 數據中心CPU芯粒化及互聯方案分析-PART2
數據中心CPU芯粒化及互聯方案分析-PART2
隨著生成式AI注入數據中心的步伐加快,CPU 在數據中心的部署變得愈發重要,為應對數據中心CPU性能提升挑戰,Chiplet和互聯技術的雙劍合璧,經芯片巨頭在自身產品體系中的多次實踐,顯現出蓬勃的生機和其普適性的一面。
2023年1月,英特爾第四代至強可擴展處理器Sapphire Rapids(SPR)首次亮相。SPR是一款專門針對AI工作負載優化的CPU,具有典型的Multi-Die架構,其亮點包括更高的核心數量、改進的緩存層次結構以及增強的互聯技術。對英特爾來說,它也是劍指AMD EPYC,意在奪回HPC市場的野心之作。
更多的核心,更強的性能

英特爾稱,ERP整體性能和每瓦性能指標均處于領先地位。與前一代處理器相比,基礎算力提升53%,人工智能性能提升10倍,5G vRAN性能提升2倍,網絡&存儲性能提升2倍,數據分析性能提升3倍,科學計算性能提升3.7倍。如此卓越的性能提升主要來自核心數量的大幅增長,以及高效的互聯方案。

1、50%核心數量增長+單核性能增強
SPR是英特爾首個Chiplet設計的Xeon處理器,由四個相同的die(芯粒)組成,die間通過英特爾的EMIB技術連接。其中,每個Die包含15個CPU內核,并分別配有自己的內存和IO控制器等各功能單元。核心部分為英特爾7工藝的Golden Cove P核(大核),設計支持60核,實際啟用56核,總核心數較上一代IceLake增長了50%。

SPR延續了英特爾的服務器處理器策略:優先考慮擴展核心數量,同時提供強大的計算能力,以大幅提高CPU在處理大量數據,如進行科學計算、機器學習、圖形處理時的性能。
最終,SPR實現了105MB Total LLC,307GB/s Memory Bandwidth,在SPECrate@2017_int_base基準測試中,得分為495。
如前文所述,除了CPU核數提升之外,SPR在CPU單核性能上也做了優化,如提高了CPU的各級緩存的大小,還為每個核心引入了兩個512位的FMA單元,同時支持一級對AMX指令集,旨在進一步提升性能。
2:優化緩存層次結構
除了核心性能的優化,Golden Cove的一項重大改進是緩存層次結構,這也是SPR與AMD EPYC系列的顯著區別之一:每個Golden Cove核心除了包2MB L2緩存外,還搭載了1.875MB的LLC切片,每個Die總28.125M LLC為56個核心所共享(SPR總緩存達112.5 MB)。相較客戶端Golden Cove,SPR在處理大量數據的應用程序時,能提供更好的性能表現。
對于需要頻繁訪問LLC的數據密集型工作負載,LLC集成在核心中可以大幅度減少LLC控制器和緩存間的連接,降低功耗。這種設計也為跨線程訪問提供了極大的靈活性。在需要時,一個核心可以訪問全部的LLC,一個LLC也可以服務于多個核心。
不過,這種跨線程訪問的缺點也很明顯,在某些情境,如需要跨越兩個Die以上的遠端存儲訪問時,可能會增加LLC控制器的工作負載,造成較高的延遲和Workload balance的不均衡。
3、優化設計成本
由于集成了多達60個核心(實際應用了56個)使得英特爾制造一個SoC芯片變得不切實際,從而轉向Chiplet和2.5D先進封裝,并通過Multi-Die架構簡化設計和制造。
基于Multi-Die架構,英特爾只需要設計兩組鏡像的掩模,再旋轉這兩個模具即可。不過,這種架構也為Die間的互聯帶來了挑戰。
互聯:由繁至簡
為了連接數量繁多的核心和緩存,英特爾在EMIB鏈路上運行了一個巨大的Mesh結構,將所有核心連接到它們各自的LLC切片,以及SPR上的其他組件,如內存控制器、各種加速器和其他I/O設備中,形成一個多Die的系統結構。
網絡加速單元
作為升級的重點,SPR在每個Die中嵌入了一個DSA網絡加速單元,可以在特定網絡工作負載中實現數倍的效率提升。該加速單元具有400Gb/s互聯帶寬,160Gb/s壓縮帶寬,每秒能夠做出400M的負載平衡決策。
DSA全稱為Data Streaming Accelerator,主要針對內存的搬移和傳輸的操作進行加速,能提高存儲、網絡和數據密集型工作負載的性能,類似于GPU等外部加速器。
在數據中心中,DSA可以更有效地處理如進行如壓縮/解壓縮、加/解密、內存搬移等特定工作負載,帶來大幅的性能提升。某些場景下,只需一個核心或部分核心就能夠處理復雜的工作負載,提高芯片的能效比。這也是英特爾為代表的頭部企業開始熱衷在處理器中內置加速器的因素之一。
基于 RoCE V2 協議自研 RDMA 技術,奇異摩爾自研Domain Specific Accelerator 系列專用領域加速器系列,具備高速以太網互聯能力,提供可編程的專用數據處理加速算法,同時集成了多種通用數據處理硬件加速器,高帶寬,高吞吐,硬件靈活可配置、軟件可編程,可實現芯粒/芯片間的高速傳輸。

