") 自動(dòng)駕駛中多模態(tài)下的Freespace檢測輕量化設(shè)計(jì)實(shí)現(xiàn)
自動(dòng)駕駛中多模態(tài)下的Freespace檢測輕量化設(shè)計(jì)實(shí)現(xiàn)
Freespace檢測是駕駛場景理解的一部分,它將圖像中的每個(gè)像素分類為可駕駛或不可駕駛區(qū)域,通常通過圖像分割算法來實(shí)現(xiàn)。自動(dòng)駕駛系統(tǒng)中的其他模塊受益于這些像素級(jí)分割結(jié)果,例如軌跡預(yù)測和路徑規(guī)劃,以確保自動(dòng)駕駛車輛在復(fù)雜環(huán)境中可以進(jìn)行安全導(dǎo)航。近年來,多模態(tài)數(shù)據(jù)融合卷積神經(jīng)網(wǎng)絡(luò)(CNN)架構(gòu)極大地提高了自由空間檢測算法的性能。為了實(shí)現(xiàn)穩(wěn)健且準(zhǔn)確的場景理解,自動(dòng)駕駛車輛通常配備不同的傳感器,并且多種傳感模式可以通過其互補(bǔ)性進(jìn)行融合。在多模態(tài)學(xué)習(xí)中,模態(tài)可以根據(jù)融合級(jí)別從下到上進(jìn)行組合。

然而,這種多模態(tài) CNN 具有高數(shù)據(jù)吞吐量并包含大量計(jì)算密集型卷積計(jì)算,限制了其實(shí)時(shí)應(yīng)用的可行性。高階智駕車載運(yùn)算單元HPC為這些問題提供了靈活性、性能和低功耗的獨(dú)特組合,以適應(yīng)多模態(tài)數(shù)據(jù)和不同壓縮算法的計(jì)算加速。網(wǎng)絡(luò)輕量級(jí)方法為促進(jìn) CNN 在此類資源上的部署提供了極大的保證。
在本文中,介紹了一種用于多模態(tài)自由空間Freespace檢測算法的網(wǎng)絡(luò)輕量級(jí)方法。首先,通過設(shè)置HPC中擅長的算子進(jìn)行運(yùn)算,同時(shí)對(duì)神經(jīng)網(wǎng)絡(luò)進(jìn)行兩部分有效的剪枝,以減少參數(shù)數(shù)量,以防完整模型超出HPC芯片內(nèi)存。然后,根據(jù)低秩特征圖包含較少信息的原則提出了數(shù)據(jù)相關(guān)的過濾器剪枝器。對(duì)于特征提取器來說,為了不損害多模態(tài)信息的完整性,剪枝器對(duì)于每種模態(tài)都是獨(dú)立的。對(duì)于分段解碼器,應(yīng)用通道修剪方法來刪除冗余參數(shù)。
詳細(xì)神經(jīng)網(wǎng)絡(luò)訓(xùn)練到底需要多大的計(jì)算量?
