 單日獲客成本超20萬,國產大模型開卷200萬字以上的長文本處理
單日獲客成本超20萬,國產大模型開卷200萬字以上的長文本處理
電子發燒友網報道(文/周凱揚)隨著AGI生態的蓬勃發展,各種支持多模態的大模型推陳出新,比如最近比較火的音樂大模型Suno和文生視頻大模型Sora等等。然而在傳統基于文本的大語言模型上,除了追求更快更精準的推理和高并發流量以外,似乎已經沒有太多值得廠商大肆宣傳的特性了,直到最近超長文本處理的爆火。
國產大模型的新卷法,長文本處理
當下將大模型長文本處理炒熱的,無疑是來自月之暗面的Kimi。作為去年發布的大模型,Kimi的主要賣點就是長文本,當時發布的初版Kimi,就已經支持到最多20萬漢字的輸入處理。
然而僅僅20萬字的文本處理,還不至于給用戶帶來質變的交互體驗,畢竟GPT-4 Turbo-128k已經支持到約合10萬漢字的長文本處理,谷歌的Gemini pro也支持到最多70萬個單詞的上下文,但不少長篇小說、專業書籍的字數要遠超這一數字。

Kimi支持200萬字上下文 / 月之暗面
Kimi在最近爆火源于一項重大迭代升級,月之暗面將長文本處理的字數限制擴展到200萬字,遠超Claude3、GPT-4 Turbo和Gemini Pro模型。在新功能推出和有效推廣下,Kimi很快涌入了一大批用戶,其app甚至短暫地沖進了蘋果App Store前五的位置。然而這樣也對Kimi的運營造成了不小的壓力,Kimi在上周經歷了多次宕機,這還是在月之暗面對服務器連續擴容的前提下。
面對競爭對手Kimi的用戶量激增,阿里巴巴和360很快就坐不住了。3月22日,阿里巴巴宣布通義千問將向所有用戶免費開放1000萬字的長文檔處理功能;3月23日,360智腦宣布正式內測500萬字長文本處理功能,且該功能即將入駐360 AI瀏覽器。
除了阿里巴巴和360外,目前國內訪問量第一的百度文心一言據傳也會在下月開放長文本處理功能,并計劃把字數上限提高至200萬甚至500萬字。
超長文本實現的技術難點和商業桎梏
盡管在用戶看來,阿里巴巴、360等廠商宣布支持超長文本處理好像是一件無需多少時間的易事,但實際上超長文本處理的實現存在不少技術痛點和商業成本問題。要知道在2022年,絕大多數的LLM上下文長度最多也只有2K,比如GPT-3。
直到GPT-4和Claude 2等,這些大模型才從架構上對文本長度進行了優化,可即便如此,主流的文本輸入長度依然不會超過100K。這也是因為對部分大模型而言,長文本不一定代表著更好的使用體驗,尤其是在查全率和準確率上。
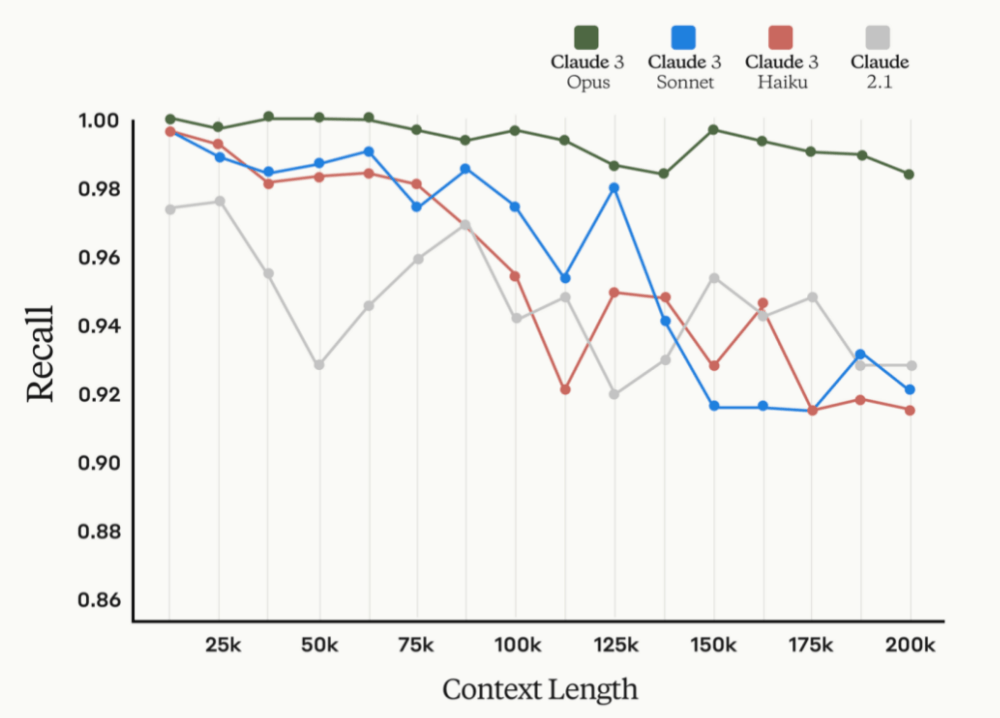