D2D:DDR5 & EMIB
互連系統方面,每個Die配有2個128位的DDR5內存接口,DDD5采用優化版的EMIB工藝,單個EMIB的D2D帶寬高達500GB/s,功耗僅為0.5pj/bit,延遲(PHY Latency end-to-end TX+RX) 2.4ns。從die間功耗和延遲的方面來看,SPR已接近一個SoC。
為了進一步增強內存帶寬,EMIB技術首次支持HBM擴展,并特別為SPR設計了一種HBM變體,通過EMIB連接四個HBM,實現內存性能方面的顯著提升。

Chip2Chip:UPI & PCIe
在SPR中,每個Die還搭載了32個PCIe 5(CXL 1.1),以及24個UPI。配置為每個插槽80xPCIeGen5通道;以及24個UPI,支持最多8個芯片的互連,也意味著Sapphire Rapids芯片最多可以組建8路計算平臺。

挑戰與解決方案
因可簡化設計,Multi-Die架構在2顆芯粒的互聯架構中顯現出顯著的性價比優勢,但一旦芯粒超過2個,就會面臨互聯挑戰。

2023年5月,英特爾公布了SPR的下一代處理器,Emerald Rapids(ERP)。總體來說,英特爾基于SPR 相同的平臺和較新的Raptor Cove核心,通過優化物理設計,實現了“巨大的PPW”改進。但令人矚目的改變是,ERP的芯粒數量減少到兩個,這一架構上的回退也從側面反映出Mutil die模式下,多Die互聯難度之高。
此外,因芯粒數量減少導致芯片尺寸過大,加之先進工藝的使用,也帶來了成本高漲的問題;再次,在Mutil die架構中,為了維持高帶寬和低功耗,EMIB的使用也會相應的增加成本,ERP的生產成本實際上比 SPR 更高。假設成品率和芯片可回收性完美,相比 SPR-MCC,EMR 只能在每個晶圓上生產 34 個 CPU,低于每個 SPR 晶圓 37 個 CPU。如果考慮到完美良率之外的任何因素,EMR 的成本就會更高。
相比之下,AMD 則選擇了一種更為簡單的方案,通過獨立IO Die和CCD中的LLC集群,避免了復雜的多核互連問題。
下一站:Central IO Die
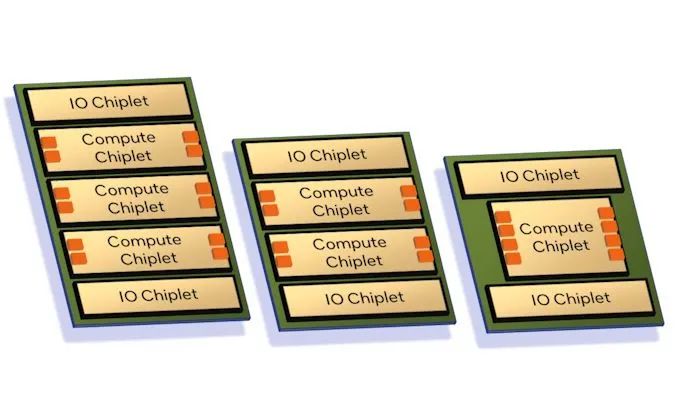
Hot Chips 2023 上,英特爾將旗下數據中心芯片分為兩類,Granite 和 Sierra ,二者都基于chiplet設計,并首次使用了獨立的 I/O 芯粒,通過 EMIB技術與計算單元封裝在一起。英特爾服務器處理器正式轉向Central IO Die架構。
隨著核心數量的增長和多die模式的流行,過去幾年中,各大計算芯片企業逐漸從Multi-Die模式轉向Central IO Die模式。以 IO Die 為代表的新興互聯技術正在打破芯片內固有的互聯方式。片內互聯技術向“更高的集成度、更短的距離、更高的效率”轉變。
在國內賽道,奇異摩爾作為片內互聯領域的代表企業,核心產品涵蓋2.5D interposer、2.5D IO Die、3D Base Die、NDSA、全系列Die2Die IP及相關Chiplet系統解決方案。
Central IO Die通過將IO功能從算芯片中分離出來,整合多種互聯接口,讓計算單元通過IO Die進行統一互聯,可以極大程度的簡化互聯設計,增加帶寬、并降低多Die間的互聯延遲。AMD Zen系列、Ampere 和 AWS 的 Graviton3 都在采用一個或多個不同的 IO芯粒。數據中心處理器Central IO Die 的模式正在到來。
-
cpu
+關注
關注
68文章
11037瀏覽量
216015 -
數據中心
+關注
關注
16文章
5143瀏覽量
73207 -
chiplet
+關注
關注
6文章
453瀏覽量
12866 -
奇異摩爾
+關注
關注
0文章
54瀏覽量
3659 -
芯粒
+關注
關注
0文章
62瀏覽量
247
原文標題:數據中心CPU芯粒化及互聯方案分析-PART2
文章出處:【微信號:奇異摩爾,微信公眾號:奇異摩爾】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論