強(qiáng)大的骨干網(wǎng)絡(luò)表現(xiàn)更好的分割特征。基于 U-Net的模型將較低級(jí)別的特征作為跳躍連接到特征圖,以預(yù)測更詳細(xì)的輸出。最近的研究主要集中在語義分割模型中的非局部操作,以消除特征圖中的噪聲。這些方法使用參數(shù)極大的變壓器來確保網(wǎng)絡(luò)學(xué)習(xí)語義之間的相關(guān)性,具有高精度結(jié)果的特點(diǎn)。后來,逐漸引入結(jié)合多模態(tài)數(shù)據(jù)的幾何信息的方法來解決這個(gè)分割問題。早期的工作將深度轉(zhuǎn)換為單通道圖像,并使用早期融合將深度和 RGB 簡單地連接起來作為四通道圖像輸入。另一種三通道深度編碼,包括水平視差、離地高度和法線角。在其他研究中,RGB和HHA圖像被輸入到兩個(gè)DCNN中分別提取特征,最后使用中間融合來進(jìn)行連接。
自由空間檢測網(wǎng)絡(luò)采用經(jīng)典的編碼器-解碼器架構(gòu)構(gòu)建,如圖1所示。
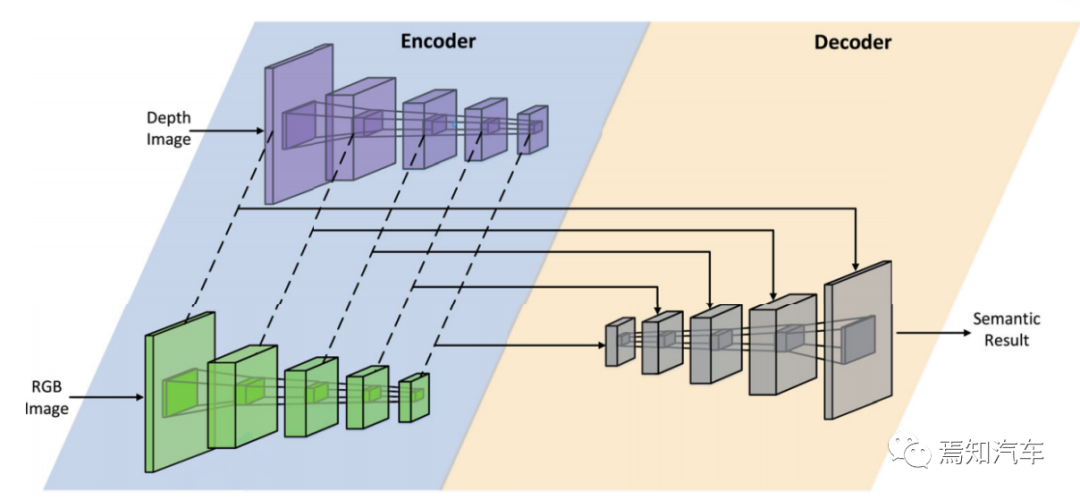
圖 1.輕量級(jí)多模態(tài)自由空間檢測網(wǎng)絡(luò)。采用編碼器-解碼器架構(gòu),網(wǎng)絡(luò)的輸入是一對(duì) RGB 和深度圖像。由殘差網(wǎng)ResNets編碼器進(jìn)行處理,多模態(tài)融合策略是特征圖的串聯(lián), U 形分割解碼器被傳播用于最終預(yù)測。
與軟件平臺(tái)不同,硬件構(gòu)建的卷積計(jì)算資源在程序過程中無法釋放。這意味著實(shí)現(xiàn)的算子越少對(duì)資源的利用就越好。常見的圖像編碼器包括 VGG 、Deeplab 、mobilenet、ResNet等。VGG采用堆疊3×3卷積,但由于梯度消失問題,網(wǎng)絡(luò)較淺,很難達(dá)到高精度。Deeplab取得了不錯(cuò)的效果,但空間金字塔結(jié)構(gòu)包含多種空洞卷積算子,多尺度融合時(shí)會(huì)產(chǎn)生較大的特征張量,很難實(shí)現(xiàn)。Mobilenet是一個(gè)輕量級(jí)網(wǎng)絡(luò),它使用深度可分離卷積來減少3×3卷積的參數(shù),但代價(jià)是計(jì)算步驟的增加和低維特征的細(xì)節(jié)損失。ResNet通過捷徑連接大大增加網(wǎng)絡(luò)深度,具有很強(qiáng)的特征提取能力,基本只由3×3卷積和1×1組成卷積,這是我們編碼器的首選。
如下圖所示,卷積分解涉及殘差網(wǎng)絡(luò)ResNet中的計(jì)算有1×1卷積、3×3卷積、7×7卷積和快捷級(jí)聯(lián)。
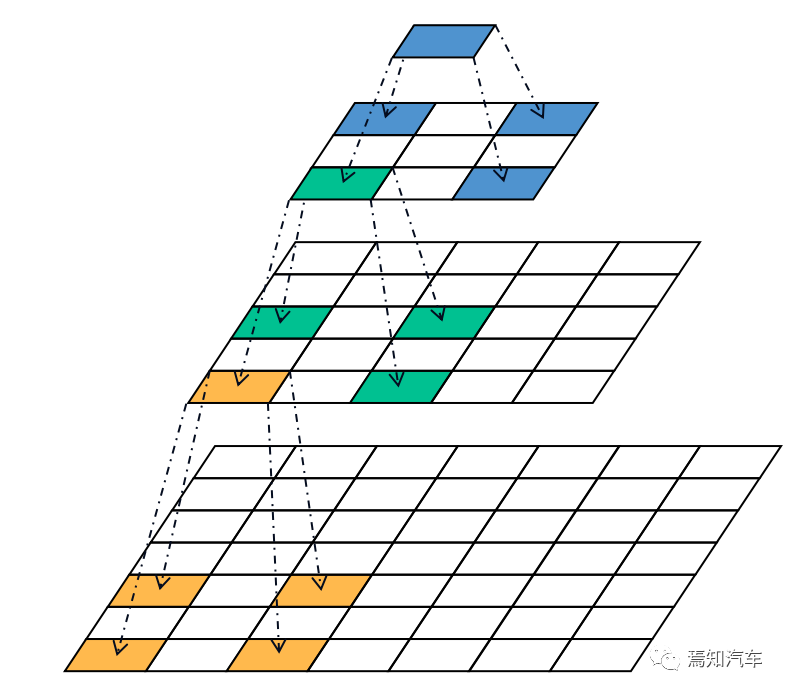
圖2. 用 3 × 3 卷積替換 7 × 7 卷積
需要注意的是,車載域控中的級(jí)聯(lián)運(yùn)算只需通過內(nèi)存調(diào)度即可實(shí)現(xiàn),無需計(jì)算單元的參與。因此,7×7卷積的計(jì)算量是最大的。同時(shí),該卷積僅在第一層中出現(xiàn)一次,并且隨后不會(huì)重復(fù)使用,這導(dǎo)致我們產(chǎn)生了對(duì)其進(jìn)行優(yōu)化的想法。與 7 × 7 空間濾波器的卷積意味著該操作的感受野是 7 × 7。不改變大小的感受野,我們?cè)噲D找到一個(gè)具有更小的卷積核的多層網(wǎng)絡(luò)來代替這個(gè)操作。卷積層的理論感受野可以通過遞歸公式計(jì)算:
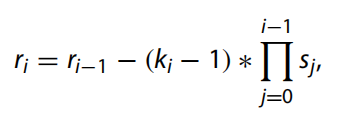
其中 r 是感受野,k 是內(nèi)核大小,s 是步幅。假設(shè)特征圖的長度和寬度都是x(x >= 7)。我們使用 7 × 7 卷積核以 1 的步長進(jìn)行滑動(dòng),這需要 (x ? 7 + 1) 次滑動(dòng)。垂直方向同樣,滑動(dòng)(x ? 7 + 1)次,因此有(x ? 6) ? (x ? 6)次卷積計(jì)算,其中感受野的大小為(x ? 6) ? (x ? 6) 6)。同理,3×3卷積后的輸出大小為(x?3+1)*(x?3+1)。在輸出圖上再使用兩個(gè) 3 × 3 卷積來獲得感受野 (x ? 3 + 1 ? 3 + 1 ? 3 + 1) ? (x ? 3 + 1 ? 3 + 1 ? 3 + 1) = (x ? 3 + 1) 6)*(x-6),等于7×7卷積結(jié)果。因此,可以得出結(jié)論,3個(gè)3×3卷積和1個(gè)7×7卷積具有相同的特征提取能力。
3 × 3 卷積的運(yùn)算量為 9 次,7 × 7 卷積的運(yùn)算量為 49 次。對(duì)于長寬均為 x 的圖像,3 個(gè) 3 × 3 卷積和 1 個(gè) 7 × 7 卷積的計(jì)算量為 O3 = 9 ?(x?2)2+9*(x?4)2+9*(x?6)2 和 O7=49*(x?6)2 分別。計(jì)算O3<=O7,可以得到x>12,這意味著對(duì)于大于12×12的圖像,三層3×3卷積在參數(shù)數(shù)量和計(jì)算量上都具有優(yōu)勢。對(duì)于Resnet的第一層,輸入是原始圖像,遠(yuǎn)大于12×12,因此使用三層3×3卷積而不是7×7卷積總是性能更好。本文設(shè)計(jì)的優(yōu)化加速7×7卷積層如圖3(a)所示。
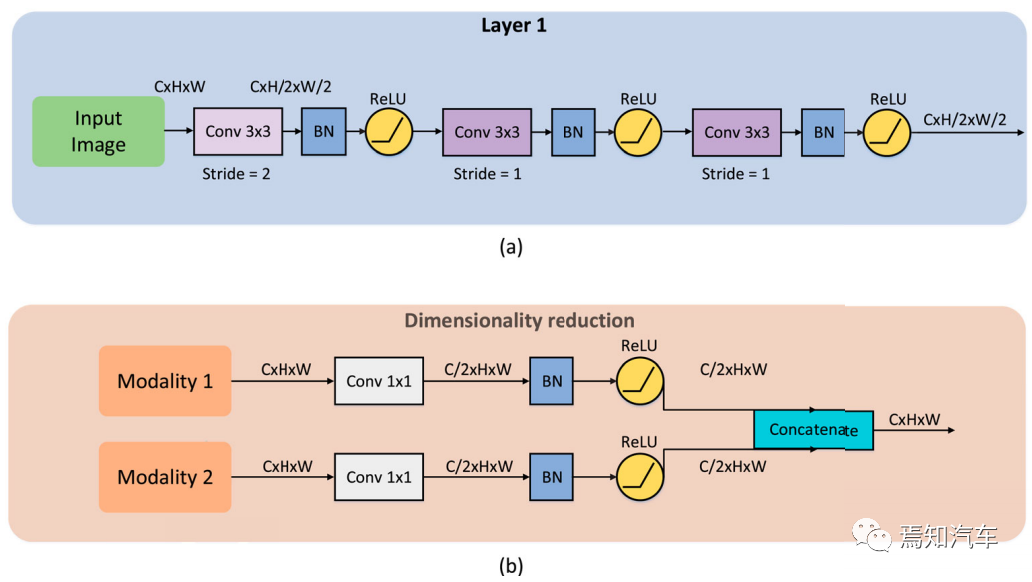
圖 3.(a) 優(yōu)化加速 7 × 7 卷積層的細(xì)節(jié)。(b) 大特征降維的細(xì)節(jié)
實(shí)際上,在語義分割模型中,網(wǎng)絡(luò)越深,感受野越大,但解碼器中丟失的信息也越多。因此,邊緣特征的檢索極其重要。U-Net采用跳躍連接的方法,將編碼器中的同級(jí)特征圖與反卷積層的恢復(fù)結(jié)果進(jìn)行融合,實(shí)現(xiàn)邊緣特征的檢索。參考這種U形結(jié)構(gòu),我們將多模態(tài)同層特征連接到skip連接,同時(shí)將它們用于反卷積層的計(jì)算。缺點(diǎn)是級(jí)聯(lián)后的特征張量會(huì)很厚。以KITTI數(shù)據(jù)集為例,原始圖像的大小為1392×512,四次下采樣后的特征圖大小為87×32,ResNet-50第4層特征圖的維度為1024。所以特征張量的大小連接后的雙模網(wǎng)絡(luò)的大小為 87 × 32 × 3072,占用約 8.13 Mb的RAM。雖然這size在可接受的范圍內(nèi),但是需要占用了一半以上的內(nèi)存空間,這使得設(shè)備無法運(yùn)行雙批并行。這是浪費(fèi),所以我們使用兩個(gè) 1 × 1 卷積層降低融合特征的維數(shù)如上圖3(b)所示。