Claude的上下文長度和召回率關聯圖 / Anthropic
以Anthropic給出的數據為例,從上圖可以看出,隨著文本長度的增加,召回率是在逐步降低的,即便是最新的Claude3也是如此,而召回率代表了檢索出相關信息量占總量的比率。至于精確度,則與上下文中的事實位置存在很大的關系,如果用戶問題的事實存在于文本開頭或后半部分的位置,那么更容易得到精確的結果,而位于10%到50%之間位置的文本,則精確度急劇下降。
除此之外,長文本對于GPU和內存的資源消耗太大了,即便是小規模地擴展文本長度,動輒也要消耗100塊以上的GPU或TPU,這里指代的GPU還是A100這種單卡顯存容量高達40GB或80GB的設備。
這也是Kimi在經歷大量用戶訪問后,需要緊急擴容的原因。而阿里巴巴之所以能這么快開放長文本能力,也是憑借著手握龐大的服務器資源。至于Anthropic,我們從Claude3 Opus高昂的Tokens價格,也可以猜到其硬件成本絕對不低。
另外,在持續火爆一年之后,目前的大模型應用也難以單純靠技術立足市場吸引用戶了,商業推廣也已經成了必行之路。就以Kimi為例,在社交媒體上有關該應用的推廣可謂鋪天蓋地,很明顯對于新興的大模型應用而言,收獲第一批用戶才是至關重要的。
據傳Kimi在廣告投放上,吸引每位新用戶的花費在10元左右,而新用戶參與到使用中帶來的額外算力開銷在12元至13元左右。如果單單只是根據手機平臺app的下載量計算,那么Kimi的每日獲客成本至少為20萬人民幣,而這還未計算來自網頁端和小程序端的用戶。
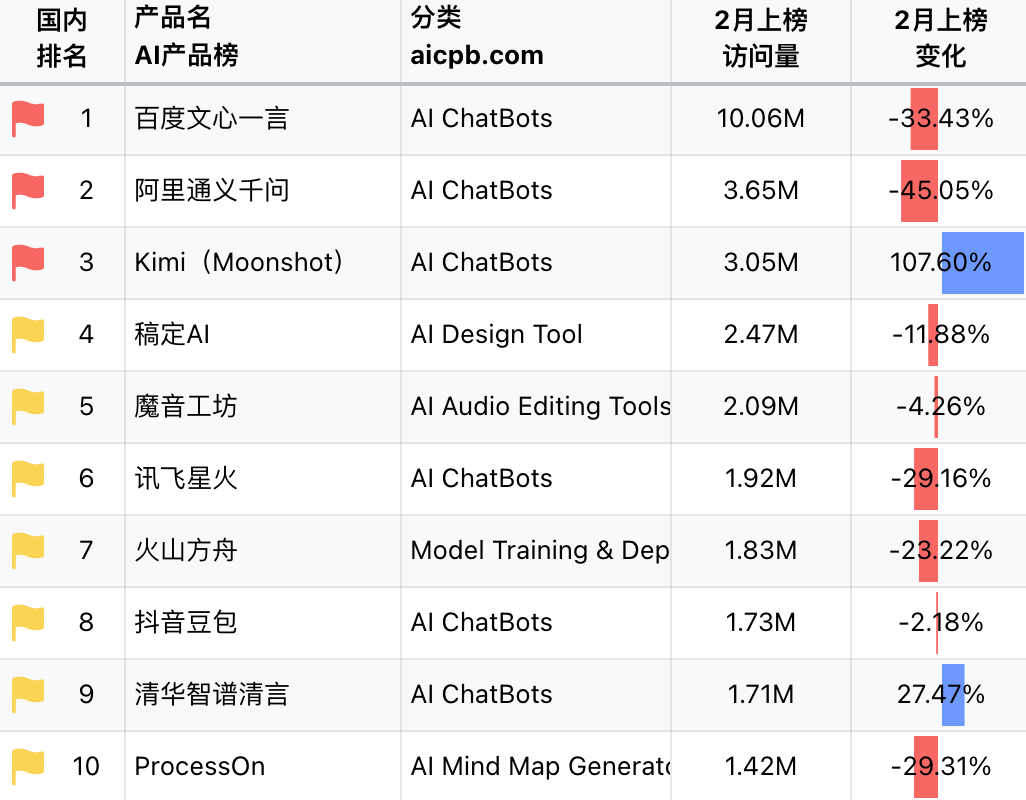
AI產品國內總榜 / AI產品榜
而且Kimi的推廣也不是從200萬長文本功能的推出才開始的,早在二月份Kimi就開始以長文本這一特性加強商業推廣了。從AI產品榜中可以看出,Kimi在2月的訪問量飆升,在國內總榜中僅次于百度文心一言和阿里通義千問,足見其在商業推廣和產品運營上都下了血本。但相對ChatGPT和New Bing之類的應用而言,其訪問量還是存在很大的差距。
這也充分說明了為何國外的大模型應用沒有去卷200K以上文本長度的原因,目前算力、準確度和長文本之間的沖突限制了他們去發展長文本。但這對于中國的大模型應用來說,反而是一個彎道超車的機會,因為大模型上的長文本能力確實帶來了用戶體驗上的改變。
長文本對于用戶體驗的改變
