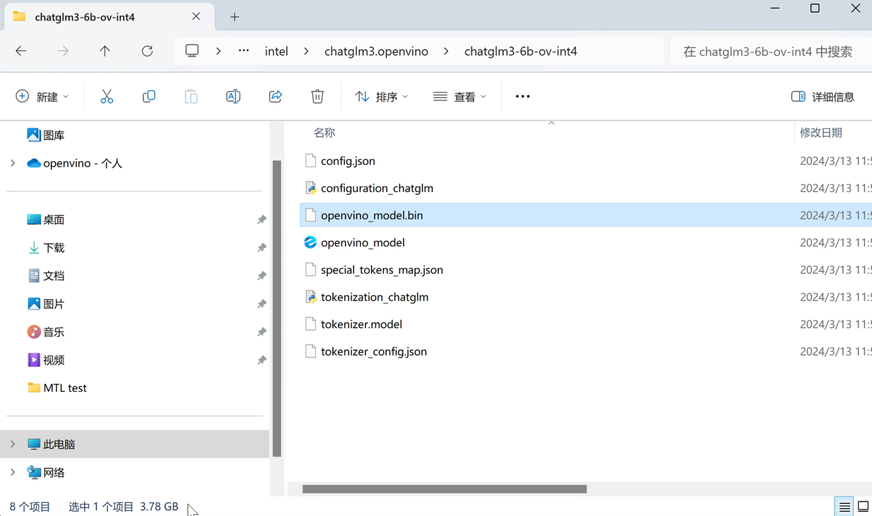
圖:量化后的OpenVINO模型文件
同時在量化結(jié)束后,亦會在終端上打印模型的量化比例,如下圖所示。

圖:量化比例輸出
由于OpenVINO NNCF工具的權(quán)重壓縮策略只針對于大語言模型中的Embedding和Linear這兩種算子,所以該表格只會統(tǒng)計這兩類算子的量化比例。其中ratio-defining parameter是指我們提前通過接口預(yù)設(shè)的混合精度比例,也就是21%權(quán)重以INT8表示,79%以INT4表示,這也是考慮到量化對ChatGLM3模型準(zhǔn)確度的影響,事先評估得到的配置參數(shù),開發(fā)者亦可以通過這個示例搜索出適合其他模型的量化參數(shù)。此外鑒于第一層Embedding layer和模型最后一層操作對于輸出準(zhǔn)確度的影響,NNCF默認(rèn)會將他們以INT8表示,這也是為何all parameters中顯示的混合精度比例會有所不同。當(dāng)然開發(fā)者也可以通過nncf.compress_weights接口中設(shè)置all_layers=True,開關(guān)閉該默認(rèn)策略。
示例:
https://github.com/openvinotoolkit/nncf/tree/develop/examples/llm_compression/openvino/tiny_llama_find_hyperparams
3
模型轉(zhuǎn)換
最后一步就是模型部署了,這里展示的是一個Chatbot聊天機(jī)器人的示例,這也是LLM應(yīng)用中最普遍,也是最基礎(chǔ)的pipeline,而OpenVINO可以通過Optimum-intel工具為橋梁,復(fù)用Transformers庫中預(yù)置的pipeline,因此在這個腳本中我們會對ChatGLM3模型再做一次封裝,以繼承并改寫OVModelForCausalLM類中的方法,實現(xiàn)對于Optimum-intel工具的集成和適配。以下為該腳本的運(yùn)行方式:
python3 chat.py --model_path {your_path}/chatglm3-6b-ov-int4 --max_sequence_length 4096 --device CPU
如果開發(fā)者的設(shè)備中包含英特爾的GPU產(chǎn)品,例如Intel ARC系列集成顯卡或是獨立顯卡,可以在這個命令中將device參數(shù)改為GPU,以激活更強(qiáng)大的模型推理能力。
在終端里運(yùn)行該腳本后,會生成一個簡易聊天對話界面,接下來你就可以驗證它的效果和性能了。
總結(jié)
通過模型轉(zhuǎn)換、量化、部署這三個步驟,我們可以輕松實現(xiàn)在本地PC上部署ChatGLM3-6b大語言模型,經(jīng)測試該模型可以流暢運(yùn)行在最新的Intel Core Ultra異構(gòu)平臺及至強(qiáng)CPU平臺上,作為眾多AI agent和RAG等創(chuàng)新應(yīng)用的核心基石,大語言模型的本地部署能力將充分幫助開發(fā)者們打造更安全,更高效的AI解決方案。
審核編輯:劉清
-
人工智能
+關(guān)注
關(guān)注
1804文章
48677瀏覽量
246341 -
計算機(jī)視覺
+關(guān)注
關(guān)注
9文章
1706瀏覽量
46561 -
pytorch
+關(guān)注
關(guān)注
2文章
809瀏覽量
13756 -
OpenVINO
+關(guān)注
關(guān)注
0文章
113瀏覽量
412
原文標(biāo)題:簡單三步使用OpenVINO? 搞定ChatGLM3的本地部署 | 開發(fā)者實戰(zhàn)
文章出處:【微信號:英特爾物聯(lián)網(wǎng),微信公眾號:英特爾物聯(lián)網(wǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
本地服務(wù)器部署怎么選?一招搞定企業(yè)IT成本、性能與安全問題!

Intel OpenVINO? Day0 實現(xiàn)阿里通義 Qwen3 快速部署
工廠設(shè)備總故障?諧波治理新國標(biāo)解讀,3步搞定省電又保生產(chǎn)

Modbus轉(zhuǎn)以太網(wǎng)終極方案:三步實現(xiàn)老舊設(shè)備智能升級
如何部署OpenVINO?工具套件應(yīng)用程序?
是否可以使用OpenVINO?部署管理器在部署機(jī)器上運(yùn)行Python應(yīng)用程序?
C#集成OpenVINO?:簡化AI模型部署

DeepSeek-R1本地部署指南,開啟你的AI探索之旅

C#中使用OpenVINO?:輕松集成AI模型!
用Ollama輕松搞定Llama 3.2 Vision模型本地部署

使用OpenVINO Model Server在哪吒開發(fā)板上部署模型
使用OpenVINO 2024.4在算力魔方上部署Llama-3.2-1B-Instruct模型
三行代碼完成生成式AI部署
【AIBOX上手指南】快速部署Llama3






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論