整個(gè)輕量級(jí)自由空間檢測網(wǎng)絡(luò)采用ResNet-50作為主干,U-net作為分割頭,并采用級(jí)聯(lián)作為特征融合方法,有效保持了網(wǎng)絡(luò)的復(fù)雜度和特征提取能力。該輕量級(jí)網(wǎng)絡(luò)僅包含3×3卷積和1×1卷積兩個(gè)卷積算子,大大節(jié)省了HPC上的計(jì)算資源。同時(shí),對(duì)算法中間結(jié)果的大小進(jìn)行精確控制,使算法能夠在HPC內(nèi)部進(jìn)行多批次并行處理,避免了外部數(shù)據(jù)交換帶來的延遲。
為何要進(jìn)行模型剪枝?
剪枝是一種基于 CNN 過度參數(shù)化的神經(jīng)網(wǎng)絡(luò)消除不必要權(quán)重的技術(shù)。作為一種機(jī)器學(xué)習(xí)方法,CNN可以分為兩個(gè)階段:訓(xùn)練和推理。
訓(xùn)練階段,需要根據(jù)數(shù)據(jù)學(xué)習(xí)必要的模型參數(shù);在推理階段,新的數(shù)據(jù)被輸入到模型中,經(jīng)過計(jì)算得到結(jié)果。過度參數(shù)化則意味著訓(xùn)練階段有大量參數(shù)來捕獲數(shù)據(jù)集中的信息。一旦訓(xùn)練完成到推理階段,這些參數(shù)大部分都是冗余的,這意味著可以在部署之前對(duì)網(wǎng)絡(luò)進(jìn)行剪枝。網(wǎng)絡(luò)剪枝有很多好處,最直接的一個(gè)是減少大量計(jì)算,從而減少計(jì)算時(shí)間和功耗。更小的內(nèi)存占用還允許算法在低端設(shè)備上運(yùn)行,例如用更快、更省電的 SRAM 取代 DRAM。最后,較小的包大小有利于模型更新,使產(chǎn)品升級(jí)更加方便。根據(jù)剪枝特征的粒度,剪枝技術(shù)可以分為權(quán)重剪枝和過濾剪枝。早期的方法基于權(quán)重剪枝,剪枝的粒度就是權(quán)重核,剪枝后的核是填充零元素的稀疏矩陣。在當(dāng)今硬件的支持下,利用現(xiàn)有的基本線性代數(shù)子程序(BLAS)庫無法對(duì)稀疏矩陣進(jìn)行優(yōu)化,因此剪枝模型很難獲得實(shí)質(zhì)性的性能提升。因此,近年來的研究主要集中在過濾器剪枝上。存在不同粒度的過濾器修剪,例如基于過濾器、基于通道、基于塊和基于層。由于過濾器剪枝不會(huì)改變權(quán)重矩陣的稀疏性,因此現(xiàn)有的計(jì)算平臺(tái)和框架可以很好地支持它。
本文主要關(guān)注濾波器剪枝來實(shí)現(xiàn)模型壓縮和加速,旨在為HPC提供通用的解決方案。典型的神經(jīng)網(wǎng)絡(luò)剪枝框架是訓(xùn)練、剪枝和微調(diào)。
如何根據(jù)濾波器剪枝評(píng)估函數(shù)刪除參數(shù)?