國產大模型為什么要去卷長文本,這是一個與大模型應用落地息息相關的問題。在過去,正是由于長文本能力不足,絕大多數大模型應用才會給人不堪大用的感覺,比如虛擬助手由于長文本能力不足,會遺忘重要信息;基于大模型來設計劇本殺等游戲規則時,上下文長度不夠只能在規則和設定上縮水,從而簡化游戲難度;在論文分析和法律法規解讀這樣的關鍵領域,更是因為缺乏長文本的支持,無法給到用戶精準的答案。
這與大模型卷參數規模不同,因為用戶已經發現了即便是70B這個量級的大模型,在面對用戶的問題時,也會出現胡編亂造的問題。反倒是長文本提供了更多的上下文信息,大模型在對語義進行分析判斷后,會提供更加精確的答案,所以不少用戶才會借助Kimi來分解長篇小說、總結論文等。
不過在享受長文本處理帶來便利的同時,我們也應該注意下長文本處理背后潛在的信息安全和版權問題。對于過去短文本的處理,就已經存在一些可能暴露用戶真實身份和隱私信息的問題,隨著長文本支持對于更大文件和更長文本的處理,有的人可能會選擇將合同、條例或標準等包含敏感信息的專業文件上傳到大模型上,又或是引入一些盜版文檔資源。
所以國家層面也開始出臺各種管理辦法,對于大模型語言模型在內的生成式人工智能進行規范,不能侵犯知識產權并保護個人隱私。如此一來,對于大模型應用本身的信息脫敏也提出了更高的要求。
寫在最后
相信經過一年的大模型應用轟炸后,不少用戶對于基本的AGI玩法已經玩膩了,所以長文本、文生視頻這種新的交互方式才會讓人趨之若鶩。但我們也很少看到成功的長文本大模型商業化落地項目,畢竟在高額的獲客成本下,RAG這種外掛知識庫的方式可能更適合手中資金有限的初創AGI應用開發商。
-
Agi
+關注
關注
0文章
91瀏覽量
10434 -
大模型
+關注
關注
2文章
3030瀏覽量
3832 -
LLM
+關注
關注
1文章
320瀏覽量
684
發布評論請先 登錄
Linux中文本處理命令的用法
國產首款量產型七位半萬用表!青島漢泰開啟國產高精度測量新篇章。
RK3588開發板上部署DeepSeek-R1大模型的完整指南
飛凌RK3588開發板上部署DeepSeek-R1大模型的完整指南(一)

了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
BQ3588/BQ3576系列開發板深度融合DeepSeek-R1大模型
BQ3588/BQ3576系列開發板成功部署 DeepSeek-R1開發板

阿里云通義開源長文本新模型Qwen2.5-1M

Linux三劍客之Sed:文本處理神器

如何掌握Linux文本處理
Llama 3 模型與其他AI工具對比
中國電信人工智能研究院完成首個全國產化萬卡萬參大模型訓練
萬字長文淺談系統穩定性建設





 工商網監
工商網監
評論