 Achronix新推出一款用于AI/ML計算或者大模型的B200芯片
Achronix新推出一款用于AI/ML計算或者大模型的B200芯片
近日舉辦的GTC大會把人工智能/機器學習(AI/ML)領域中的算力比拼又帶到了一個新的高度,這不只是說明了通用圖形處理器(GPGPU)時代的來臨,而是包括GPU、FPGA和NPU等一眾數據處理加速器時代的來臨,就像GPU以更高的計算密度和能效勝出CPU一樣,各種加速器件在不同的AI/ML應用或者細分市場中將各具優勢,未來并不是只要貴的而是更需要對的。
此次GTC上新推出的用于AI/ML計算或者大模型的B200芯片有一個顯著的特點,它與傳統的圖形渲染GPU大相徑庭并與上一代用于AI/ML計算的GPU很不一樣。在其他算力器件品種中也是如此,AI/ML計算尤其是推理應用需要一種專為高帶寬工作負載優化的新型FPGA,下面我們以Achronix的Speedster7t FPGA芯片為例來看看技術的演進方向,以及在實際推理應用中展現出來的在性價比和能效比等方面優于先進GPU的特性。
先來快速看看Speedster7t的產品亮點:該器件集成了800K到1500K等效邏輯單元以及326K到692K 6輸入查找表(LUT),高達120T算力的機器學習處理單元(MLP),同時還配備了高性能存儲和I/O接口,以及最高可達190Mb的嵌入式存儲容量。在外部連接接口部署上,Speedster7t包含16個GDDR6通道,可提供高達4 Tbps的高速存儲帶寬;32對SerDes通道,支持1-112Gbps的數據速率;4個400G以太網端口(4× 400G或16× 100G)和2個PCIe Gen5端口,支持16通道(×16)和8通道(×8)配置。
Achronix的Speedster7t FPGA芯片被用戶認為非常適合AI/ML推理原因是:足夠的算力,靈活可配的計算精度;高帶寬大容量低成本的GDDR6(4Tbps帶寬, 32GB容量);革命性的全新二維片上網絡(2D NoC)路由架構;靈活通用的芯片間互聯;支持用戶基于該芯片開發自定義的推理系統,比如單板多片FPGA甚至多板互聯以組成更高性能(如1TBbps/64GB,2TBbps/128GB, 4TBbps/256GB…等更高帶寬和更大容量的計算存儲)以支持更大或超大模型推理部署。
簡而言之,相比傳統的推理算力平臺,Speedster7t FPGA可以提供更高性價比和能耗比的大模型推理能力;另外,在傳統的FPGA處理功能中,越來越多的用戶在該系統中加入機器學習的能力, Speedster7t FPGA能很好勝任傳統FPGA功能和高性能機器學習融合在一起。
一類創新性的高性能FPGA系列產品
Achronix Speedster7t系列FPGA基于革命性的FPGA架構,該架構經過了高度優化提供了高速、高帶寬內外連接,可以滿足日益增長的人工智能/機器學習、網絡密集型和數據加速應用的需求。Speedster7t系列FPGA芯片具有一個革命性的全新二維片上網絡,以及一個針對人工智能/機器學習進行優化的高密度的機器學習處理單元陣列。通過將FPGA的可編程性與類似ASIC路由架構和計算引擎相結合,Speedster7t系列提高了高性能FPGA的標準。
全新的二維片上網絡(2D NoC)提供ASIC級別的性能
Speedster7t系列FPGA芯片具有革命性的2D NoC,可在整個FPGA邏輯陣列中傳輸數據,并將數據傳輸到高性能I/O和內存子系統,同時可提供高達20 Tbps的總帶寬。憑借2D NoC,在Speedster7t FPGA芯片不需要消耗任何可編程邏輯資源的情況下來進行數據傳輸。在該芯片上的2D NoC提供了20 Tbps的二維片上網絡總帶寬;該2D NoC不僅覆蓋了芯片全域,而且還連接到各類高速接口和總帶寬高達4 Tbps的高速存儲接口。
高速接口
無論是支持輸入和輸出的數據流,還是存儲緩沖這些數據,對于高性能計算、機器學習和硬件加速解決方案而言,都需要在片內和片外傳輸數據。Speedster7t系列FPGA芯片的架構可支持前所未有的帶寬。包括:
400G以太網:Speedster7t系列FPGA芯片支持多達4個400GbE端口或16個100GbE端口,通過2D NoC連接到FPGA邏輯。
PCI Express Gen5:Speedster7t系列FPGA芯片配備了多個PCle Gen5接口,支持速率達32GT/s。
存儲接口:GDDR6 + DDR4/5
Speedster7t器件是唯一在片上支持GDDR6存儲器的FPGA,以最低的DRAM成本(每存儲位)提供最快的SDRAM訪問速度。Speedster7t系列FPGA芯片具有高達4 Tbps的GDDR6帶寬,以很低的成本就可提供相當于基于HBM的FPGA存儲器帶寬。Speedster7t系列FPGA芯片包括了DDR4/5存儲器接口,以支持更深入的緩沖需求。PHY和控制器支持由JEDEC規范定義的所有標準功能。
機器學習處理單元