濾波器剪枝是通過去除特征提取能力較弱的卷積核,使網(wǎng)絡(luò)稀疏來加速的方法。該方法可以大大減少網(wǎng)絡(luò)中的參數(shù)。重新訓(xùn)練剪枝后的模型,精度可以很快恢復(fù)。該過程可分為五個(gè)步驟。步驟1是用數(shù)據(jù)集訓(xùn)練整個(gè)網(wǎng)絡(luò),生成初始網(wǎng)絡(luò)模型文件。步驟2記錄第一層卷積核的權(quán)重分布,并根據(jù)卷積核的重要性設(shè)置剪枝率。步驟3,根據(jù)剪枝率刪除對(duì)網(wǎng)絡(luò)性能影響較小的卷積核和特征圖之間的對(duì)應(yīng)關(guān)系。步驟 4 是重新訓(xùn)練網(wǎng)絡(luò)以恢復(fù)性能損失。步驟5,逐層重復(fù)上述過程,進(jìn)行剪枝和微調(diào),直至輸出剪枝后的網(wǎng)絡(luò)模型文件。
當(dāng)前,眾多研究專注于修剪過濾器的細(xì)粒度權(quán)重。先前有人提出了一種迭代方法來丟棄值低于預(yù)定義閾值的小權(quán)重值,同時(shí),將剪枝表述為一個(gè)優(yōu)化問題,即找到最小化損失的權(quán)重,同時(shí)滿足剪枝成本條件。然而,通過權(quán)值剪枝得到的稀疏矩陣不支持相應(yīng)的加速操作。
與權(quán)重剪枝相反,過濾器剪枝是根據(jù)某些指標(biāo)刪除整個(gè)過濾器。它是加速超參數(shù)化 CNN 最流行的方法之一,因?yàn)樾藜艉蟮纳疃染W(wǎng)絡(luò)可以直接應(yīng)用于任何現(xiàn)成的平臺(tái)和硬件上以獲得在線加速,從而使一些與數(shù)據(jù)無關(guān)的過濾器剪枝策略得到進(jìn)一步探索。一些有效的方法包括利用 l1-范數(shù)標(biāo)準(zhǔn)可以修剪不重要的過濾器。而使用 l2-范數(shù)標(biāo)準(zhǔn)可以有效的選擇濾波器,并以軟方式修剪這些選定的濾波器,隨后又有人提出通過對(duì)批量歸一化層的縮放參數(shù)實(shí)施稀疏性來修剪模型,在濾波器上使用譜聚類來選擇不重要的濾波器。還有一些論文甚至提出了通過幾何中值進(jìn)行過濾器剪枝來壓縮模型。而這些過濾器剪枝方法需要利用訓(xùn)練數(shù)據(jù)來確定修剪后的過濾器。進(jìn)而,采用下一層的統(tǒng)計(jì)信息來指導(dǎo)過濾器的選擇。旨在通過最小化訓(xùn)練集樣本激活的重建誤差來獲得分解。還有提出了一種本質(zhì)上由數(shù)據(jù)驅(qū)動(dòng)的方法,該方法使用主成分分析 (PCA) 來指定應(yīng)保留的能量比例。將子空間聚類應(yīng)用于特征圖,以消除卷積濾波器中的冗余。此外,也有開發(fā)一種經(jīng)過數(shù)學(xué)公式化的方法,用于修剪具有低秩特征圖的過濾器。
剪枝濾波器評(píng)價(jià)函數(shù)
使用低學(xué)習(xí)率用額外的時(shí)期來訓(xùn)練網(wǎng)絡(luò),以便網(wǎng)絡(luò)有機(jī)會(huì)從性能損失中恢復(fù)。一般來說,最后兩步是迭代的,每次迭代都會(huì)增加剪枝率。剪枝器的核心在于選擇剪枝濾波器評(píng)價(jià)函數(shù),其目標(biāo)是在最高壓縮比下實(shí)現(xiàn)較小的精度損失。根據(jù)是否利用訓(xùn)練數(shù)據(jù)來確定剪枝濾波器,濾波器剪枝可以分為數(shù)據(jù)相關(guān)型和數(shù)據(jù)無關(guān)型。
1)與數(shù)據(jù)無關(guān)的剪枝方法是基于網(wǎng)絡(luò)的固有權(quán)重,不依賴于輸入數(shù)據(jù)。剪枝后,需要進(jìn)行微調(diào)以恢復(fù)精度。典型的方法包括 L1 或 L2 范數(shù)、一階梯度度量、特征圖的秩和網(wǎng)絡(luò)層中的幾何中值。這些濾波器具有時(shí)間復(fù)雜度低的優(yōu)點(diǎn),但在精度和壓縮比方面存在局限性。
2)數(shù)據(jù)相關(guān)剪枝的方法是在輸入數(shù)據(jù)中添加額外的正則項(xiàng),使其稀疏,并將剪枝嵌入到訓(xùn)練過程中,使數(shù)據(jù)流在網(wǎng)絡(luò)訓(xùn)練過程中提出更好的剪枝策略。該類別屬于 BN 層中的縮放因子和掩蔽結(jié)構(gòu)稀疏參數(shù)等方法。這些直接向網(wǎng)絡(luò)添加稀疏約束的方法通常會(huì)比第一種方法取得更好的效果。
在多模態(tài)學(xué)習(xí)中,模型通常支持多個(gè)數(shù)據(jù)輸入,這使得數(shù)據(jù)對(duì)網(wǎng)絡(luò)產(chǎn)生顯著影響。因此,我們更喜歡依賴數(shù)據(jù)的過濾器剪枝作為評(píng)估函數(shù)。
優(yōu)化網(wǎng)絡(luò)學(xué)習(xí)算法進(jìn)行模型訓(xùn)練
高效的自由空間檢測算法對(duì)于智駕系統(tǒng)的部署非常重要。然而,很少有工作討論用于自由空間檢測任務(wù)的語義分割神經(jīng)網(wǎng)絡(luò)的修剪。針對(duì)分類任務(wù)設(shè)計(jì)的修剪方法已直接應(yīng)用于分割神經(jīng)網(wǎng)絡(luò),且在ImageNet上的主干網(wǎng)絡(luò)中修剪過濾器并將其轉(zhuǎn)移到分割網(wǎng)絡(luò)。
本文介紹了一種多任務(wù)通道修剪以獲得輕量級(jí)語義分割網(wǎng)絡(luò)。
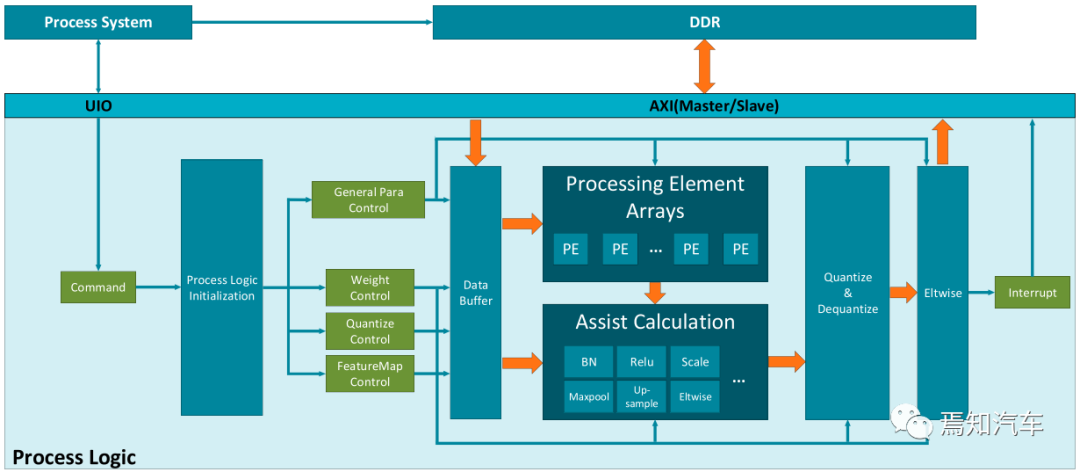
假設(shè) Ci 是預(yù)訓(xùn)練 CNN 模型的第 i 個(gè)卷積層。Ci 中的權(quán)重可以表示為 WCi = {w1, w2, ... , wni} ε Rni×ni?1×ki×ki,其中 ni 代表數(shù)字Ci 和 ki 中的濾波器數(shù)量表示內(nèi)核大小。輸入特征圖表示為 Xi ={x1, x2, ... , xni}εRb×ni?1×hi×wi,其中 b 是批量大小,hi 和 wi 是特征圖的高度和寬度。過濾器剪枝旨在識(shí)別并刪除不太重要的權(quán)重從 WCi 設(shè)置,可以將其表述為優(yōu)化問題:
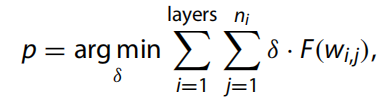
其中 F() 衡量 CNN 中權(quán)重的重要性。δ是一個(gè)過濾器,如果 wi,j 重要,則為 1;如果 wi,j不重要,則為 0。最小化 p 就是去除 Ci 中最不重要的權(quán)重。
編碼器剪枝:我們的關(guān)鍵問題在于設(shè)計(jì)一個(gè)能夠很好地反映多模態(tài)特征信息豐富度的函數(shù)F()。由于不同模態(tài)的特征圖相對(duì)獨(dú)立,大多數(shù)直接基于網(wǎng)絡(luò)權(quán)重設(shè)計(jì)F()的剪枝方法都會(huì)集中于某種模態(tài),這導(dǎo)致算法忽略了重要的跨模態(tài)信息。因此,對(duì)于編碼器,我們建議根據(jù)每個(gè)獨(dú)立模態(tài)的特征圖來定義 F(),因?yàn)樘卣鲌D是可以反映濾波器屬性和輸入圖像的中間步驟。
因此,優(yōu)化函數(shù) p 重新表述為:
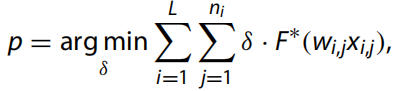
其中 F*() 估計(jì) wi,j 和 xi,j 生成的特征圖的信息。特征圖包含的信息越多,相應(yīng)的濾波器就越重要。
矩陣的秩是不相關(guān)的行或列向量的數(shù)量。對(duì)于圖像的矩陣來說,秩可以表示圖像中的信息冗余程度和信息量。我們對(duì)圖像 xi,j 執(zhí)行奇異值分解 (SVD):