每個Speedster7t FPGA器件都具有可編程的數學計算單元,這些單元被集成至全新的機器學習處理單元(MLP)模塊中。每個MLP都是一個高度可配置的計算密集型模塊,具有多達32個乘法器/累加器(MAC),支持4到24位整數格式和各種浮點模式,包括Tensorflow的bfloat16格式以及高效的塊浮點格式,大大提高了性能。
MLP模塊包括緊密集成的嵌入式存儲器模塊,以確保機器學習算法將以750 MHz的最高性能運行。這種高密度計算和高性能數據傳輸的結合造就了高性能機器學習處理結構,該結構可提供市場上基于FPGA的極高TOPS級別運算能力(TOPS即Tera-Operations Per Second,每秒萬億次運算)。
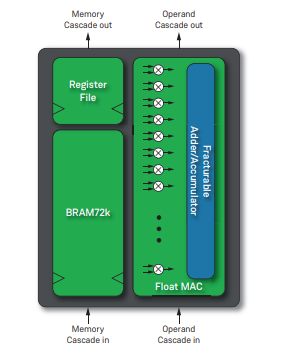
圖中文字說明:Register File - 寄存器文件,Fracturable Adder/Accumulator - 可拆分的加法器/累加器,Float MAC - 浮點乘累加單元(MAC),Memory Cascade in - 存儲器級聯,Operand Cascade in - 操作數級聯。 設計工具支持
Achronix Tool Suite工具套件是一個支持所有Achronix硬件產品的工具鏈。它可與行業標準的邏輯綜合和仿真工具結合使用,從而使FPGA設計人員能夠輕松地將其設計映射到Speedster7t FPGA器件中。Achronix Tool Suite工具套件包括Synopsys的Synplify Pro的優化版本和Achronix Snapshot調試器。Achronix仿真庫由Siemens EDA的ModelSim、Synopsys的VCS和Aldec的Riviera-PRO提供支持。
展望:在推理等領域幫助開發者打造綜合性能優于先進GPU的應用
隨著AI/ML技術在各個領域開始廣泛走進應用,Achronix根據Speedster7t FPGA器件的高性能和高帶寬特性,選擇了推理這一個應用面非常廣的技術市場方向,與合作伙伴加大了在Speedster7t FPGA器件上的推理算法和IP的研發,以期幫助更多的創新者實現突破。
該芯片提供了足夠的算力,并利用其片上搭載的二維片上網絡(2D NoC)和機器學習處理單元(MLP),各種高速接口和GDDR6高帶寬存儲接口,提供了用于大規模推理應用需要的計算器件內外連接、硬件加速和存儲調用等新技術,從而可以支持開發者快速去實現創新。
這個策略取得了顯著的成果,其中一個領域是加速自動語言識別(ASR)解決方案,它由搭載Speedster7t FPGA器件的VectorPath加速卡提供支持,運行Myrtle.ai提供的基于Achronix FPGA的ASR IP,從而提供業界領先的、實時的、超低延遲的語音轉文本功能。運行在服務器中的單張VectorPath加速卡可替代多達20臺僅基于CPU的服務器或10張GPU加速卡。
Speedster7t FPGA的技術創新為人工智能推理帶來了更高性價比和更高能效比以及可以讓用戶開發自定義的推理硬件平臺和系統。 在ASR實際性能方面,其出色的超低單詞錯誤率和僅有最先進GPU解決方案八分之一以下的端到端延遲(包括了預處理和后處理以及與CPU做數據交互的時間)顛覆了ASR領域。該解決方案可以在標準的機器學習框架中使用垂直應用特定的或自定義的數據集進行定制或重新訓練。
對于越來越多的其他的推理應用,Speedster7t FPGA的獨創高帶寬架構也可以為這些應用提供有力的支撐。Achronix正在通過不斷研發,以完善其工具鏈和應用生態,將在2024年推出更好的工具來幫助各種推理應用的開發,使眾多的用戶更加便捷地使用Speedster7t FPGA器件或者VectorPath加速卡來實現性價比和能效提升,而不用去爭搶緊俏的高性能GPU加速卡。
審核編輯:劉清
-
人工智能
+關注
關注
1804文章
48677瀏覽量
246376 -
圖形處理器
+關注
關注
0文章
202瀏覽量
25969 -
機器學習
+關注
關注
66文章
8490瀏覽量
134069 -
FPGA器件
+關注
關注
1文章
22瀏覽量
11752 -
GDDR6
+關注
關注
0文章
52瀏覽量
11454
原文標題:新型的FPGA器件將支持多樣化AI/ML創新進程
文章出處:【微信號:Achronix,微信公眾號:Achronix】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
AlphaEvolve:一款基于Gemini的編程Agent,用于設計高級算法
【AI開發板】正點原子K230D BOX開發板來了!一款性能強悍且小巧便攜的AI開發板!
漢威科技集團推出Ai200邊緣計算網關,引領智慧監測新潮流
亞馬遜轉向Trainium芯片,全力投入AI模型訓練
一顆芯片面積頂4顆H200,博通推出3.5D XDSiP封裝平臺
Supermicro推出面向AI數據中心的液冷超級集群
NVIDIA DGX B200首次面向零售市場:配備8塊B200 GPU
基于Achronix Speedster7t FPGA器件的AI基準測試






 工商網監
工商網監
評論