其中 R 是輸入特征圖的秩,σi、ui 和 vi 是奇異值。具有等級(jí)R的特征圖可以分解為具有等級(jí)R和附加信息的較低等級(jí)的特征圖,這表明較高等級(jí)的特征圖比較低等級(jí)的特征圖包含更多信息。它不僅可以作為信息的有效度量,而且可以作為穩(wěn)定的表示。因此,我們將信息測量定義為:
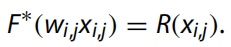
解碼器剪枝:由于編碼器和解碼器網(wǎng)絡(luò)中的縮放因子是交替優(yōu)化的,因此為骨干網(wǎng)絡(luò)和解碼器設(shè)置相同的全局閾值是不合適的。無需考慮中間結(jié)果的影響,在解碼器上應(yīng)用傳統(tǒng)的剪枝方法足以去除冗余參數(shù)。我們根據(jù)卷積核的 L1 范數(shù)對(duì)它們進(jìn)行排序:
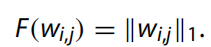
我們?yōu)槊總€(gè)通道引入一個(gè)縮放因子,該因子乘以該層的輸出。然后,我們聯(lián)合訓(xùn)練網(wǎng)絡(luò)權(quán)重和這些縮放因子,并對(duì)它們進(jìn)行稀疏正則化。最后,我們用小因素修剪這些通道并對(duì)修剪后的網(wǎng)絡(luò)進(jìn)行微調(diào)。由于剪枝對(duì)應(yīng)于刪除該層的所有輸入和輸出,因此我們可以直接獲得一個(gè)狹窄的網(wǎng)絡(luò)。縮放因子充當(dāng)權(quán)重選擇并與權(quán)重共同優(yōu)化,網(wǎng)絡(luò)可以自動(dòng)識(shí)別不重要的通道并安全地刪除它們,而不會(huì)極大地影響泛化性能。
最后一步:量化和層融合
8位量化:我們的量化策略是在網(wǎng)絡(luò)訓(xùn)練中使用浮點(diǎn)計(jì)算,在推理中使用整數(shù)計(jì)算。量化的目標(biāo)是僅使用整數(shù)計(jì)算來完成所有算術(shù)運(yùn)算。它是通過實(shí)數(shù)值r和整數(shù)值q之間的仿射變換來實(shí)現(xiàn)的:
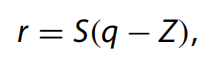
其中 Z 是量化零點(diǎn),它是常數(shù)。r 是要量化的真實(shí)值,通常是 32 位浮點(diǎn)數(shù)。對(duì)于B位量化,q是B位的整數(shù)。在本文中,我們?cè)O(shè)置B = 8。S是量化尺度,通過計(jì)算整個(gè)數(shù)組的最大值和最小值來計(jì)算:
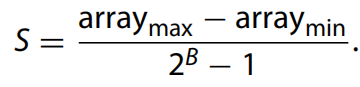
Z是量化零點(diǎn),表示q相對(duì)于0的偏差,與q是相同的數(shù)據(jù)類型。
量化層融合:一般CNN中的一層由卷積、BN和ReLU組成。由于推理過程中所有參數(shù)都是恒定的,這些計(jì)算的融合可以大大減少參數(shù)的數(shù)量。由于批量歸一化,卷積計(jì)算可以設(shè)置為無偏的。
因此,卷積可以表示為:
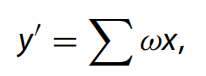
其中ω是權(quán)重,x是輸入特征,y是卷積結(jié)果。將如上方程量化,其中 x = Sx(qx ? Zx) 和 ω = Sω(qω ? Zω),卷積等效于:
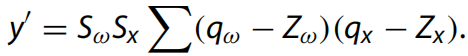
批量歸一化(BN)廣泛用于解決內(nèi)部協(xié)變量偏移問題。BN在推理過程中的計(jì)算可以概括為歸一化和縮放的結(jié)合:
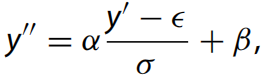
其中?是均值,σ是方差,α是尺度,β是平移。然后我們就有了量化的BN:
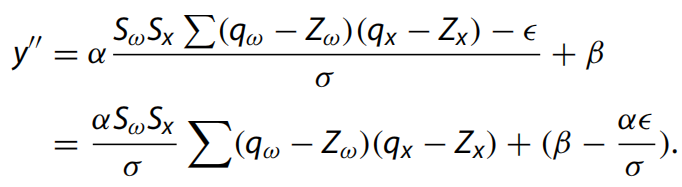
卷積運(yùn)算后接非線性激活單元,通過非線性激活函數(shù)處理上一層的線性輸出,模擬任意函數(shù),從而增強(qiáng)網(wǎng)絡(luò)的表示能力。ReLU 是分段線性函數(shù),這是最常用的激活層。ReLU算子可表示為:
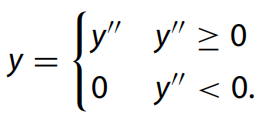
輸出y也應(yīng)量化為 y = Sy(qy ? Zy)。因此當(dāng) y’’≥0 時(shí),那么我們的量化結(jié)果為:
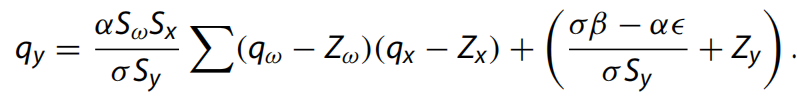
當(dāng) y’’< 0 時(shí):
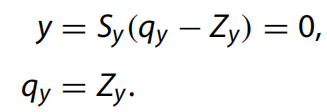
最后,得到量化卷積層參數(shù)公式如下:
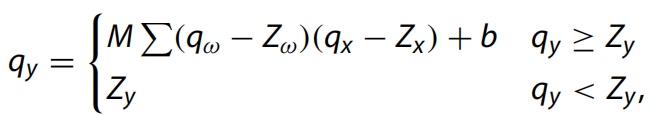
其中M、b、Zx、Zω和Zy是五個(gè)常數(shù),可以在推理前離線計(jì)算。融合卷積層大大減少了推理中的計(jì)算步驟,進(jìn)一步加速了網(wǎng)絡(luò)。
總結(jié)
對(duì)于自動(dòng)駕駛汽車來說,自由空間檢測是視覺感知的重要組成部分。近年來,隨著多模態(tài)卷積神經(jīng)網(wǎng)絡(luò)(CNN)的發(fā)展,駕駛場景語義分割算法的性能得到了顯著提高。因此,大多數(shù)自由空間檢測算法都是基于多個(gè)傳感器開發(fā)的。
本文介紹的算法首先引入一種輕量級(jí)多模態(tài)自由空間檢測網(wǎng)絡(luò),具有較少的卷積算子和較小的特征圖。然后通過濾波器剪枝和8位量化來減少模型的參數(shù)。最后將該模型移植到車載域控上,使其能夠在低功耗器件中進(jìn)行獨(dú)立預(yù)測。
審核編輯:劉清
-
濾波器
+關(guān)注
關(guān)注
162文章
8076瀏覽量
181049 -
編解碼器
+關(guān)注
關(guān)注
0文章
272瀏覽量
24646 -
自動(dòng)駕駛
+關(guān)注
關(guān)注
788文章
14203瀏覽量
169561 -
卷積神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
4文章
369瀏覽量
12199
原文標(biāo)題:自動(dòng)駕駛中多模態(tài)下的Freespace檢測到底如何實(shí)現(xiàn)輕量化
文章出處:【微信號(hào):阿寶1990,微信公眾號(hào):阿寶1990】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
未來已來,多傳感器融合感知是自動(dòng)駕駛破局的關(guān)鍵
FPGA在自動(dòng)駕駛領(lǐng)域有哪些應(yīng)用?
谷歌的自動(dòng)駕駛汽車是醬紫實(shí)現(xiàn)的嗎?
【話題】特斯拉首起自動(dòng)駕駛致命車禍,自動(dòng)駕駛的冬天來了?
自動(dòng)駕駛真的會(huì)來嗎?
自動(dòng)駕駛的到來
UWB主動(dòng)定位系統(tǒng)在自動(dòng)駕駛中的應(yīng)用實(shí)踐
如何讓自動(dòng)駕駛更加安全?
自動(dòng)駕駛汽車的處理能力怎么樣?
自動(dòng)駕駛汽車中傳感器的分析
自動(dòng)駕駛技術(shù)的實(shí)現(xiàn)
LabVIEW開發(fā)自動(dòng)駕駛的雙目測距系統(tǒng)
自動(dòng)駕駛深度多模態(tài)目標(biāo)檢測和語義分割:數(shù)據(jù)集、方法和挑戰(zhàn)

端到端自動(dòng)駕駛多模態(tài)軌跡生成方法GoalFlow解析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論